演習 - Azure Notebooks を作成してデータをインポートする
最初に、新しい Azure ノートブックを作成します。 Azure ノートブックは、関連するノートブックをグループ化することが主な目的である、プロジェクトに含まれています。 このユニットでは、新しいプロジェクトを作成してから、その中にノートブックを作成します。
ブラウザーで https://notebooks.azure.com に移動します
Microsoft アカウントを使用してサインインします。
ページの上部にあるメニューの [ マイ プロジェクト ] をクリックします。
[マイ プロジェクト] ページの上部にある [ + 新しい プロジェクト] ボタンをクリックします。
"ML Notebooks" または同様の名前の新しいプロジェクトを作成します。 必要に応じて、[パブリック] ボックスをオフにしてもかまいませんが、プロジェクトをパブリックにすることで、その中のノートブックを、リンク、ソーシャルメディア、または電子メールを介して他のユーザーと共有できます。 どちらにすればよいかわからない場合は、プロジェクトを後で簡単にパブリックまたはプライベートに変更することができます。
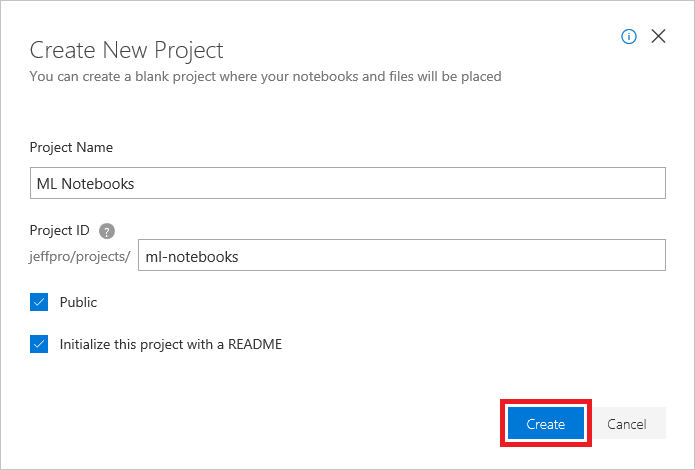
プロジェクトの作成
[ + 新規 ] をクリックし、メニューから [ノートブック ] を選択して、プロジェクトにノートブックを追加します。
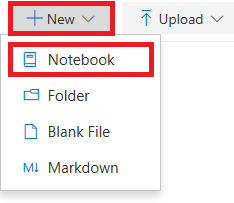
プロジェクトへのノートブックの追加
ノートブックに "On-Time Flight Arrivals.ipynb" などの名前を付け、言語として Python 3.6 を選択します。 これにより、Python コードを実行するための Python 3.6 カーネルを使用したノートブックが作成されます。 Azure ノートブックの長所の 1 つは、選択するカーネルによってさまざまな言語を使用できることです。
