畳み込みニューラル ネットワーク
ディープ ラーニング モデルはあらゆる種類の機械学習に使用できますが、画像など、数値の大きな配列で構成されるデータを処理する場合に特に便利です。 画像で動作する機械学習モデルは 、コンピューター ビジョンと呼ばれる領域人工知能の基盤であり、ディープ ラーニング技術は、近年この分野で驚くべき進歩を推進する役割を担っています。
この分野でのディープ ラーニングの成功の中心にあるのは、 畳み込みニューラル ネットワーク ( CNN) と呼ばれる一種のモデルです。 CNN は通常、画像から特徴を抽出し、それらの特徴を完全に接続されたニューラル ネットワークに供給して予測を生成することによって機能します。 ネットワーク内の特徴抽出レイヤーは、個々のピクセル値の膨大な配列から、ラベル予測をサポートする小さな特徴セットに特徴の数を減らす効果があります。
CNN 内の層
CNN は複数のレイヤーで構成され、それぞれが特徴の抽出やラベルの予測で特定のタスクを実行します。
畳み込み層
主なレイヤーの種類の 1 つは、画像内の重要な特徴を抽出する 畳み込み レイヤーです。 畳み込みレイヤーは、画像にフィルターを適用することによって機能します。 フィルターは、重み値の行列で構成される カーネル によって定義されます。
たとえば、3x3 フィルターは次のように定義できます。
1 -1 1
-1 0 -1
1 -1 1
画像は単なるピクセル値のマトリックスでもあります。 フィルターを適用するには、それを画像に "オーバーレイ" し、フィルター カーネルの下にある対応する画像ピクセル値の 重み付けされた合計 を計算します。 その後、画像と同じサイズの値の新しいマトリックスで、同等の 3x3 パッチの中央のセルに結果が割り当てられます。 たとえば、6 x 6 の画像に次のピクセル値があるとします。
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
画像の左上の 3x3 パッチにフィルターを適用すると、次のように動作します。
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
結果は、次のように新しいマトリックス内の対応するピクセル値に割り当てられます。
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
ここで、フィルターが移動します ("畳み込み")。通常は、"ステップ" サイズ 1 を使用し (右に 1 ピクセルずつ移動します)、次のピクセルの値が計算されます
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
これで、新しいマトリックスの次の値を入力できます。
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
このプロセスは、画像のすべての 3x3 パッチにフィルターを適用して、次のような値の新しいマトリックスを生成するまで繰り返されます。
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
フィルター カーネルのサイズのため、エッジのピクセルの値を計算することはできません。そのため、通常は パディング 値 (多くの場合 0) を適用します。
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
畳み込みの出力は通常、アクティブ化関数に渡されます。これは多くの場合、負の値が 0 に設定されることを保証する ReLU (Relu ) 関数です。
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
結果のマトリックスは、機械学習モデルのトレーニングに使用できる特徴値の 特徴マップ です。
注: フィーチャ マップ内の値はピクセルの最大値 (255) より大きくなる可能性があるため、フィーチャ マップを画像として視覚化する場合は、0 から 255 の間の特徴値を 正規化 する必要があります。
畳み込みプロセスを次のアニメーションに示します。

- 画像は畳み込み層に渡されます。 この場合、画像は単純な幾何学的形状です。
- 画像は、0 ~ 255 の値を持つピクセルの配列で構成されます (カラー 画像の場合、通常は赤、緑、青のチャネルの値を持つ 3 次元配列です)。
- 通常、フィルター カーネルはランダム重みで初期化されます (この例では、フィルターがピクセル値に与える影響を強調するために値を選択しましたが、実際の CNN では、通常、初期重みはランダムガウス分布から生成されます)。 このフィルターは、画像データからフィーチャ マップを抽出するために使用されます。
