さまざまな種類のクラスタリングを評価する
クラスタリング モデルのトレーニング
クラスタリングには複数のアルゴリズムを使用できます。 最もよく使用されるアルゴリズムの 1 つは K-Means クラスタリングです。これは、最も単純な形式では次の手順で構成されます。
- 特徴の値がベクトル化されて、n 次元の座標が定義されます (ここで、n は特徴の数です)。 花の例では、特徴が 2 つあります。すなわち、花びらの数と葉の数です。 そのため、特徴ベクトルには 2 つの座標があり、それを使用して、2 次元空間にデータ ポイントを概念的にプロットすることができます。
- 花をグループ化するために使用するクラスターの数を決定します (この値を k とします)。 たとえば、3 つのクラスターを作成するには、k 値に 3 を使用します。 その後、k 個のポイントがランダムな座標にプロットされます。 これらのポイントは各クラスターの中心点になるため、"重心" と呼ばれます。
- 各データ ポイント (この例では花) は、最も近い重心に割り当てられます。
- 各重心は、ポイントとの間の平均距離に基づいて、割り当てられたデータ ポイントの中心に移動されます。
- 重心が移動されると、データ ポイントが異なる重心に近くなる場合があるため、新しい最も近い重心に基づいて、データ ポイントがクラスターに再割り当てされます。
- クラスターが安定するまで、または事前に決定されている繰り返しの最大数に達するまで、重心の移動とクラスターの再割り当ての手順が繰り返されます。
次のアニメーションは、このプロセスを示したものです。

階層クラスタリング
階層クラスタリングは、クラスタリング アルゴリズムのもう 1 つの種類です。このクラスタリングでは、クラスター自体がより大きなグループに属し、そのグループがさらに大きなグループに属すというような構造になります。 その結果、データ ポイントは、精度が異なるクラスター (多数のとても小さく正確なグループ、または少数の大きなグループ) になる可能性があります。
たとえば、単語の意味にクラスタリングを適用する場合、感情に固有の形容詞 ("怒った" や "幸せな" など) を含むグループが得られるかもしれません。 このグループは、人間に関連するすべての形容詞 ('幸せな'、'ハンサムな'、'若い') を含むグループに属し、そのグループはすべての形容詞 ('幸せな'、'緑の'、'ハンサムな'、'硬い'" など) を含むさらに上位のグループに属します。
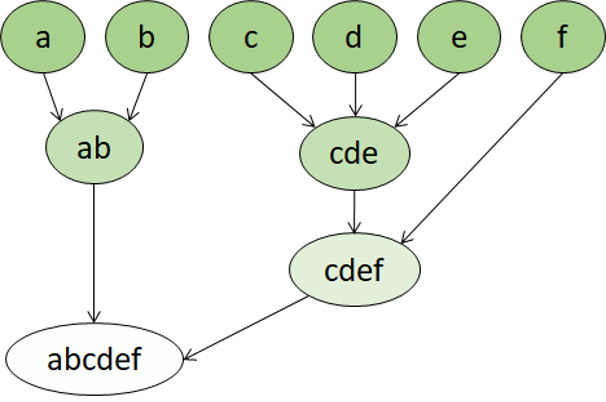
階層クラスタリングは、データをグループに分割するだけでなく、これらのグループ間の関係を理解するのにも役立ちます。 階層クラスタリングの主な利点は、クラスターの数を事前に定義する必要がないことです。 また、非階層的アプローチよりも解釈しやすい結果をもたらす場合があります。 主な欠点は、これらのアプローチでは、計算にかかる時間が単純なアプローチよりも長くなる可能性があり、大規模なデータセットには適さない場合があることです。