HDInsight Interactive Query はいつ使用すべきか?
あなたはビジネス アナリストとして、ソリューションを構築するために作成する HDInsight クラスターの最適な種類を判断する必要があります。 Interactive Query クラスターでは、多くの機能と相互運用性オプションが提供されます。これは、特に SQL に慣れているビジネス アナリストに役立ちます。 これは、ビジネス インテリジェンス ツールを操作し、高速な対話型クエリを必要とするユーザーに最適です。 さまざまなファイル形式、コンカレンシー、および原子性、一貫性、分離性、持続性 (ACID) トランザクションのサポートなど、利点は他にもあります。 データの行と列レベルの詳細な制御のための Apache Ranger との統合は言うまでもありません。
注意
このモジュールの内容は、Hive LLAP ともいう、Hive 3.1 および LLAP を使用する、HDInsight 4.0 用に作成された対話型クエリ クラスターに関連しています。
クエリの準備ができている大規模なデータ セットがある
対話型クエリ クラスターは、そのまま、あるいは最小限の変換でクエリを実行できる、大規模なデータ セットに最適です。 データに対してさまざまなクエリを実行し、すぐに応答する必要がある場合があります。 対話型クエリ クラスターは、実行時間の長いバッチ計算を実行するために最適化されていません。 対話型クエリでは、次のファイル形式がサポートされます: ORC、Parquet、CSV、Avro、JSON、text、tsv。
SQL に似た機能が必要である
Azure Storage と Azure Data Lake Storage にあるビッグ データに対して対話型およびアドホックの 1 秒未満の待機時間クエリを実行する必要があり、SQL に似たエクスペリエンスを希望する場合は、Azure HDInsight 対話型クエリ クラスターをお勧めします。 ビジネス アナリストとして、あなたは SQL テーブルを熟知しており、SQL を使用してクエリを作成しています。 Apache Hadoop は、ビッグ データ分析を実行するための強力なツールです。 Java プログラミングのスキルを最近あまり使用していない場合は、Apache Hadoop での MapReduce フレームワークとその Java API の使用が妨げになる場合があります。 この場合、HDInsight Interactive Query がより適しています。これは Apache Hadoop 上に構築されているものの、SQL の経験があれば誰でもより簡単に使用できるためです。 対話型クエリでは、SQL に似た Hive テーブルを使用してデータを処理し、HiveQL という SQL に似たクエリ言語を使ってデータに対してクエリを実行します。 Hive の使用は、Apache Hadoop で MapReduce を使ってデータを処理するよりも複雑ではありません。 Hive では、会社にソリューションをより迅速かつ効率的にロールアウトできます。
インテリジェント キャッシュを使用する高速対話型クエリ
対話型クエリ クラスターではインテリジェント キャッシュ手法を使用して、ダイナミック RAM、ローカル クラスター ノード SSD、および Azure Blob や Azure Data Lake Storage などのリモート ストレージ システム全体でデータを階層化し、ビッグ データに対する対話型で高速なクエリ結果を実現します。 高度なキャッシュ手法の 1 つの良い例は、動的テキスト キャッシュです。これにより、CSV データが最適化されたメモリ内形式に変換されるため、キャッシュが動的になり、クエリでキャッシュされるデータが決定されます。 この機能は、最初にデータを読み込んで変換する必要がないことを意味します。 データを元の形式で Azure Storage にアップロードして、クエリを開始することができます。 また、2 回目の実行時にクエリのパフォーマンスが向上することも意味します。 初めてクエリが実行されるときに、Azure Storage または Azure Data Lake Gen2 のビジネス データ ストレージ層からデータが読み取られます。 その後、データは、クラスター内の共有メモリ内キャッシュにキャッシュされます。 次にクエリが実行されるときに、データは単に共有メモリ内キャッシュから取得され、リモート ストレージ層からデータを取得しないことで時間を節約できます。
一般的なツールを使用してクエリを実行する
対話型クエリでは、Microsoft Power BI や Tableau などの使い慣れた BI ツールを使用して、ビッグ データを簡単に操作できます。 ビッグ データ分析では、エンド ユーザーが分析システムから十分な価値を得られないことに組織の懸念が高まっています。これは、多くの場合、難しすぎる、また分析を実行するために使い慣れていない、習得が困難なツールを使用する必要があるためです。 HDInsight 対話型クエリでは、データから分析情報を得るために新しいユーザー トレーニングを必要としないか、最小限に抑えることで、この問題に対処します。 ユーザーは、既に使用しているツールで SQL に似た HiveQL クエリを書き込むことができます。 これらのツールには、Visual Studio Code、Power BI、Apache Zeppelin、Visual Studio、Ambari Hive View、Beeline、Data Analytics Studio、Hive ODBC があります。 Hive コンソール、Templeton、Azure クラシック CLI、または Azure PowerShell を使用して、対話型クエリ クラスターでクエリを実行することはできません。
トランザクションの一貫性とコンカレンシーが必要である
詳細なリソース管理、プリエンプションおよびクエリとユーザー間でのキャッシュ データの共有の導入により、Interactive Query では同時実行ユーザーを簡単にサポートできます。 HDInsight では、共有 Azure ストレージでの複数のクラスターの作成がサポートされます。 Hive メタストアは、高度なコンカレンシーを実現するのに役立ちます。 クラスター ノードをさらに追加するか、あるいは同じ基になるデータとメタデータを指すクラスターをさらに追加することで、コンカレンシーをスケーリングすることができます。 対話型クリでは、ACID (原子性、一貫性、分離性、持続性) であるデータベース トランザクションもサポートされます。 ACID トランザクションでは、複数の操作が含まれている場合でも、トランザクションが 1 つの単位に含まれることが保証されます。 したがって、トランザクション内のいずれかの操作が失敗した場合、操作全体をロールバックでき、これにより、データの一貫性と正確性が維持されます。
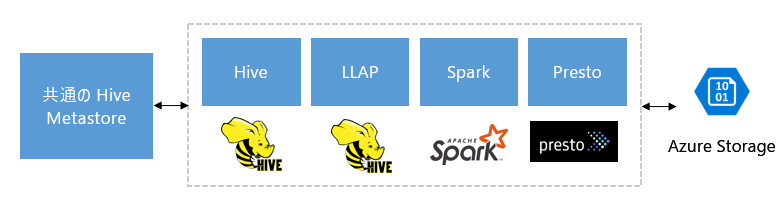
Spark、Hive、Presto、およびその他のビッグ データ エンジンを補完するように構築されている
HDInsight 対話型クエリは、Apache Spark、Hive、Presto などの一般的なビッグ データ エンジンで適切に動作するように設計されています。 この種のクエリは、ユーザーが分析を行うためにこれらのツールのいずれかを選択できるため、特に便利です。 HDInsight の外部テーブル用の共有データとメタデータ アーキテクチャを使用すると、ユーザーは同じ基になるデータとメタデータを指す同じまたは異なるエンジンで複数のクラスターを作成できます。 この機能は、分析のための 1 つのテクノロジによって制限されなくなるため、強力な概念です。