データの不均衡
データ ラベルに含まれているあるカテゴリの数が他のカテゴリより多い場合、データの不均衡があると言います。たとえば、このシナリオでは、ドローン センサーによって検出された物体を識別しようとしていることを思い出してください。 トレーニング データには、数が大きく異なるハイカー、動物、木、岩が含まれているため、このデータは不均衡です。 これは、このデータを表にするか、
| ラベル | ハイカー | 動物 | ツリー | 石 |
|---|---|---|---|---|
| Count | 400 | 200 | 800 | 800 |
またはグラフにすることによって確認できます。
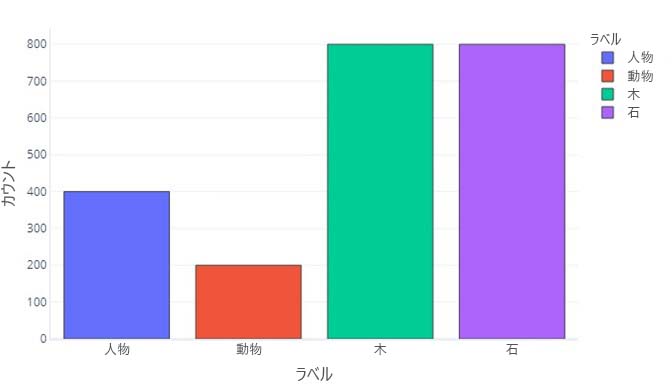
ほとんどのデータが木または岩であることに注意してください。 均衡のとれたデータセットには、この問題はありません。
たとえば、ある物体がハイカー、動物、木、岩のうちのどれであるかを予測しようとしている場合、次のように、すべてのカテゴリが等しい数にするのが理想的です。
| ラベル | ハイカー | 動物 | ツリー | 石 |
|---|---|---|---|---|
| Count | 550 | 550 | 550 | 550 |
単にある物体がハイカーであったかどうかを予測しようとしている場合は、ハイカーとハイカー以外の物体を等しい数にするのが理想的です。
| ラベル | ハイカー | ハイカー以外 |
|---|---|---|
| Count | 1100 | 1100 |
データの不均衡が問題になる理由
データの不均衡が問題になるのは、そうすることが望ましくないときに、モデルがこれらの不均衡を模倣するように学習できるためです。 たとえば、オブジェクトをハイカーまたはハイカー以外として識別するようにロジスティック回帰モデルをトレーニングしたとします。 このトレーニング データの多くが "ハイカー" ラベルで占められている場合、トレーニングでは、モデルがほとんど常に "ハイカー" ラベルを返すため偏りが生じます。 ただし、実際の使用環境では、ドローンが見つけるほとんどのものが木であるとわかることがあります。 偏りがあるモデルはおそらく、これらの木の多くにハイカーのラベルを付けます。