- フィルターは画像全体に結合され、各位置に対応するピクセル値を乗算した重みの合計を適用して特徴値を計算します。 負の値が 0 に設定されるように、修正された線形単位 (ReLU) アクティブ化関数が適用されます。
- 畳み込み後、フィーチャ マップには抽出された特徴値が含まれ、多くの場合、画像の主要な視覚的属性が強調されます。 この場合、フィーチャ マップは、画像内の三角形のエッジとコーナーを強調表示します。
通常、畳み込み層は複数のフィルター カーネルを適用します。 各フィルターによって異なるフィーチャ マップが生成され、すべてのフィーチャ マップがネットワークの次のレイヤーに渡されます。
プーリング層
画像から特徴の値を抽出した後、プール (またはダウンサンプリング) レイヤーを使用して、抽出された主要な特徴を区別しながら、特徴値の数を減らします。
プールの最も一般的な種類の 1 つは、画像にフィルターが適用される 最大プーリング であり、フィルター領域内の最大ピクセル値のみが保持されます。 たとえば、イメージの次のパッチに 2x2 プーリング カーネルを適用すると、結果 155 が生成されます。
0 0
0 155
2x2 プーリング フィルターの効果は、値の数を 4 から 1 に減らすことです。
畳み込みレイヤーと同様に、プール レイヤーはフィーチャ マップ全体にフィルターを適用することで機能します。 次のアニメーションは、イメージ マップの最大プーリングの例を示しています。

- 畳み込みレイヤーのフィルターによって抽出されたフィーチャ マップには、特徴値の配列が含まれています。
- プーリング カーネルは、機能値の数を減らすために使用されます。 この場合、カーネル サイズは 2x2 であるため、特徴値の 4 分の 1 の配列が生成されます。
- プーリング カーネルは、各位置で最も高いピクセル値のみを保持して、フィーチャ マップ全体に結合されます。
ドロップ層
CNNで最も困難な課題の一つは<...>オーバーフィッティングを回避することです。この場合、結果として得られたモデルはトレーニングデータに対して十分に機能しますが、トレーニングされていない新しいデータにうまく適用されません。 オーバーフィットを軽減するために使用できる手法の 1 つは、トレーニング プロセスによって特徴マップがランダムに除去 (または "ドロップ") するレイヤーを含める方法です。 これは直感に反しているように見えるかもしれませんが、モデルがトレーニング イメージに過度に依存することを学習しないようにする効果的な方法です。
オーバーフィットを軽減するために使用できるその他の手法としては、トレーニング イメージをランダムに反転、ミラーリング、傾斜させたりして、トレーニング エポックごとに異なるデータを生成できます。
レイヤーのフラット化
畳み込みレイヤーとプーリング レイヤーを使用して画像内の顕著な特徴を抽出した後、結果の特徴マップはピクセル値の多次元配列になります。 フラット化レイヤーは、フィーチャ マップを、完全に接続されたレイヤーへの入力として使用できる値のベクトルにフラット化するために使用されます。
完全に接続されたレイヤー
通常、CNN は完全に接続されたネットワークで終わり、1 つ以上の非表示レイヤーを介してフィーチャ値が入力レイヤーに渡され、出力レイヤーで予測値が生成されます。
基本的な CNN アーキテクチャは次のようになります。
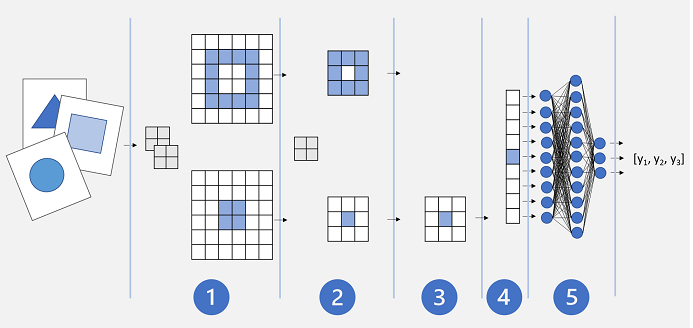
- 画像は畳み込みレイヤーにフィードされます。 この場合、2 つのフィルターがあるため、各画像は 2 つのフィーチャ マップを生成します。
- フィーチャ マップはプーリング レイヤーに渡され、2x2 プーリング カーネルによってフィーチャ マップのサイズが小さくなります。
- ドロップ レイヤーは、オーバーフィットを防ぐために、フィーチャ マップの一部をランダムにドロップします。
- フラット化レイヤーは、残りのフィーチャ マップ配列を受け取り、ベクターにフラット化します。
- ベクター要素は、完全に接続されたネットワークに供給され、予測が生成されます。 この場合、ネットワークは、考えられる 3 つの画像クラス (三角形、四角形、円) の確率を予測する分類モデルです。
CNN モデルのトレーニング
ディープ ニューラル ネットワークと同様に、CNN は複数のエポックにトレーニング データのバッチを渡し、各エポックで計算される損失に基づいて重みとバイアス値を調整することによってトレーニングされます。 CNN の場合、調整された重みの逆伝播には、畳み込み層で使用されるフィルター カーネルの重みと、完全に接続された層で使用される重みが含まれます。