Azure Site Recovery の概要
Azure Site Recovery は、システムの障害からの復旧を支援するだけのツールではありません。 Azure Site Recovery では、プライマリ サイトとセカンダリ サイトの間でワークロードが複製されます。 また、Site Recovery を使って、オンプレミスのインフラストラクチャから Azure に VM を移行することもできます。
たとえば、地震からワークロードを保護するための最初の作業は、企業の現在の事業継続とディザスター リカバリー (BCDR) プランを確認することです。 保護が必要なシステムの復旧目標と範囲を明らかにする必要があります。
このユニットでは、Azure Site Recovery によってどのようにこれらの目標が達成され、障害発生時にリソースのフェールオーバーと復旧が可能になるのかを調べます。
事業継続とディザスター リカバリー
サービスが失われると、スタッフやユーザーが中断される可能性があります。 システムを利用できない 1 秒ごとに、会社の収益が失われる可能性があります。 また、提供するサービスの可用性に関する契約を破った場合には、会社に罰金が科せられる可能性もあります。
BCDR 計画は、企業が作成する正式なドキュメントであり、災害や大規模な停止が発生したときに実行する必要がある範囲とアクションを記述します。 各停止は、それ自体の価値で評価されます。 たとえば、データセンター全体で停電が発生すると、BCDR 計画が実行されます。
この例のシナリオでは、地震が発生し、通信回線が損傷したため、データセンターは役に立たなくなり、修復が必要になりました。 この規模の障害では、サービスが数時間ではなく数日停止する可能性があるため、サービスをオンラインに戻すには完全な BCDR プランを実行する必要があります。
BCDR プランの一部として、アプリケーションの目標復旧時間 (RTO) と目標復旧時点 (RPO) を明らかにします。 これら 2 つの目的はどちらも、特定のサービスがなくてもビジネスを遂行できる最大許容時間と、データ復旧プロセスはどのようなものにする必要があるかを特定するのに役立ちます。 それぞれについて詳しく見てみましょう。
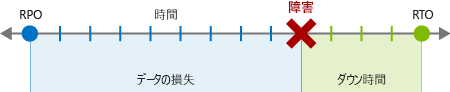
目標復旧時間
RTO とは、障害発生後、継続性の中断による許容できない結果を回避するために、通常のサービスを復元するまで、ビジネスを維持できる最大時間を示す指標です。 RTO が 12 時間であるとすると、ビジネス コア サービスが機能しなくても、業務を 12 時間継続できることを意味します。 ダウンタイムが長くなると、ビジネスは深刻な被害を受ける可能性があります。
目標復旧時点
RPO は、障害発生後に許容できるデータ損失の最大量の測定値です。 会社では、通常、24 時間ごとや 12 時間ごと、さらにはリアルタイムでバックアップを行うことができます。 障害が発生した場合は、常にデータがある程度失われます。
たとえば、バックアップが午前 0 時に 24 時間ごとに行われている場合、午前 9 時に障害が発生すると、9 時間分のデータが失われます。 会社の RPO が 12 時間であれば、9 時間しか経っていないので問題ありません。 RPO が 4 時間の場合は、問題になり、ビジネスに損害が生じる可能性があります。
Azure Site Recovery とは