この現象が発生するのは、コスト関数が、既定では、正しい応答が得られたかどうかを判定するためです。 つまり、偏りがあるデータセットの場合、モデルが最適なパフォーマンスに到達するための最も簡単な方法は、提供された特徴をほとんど無視し、常に (または、ほぼ常に) 同じ答えを返すことである可能性があります。 これが破壊的な影響を与える場合があります。 たとえば、ハイカーが含まれているサンプルが 1000 件あたり 1 件のみであるデータで、ハイカー/ハイカー以外のモデルがトレーニングされるとします。 毎回 "ハイカー以外" を返すことを学習したモデルの精度は 99.9% です。 この統計は非常に優れているように見えますが、このモデルは役に立ちません。なぜなら、山に人がいるかどうかはわからず、雪崩が発生してもそれらの人々を救出できるかどうかはわからないからです。
混同行列における偏り
混同行列は、データの不均衡またはモデルの偏りを識別するための鍵です。 理想的なシナリオでは、テスト データにほぼ同じ数のラベルが含まれており、モデルによって行われた予測もラベルにまたがってほぼ分散しています。 1000 サンプルの場合、偏りはないが、間違った答えが得られることが多いモデルは、次のようになることがあります。
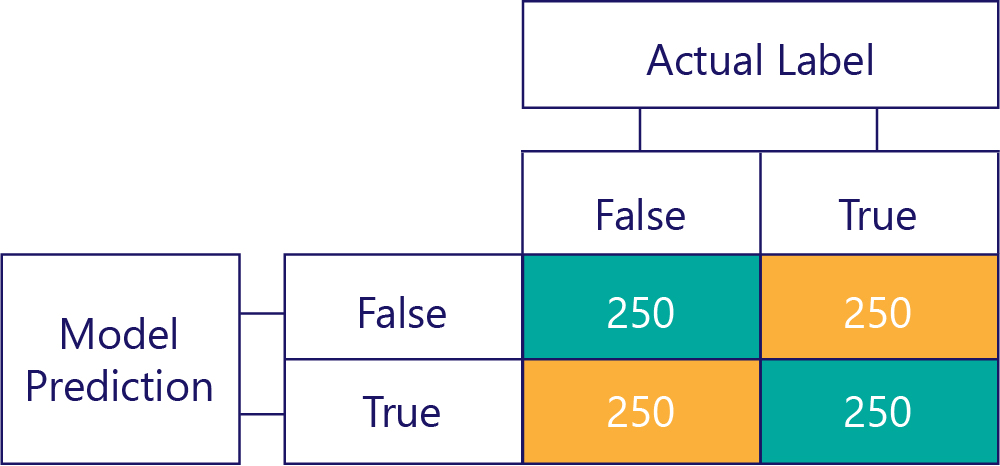
行の合計が同じ (それぞれ 500) であり、ラベルの半分は "true"、半分は "false" であることを示しているため、入力データは偏りがないと言えます。 同様に、時間の半分は true を、時間の残りの半分は false を返しているため、このモデルでは偏りのない応答が得られていることを確認できます。
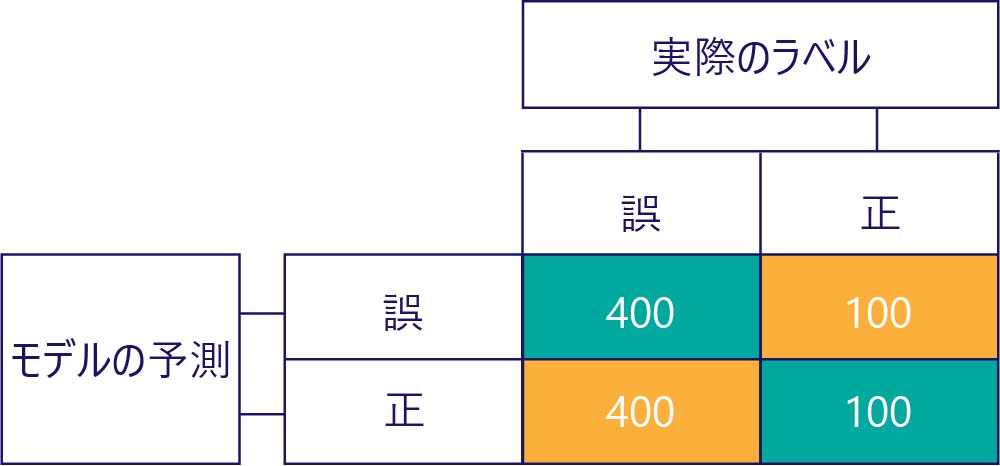
これに対して、偏りがあるデータにはほとんど、次のように 1 種類のラベルが含まれています。
