デシジョン ツリーとモデル アーキテクチャ
アーキテクチャというと、多くの場合、建物を思い浮かべるかもしれません。 アーキテクチャは、建物がどのような構造になるか (高さ、深さ、フロア数、内部接続など) を定めます。 また、このアーキテクチャによって事実上、建物の使用方法 (どこから入るか、何が "得られるか" など) も決まります。
機械学習では、アーキテクチャは同様の概念を表します。 パラメーターの数はどれくらいになるか、また計算結果を得る上でそれらのパラメーターがどのように関わり合うでしょうか。 並列 (幅) して計算するでしょうか、それとも以前の計算に基づく直列的な演算 (深さ) を行うでしょうか。 このモデルにどのように入力を渡し、出力を受け取るでしょうか。 通常、このようなアーキテクチャの決定はより複雑なモデルにのみ適用され、アーキテクチャの決定には単純なものから複雑なものまで幅があります。 大抵、これらの決定はモデルをトレーニングする前に行いますが、状況によっては、トレーニング後に変更を加えることもできます。
例としてデシジョン ツリーを用いて、より具体的に考えてみましょう。
デシジョン ツリーとは
基本的に、デシジョン ツリーはフローチャートです。 デシジョン ツリーは、意思決定を複数のステップに分割する分類モデルです。
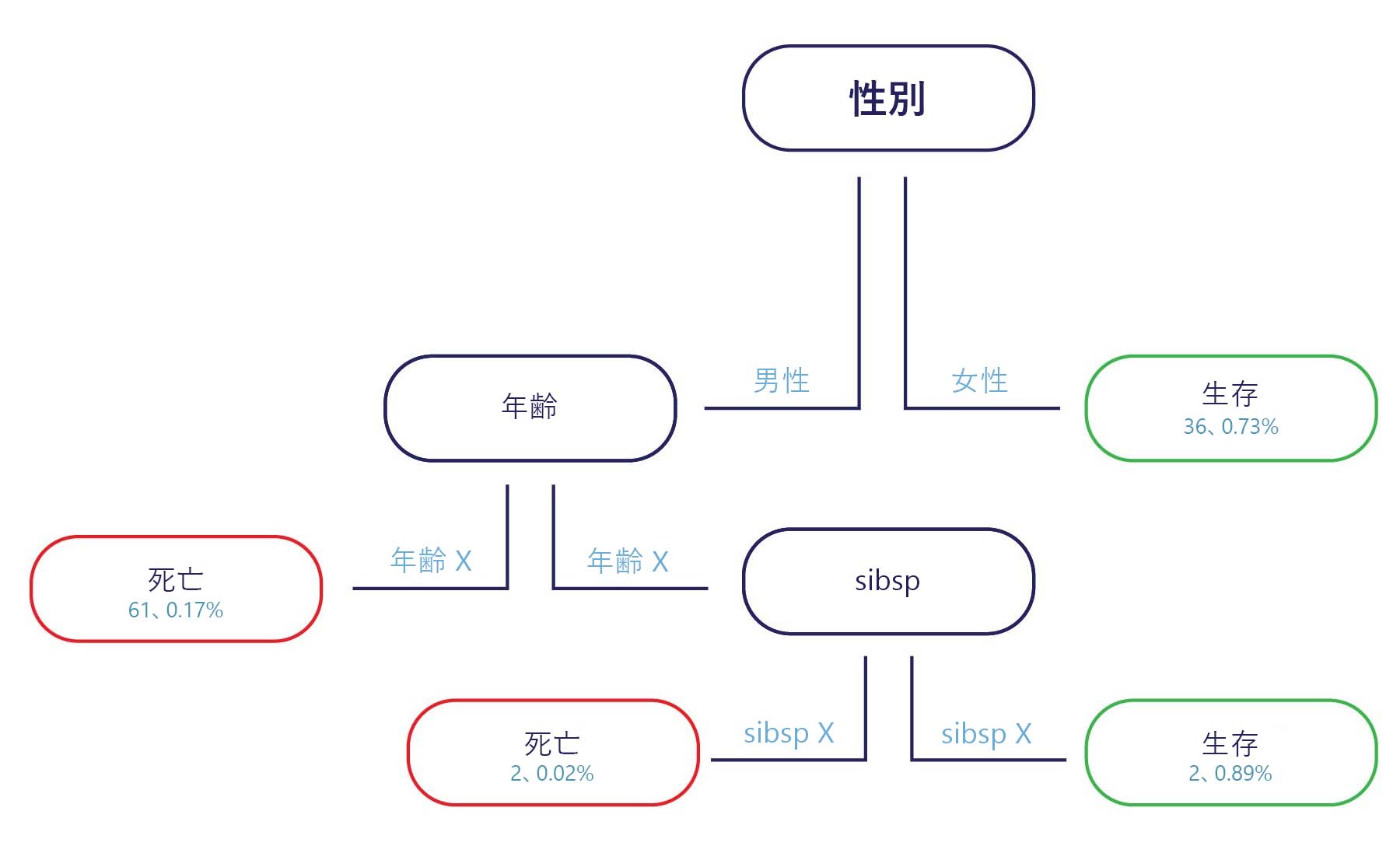
サンプルはエントリ ポイントで提供され (上記図の上部)、各エグジット ポイントにはラベルがあります (図の下部)。 各ノードでは、単純な "if" ステートメントによって、サンプルが次に通過する分岐が決定されます。 分岐がツリーの末尾 (リーフ) に達すると、ラベルに割り当てられます。
デシジョン ツリーのトレーニング方法
デシジョン ツリーは、一度に 1 つのノード (または意思決定ポイント) でトレーニングされます。 最初のノードでは、トレーニング セット全体が評価されます。 そこから、より同質のラベルを持つ 2 つのサブセットに最適に分離できる特徴が選択されます。 たとえば、次のようなトレーニング セットがあるとします。
| 体重 (特徴) | 年齢 (特徴) | メダルの獲得 (ラベル) |
|---|---|---|
| 90 | 18 | いいえ |
| 80 | 20 | いいえ |
| 70 | 19 | いいえ |
| 70 | 25 | いいえ |
| 60 | 18 | はい |
| 80 | 28 | はい |
| 85 | 26 | はい |
| 90 | 25 | はい |
このデータを分割するルールを見いだそうとすると、年齢で、しかも 24 歳頃で分けるかもしれません。メダルを勝ち取った選手のほとんどが 24 歳を超えているからです。 この分割によって、データの 2 つのサブセットが得られます。
サブセット 1
| 体重 (特徴) | 年齢 (特徴) | メダルの獲得 (ラベル) |
|---|---|---|
| 90 | 18 | いいえ |
| 80 | 20 | いいえ |
| 70 | 19 | いいえ |
| 60 | 18 | はい |
サブセット 2
| 体重 (特徴) | 年齢 (特徴) | メダルの獲得 (ラベル) |
|---|---|---|
