Apache Kafka を使用してデータをストリーム配信する
Apache Kafka は、高度なフォールト トレランスを備えた超低遅延かつ超大規模なデータ移動という目標を掲げて、2010 年に LinkedIn で開発されました。 その後、2012 年にこのプロジェクトは Apache Foundation に寄贈されましたが、LinkedIn ではユーザー アクティビティの追跡、メッセージの交換、メトリックの収集のために、Kafka をエコシステム全体で引き続き使用しています。
Kafka は、以下を目的として設計された分散ストリーミング プラットフォームです。
- データ パイプラインの簡素化
- ストリーミング パターンでの大量のデータの処理
- リアルタイムおよびバッチ システムのサポート
- 水平方向への大規模な拡張
最初に Apache Kafka そのものについて説明し、次に Azure HDInsight 上での Kafka について説明します。
Kafka コンポーネント
Kafka のしくみを理解する前に、Kafka のいくつかの主要なコンポーネントの役割と、それらがどのように連携して、拡張性とフォールト トレランスに優れたメッセージング システムを提供するかについて説明します。
ブローカー
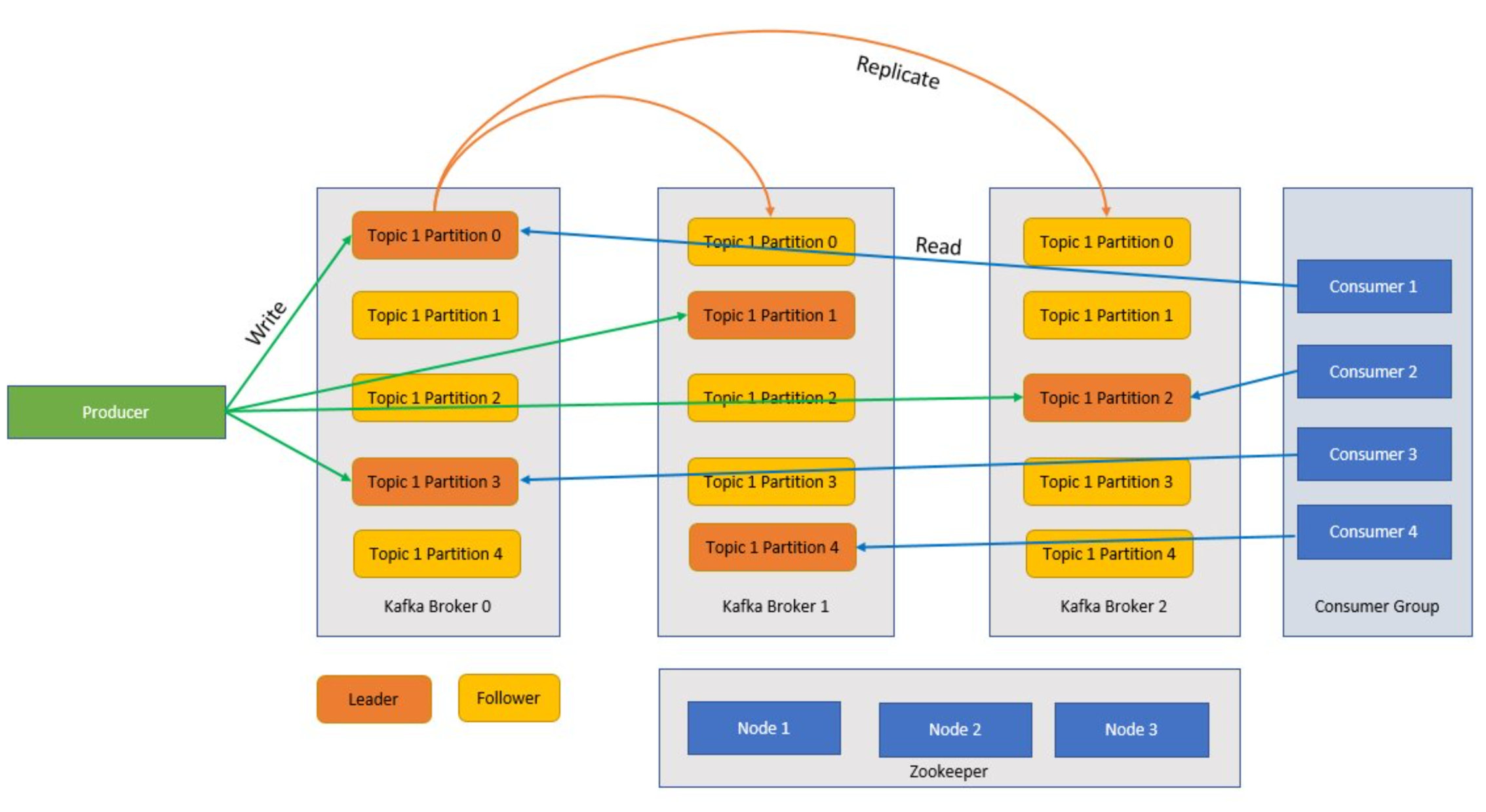
Kafka はクラスター化されたサービスで、1 つの Kafka クラスターはブローカーとも呼ばれます。 ブローカーはプロデューサーからメッセージを受信し、それらのメッセージをディスクに格納します。 ブローカーは、コンシューマーからのフェッチ要求にも応答します。 ブローカーのクラスター内では、1 つのブローカーがコントローラーとして機能し、管理操作と、ブローカーへのパーティションの割り当てを行います。
メッセージ
Kafka クラスター内のデータの単位。 ほとんどのインスタンス内のメッセージは、キーと値のペアです。
トピックとパーティション
Kafka では、トピックとパーティションはメッセージのカテゴリです。 通常、全体を向上させるためにトピックはいくつかのパーティションに分割されます (3 つ以上のパーティションが推奨されます)。 メッセージは、追加のみの方法でトピック パーティションに書き込まれます。 ブローカーに障害が発生した場合の冗長性を向上させるために、パーティションはさらに複数のブローカーにわたってレプリケートされます。 パーティションを使用すると、複数のブローカーの間でデータを分割できるため、トピックを並列で読み取ることができます。 すべての読み取り/書き込み要求を処理するリーダー レプリカが 1 つあり、フォロワーはそのリーダーからレプリケートされます。 リーダーに障害が発生した場合は、それらのレプリカの 1 つがリーダーになります。
プロデューサーとコンシューマー
プロデューサーとコンシューマーは、それぞれ Kafka システムからメッセージを生成したり、使用したりするクライアントです。 プロデューサーは、新しいメッセージを公開し、特定のトピックに送信します。 特定のトピック パーティションに書き込むようにコンシューマーを設計することもできます。 一方、コンシューマーは 1 つまたは複数のトピックをサブスクライブして、それらのトピックからメッセージを読み取ります。
コンシューマー グループ
1 つまたは複数のコンシューマーがグループとして連携し、グループとしてメッセージを使用できます。 コンシューマーの数がトピック パーティションの数と等しい場合は、各コンシューマーが 1 つのトピック パーティションから使用するため並列処理が行われます。
