構成とメトリックを確認して問題を診断する
Azure Load Balancer のパフォーマンスを監視すると、可能性のある障害に対する警告が早期に示されることがあります。 Azure Monitor により Load Balancer のパフォーマンスの傾向を調べるために使用する多くの重要なメトリックが提供されています。 1 つ以上の仮想マシン (VM) で正常性プローブの要求が失敗した場合、アラートをトリガーすることもできます。
このシナリオ例では、負荷分散システムのパフォーマンスを監視して、パフォーマンスが確実に要件を満たすようにします。 パフォーマンスが低下し、VM への接続が失敗し始めた場合は、システムのトラブルシューティングを行い、原因を特定して問題を解決します。 このユニットを完了すると、次のことができるようになります。
- 負荷分散されたシステムのスループットとパフォーマンスの測定に使用できるメトリックについて説明します。
- Azure portal のリソース正常性ページを使用して、システムの正常性を監視します。
- 負荷分散されたシステムでの一般的な問題を解決する方法について説明します。
Azure Monitor を使用して Load Balancer のトラブルシューティングを行う
Azure Monitor を使用すると、Load Balancer の診断ログとパフォーマンス データをキャプチャして調べることができます。
接続を監視する
Azure portal の [メトリック] ウィンドウを使用して、Load Balancer のメトリックを視覚化できます。 接続のトラブルシューティングの観点から見て最も重要なメトリックは、Data Path Availability (データ パス可用性) と Health Probe Status (正常性プローブ状態) です。

Load Balancer では、VM 上で実行されているアプリケーションへの、負荷分散ルールとバックエンド プールを通したパスの、フロントエンド IP アドレスに対する可用性が、継続的にテストされています。 この情報は、Data Path Availability (データ パス可用性) メトリックとして記録されます。 [平均] メトリックを適用すると、特定の時間間隔の平均可用性が示されます。 この集計は、0 (利用不可) から、フロントエンド IP アドレスからバックエンド プール内の VM に対して使用可能な正常なパスが少なくとも 1 つ存在することを示す 100 までの間の値です。
