Azure Databricks を使用してデータを取り込む
Azure Databricks 内でデータを操作する前に、プラットフォーム内にデータを取り込む必要があります。 プラットフォームの中に入ると、クラウドベースのコンピューティングを使用して、大量のデータを効率的に処理できます。
Azure Databricks のデータは、リレーショナル テーブルを定義および照会できるデータ ファイルを管理するためのオープンソース システムである Apache Delta Lake を使用して格納されます。 差分レイク ファイルの実際の保存場所は異なる場合があります。 Azure Databricks では、Azure Storage や Azure Data Lake などのクラウド データ ストレージ サービスへの接続がサポートされています。 Azure Databricks には、複数の接続されたデータ ストア間でデータ アクセスと系列を管理および追跡するためのガバナンス ソリューションとして Unity カタログ も用意されています。
Azure Databricks 内にデータを取り込む方法が複数あることにより、次のようなデータ分析用の多目的で強力なツールとなっています:
Lakeflow Connect での Managed Databricks コネクタの使用
Azure Databricks Lakeflow Connect は、マネージド コネクタを使用して SaaS アプリケーション、データベース、およびその他のソースから Lakehouse にデータを取り込むためのフレームワークを提供します。 これらのコネクタは、認証、パイプライン、および変換先テーブルの設定方法と管理方法を定義します。 SaaS ソースの場合、主な要素は 接続 (認証用)、 サーバーレス インジェスト パイプライン、および取り込まれたデータを格納する Delta テーブル です。 