Azure Site Recovery は、プライマリ サイトからセカンダリ サイトにワークロードをレプリケートできるので、BCDR 計画に役に立ちます。 プライマリ サイトで問題が発生した場合、Site Recovery を自動的に起動して、保護されている仮想マシンを別の場所にレプリケートすることができます。 フェールオーバーは、オンプレミスから Azure に対して、またはある Azure リージョンから別のリージョンに対して行うことができます。
Azure Site Recovery の注目すべき機能を次に示します。
- 中央管理: レプリケーションの設定と管理およびフェールオーバーとフェールバックの呼び出しをすべて、Azure portal 内から実行できます。
- オンプレミスの仮想マシンのレプリケーション: 必要に応じて、オンプレミスの仮想マシンを Azure にレプリケートすることも、オンプレミスのセカンダリ データセンターにレプリケートすることもできます。
- Azure 仮想マシンのレプリケーション: Azure の仮想マシンを、あるリージョンから別のリージョンにレプリケートできます。
- フェールオーバー中のアプリの整合性: 復旧ポイントとアプリケーション整合性スナップショットを使用すると、仮想マシンはレプリケーションの間常に整合性のある状態に維持されます。
- 柔軟なフェールオーバー: フェールオーバーは、テストとしてオンデマンドで実行することも、実際の障害発生時にトリガーすることもできます。 テストを実行して、ライブ サービスを中断せずにディザスター リカバリー シナリオをシミュレートすることができます。
- ネットワーク統合: Site Recovery では、レプリケーションおよびディザスター リカバリー シナリオ時にネットワーク管理の管理を行うことができます。 仮想マシンが新しい場所で動作できるように、予約済み IP アドレスとロード バランサーが含まれています。
Azure Site Recovery をセットアップする

Azure Site Recovery を有効にするには、いくつかのコンポーネントをセットアップする必要があります。
- ネットワーク: レプリケートされた仮想マシンで使用される、有効な Azure 仮想ネットワークが必要です。
- Recovery Services コンテナー: フェールオーバーの実行時に移行された VM が格納される Azure サブスクリプション内のコンテナーです。 コンテナーには、レプリケーション ポリシーと、レプリケーションおよびフェールオーバーのソースとターゲットの場所も含まれます。
- 資格情報: Azure に使用する資格情報には、Site Recovery が接続されている VM とストレージの両方を変更するためのアクセス許可があるように、仮想マシン共同作成者ロールと Site Recovery 共同作成者ロールが必要です。
- 構成サーバー: オンプレミスの VMware サーバーは、フェールオーバーおよびレプリケーション プロセス中にいくつかの役割を果たします。 それは、簡単にデプロイできるように、Azure portal からオープン仮想マシン アプライアンス (OVA) として取得されます。 構成サーバーには、次のものが含まれます。