Health Probe Status (正常性プローブ状態) メトリックも似ていますが、Load Balancer を通した完全なパスではなく、VM に対する正常性プローブにのみ適用されます。 繰り返しますが、このメトリックの Avg 集計では、0 (すべての VM が異常で応答に失敗している) から 100 (すべての VM が正常性プローブに応答している) までの値が返されます。
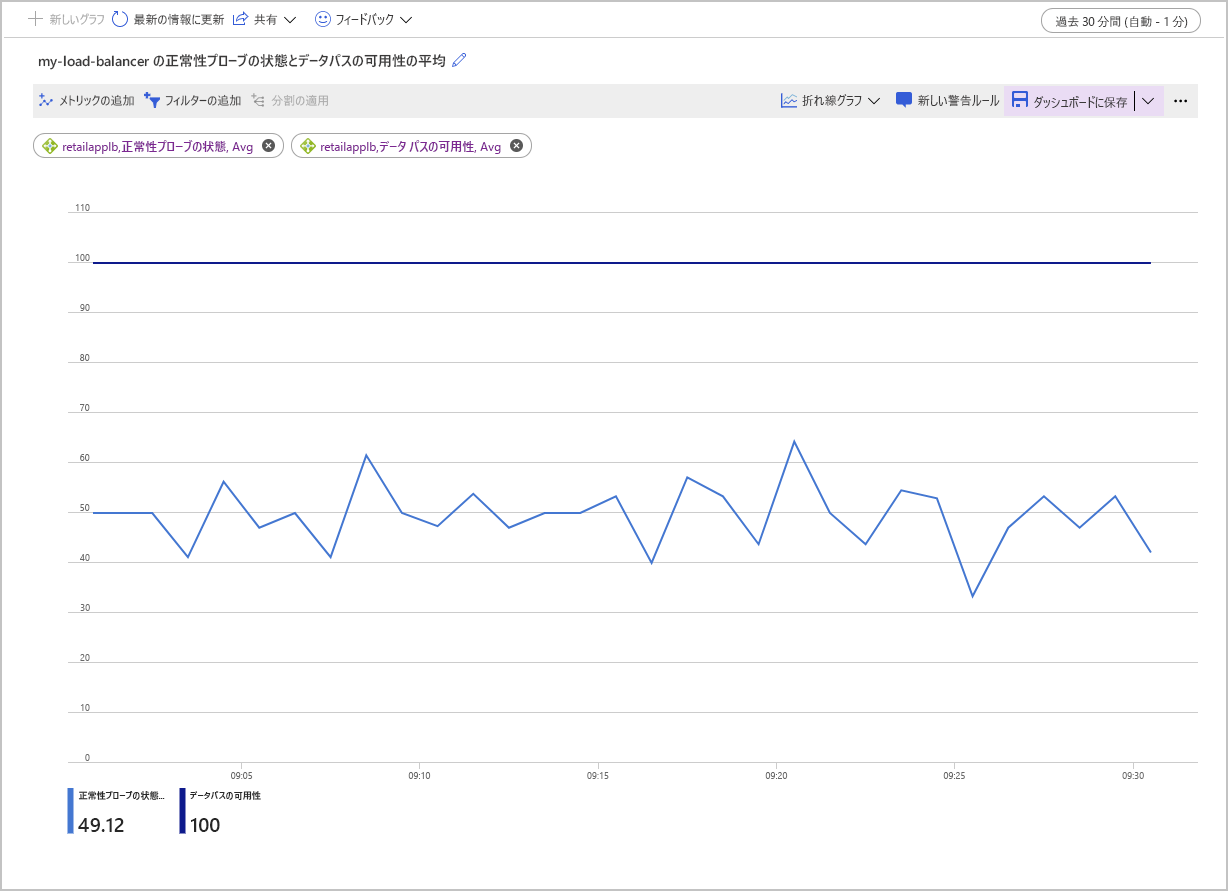
次のスクリーンショットでは、バックエンド プールに 2 つの VM があるロード バランサーに対するデータ パスの可用性の平均と正常性プローブの状態の平均のグラフを示しています。 マシンの 1 つが正常性プローブに応答していません。 正常性プローブの状態の平均は、50% 前後で推移しています。
これらのメトリックを調べるもう 1 つの方法は、[カウント] 集計を使用することです。 この方法では、現在の構成に関する潜在的な問題についての別の分析情報が得られます。 次の例では、Health Probe Status (正常性プローブ状態) および Data Path Availability (データ パス可用性) メトリックの数のグラフを示します。 グラフには、正常に実行されたプローブの数が時間の経過に沿って示されています。
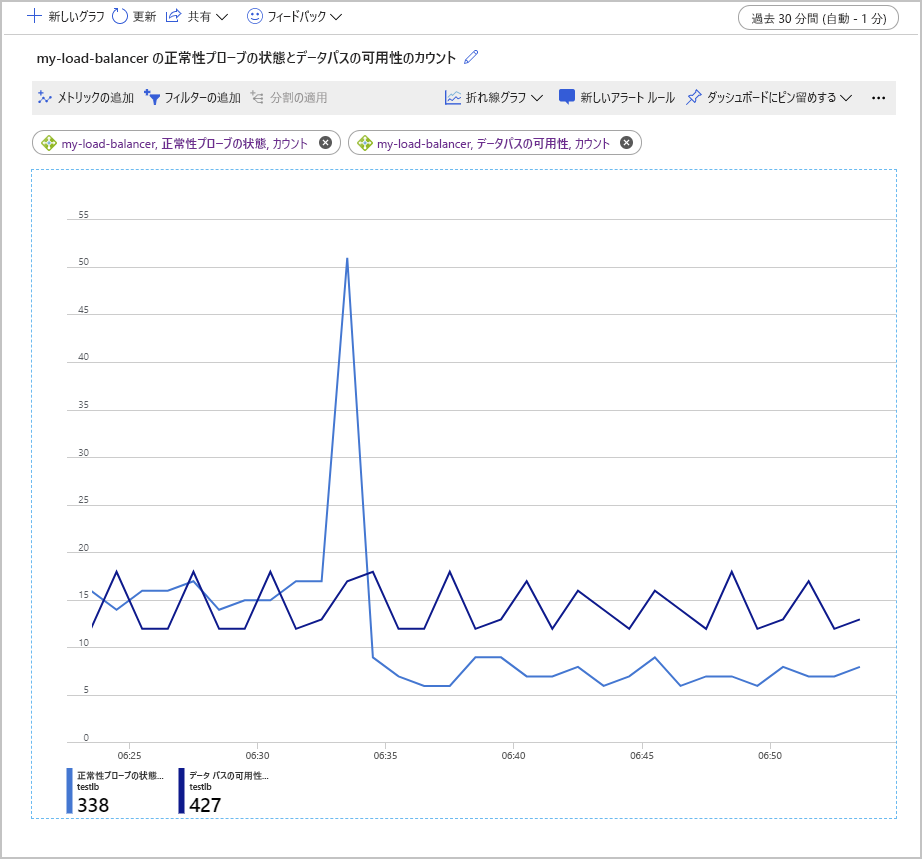
このグラフの興味深い点は、成功したデータ パス可用性プローブの数が一定の範囲内に留まったことです。 一方、Health Probe Status (正常性プローブ状態) チェックの数は、瞬間的に増加した後、増加前の値の半分程度に低下しています。
このグラフの生成に使用した設定のバックエンド プールには、VM が 2 つしか含まれていませんでした。 障害をシミュレートするため、これらのマシンの 1 つを停止しました。 Data Path Availability (データ パス可用性) メトリックでは、動作している残りの VM で実行されているアプリケーションに、クライアント アプリケーションがまだ接続できることが示されています。 しかし、Health Probe Status (正常性プローブ状態) では、バックエンド プールの全体的な "正常性" が、以前の状態の半分であることが示されています。
サービスの正常性を表示する
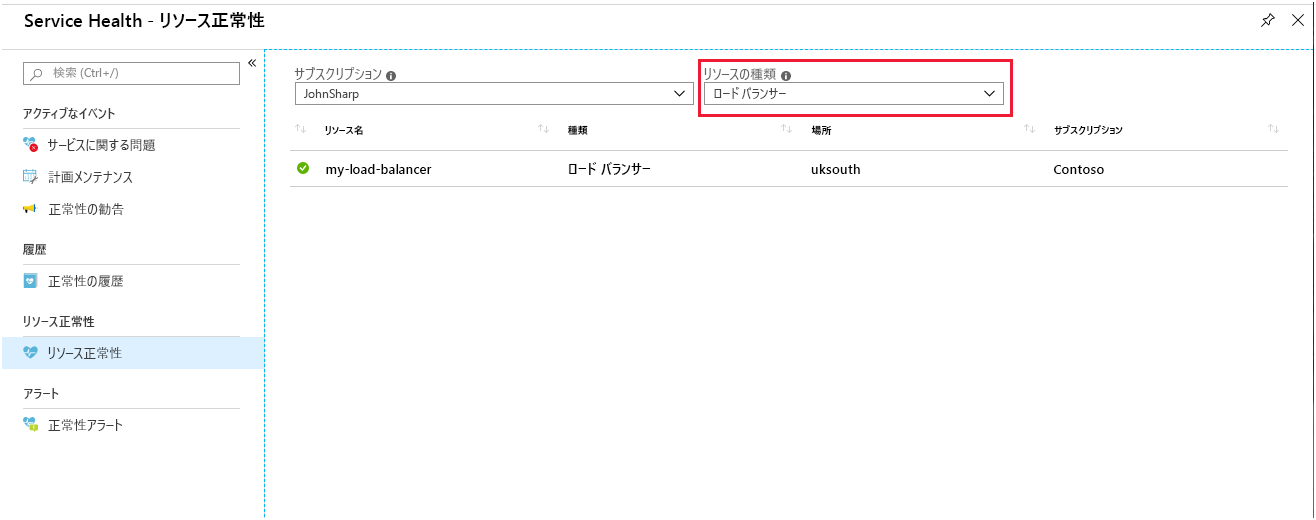
