ディープ ニューラル ネットワークの概念
ディープ ニューラル ネットワーク (DNN) 機械学習モデルのトレーニング方法を調べる前に、何を達成しようとしているのかを考えてみましょう。 機械学習は、特定の観測の一部の "特徴量" に基づいて "ラベル" を予測することに関係しています。 簡単に言うと、機械学習モデルは、x (特徴量) から y (ラベル) を計算する関数 f(x)=y です。
簡単な分類の例
たとえば、ペンギンの測定値で構成される観測を考えます。

具体的には、測定値は次のとおりです。
- ペンギンのくちばしの長さ。
- ペンギンのくちばしの深さ。
- ペンギンのひれ足の長さ。
- ペンギンの体重。
この場合、特徴量 (x) は、4 つの値のベクトルになります (数学的には、x=[x1,x2,x3,x4])。
予測しようとしているラベル (y) がペンギンの種であり、次の 3 つの種が存在すると考えられるとします。
- アデリーペンギン
- "ジェンツーペンギン"
- "ヒゲペンギン"
これは "分類" の問題の例であり、機械学習モデルによって、観測対象が属する最も可能性の高いクラスを予測する必要があります。 分類モデルでは、各クラスの確率で構成されるラベルを予測することによってこれを実現します。 言い換えると、y は、可能性があるクラスごとに 1 つ、合計 3 つの確率値のベクトルです (y=[P(0),P(1),P(2)])。
実際のラベルが既にわかっている観測を使用して、機械学習モデルをトレーニングします。 たとえば、"アデリーペンギン" に対して次のような特徴量測定値があるとします。
x=[37.3, 16.8, 19.2, 30.0]
これは "アデリーペンギン" (クラス 0) の例であることがわかっているので、完全な分類関数は、クラス 0 に対して 100% の確率、クラス 1 と 2 に対して 0% の確率を示すラベルになります。
y=[1, 0, 0]
ディープ ニューラル ネットワーク モデル
では、ディープ ラーニングを使用して、ペンギン分類モデルの分類モデルを作成するにはどうすればよいでしょうか。 例を見てみましょう。
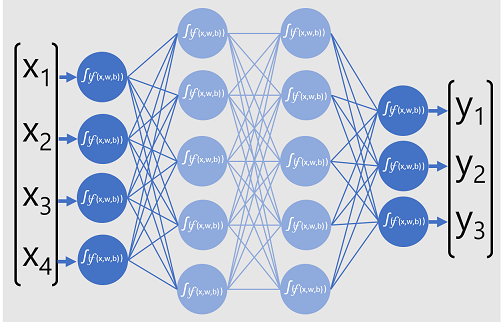
分類器のディープ ニューラル ネットワーク モデルは、人工ニューロンの複数の層で構成されています。 この例では、次のような 4 つの層があります。
- 期待される入力値 (x) ごとにニューロンを含む "入力" 層。
- 2 つのいわゆる "非表示" の層。それぞれに 5 つのニューロンが含まれています。
- モデルによって予測されるクラスの確率 (y) 値ごとに 1 つ、合計 3 つのニューロンを含む "出力" 層。
ネットワークの多層アーキテクチャにより、この種のモデルは "多層パーセプトロン" と呼ばれることもあります。 さらに、入力層と非表示層のすべてのニューロンが後続の層のすべてのニューロンに接続されていることに注意してください。これは、"完全に接続されたネットワーク" の例です。
このようなモデルを作成する場合は、モデルが処理する特徴量の数をサポートする入力層と、生成される出力の数を反映する出力層を定義する必要があります。 含める非表示層の数と、それぞれに含まれるニューロンの数を決めることができます。ただし、これらの層の入力値と出力値を制御することはできません。これらは、モデルのトレーニング プロセスによって決定されます。
ディープ ニューラル ネットワークのトレーニング
ディープ ニューラル ネットワークのトレーニング プロセスは、"エポック" と呼ばれる複数の反復で構成されています。 最初のエポックでは、まず、重み (w) とバイアス b の値に対してランダムな初期化値を割り当てます。 その後のプロセスは次のようになります。
- 既知のラベル値を持つデータ観測の特徴量が入力層に送信されます。 一般に、これらの観測は "バッチ" ("ミニバッチ" と呼ばれることもあります) にグループ化されます。
- 次に、ニューロンで関数が適用され、活性化した場合は、出力層が予測を生成するまで結果が次の層に渡されます。
- 予測は実際の既知の値と比較され、予測値と真の値の間の差異の量 ("損失" と呼ばれます) が計算されます。
- 結果に基づいて、損失を減らすために重みとバイアスの修正された値が計算されます。これらの調整は、ネットワーク層のニューロンに "逆伝播" されます。