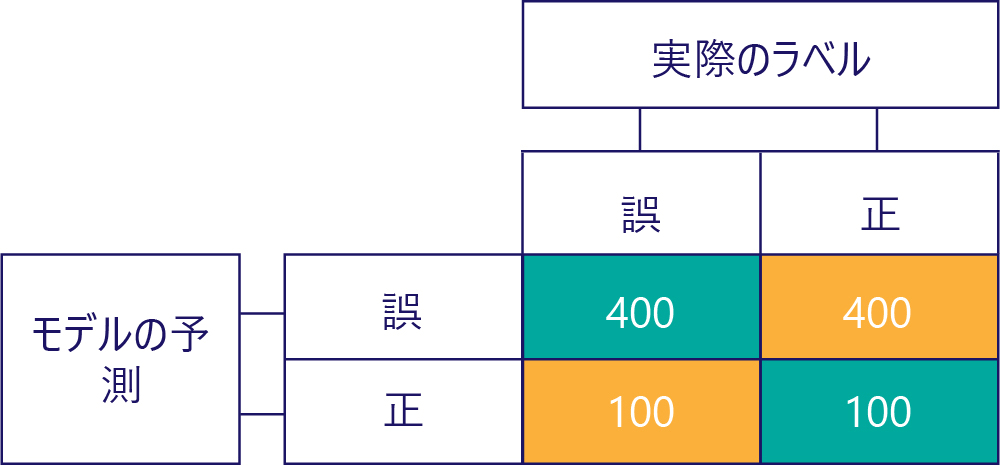
同様に、偏りがあるモデルはほとんど、次のように 1 種類のラベルを生成します。
モデルの偏りは精度ではない
偏りが精度ではないことに注意してください。 たとえば、上の例のいくつかには偏りがあり、その他には偏りがありませんが、これらはすべて、50% の確率で正しい答えが得られるモデルを示しています。 より極端な例として、次の行列は、不正確である偏りのないモデルを示しています。
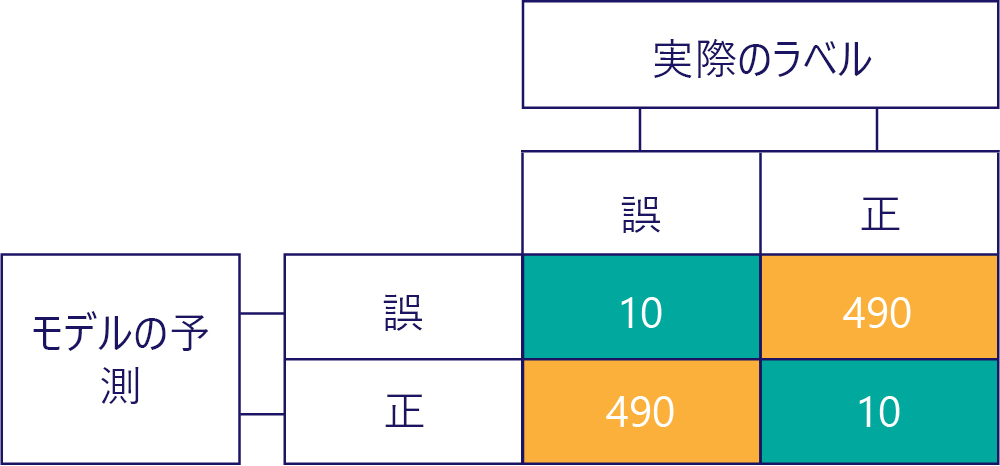
行と列の数がすべて合計して 500 になっており、データの均衡がとれていることと、モデルに偏りがないことの両方を示している点に注意してください。 ただし、このモデルでは、ほぼすべての応答が間違っています。
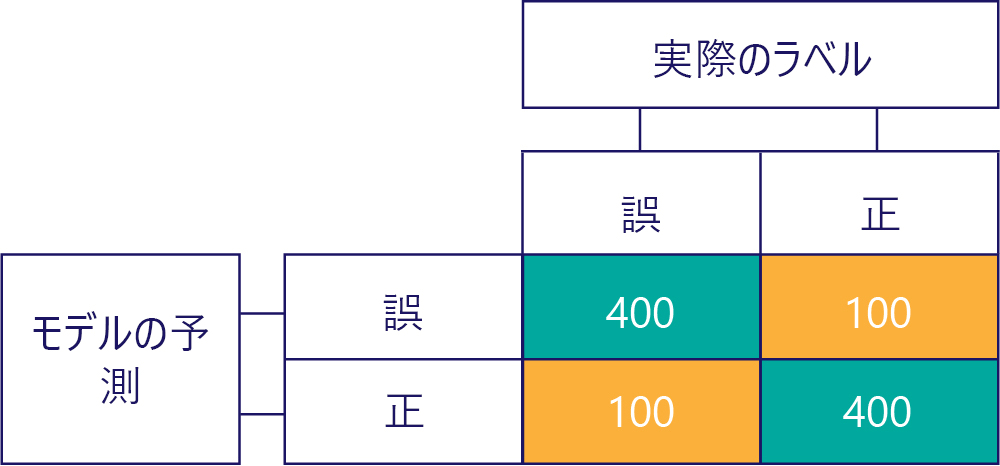
もちろん、私たちの目標は、モデルを正確で、かつ偏りのないものにすることです。その例を次に示します。
ただし、単純にデータが次のようになっているため、正確なモデルに偏りがないことを保証する必要があります。
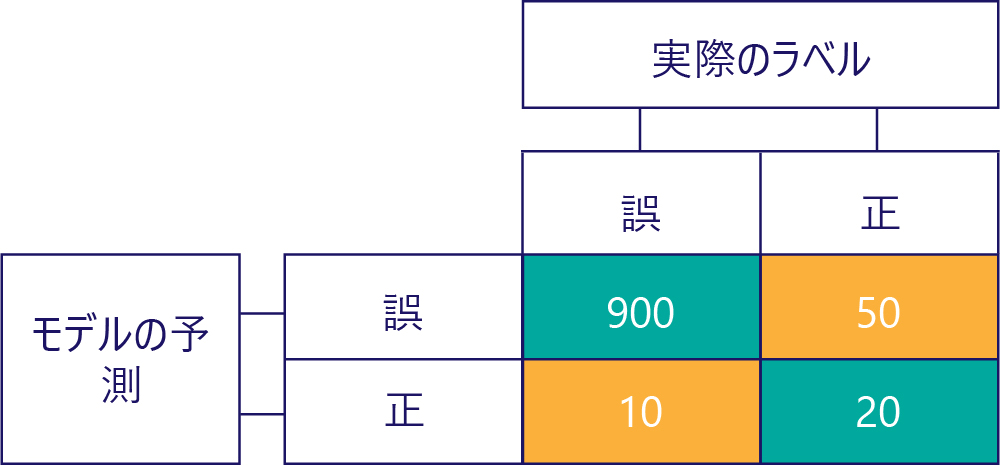
この例では、実際のラベルはほとんどが false であり (左の列、データの不均衡を示しています)、モデルもまた頻繁に false を返す (上の行、モデルの偏りを示しています) ことに注意してください。 このモデルは、'True' 応答を正しく返すことが得意ではありません。
不均衡なデータの影響の回避
不均衡なデータの影響を回避するための最も簡単な方法のいくつかを次に示します。
- データ選択を改善することによって回避します。
- 少数派ラベル クラスの重複が含まれるようにデータを "リサンプル" します。
- あまり一般的ではないラベルを優先するようにコスト関数を変更します。 たとえば、木を返すべき応答が間違っている場合はコスト関数で 1 を返し、ハイカーを返すべき応答が間違っている場合は 10 を返すようにします。
次の演習では、これらの方法について調べます。