Load Balancer の [リソース正常性] ページでは、システムの全般的な状態に関してレポートされます。 このページには、ポータルの Azure Monitor からアクセスします。 [Service Health] を選択して、[リソース正常性] を選択し、リソースの種類として [Load Balancer] を選択します。
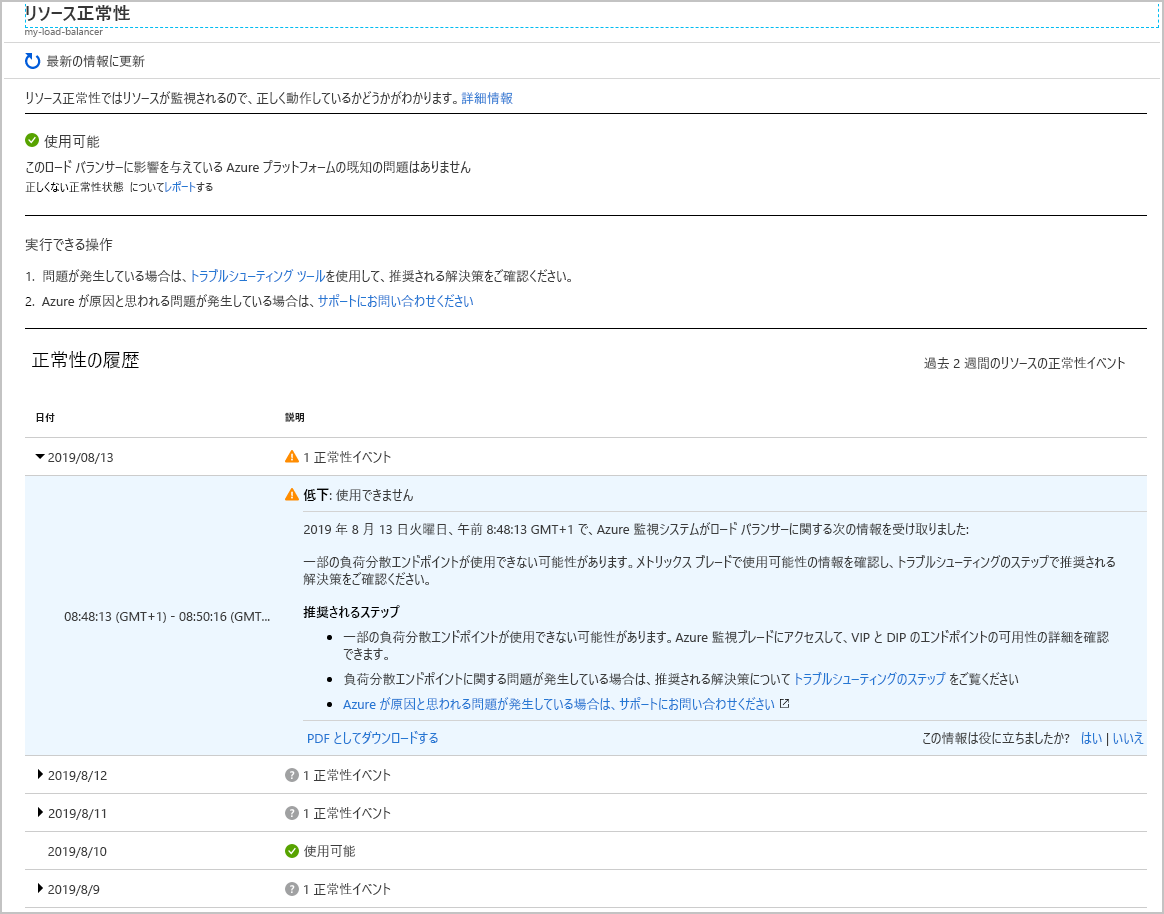
お使いのロード バランサーを選択します。 サービスの正常性の履歴の詳細を示すレポートが表示されます。 レポート内の任意の項目を展開して、詳細を表示できます。 次の図では、バックエンド プール内の VM の 1 つがオフラインになったときに生成される概要を示します。
VM ごとのワークロードを監視する
Load Balancer に対して使用できる他のメトリックを使用すると、"フロントエンド" ごとに Load Balancer を通過するバイト数とネットワーク パケット数を追跡できます。 フロントエンドは、Load Balancer の IP アドレス、受信要求を受け入れるために使用されるプロトコル、および VM に接続するために負荷分散規則で使用されるポート番号の組み合わせとして定義されます。 これらのメトリックでは、アクティブな VM ごとにシステムのスループットの測定値を提供できます。
次のグラフは、テスト ワークロードとして 500 人の同時ユーザーを 2 分間実行したときに、Load Balancer を通過した平均パケット数を示したものです。 ワークロードは 2 回実行されました。 1 回目には、バックエンド プールに 2 つの VM インスタンスが含まれていました。 2 回目の実行では、VM の 1 つがシャットダウンされていました (エラーのシミュレート)。
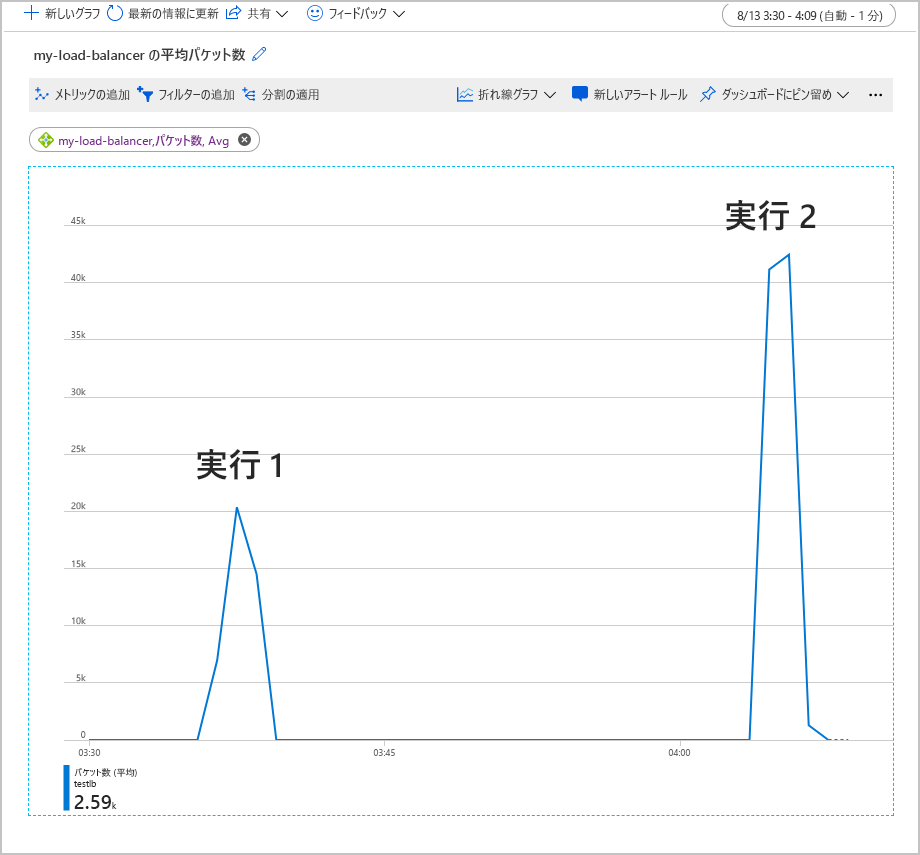
このグラフでは、1 つの VM がシャットダウンされていると、フロントエンドごとの平均パケット数が 2 倍になりました。 この作業量によって、残りの VM が過負荷になるため、応答時間が長くなり、タイムアウトが発生する可能性があります。
Load Balancer に関する一般的な問題を調査して修復する
このセクションでは、Load Balancer で発生する可能性のある一般的なエラー シナリオについて説明します。 各シナリオでは、エラーの症状と、問題を解決する方法がまとめられています。
Load Balancer の内側にある VM が、プローブ ポートのトラフィックに応答しない
