はじめに
機械学習では、トレーニング データに含まれる既知のラベルと特徴量の相関関係に基づいて、新しいデータの不明なラベルを予測するためにモデルがトレーニングされます。 使用するアルゴリズムによっては、モデルのトレーニング方法を構成するために "ハイパーパラメーター" を指定することが必要になる場合があります。
たとえば、"ロジスティック回帰" アルゴリズムでは、"正則化率" ハイパーパラメーターを使用してオーバーフィットを打ち消すことができます。また、畳み込みニューラル ネットワーク (CNN) のディープ ラーニング手法では、トレーニング中の重みの調整方法を制御する "学習率" や、各トレーニング バッチに含まれるデータ項目の数を決定する "バッチ サイズ" などのハイパーパラメーターを使用します。
注意
機械学習は固有の用語を持つ学術分野です。 データ サイエンティストは、トレーニングの特長から決定された値を "パラメーター" と呼んでいます。したがって、トレーニング動作の構成に使用されるが、トレーニング データから派生したものでは "ない" 値には別の用語が必要です。そのため、"ハイパーパラメーター" という用語が使用されます。
ハイパーパラメーター値を選択すると、結果として得られるモデルに大きな影響が生じる可能性があります。そのため、特定のデータと予測パフォーマンス目標に最適な値を選択することが重要になります。
ハイパーパラメーターを調整する
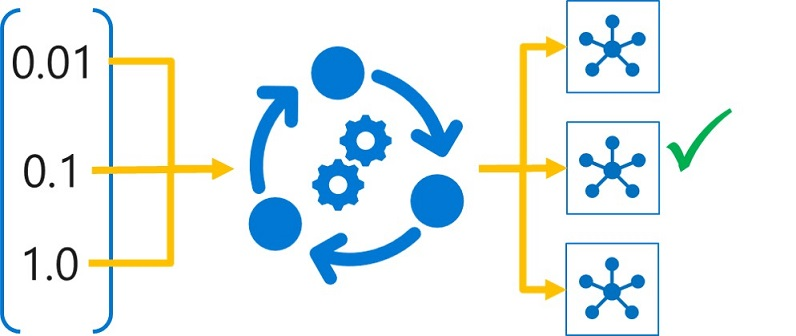
ハイパーパラメーターの調整は、同じアルゴリズムとトレーニング データを使用し、ハイパーパラメーターの値が異なる複数のモデルをトレーニングすることで実現します。 次に、各トレーニング実行の結果として得られるモデルを評価して、最適化するパフォーマンス メトリック ("正確性" など) を決定し、最適なモデルを選択します。
Azure Machine Learning では、スイープ ジョブとしてスクリプトを送信することでハイパーパラメーターを調整できます。 スイープ ジョブにより、テスト対象のハイパーパラメーターの組み合わせごとに 1 つの試行が実行されます。 各試行では、パラメーター化されたハイパーパラメーター値を指定したトレーニング スクリプトを使ってモデルをトレーニングし、トレーニング済みモデルによって達成されたターゲット パフォーマンス メトリックをログに記録します。
学習の目的
このモジュールでは、次の方法を学習します。
- ハイパーパラメーター検索空間を定義します。
- ハイパーパラメーターのサンプリングを構成します。
- 早期終了ポリシーを選択します。
- スイープ ジョブを実行します。