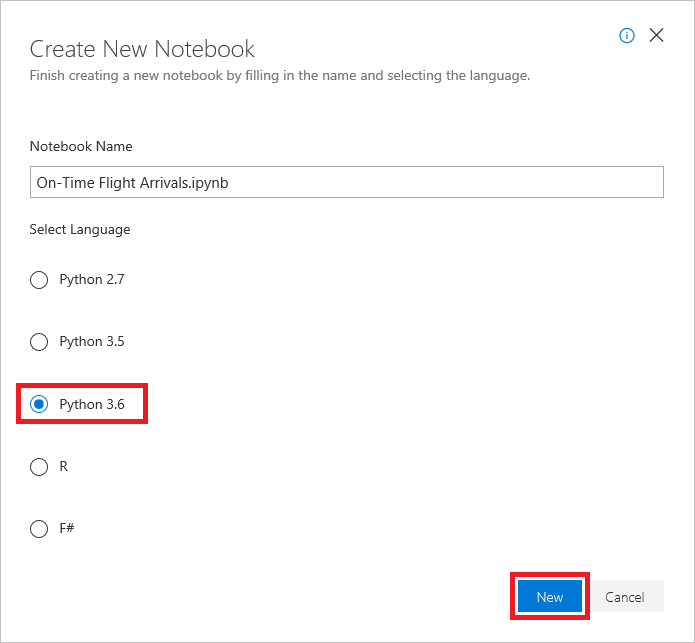
ノートブックの作成
興味がある場合は、 .ipynb ファイル名拡張子は "IPython Notebook" の略です。Jupyter ノートブックは、もともと IPython (対話型 Python) ノートブックと呼ばれ、プログラミング言語として Python のみをサポートしていました。 Jupyter という名前は、Jupyter でサポートされるコア プログラミング言語である Julia、Python、R を組み合わせたものです。
ノートブックをクリックして、編集のために開きます。
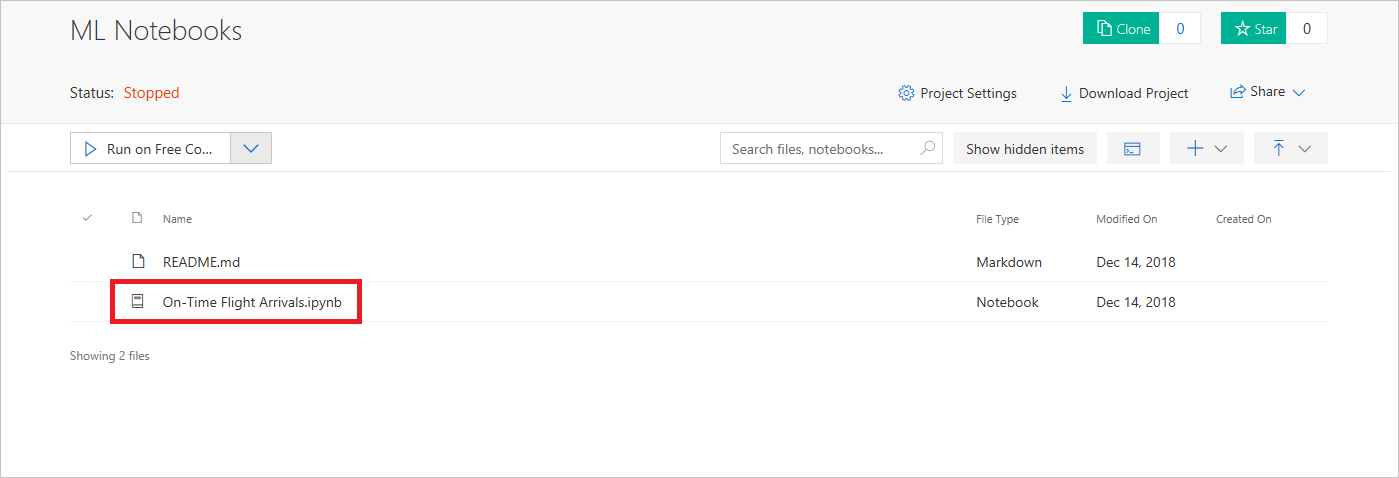
ノートブックを開く
Azure Notebooks を使用するときに、追加のプロジェクトとノートブックを作成できます。 ノートブックを最初から作成することも、既存のノートブックをアップロードすることもできます。
Jupyter ノートブックは非常にインタラクティブであり、これに実行可能なコードを含めることができるため、データを操作し、そこから予測モデルを構築するための完璧なプラットフォームが提供されます。
ノートブックの最初のセルに次のコマンドを入力します。
!curl https://topics.blob.core.windows.net/public/FlightData.csv -o flightdata.csvヒント
