分類モデルを評価する
分類モデルのトレーニング精度は、扱ったことがない新しいデータを使用した場合にモデルがどの程度うまく働くかに比べて重要性がはるかに低くなります。 結局のところ、モデルをトレーニングして、実世界で見つかった新しいデータに対してそれらを使用できるようにします。 そのため、分類モデルのトレーニングが完了したら、扱ったことがない新しいデータのセットに対するパフォーマンスを評価します。
前のユニットでは、血糖値に基づいて患者が糖尿病かどうかを予測するモデルを作成しました。 ここで、トレーニング セットに含まれていなかったいくつかのデータに適用すると、次の予測が得られます。
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |
x は血糖値を示し、y は実際に糖尿病かどうかを示し、ŷ は糖尿病かどうかに関するモデルの予測を示していることを思い出してください。
正確だった予測の数を計算するだけでは、誤解が生じたり、単純すぎて現実に発生する誤りの種類を把握できなかったりすることがあります。 より詳細な情報を得るために、この結果を次のような "混同行列" という構造で図表化することができます。
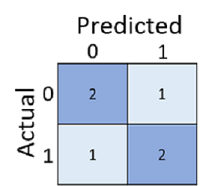
混同行列は、次のケースの合計数を示しています。
- モデルでは 0 と予測され、実際のラベルは 0 ("真陰性" (左上))
- モデルでは 1 と予測され、実際のラベルは 1 ("真陽性" (右下))
- モデルでは 0 と予測され、実際のラベルは 1 ("偽陰性" (左下))
- モデルでは 1 と予測され、実際のラベルは 0 ("偽陽性" (右上))
混同行列のセルは多くの場合、値が高くなるほど網掛けが濃くなるように網掛けされます。 これにより、左上から右下への強い斜めの傾向を簡単に見ることができ、予測値と実際の値が同じセルが強調して表示されています。
これらのコア値から、モデルの成績を評価するのに役立つその他のメトリックの範囲を計算できます。 例:
- 正確性: (TP+TN)/(TP+TN+FP+FN) - すべての予測のうち、正しかった数を示します。
- リコール: TP/(TP+FN) - "実際に" 陽性だったすべてのケースのうち、モデルが識別できた数を示します。
- 精度: TP/(TP+FP) - モデルにより陽性だと予測されたすべてのケースのうち、"実際に" 陽性だった数を示します。