データベース コネクタには同じ要素が含まれますが、抽出されたデータを一時的に保持するために、クラシック コンピューティングと Unity カタログのステージング ストレージ領域で実行される インジェスト ゲートウェイ にも依存します。 オーケストレーションは Databricks ジョブによって処理され、アクセス制御と監査は Unity カタログを介して管理されます。
マネージド コネクタを使用すると、カスタム インジェスト コードを記述しなくても、データ パイプラインをスケジュール、再試行、およびスケーリングできます。 増分インジェストがサポートされています。これにより、テーブルを最新の状態に保ちながら、ソース システムの負荷を軽減できます。 このアプローチでは、さまざまなデータ ソース間で一貫したガバナンス、スキーマ処理、監視が重視されます。
次のマネージド コネクタを使用できます。
- Google アナリティクス
- Salesforce
- Workday レポート
- SQL Server
- ServiceNow
- SharePoint
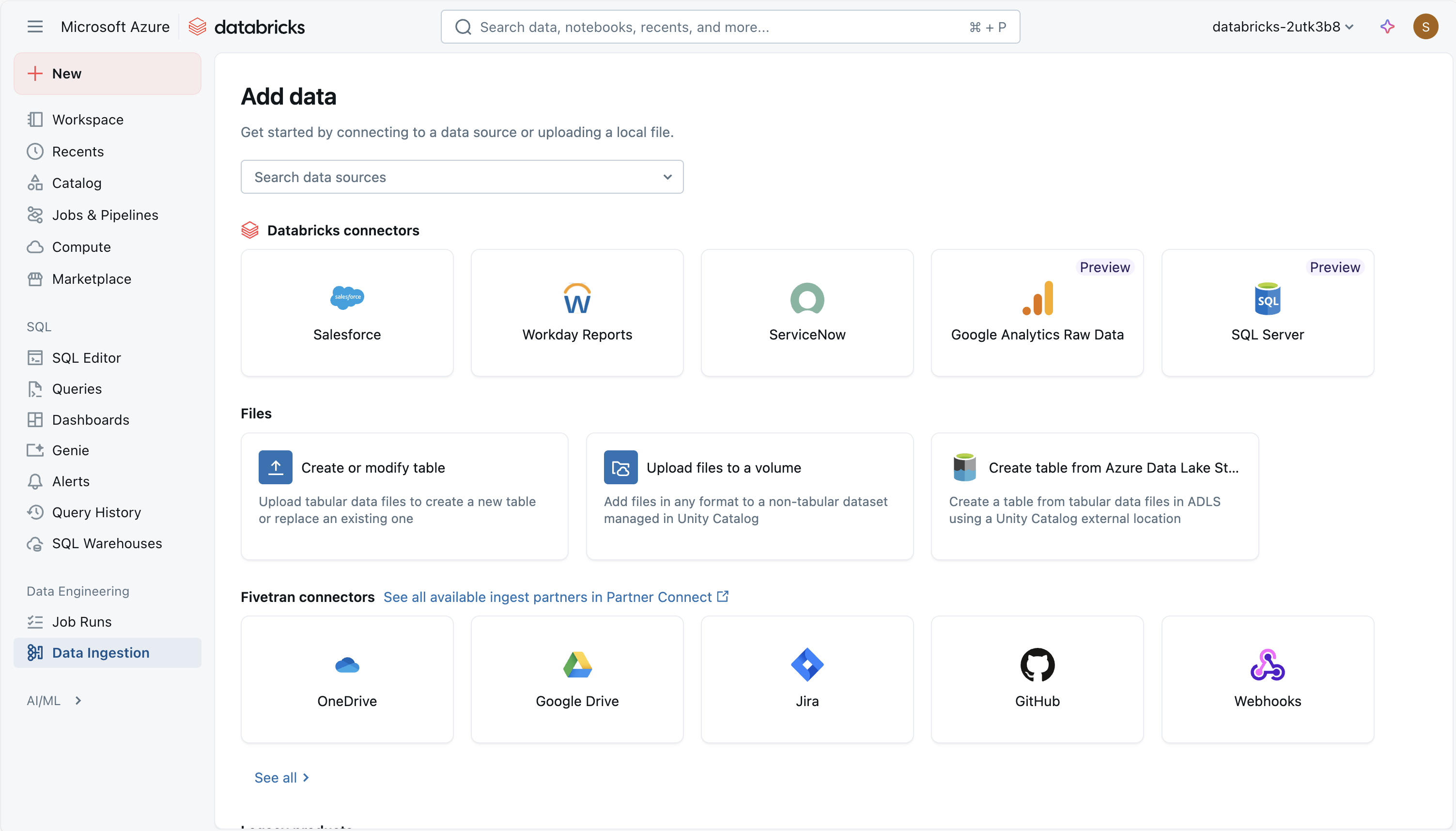
Azure Databricks にファイルをアップロードする
ローカル CSV、TSV、JSON、XML、Avro、Parquet、またはプレーン テキスト ファイルを Databricks にインポートして 、Delta テーブルを生成できます。 この方法は、コンピューターから直接転送される小さいファイル (2 GB 未満) を対象としています。 ZIP や TAR などの圧縮アーカイブはサポートされていません。 アップロード プロセス中、Databricks には最大 50 行のプレビューが用意されており、書式設定を調整して、CSV または JSON ファイル内の列とデータ型が正しく認識されるようにすることができます。