この状態は、次の問題が原因で発生する可能性があります。
バックエンドプール内の VM が、正しいプローブ ポートでリッスンしていません。
Load Balancer で正常性プローブが正しく設定されていることを確認します。 各 VM で実行されているアプリケーション コードがプローブ要求に対して適切に応答することを確実にします。 HTTP 200 (OK) 応答メッセージが返されるはずです。
VM をホストしている仮想ネットワーク サブネットの NSG によって、プローブ ポートがブロックされています。
VM を含む仮想ネットワーク サブネットの NSG 構成を確認します。 NSG により Load Balancer からのトラフィックが確実に正常性プローブ ポートを通過できるようにします。
同じ VM と仮想ネットワーク カードから Load Balancer にアクセスしようとしています。 この問題はプローブに関連するものではなく、サポートされていないデータ パスのシナリオです。
バックエンド プール内の VM から Load Balancer フロントエンドにアクセスしようとしています。
これらの項目はどちらもアプリケーションの設計上の問題です。 バックエンド プール内の VM から Load Balancer の同じインスタンスに要求を送信しないようにします。
バックエンド プール内の VM が異常
この場合、ほとんどの VM は正常に応答しますが、しないものが 1 つか 2 つあります。 一部の VM はトラフィックを受け入れるため、正常性プローブは正しく構成されていると考えられます。 サブネットの NSG によって、正常性プローブで使用されるポートはブロックされていません。 問題はおそらく、異常な VM にあります。 この問題は、VM がアクセス不能かダウンしている、またはこれらのマシンにアプリケーションの問題があることにより発生した可能性があります。
異常な VM の問題の原因を特定するには、次の手順に従います。
- 異常な VM にサインインして、稼働していることを確認します。 VM が、バックエンド プール内の別の VM からの ping、rdp、ssh 要求などの基本的なチェックに応答できることを確認します。
- VM が稼働していて、アクセスできる場合は、アプリケーションが実行されていることを確認します。
netstat -anコマンドを実行し、正常性プローブとアプリケーションによって使用されるポートが LISTENING として一覧表示されていることを確認します。