curlは Bash コマンドです。 Jupyter ノートブックで Bash コマンドを実行できます。その場合、前に感嘆符を付けます。 このコマンドは、Azure BLOB ストレージから CSV ファイルをダウンロードし、 flightdata.csv名を使用して保存します。[ 実行 ] ボタンをクリックして、
curlコマンドを実行します。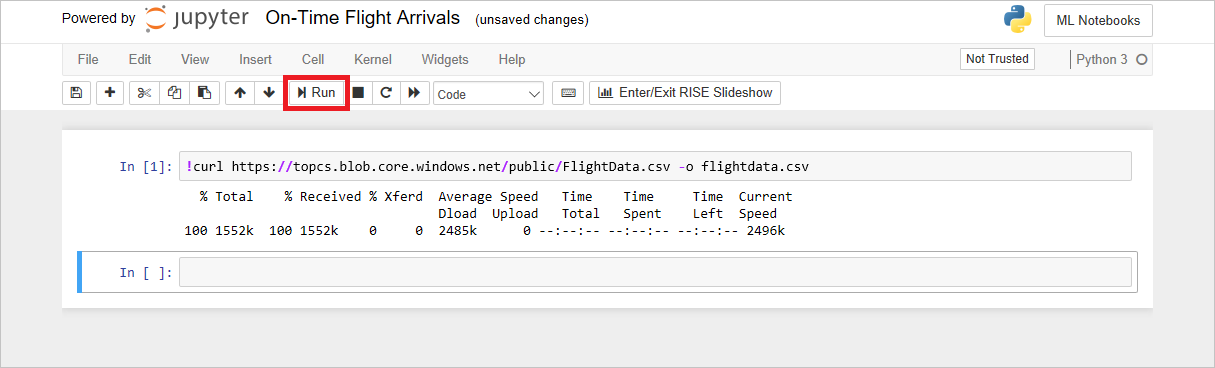
データセットのインポート
ノートブックの 2 番目のセルで、次の Python コードを入力して flightdata.csv読み込み、そこから Pandas DataFrame を 作成し、最初の 5 行を表示します。
import pandas as pd df = pd.read_csv('flightdata.csv') df.head()[ 実行 ] ボタンをクリックしてコードを実行します。 出力が次のようになっていることを確認します。
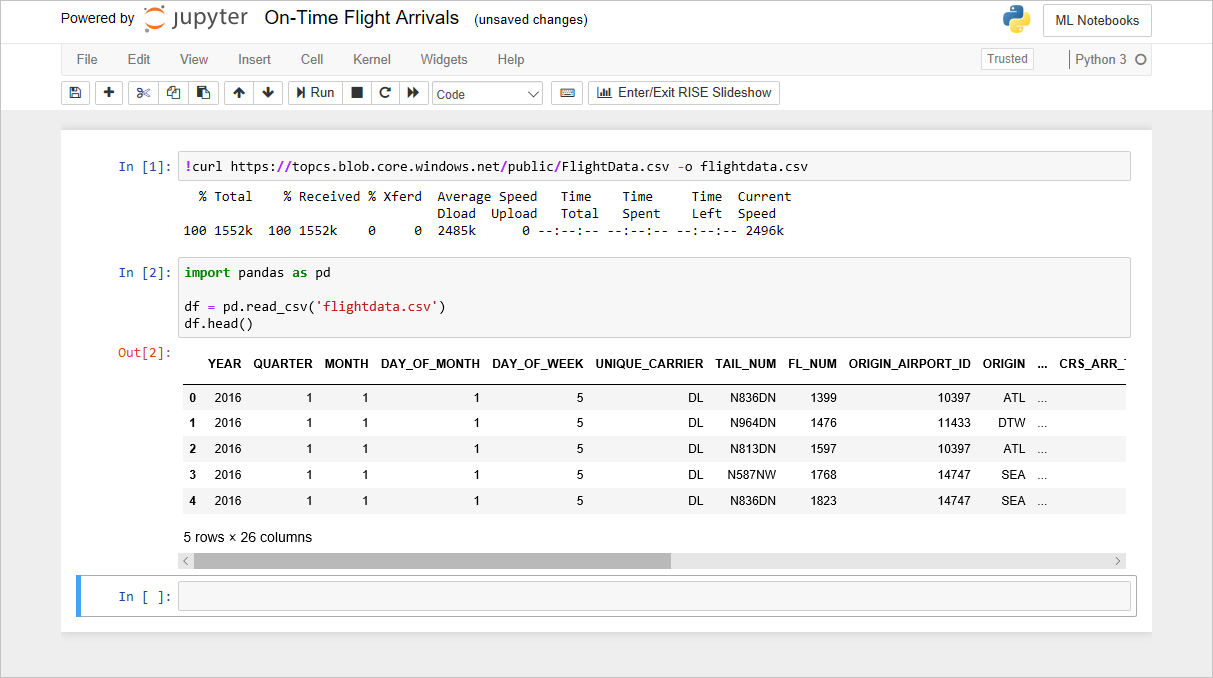
データセットの読み込み
作成した DataFrame には、米国の大手航空会社の到着時刻情報が含まれています。 11,000 個を超える行と 26 個の列があります (DataFrame の ヘッド 関数は最初の 5 行のみを返すので、出力には "5 行" と表示されます)。各行は 1 つのフライトを表し、出発地、目的地、スケジュールされた出発時刻、フライトが定刻または遅れて到着したかどうかなどの情報が含まれています。 データについては、このモジュールのもう少し後でより詳しく見ていきます。
File ->Save and Checkpoint コマンドを使用してノートブックを保存します。
水平スクロール バーを使用して左右にスクロールし、データセット内のすべての列を表示します。 データセットにはどれくらいの数の列が含まれるのでしょうか。 各列名から、その列が何を表しているのかを推測できますか?