Dataflow Gen2 を使用してデータを読み込んで変換する
Dataflow Gen2 は、新しい世代のデータフローです。 包括的な Power Query エクスペリエンスを提供し、データフローにデータをインポートするための各手順をガイドします。 データフローを作成するプロセスは簡素化され、必要な手順の数が減りました。
データ パイプラインのデータフローを使って、レイクハウスまたはウェアハウスにデータを取り込んだり、Power BI レポート用のデータセットを定義したりできます。
データフローを作成する
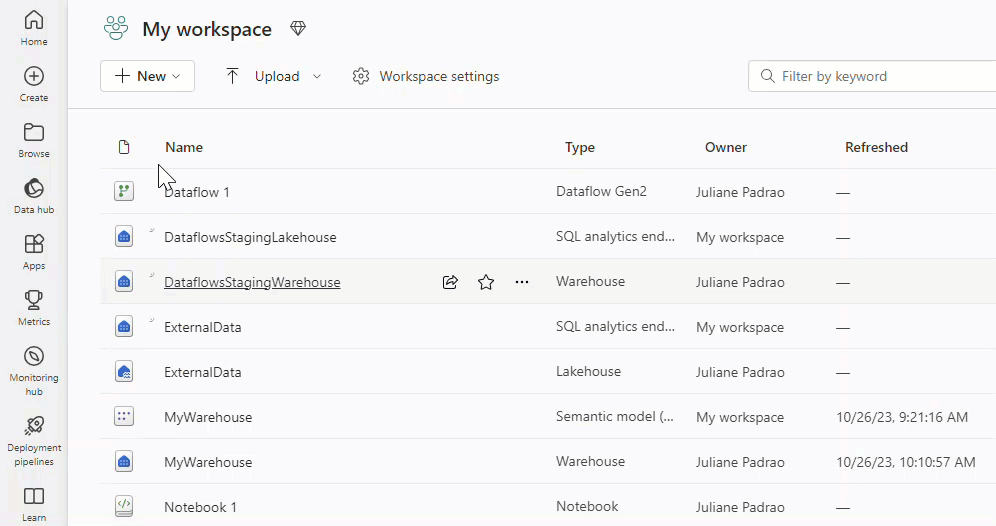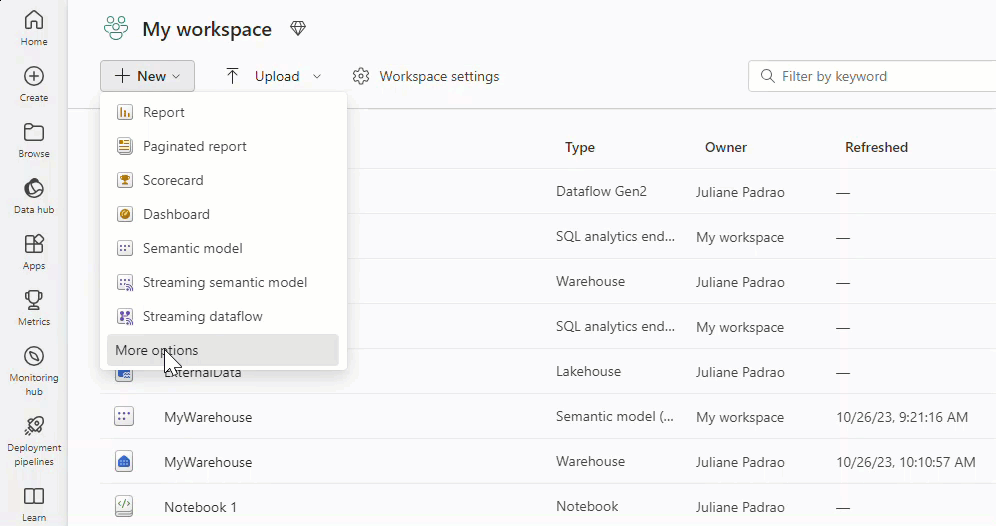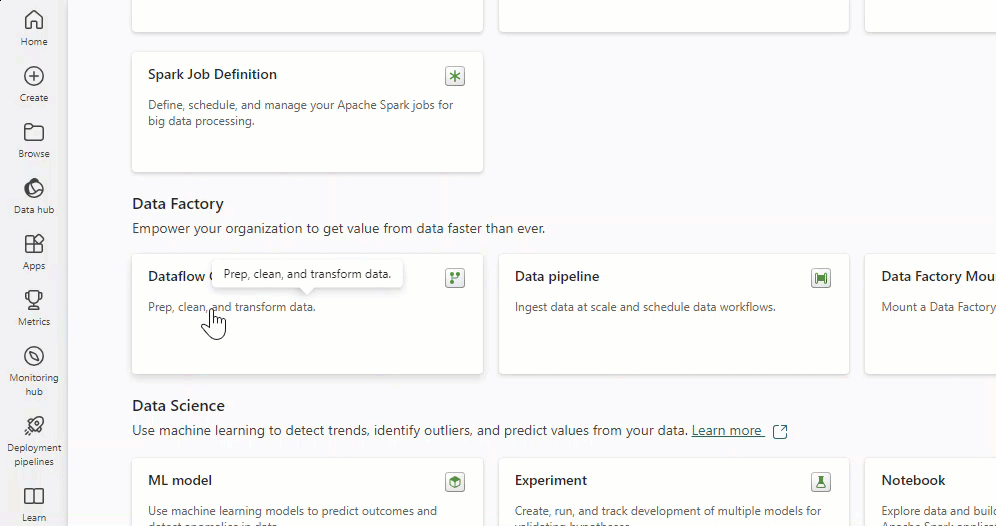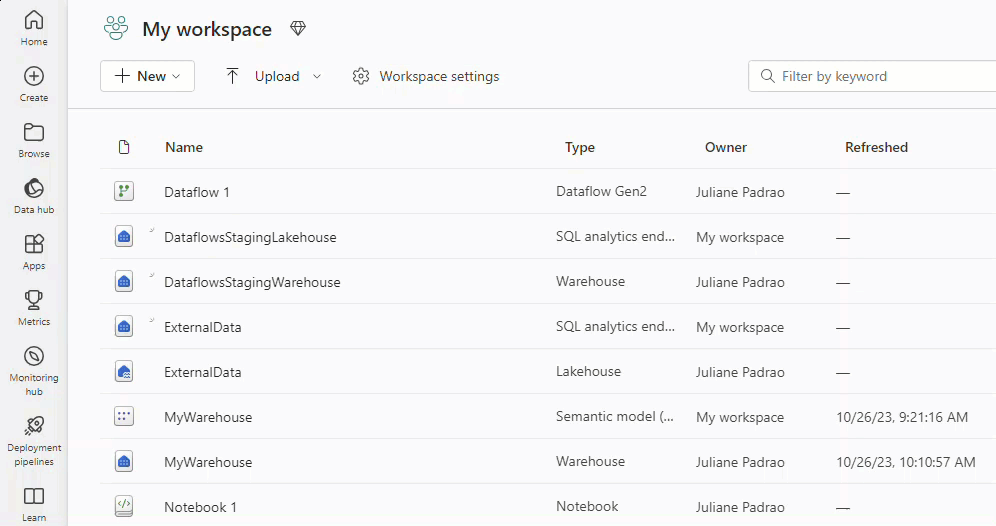
新しいデータフローを作成するには、ワークスペースに移動し、[+ 新規] を選択します。 Dataflow Gen2 が一覧に表示されない場合は、[その他のオプション] を選択して、[データ ファクトリ] セクションにある [Dataflow Gen2] を見つけます。
データのインポート
Dataflow Gen2 が起動すると、データを読み込むための多くのオプションが表示されます。

