回帰とは何でしょうか?
回帰は、観察対象の特徴と呼ばれる特徴を表すデータ内の変数と、予測しようとしている変数 (ラベル) の間にリレーションシップを確立することによって機能します。
先ほどの会社では、自転車をレンタルし、特定の日に予想されるレンタル数を予測したいと考えていました。 この場合、特徴には曜日、月などが含まれ、ラベルは自転車のレンタル数です。
モデルをトレーニングするには、特徴量とラベルの既知の値を含むデータ サンプルから始めます。この例では、日付、気象条件、自転車のレンタル数を含む履歴データが必要です。
次に、このデータ サンプルを以下の 2 つのサブセットに分割します。
- 特徴値と既知のラベル値の関係をカプセル化する関数を決定するアルゴリズムを適用する トレーニング データセット。
- モデルを使用してラベルの予測を生成し、実際の既知のラベル値と比較することで、モデルを評価するために使用できる 検証 データセットまたは テスト データセット。
既知のラベル値を持つ履歴データを使用してモデルをトレーニングすると、 回帰が教師あり 機械学習の例になります。
シンプルな例
ここでは、トレーニングと評価のプロセスがどのように機能するかを簡単に説明します。 たとえば、特徴の 1 つである 1 日の平均気温を使用して自転車のレンタル数のラベルを予測するようにシナリオを簡略化したとします。
最初の例では、1 日の平均気温の特徴量と自転車レンタル数のラベルの既知の値を含むいくつかのデータから始めます。
| 温度 | レンタル数 |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
| 82 | 156 |
| 54 | 114 |
| 62 | 129 |
次に、これらの観測値のうち 5 つを ランダムに 選択し、それらを使用して回帰モデルをトレーニングします。 「モデルのトレーニング」について話すとき、温度特徴 (x と呼びます) を使用してレンタル数 (y と呼びます) を計算できる関数 (数学方程式、f と呼びます) を見つけることです。 つまり、 f(x) = y という関数を定義する必要があります。
トレーニング データセットは次のようになります。
| x | y |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
まず、グラフに x と y のトレーニング値をプロットします。
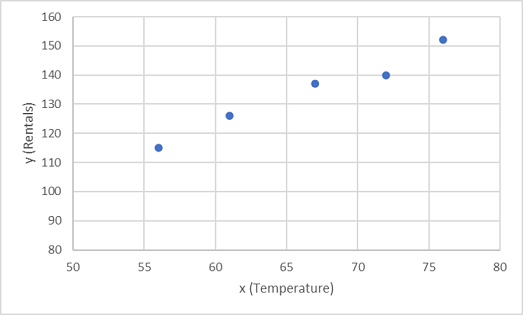
ここで、ランダムな変動を許しながらこれらの値を関数に適合させる必要があります。 プロットされた点がほぼ直線の対角線を形成していることがわかります。つまり、x と y の間には明らかな線形関係があるため、データ サンプルに最適な線形関数を見つける必要があります。 この関数を決定するために使用できるさまざまなアルゴリズムがあります。最終的には、次のようにプロットされた点からの全体的な差異が最小限となる直線を見つけます。
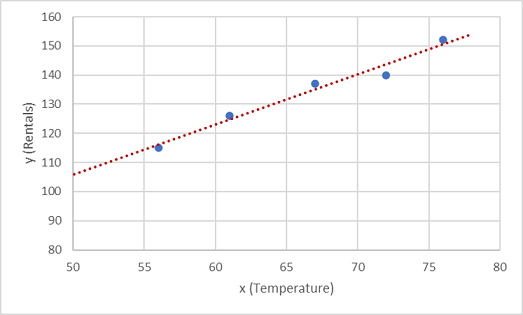
線は、任意の値 x で使用できる線形関数を表し、線の 傾き とその 切片 ( x が 0 の場合に線が y 軸を横切る位置) を適用して y を計算できます。 この場合、線を左に拡張すると、x が 0、y が約 20、線の傾きが x の単位ごとに右に移動するように、y が約 1.7 増加することがわかります。 したがって、 f 関数は 20 + 1.7x として計算できます。