Load Balancer の構成ミス
Load Balancer では、フロントエンドからバックエンド プールに着信トラフィックを送信するルーティング規則を正しく構成する必要があります。 ルーティング規則が見つからないか、正しく構成されていない場合、フロントエンドに到着したトラフィックは切断されます。 トラフィックが切断されると、アプリケーションはアクセス不可としてクライアントに報告されます。
Load Balancer を経由するフロントエンドからバックエンド プールへのルートを検証します。 Windows と Linux で使用可能な、Ping、TCPing、netsh などのツールを使用できます。 Windows では psping を使うこともできます。 次のセクションでは、これらのツールの使用方法について説明します。
ping を使う
ping コマンドは、ICMP プロトコルを使ってエンドポイントを介した ping 接続をテストします。 Load Balancer を経由して、お使いのクライアントから VM にルーティングできることを確認するには、次のコマンドを使用します。 <ip address> を Load Balancer インスタンスの IP アドレスに置き換えます。
ping -n 10 <ip address>
| Switch | 説明 |
|---|---|
| -n | このスイッチは、送信する ping 要求の数を指定します。 |
一般的な出力は次のようになります。
ping -n 10 nn.nn.nn.nn
Pinging nn.nn.nn.nn with 32 bytes of data:
Reply from nn.nn.nn.nn: bytes=32 time=34ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Ping statistics for nn.nn.nn.nn:
Packets: Sent = 10, Received = 10, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 29ms, Maximum = 34ms, Average = 30ms
PsPing を使用する
PsPing コマンドは、エンドポイントを介した ping 接続をテストします。 このコマンドは、サービスに対する待機時間と帯域幅の可用性も測定します。 Load Balancer を経由して、お使いのクライアントから VM にルーティングできることを確認するには、次のコマンドを使用します。 <ip address> と <port> を Load Balancer インスタンスの IP アドレスとフロントエンド ポートに置き換えます。