さまざまなファイルの種類をわずかな手順で読み込むことができます。 たとえば、ローカル コンピューターからテキストまたは CSV ファイルを読み込む場合などです。
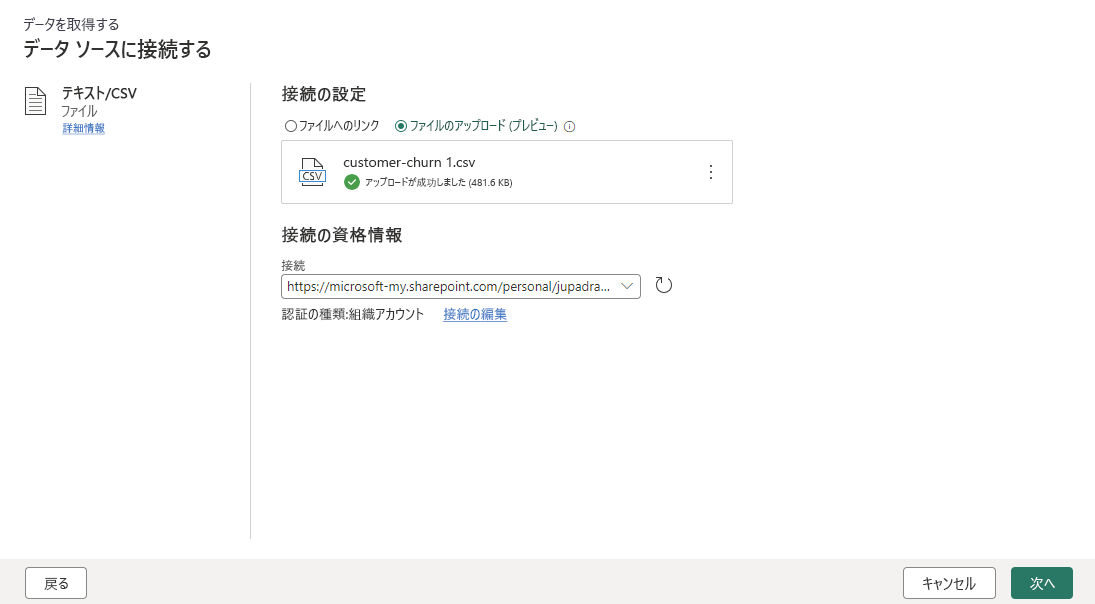
データをインポートしたら、データフローの作成を開始できます。データのクリーンアップ、整形、列の削除、新しい列の作成などを行うことができます。 実行した手順はすべて保存されます。
Copilot を使ってデータを変換する
Copilot は、データフロー変換を支援するのに役立つツールとして使用できます。 たとえば、'Male' と 'Female' を含む Gender 列があり、これを変換したいとします。
最初の手順は、データフロー内で Copilot をアクティブにすることです。 完了したら、実行したい変換についての具体的な指示を指定できます。
たとえば、次のようなコマンドを入力できます。"Gender 列を変換します。Male の場合は 0、Female の場合は 1。次に、整数に変換します。"
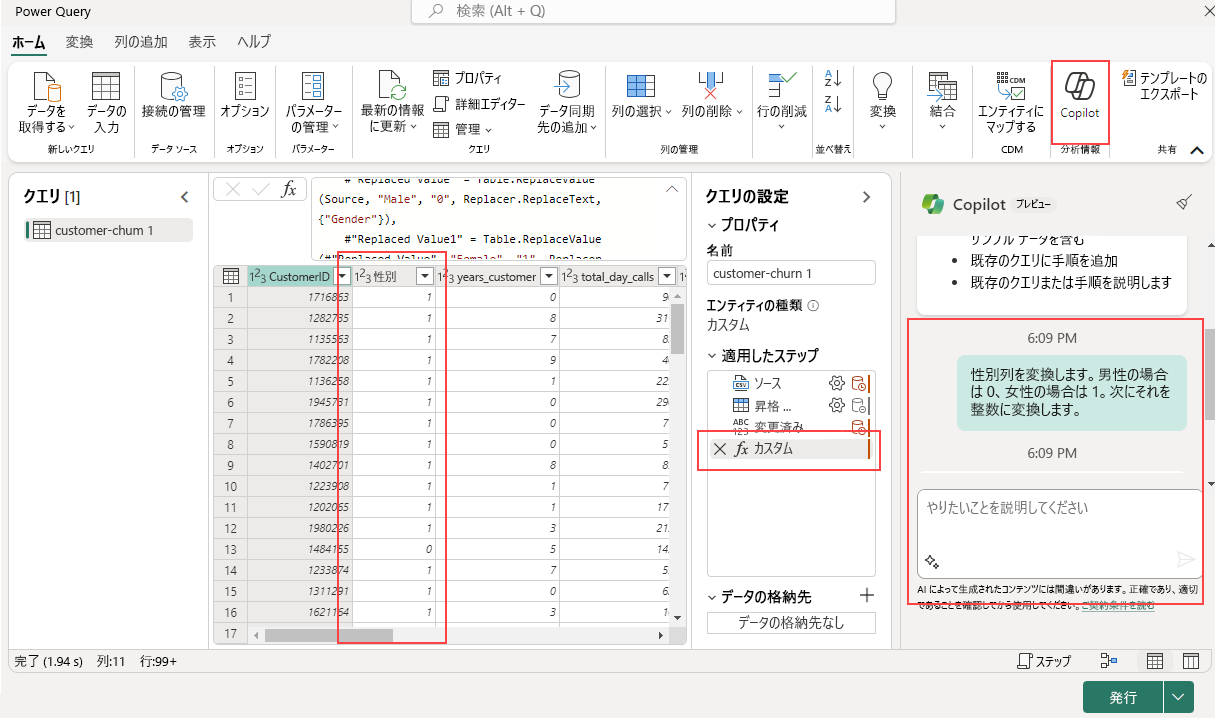
Copilot によって自動的に新しい手順が追加されます。必要があればいつでも元に戻したり、作業を続けてさらに変換したりできます。
データ格納先を追加する
[データ同期先の追加] 機能を使うと、ETL ロジックと同期先ストレージを分離できます。 この分離により、コードがすっきりして保守しやすくなり、ETL プロセスとストレージ構成を相互に影響を与えることなく簡単に変更できるようになります。
データを変換したら、次の手順は同期先ステップを追加することです。 [クエリの設定] タブで + を選択して、データフローに同期先ステップを追加します。
次の同期先オプションを使用できます。
- Azure SQL Database
- レイクハウス
- Azure Data Explorer (Kusto)
- Azure Synapse Analytics (SQL DW)
- 倉庫
ウェアハウスなどの同期先に読み込んだデータは、さまざまなツールを使って簡単にアクセスして分析できます。 これにより、データにアクセスしやすくなり、より柔軟で包括的なデータ分析が可能になります。
同期先としてウェアハウスを選択する場合は、次の更新方法を選択できます。

- 追加:既存のテーブルに新しい行を追加します。
- 置換:テーブルの内容全体を新しいデータのセットに置き換えます。
データフローを公開する
更新方法を選択したら、最後にデータフローを公開します。
公開すると、変換とデータ読み込みの操作がライブになり、手動またはスケジュールに従ってデータフローを実行できるようになります。 このプロセスにより、ETL 操作が 1 つの再利用可能なユニットにカプセル化され、データ管理ワークフローが合理化されます。
データフローで行った変更は、公開すると有効になります。 そのため、関連する変更を行った後は、必ずデータフローを公開してください。