- プロセス サーバー: このサーバーは、レプリケーション トラフィックに対するゲートウェイとして機能します。 トラフィックはキャッシュ、圧縮、および暗号化された後、WAN 経由で Azure に送信されます。 また、プロセス サーバーでは、フェールオーバーおよびレプリケーションの対象となるすべての物理マシンと仮想マシンにモビリティ サービスがインストールされます。
- マスター ターゲット サーバー: このコンピューターでは、Azure からのフェールバックの間にレプリケーション プロセスが処理されます。
重要
Azure からオンプレミス環境にフェールバックするには、Azure に物理マシンをレプリケートするだけの場合でも、構成サーバーが含まれる VMware vCenter を使用できるようにする必要があります。 物理サーバーにはフェールバックできません。
レプリケーション プロセス
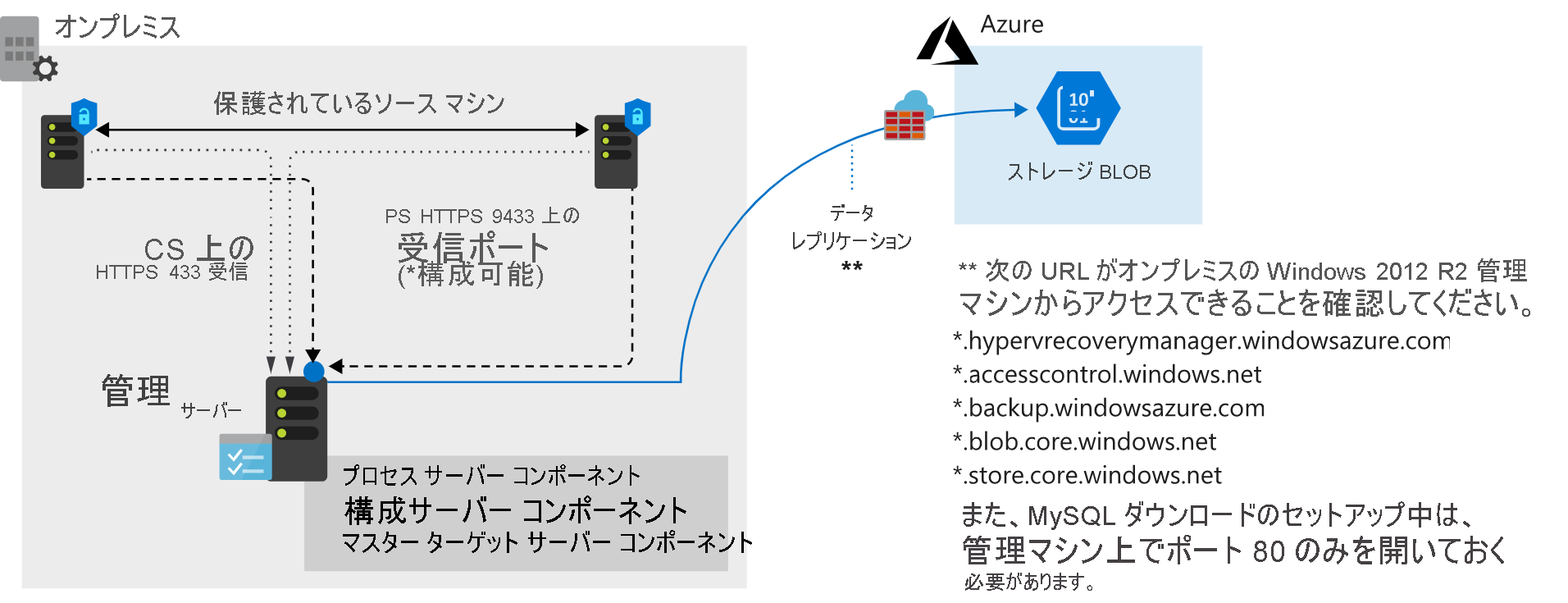
前提条件のタスクがセットアップされたら、マシンのレプリケーションを開始できます。 使用しているレプリケーション ポリシーに従って、レプリケートが行われます。 最初のコピーの初期ステージの間に、サーバー データが Azure Storage にレプリケートされます。 初期レプリケーションが完了した後、2 回目のレプリケーションが行われます。 今度は、仮想マシンへの差分変更が Azure にレプリケートされます。
フェールオーバーをテストおよび監視する
ディザスター リカバリー用に環境をセットアップした後、それをテストして、正しく構成されており、すべてが期待どおりに動作することを確認します。 構成をテストするには、分離された VM でディザスター リカバリーの訓練を行います。 ライブ サービスが中断されないように、テストには分離されたネットワークを使うのがベスト プラクティスです。
復旧の訓練を試みるときの最初のタスクは、Azure portal の [Protected Items](保護されているアイテム) セクションで、テスト用の仮想マシンのプロパティを確認することです。 最新の復旧ポイントが、[レプリケートされたアイテム] ウィンドウに表示されます。 [コンピューティングとネットワーク] セクションで、必要に応じて、仮想マシン名、リソース グループ、ターゲット サイズ、可用性セット、ディスクの設定を調整できます。
復旧訓練は、Azure portal の [設定]>[レプリケートされたアイテム] セクションから開始できます。 ターゲット仮想マシンを選択してから、最後に処理された復旧ポイントに対する [テスト フェールオーバー] メニュー項目を選択します。 同じメニューで Azure ネットワークを選択します。 復旧ジョブを開始するには、ネットワーク選択画面で [OK] を選択します。
復旧ジョブとレプリケートされた仮想マシンの状態には、Recovery Services コンテナーの [概要] セクションからアクセスします。 レプリケートされたアイテムの状態は次のとおりです。
- 正常: レプリケーションは正常に動作しています。
- 警告: レプリケーションに影響する可能性のある問題があります。
- 重大: 重大なレプリケーション エラーが検出されました。
すべてに問題がなければ、レプリケートされた VM の状態は [正常に実行されました] に設定されます。 テストが行われていない場合は、状態は [テストをお勧めします] に設定されます。 前回のテストから 6 か月以上経過している場合も、VM は [テストをお勧めします] に設定されます。