- 次のエポックでは、修正された重みとバイアスの値を使用してバッチ トレーニングの前方パスを繰り返します。うまくいけば、損失を減らすことで、モデルの精度を向上させることができます。
注意
トレーニング特徴量をバッチとして処理し、複数の観測を、重みとバイアスのベクトルを含む特徴量の行列として同時に処理することで、トレーニング プロセスの効率を向上させることができます。 行列とベクトルを操作する線形代数関数は、3D グラフィックス処理の特色でもあります。これは、グラフィック処理ユニット (GPU) が搭載されたコンピューターが中央処理装置 (CPU) のみのコンピューターよりもディープ ラーニング モデルのトレーニングのパフォーマンスが大幅に向上する理由です。
損失関数と逆伝播の詳細
前述のディープ ラーニングのトレーニング プロセスの説明では、モデルによる損失が計算され、重みとバイアスの値の調整に使用されることを示しました。 そのしくみは
損失の計算
トレーニング プロセスを通じて渡されるサンプルの 1 つに、"アデリーペンギン" (クラス 0) の特徴量が含まれているとします。 ネットワークからの正しい出力は [1, 0, 0] になります。 ここで、ネットワークによって生成された出力が [0.4, 0.3, 0.3] であるとします。 これらを比較すると、各要素の絶対分散 (つまり、各要素の予測値が本来の値からどのくらい離れているか) を [0.6, 0.3, 0.3] と計算できます。
実際には、複数の観測を処理するので、通常は分散を集計します。たとえば、個々の分散値を 2 乗して平均を計算することにより、0.18 のような 1 つの平均損失値が算出されます。
オプティマイザー
ここで、巧妙な手法があります。 損失は関数を使用して計算されます。この関数は、ネットワークの最後の層の結果を操作しますが、これも関数です。 ネットワークの最後の層は、前の層の出力を操作しますが、これも関数です。 そのため、実質的には、入力層から損失計算までのモデル全体は、1 つの大きな入れ子になった関数に過ぎません。 関数には、次のような非常に役立つ特性がいくつかあります。
- 関数は、出力をそれぞれの変数と比較してプロットした線として概念化できます。
- 微分学を使用すると、変数について任意の点で関数の "微分係数" を計算できます。
まず、1 番目の特性を使用してみましょう。 関数の線をプロットして、個々の重みの値と損失の比較を示し、現在の重みの値が現在の損失の値と一致する点をその線にマークすることができます。
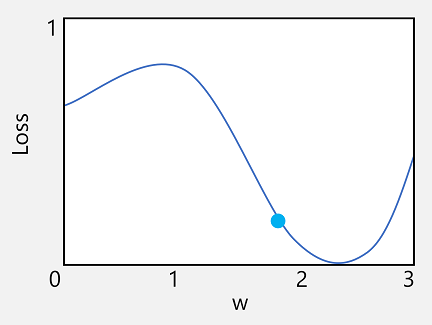
次に、関数の 2 番目の特性を適用します。 特定の点での関数の微分係数は、関数の出力 (この場合は損失) の傾き (または "勾配") が、関数の変数 (この場合は重みの値) に関して増加しているか減少しているかを示します。 微分係数が正の場合は関数が増加していることを示し、微分係数が負の場合は減少していることを示します。 この場合、現在の重みの値をプロットした点で、関数には下向きの勾配があります。 つまり、重みを上げると、損失を減らす効果が得られます。
ここでは、"オプティマイザー" を使用して、モデル内のすべての重み変数およびバイアス変数に対してこれと同じ手法を適用し、モデルの全体的な損失量を減らすために、調整する必要がある方向 (上下) を決定します。 一般的に使用される最適化アルゴリズムには、"確率的勾配降下法 (SGD)"、"適応学習率 (ADADELTA)"、"適応運動量推定 (Adam)" などがあります。これらはすべて、重みとバイアスを調整して損失を最小限に抑える方法を突き止めるように設計されています。
Learning rate (学習率)
次の疑問は、オプティマイザーは重みとバイアスの値をどれだけ調整する必要があるかということです。 重みの値のプロットを見るとわかるように、重みを少しだけ大きくすると、関数の線は下がります (損失が減少します)。しかしながら、大きくしすぎると関数の線は再び上昇するようになり、実際には損失が増加します。そのため、次のエポックの後には重みを下げる必要があることがわかります。
調整の大きさは、"学習率" と呼ばれるトレーニング用に設定したパラメーターによって制御されます。 学習率が低いと小さな調整が行われ (このため、損失を最小限に抑えるにはより多くのエポックが必要になる可能性があります)、学習率が高いと大きな調整が行われます (このため、最小値を見逃す可能性があります)。