予測関数を定義したので、それを使用して、保持している検証データのラベルを予測し、予測値 (通常はシンボル ŷ または "y-hat" で示します) を実際の既知の y 値と比較できます。
| x | y | ŷ |
|---|---|---|
| 82 | 156 | 159.4 |
| 54 | 114 | 111.8 |
| 62 | 129 | 125.4 |
プロットで y と ŷ の値を比較してみましょう。
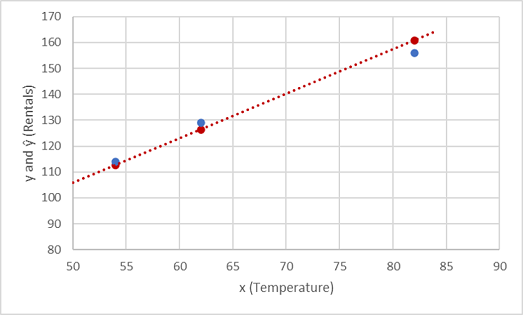
関数線上のプロットされた点は、関数によって計算された予測された ŷ 値であり、他のプロットされた点は実際の y 値です。
予測値と実際の値の間の分散を測定するにはさまざまな方法があります。これらのメトリックを使用すると、モデルの予測精度を評価できます。
注
機械学習は統計学と数学に基づいているため、統計学者と数学者 (したがって、データ サイエンティスト) が使用する特定の用語に注意することが重要です。 予測ラベル値と実際のラベル値の差は、誤差の尺度と考えることができます。 ただし、現実には、"実際の" 値はサンプルの観測値に基づいています (これ自体がランダムな分散を持つ場合があります)。 予測値 (ŷ) と観測値 (y) を比較していることを明確にするために、それらの差を残差と見なします。 すべての検証データ予測の残差を集計して、モデルの全体的な 損失 を予測パフォーマンスの指標として計算できます。
損失を測定する最も一般的な方法の 1 つは、個々の残差を 2 乗して合計し、平均を計算することです。 残差の二乗は、 絶対値 に基づいて計算を行い (差が負か正かを無視する)、より大きな差により重みを与える効果があります。 このメトリックは、 平均二乗誤差と呼ばれます。
この例の検証データの場合、計算は次のようになります。
| y | ŷ | y - ŷ | (y - ŷ)2 |
|---|---|---|---|
| 156 | 159.4 | -3.4 | 11.56 |
| 114 | 111.8 | 2.2 | 4.84 |
| 129 | 125.4 | 3.6 | 12.96 |
| 合計 | ∑ | 29.36 | |
| 平均 | x̄ | 9.79 |
このように、MSE メトリックに基づくモデルの損失は 9.79 です。
それでは、これはどれだけ優れているのでしょうか。 MSE の値は意味のある測定単位では表されていないため、判断するのは困難です。 値が小さいほどモデルの損失は少なく、予測がより優れていることはわかります。 そのため、これは 2 つのモデルを比較して最適なモデルを見つけるのに便利なメトリックです。
場合によっては、予測されるラベル値自体と同じ測定単位 (この例ではレンタルの数) で損失を表す方が便利です。 これを行うには、MSE の平方根を計算します。これにより、当然ながら、2 乗平均平方根誤差 (RMSE) として既知のメトリックが生成されます。
√9.79 = 3.13
このモデルの RMSE は、損失が 3 をわずかに超えていることを示しています。これは大まかにいえば、正しくない予測は平均してレンタル数で約 3 誤っていることを意味すると解釈できます。
回帰の損失を測定するために使用できるメトリックは他にも多数あります。 たとえば、R2 (R-2 乗) (決定係数と呼ばれることもあります) は、x と y の 2 乗の間の相関関係です。 これにより、モデルで説明できる分散の量を測定する 0 ~ 1 の値が生成されます。 一般に、この値が 1 に近いほど、モデルの予測精度が向上します。