保持
Kafka 内のメッセージは、事前定義された期間だけ、Kafka クラスター内に非揮発性として保持できます。 保持期間の上限に達すると、Kafka ではそれらのメッセージを期限切れにして削除できます。
オフセット
オフセットとは、単にパーティション内のメッセージの位置のことです。 メッセージが処理されるときに、パーティション内の現在の位置を更新することをコミットと呼びます。 メッセージが処理されると、Kafka によって、メッセージのオフセットが特別な内部 Kafka トピックにコミットされます。 プロデューサーがメッセージをパーティションに公開すると、それはリーダーに転送されます。 リーダーは、そのメッセージをコミット ログに追加し、メッセージ オフセットを増分します。 メッセージ オフセットは、トピック内でメッセージがどのように識別されるかを示すものです。 メッセージがクラスターにコミットされた後にのみ、コンシューマーはメッセージを使用できます。
Zookeeper
Zookeeper とは調整サービスのことであり、Kafka クラスター内では、Zookeeper はクラスターの状態の同期されているビューを提供します。 Kafka では、ブローカーやトピック パーティション間でのリーダーの選出に Zookeeper が使用されています。 Kafka では、Zookeeper を使用して、クラスターを形成する Kafka ブローカーのサービス検出を管理します。 Zookeeper によってトポロジの変更が Kafka に送信されるため、クラスター内の各ノードでは、新しいブローカーの加入、ブローカーの停止、トピックの削除、またはトピックの追加がいつ行われたかを認識しています。
すべてが連携して機能するしくみ
アプリケーション (プロデューサーとも呼ばれる) によって Kafka ブローカーにメッセージが送信され、それらのメッセージが 1 つまたは複数のコンシューマーによって処理されます。 クラスター内のメッセージは、トピック別に分類されます。 たとえば、顧客は "売上" というトピックを作成して、売上などに関連するすべてのメッセージを送信できます。 メッセージの増加に伴ってトピックのサイズが大きくなると、それらはパーティションに分割され、冗長性を確保するために、それらのパーティションはさらに複数の Kafka ブローカーにわたってレプリケートされます。 パーティションは、リーダーとフォロワーに分類されます。 リーダー パーティションは書き込み先や読み取り元となりますが、フォロワー パーティションは単なるレプリカであり、リーダーの状態を把握しているだけです。 書き込み先や読み取り元となるパーティションを特定するために、プロデューサーとコンシューマーは、どのパーティションがリーダーとして設計されているかを認識している必要があります。 Zookeeper ノードでは、Kafka クラスターの状態を管理しており、その中でも特にパーティション リーダーを選出して、その情報をプロデューサーとコンシューマーに提供します。
Kafka では、パーティションを持つメッセージが、受信されたのと同じ順序で並べられることを保証しています。 特定のメッセージは、そのオフセット (パーティション内での位置) を使用して明確に特定できます。 コンシューマーは、パーティションからメッセージを読み取り、処理後に、メッセージが正常に処理されたことを示すオフセットをコミットします。 Kafka では、すべてのレコードがディスクに保存され、メッセージの永続性が確保されます。 何らかの理由でコンシューマーが中断され、処理が停止した場合、Kafka では、事前定義された保持期間の間だけそれらのメッセージを保持します。オンラインに戻ると、コンシューマーは、コミットされたオフセット (中断前に中止した場所) から処理を再開できます。
