Kafka と Spark アーキテクチャを作成する
Azure HDInsight で Kafka と Spark を併用するには、それらを同じ VNet 内に配置するか、VNet をピアリングして、それらのクラスターが DNS 名前解決を使用して動作するようにする必要があります。
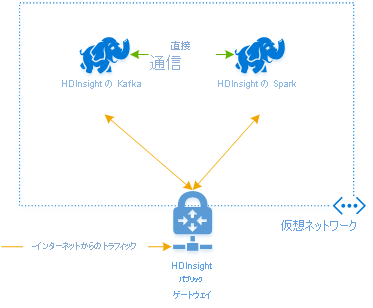
同じ VNet 内にクラスターを作成するには、次の手順に従います。
- リソース グループを作成する
- リソース グループに VNet を追加する
- Kafka クラスターと Spark クラスターを同じ VNet に追加するか、あるいはこれらのサービスが DNS 名前解決を使用して動作する VNet をピアリングします。
HDInsight の Kafka および Spark クラスターを接続するには、ネイティブの Spark - Kafka コネクタを使用することをお勧めします。これにより、Spark クラスターが Kafka クラスター内のデータの個々のパーティションにアクセスできるようになるため、リアルタイム処理ジョブに含まれる並列処理の数が増え、非常に高いスループットが得られます。
両方のクラスターが同じ VNet 内にある場合は、Spark ストリーミング コード内で Kafka ブローカーの FQDN を使用することもできます。また、エンタープライズ セキュリティのために VNet に対し NSG ルールを作成することもできます。
ソリューションのアーキテクチャ
Azure 上でのリアルタイム ストリーミング分析パターンには通常、次のソリューション アーキテクチャが使用されます。
- 取り込み: 非構造化または構造化データは、Azure HDInsight 上の Kafka クラスターに取り込まれます。
- 準備とトレーニング: データは、HDInsight 上の Spark で準備され、トレーニングされます。
- モデル化と提供: データは、Azure Synapse や HDInsight Interactive Query などのデータ ウェアハウスに格納されます。
- インテリジェンス: データは、Power BI や Tableau などの分析ダッシュボードに提供されます。
- ストア: データは Azure Storage などのコールド ストレージ ソリューションに入れられ、後で配信されます。

サンプル シナリオのアーキテクチャ
次のユニットでは、サンプル アプリケーション用のソリューション アーキテクチャの構築を開始します。 このサンプルでは、Azure Resource Manager テンプレート ファイルを使用して、リソース グループ、VNet、Spark クラスター、Kafka クラスターを作成します。
それらのクラスターがデプロイされたら、いずれかの Kafka ブローカーに SSH で接続し、Python プロデューサー ファイルをヘッド ノードにコピーします。 このプロデューサー ファイルは、10 秒ごとに擬似株価を提供します。また、メッセージのパーティション番号とオフセットをコンソールに書き込みます。
プロデューサーが実行されたら、Jupyter Notebook を Spark クラスターにアップロードできます。 このノートブックで、Spark および Kafka クラスターを接続し、データに対していくつかのサンプル クエリ (イベント ウィンドウ内で株価の高値と安値を検索するなど) を実行します。