| 70 | 25 | いいえ |
| 80 | 28 | はい |
| 85 | 26 | はい |
| 90 | 25 | はい |
ここで止めると、1 つのノードと 2 つのリーフを持つ単純なモデルになります。 リーフ 1 には、メダルを逃した選手が含まれており、トレーニング セットに対して 75% の精度が得られます。 リーフ 2 には、メダルを獲得した選手が含まれており、こちらもトレーニング セットに対して 75% の精度が得られます。
ただし、ここでは止める必要はありません。 リーフをさらに分割することで、このプロセスを続けることができます。
サブセット 1 では、最初の新しいノードを体重で分割できる可能性があります。唯一のメダル獲得選手がメダルを獲得していない人よりも体重が軽いためです。 ルールは "体重 < 65" に設定できます。 体重が 65 kg 未満の選手が、メダルを獲得すると予測されます。一方、体重が 65 kg 以上の選手はこの条件を満たさず、メダルを獲得しないと予測される可能性があります。
サブセット 2 では、2 番目の新しいノードも体重で分割できそうですが、今回は、体重が 70 kg を超える選手がメダルを獲得すると予測され、それ以下の体重の選手は獲得しないと予測されます。
これにより、トレーニング セットに対して 100% の精度を達成するツリーが出来上がります。
デシジョン ツリーの長所と短所
デシジョン ツリーでは、バイアスが低くなると見なされます。 これは、通常、適切なラベル付けを行うために重要な特徴を識別するのに適しています。
デシジョン ツリーの主な弱点は、オーバーフィットです。 前の例を考えてみましょう。このモデルでは、どの選手がメダルを獲得する可能性があるかを正確な方法で計算できます。これにより、トレーニング データセットの 100% が正しく予測されます。 このレベルの精度は、機械学習モデルでは異常であり、トレーニング データセットで多くのエラーが発生します。 優れたトレーニング パフォーマンス自体が悪いわけではありませんが、ツリーがトレーニング セットに特化され過ぎており、おそらくテスト セットではうまくいきません。 これは、25 歳未満の場合に 60 kg の体重であるとメダルが保証されるといった、あまり現実的ではないと思われるトレーニング セット内のリレーションシップを学習するようにツリーが管理されているためです。
モデル アーキテクチャがオーバーフィットに影響を与える
デシジョン ツリーをどのように構築するかは、その弱点を回避するうえで重要です。 ツリーが深くなるほど、トレーニング セットにオーバーフィットする可能性が高くなります。 たとえば、上記の単純なツリーで、ツリーを最初のノードのみに制限すると、トレーニング セットではエラーが発生しますが、テスト セットではうまくいく可能性があります。 これは、トレーニング セットにのみ適用される可能性のある非常に具体的なルールではなく、"24 歳以上の選手" といった、だれがメダルを獲得するかに関してより一般的なルールを持つことになるからです。
ここではツリーに焦点を絞っていますが、多くの場合、その他の複雑なモデルにも、どのような構造にするか、またトレーニングによる操作をどの程度許可するかを決定することによって軽減できる類似した弱点があります。