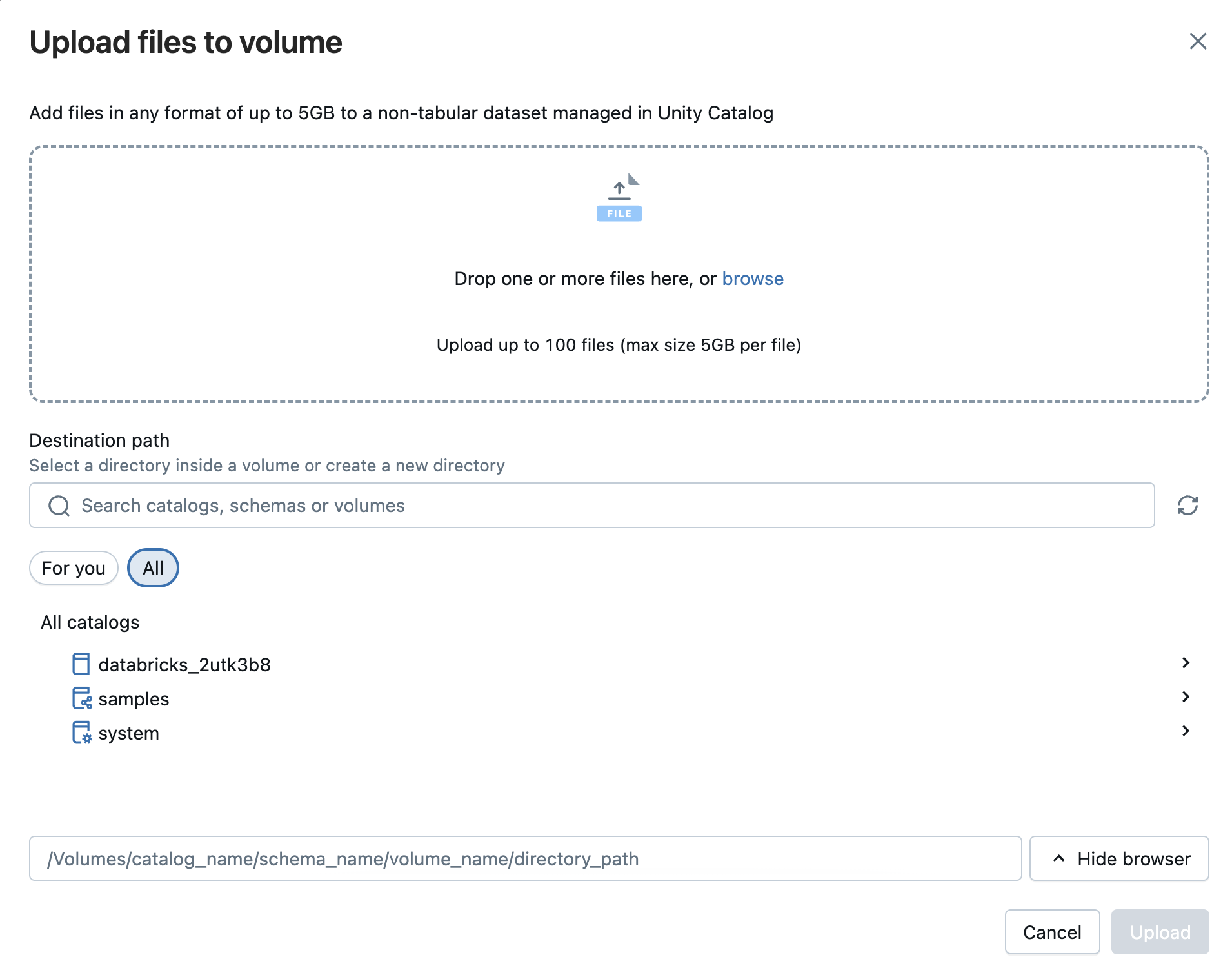
また、任意の形式 (構造化、半構造化、非構造化) のファイルを ボリュームにアップロードすることもできます。 ボリュームは、表形式以外のデータセットのガバナンスを提供し、クラウド オブジェクト ストア内の論理ストレージ領域を表す Unity Catalog オブジェクトです。 ボリュームを使用すると、ファイルへのアクセス、保存、整理、ガバナンスの適用を行うことができます。 ボリュームには次の 2 種類があります。
- マネージド ボリューム: Databricks で管理されるストレージ。簡単なユース ケースに対応します。
- 外部ボリューム: 既存のクラウド オブジェクトストレージの場所に適用されるガバナンス。
注
DBFS オプションを使用すると、従来の Databricks ファイル システム ファイルのアップロードを使用できます。 これはサポートされなくなりました。
Apache Spark API を使用してファイルを取り込む
Apache Spark は Azure Databricks のネイティブ コンピューティング プラットフォームであり、Scala、Java、PySpark (Python の Spark 最適化バリアント)、SQL などの複数のプログラミング言語の API をサポートしています。 リモート ストレージ内のデータを簡単に取り込むには、必要なデータに接続してインポートするコードを記述できます。
wget を使用してドライバー ノードの /tmp/ にリモート ファイルをプルし、Spark を使用してローカル パスから読み取り、Databricks の Delta テーブルとして保存する例を次に示します。