psping -n 100 -i 0 -q -h <ip address>:<port>
| フラグ | 説明 |
|---|---|
| -n | 実行する ping の回数を指定します。 |
| -i | イテレーション間の間隔を秒単位で示します。 |
| -q | ping の実行中に出力を抑制します。 概要だけが最後に表示されます。 |
| -h | 要求の待機時間を示すヒストグラムを出力します。 |
一般的な出力は次のようになります。
TCP connect to nn.nn.nn.nn:nn:
101 iterations (warmup 1) ping test: 100%
TCP connect statistics for nn.nn.nn.nn:nn:
Sent = 100, Received = 100, Lost = 0 (0% loss),
Minimum = 7.48ms, Maximum = 9.08ms, Average = 8.30ms
Latency Count
7.48 3
7.56 2
7.65 2
7.73 2
7.82 7
7.90 4
7.98 4
8.07 6
8.15 9
8.24 9
8.32 11
8.40 7
8.49 11
8.57 12
8.66 3
8.74 2
8.82 2
8.91 1
8.99 2
9.08 1
tcping を使用する
tcping ユーティリティは ping に似ていますが、ICMP ではなく TCP 接続上で動作する点が異なります。 tcping は次のように使用します。
tcping <ip address> <port>
一般的な出力は次のようになります。
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.042ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.810ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.266ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.181ms
Ping statistics for nn.nn.nn.nn:nn
4 probes sent.