Kafka トピック
Kafka トピックとは、メッセージが格納および公開されるフィードまたはキューです。 プロデューサーはトピックにメッセージをプッシュし、コンシューマーがトピックから読み取ります。 Kafka ブローカー内の各ノードには、複数のトピックを含めることができます。
Azure HDInsight 上での Kafka の利点
オープンソース バージョンの Kafka には多くの機能が搭載されていますが、その設定には多くの作業が必要です。 Azure HDInsight では、オープンソースの分析フレームワークを Azure に導入して、顧客がオープンソース クラスターの設定に数週間も数か月もかけるのではなく、数分以内で簡単に設定できるようにします。そのため、それらをすぐに使用できます。 また、HDInsight は次の利点を備えたエンタープライズ向けの製品でもあります。
- これは、簡単な構成プロセスを提供する管理されたサービスです。 その結果は、Microsoft によってテスト済みのサポートされている構成になります。
- Microsoft では、Spark と Kafka のアップタイムに対し 99.9% のサービス レベル アグリーメント (SLA) を提供しています。
- Kafka のバッキング ストアとして Azure Managed Disks を使用します。 Managed Disks には、Kafka ブローカーあたり最大 16 TB のストレージを搭載できます。
- HDInsight では、VNet を使用した最高のエンタープライズ セキュリティ、Apache Ranger を使用したきめ細かいセキュリティ、保存データの Bring Your Own Key (BYOK) 暗号化を提供しています
- HIPAA、SOC、PCI へのコンプライアンス
- 同じ VNet 内で自動の Azure Resource Manager (ARM) テンプレートを使用して、Spark と Storage を含むエンドツーエンドのストリーミング パイプラインをデプロイできます。
- Kafka の MirrorMaker を使用して高可用性を実現できます。この場合、プライマリ クラスター上のトピックからレコードが使用され、セカンダリ クラスターにローカル コピーが作成されます。
- HDInsight を使用すると、クラスターの作成後に、worker ノード (Kafka ブローカーをホストするノード) の数を変更することができます。 スケーリングは、Azure Portal、Azure PowerShell、およびその他の Azure 管理インターフェイスで実行できます。 Kafka では、スケーリング操作の後で、パーティションのレプリカを再調整する必要があります。 パーティションを再調整することで、Kafka は新しい数のワーカー ノードを活用することができます。
- Azure Monitor ログを使用して、HDInsight 上の Kafka を監視できます。 Azure Monitor ログには、仮想マシン レベルの情報 (ディスクと NIC のメトリック、Kafka からの JMX メトリックなど) が記録されます。