# Step 1: Use wget to download the file (e.g., a CSV from a public URL)
# In Databricks, prefix shell commands with "!"
!wget https://<location>/airtravel.csv -O /tmp/airtravel.csv
# Step 2: Load the downloaded file into a Spark DataFrame
df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file:/tmp/airtravel.csv")
# Step 3: Preview the data
df.show(5)
# Step 4: Save as a Delta table
df.write.format("delta").mode("overwrite").saveAsTable("default.airtravel")
サービス プリンシパルで COPY INTO を使用してデータを読み込む
COPY INTO コマンドを使用して、Azure アカウントの Azure Data Lake Storage (ADLS) コンテナーから Databricks SQL のテーブルにデータを読み込むことができます。
COPY INTO my_json_data
FROM 'abfss://container@storageAccount.dfs.core.windows.net/jsonData'
FILEFORMAT = JSON;
Lakeflow 宣言型パイプライン
Lakeflow 宣言型パイプラインは、SQL および Python でバッチ およびストリーミング データ パイプラインを開発および実行するための宣言型フレームワークです。 自動オーケストレーション、再試行、エラー分離、スキーマの進化、増分処理、CDC 変更データ キャプチャの種類 1 と 2 がサポートされています。
フローは、ストリーミングセマンティクスとバッチ セマンティクスの両方をサポートする Lakeflow 宣言パイプラインの基本的なデータ処理の概念です。 フローは、ソースからデータを読み取り、ユーザー定義の処理ロジックを適用して、結果をターゲットに書き込みます。
パイプラインの期待値を使用してデータ品質を管理することもできます。これにより、データが宛先に書き込まれる前に、データが必要な標準を満たしていることを確認する検証規則を定義できます。
宣言型パイプラインの例を次に示します。
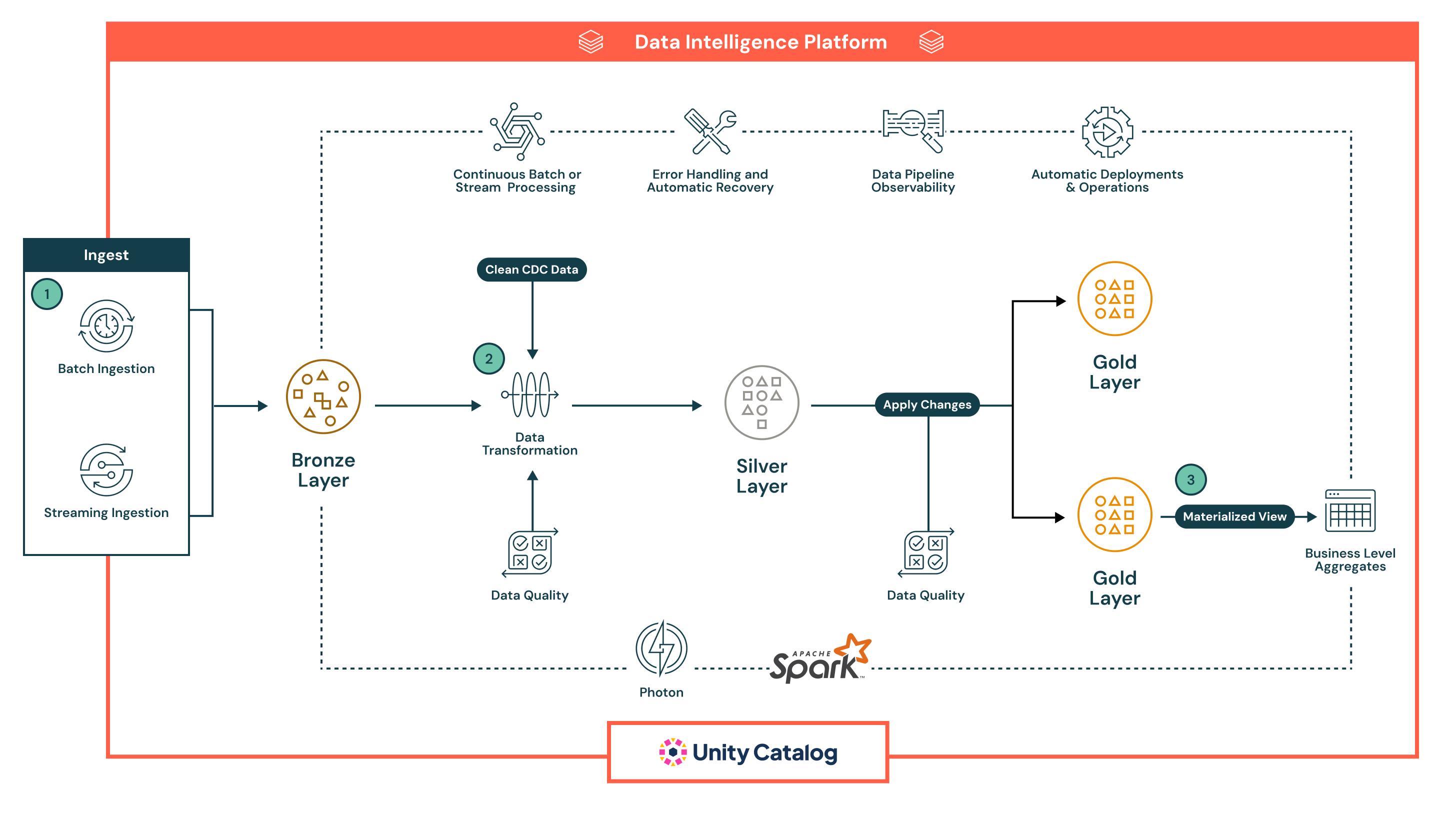
この例では、データはまず系列と安全な再処理のために生の形式で ブロンズ レイヤーに配置され、 次に Silver レイヤーに進み、そこでクリーニング、強化、インライン品質チェックで検証され、Spark で大規模に処理されてから、 Gold レイヤーに到達します。これにより、BI、機械学習、履歴追跡などの高度なユース ケース用にキュレーションされたビジネス対応データセットが提供されます。
Azure Data Factory
Azure Data Factory (ADF) を使用すると、組み込みのコピー アクティビティを使用して 、Azure Databricks Delta Lake との間でデータを コピーできます。 ソースとして機能する場合、ADF は Databricks の Delta テーブルからデータを抽出し、サポートされているシンクに移動できます。シンクとして機能する場合は、サポートされているソースから Delta Lake テーブルにデータを読み込むことができます。
データ移動は、転送を処理するために Databricks クラスターを呼び出すことによって調整され、ADF は環境に応じて Azure 統合ランタイムとセルフホステッド統合ランタイムの両方をサポートします。
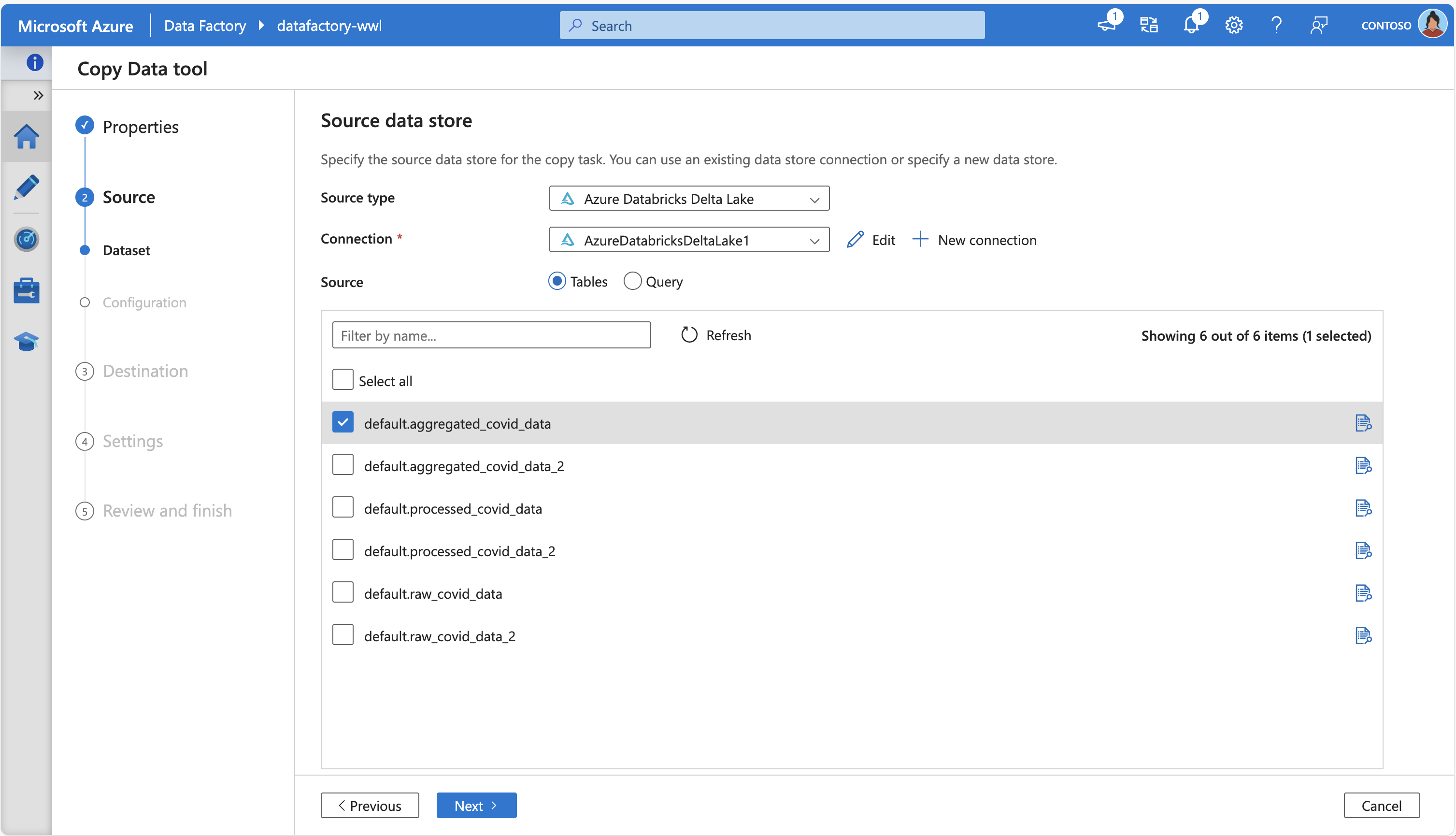
スクリーンショットには Azure Data Factory Copy Data Tool が表示されています。ツールは Azure Databricks Delta Lake に接続し、いくつかのソース テーブルを取得します。
さらに、ADF の マッピング データ フロー は、コード不要の ETL エクスペリエンスを提供します。Azure Storage で Delta 形式のデータをソースおよびシンクとして使用することができ、コードを記述せずに、マネージド Azure Integration Runtime 上で変換が可能です。
Azure Event Hubs と IoT Hubs
リアルタイム データ インジェストでは、Azure Event Hubs と IoT Hubs が最適な選択肢です。 これらにより、Azure Databricks 内にデータを直接ストリーミングできるようになるため、到着したデータを処理および分析できます。 リアルタイムのデータ インジェストと分析は、ライブ イベントの監視、またはモノのインターネット (IoT) のデバイス データ追跡などのシナリオで役立ちます。
Azure Event Hubs には、Databricks ランタイムの Structured Streaming Kafka コネクタと連携する Kafka 互換エンドポイントがあります。 Event Hubs インスタンスに接続し、トピックからイベントを使用するように、Lakeflow 宣言パイプラインを設定できます。