4 successful, 0 failed. (0.00% fail)
Approximate trip times in milli-seconds:
Minimum = 9.042ms, Maximum = 9.810ms, Average = 9.325ms
netsh を使用する
netsh ユーティリティは、汎用ネットワーク構成ツールです。 netsh の trace コマンドを使用して、ネットワーク トラフィックをキャプチャします。 次に、Wireshark などのツールを使って分析します。 Load Balancer を介した接続をテストするときに、psping によって送受信されたネットワーク パケットを確認するには、次のように netsh trace を使用します。
管理者として実行しているコマンド プロンプトからネットワーク トレースを開始します。 次の例では、指定された IP アドレスとの間のインターネット クライアント トラフィック (HTTP 要求) をトレースします。 <ip address> を Load Balancer インスタンスのアドレスに置き換えます。 トレース データが trace.etl という名前のファイルに書き込まれます。
netsh trace start ipv4.address=<ip address> capture=yes scenario=internetclient tracefile=trace.etlLoad Balancer を通じて接続をテストするには psping を実行します。
psping -n 100 -i 0 -q <ip address>:<port>トレースを停止します。
netsh trace stopこのコマンドでは、トレース出力ファイルの作成中に情報の関連付けと結合が行われるため、完了までに数分かかります。
Wireshark を起動し、トレース ファイルを開きます。
次のフィルターをトレースに追加します。 <nn> を Load Balancer のフロントエンド ポート番号に置き換えます。
TCP.Port==80 or TCP.Port==<nn>HTTP 要求の送信元と送信先をフィールドとしてトレース出力に追加します。
トレース メッセージで次のことを確認します。
- Load Balancer への着信パケットがない場合、ネットワーク セキュリティの問題、またはユーザー定義のルーティングの問題がある可能性があります。
- 送信パケットがクライアントに返されない場合は、アプリケーション構成の問題、またはユーザー定義のルーティングの問題がある可能性があります。
VM ファイアウォールまたは NSG によってポートがブロックされている
ネットワークと Load Balancer が正しく構成され、VM が起動していて、アプリケーションが実行中の場合、VM のファイアウォールまたは NSG 構成により正常性プローブまたはアプリケーションで使われるポートがブロックされている可能性があります。 これに該当するかどうかを判断するには、以下の手順を使います。
VM にファイアウォールがある場合、正常性プローブとアプリケーションで使用されるポートで要求をブロックしている可能性があります。 ホストのファイアウォール構成を検証して、正常性プローブとアプリケーションで使用されるポートでのトラフィックが確実に許可されるようにします。
VM の NIC の NSG で、必要なポートでの受信と送信が許可されていることを確認します。 VM の NIC 上の NSG で、既定のルールより高い優先順位を持つ "すべて拒否" ルールを確認します。
重要
NSG は、サブネットと、サブネット内の VM の個々の NIC に関連付けることができます。 トラフィックがポートを通過できるように、サブネットに NSG を構成している可能性があります。 ただし、VM の NSG でその同じポートが閉じられると、要求がその VM に到達できません。
Load Balancer の制限事項
Load Balancer は、ISO ネットワーク スタックのレイヤー 4 で動作し、これによりネットワーク パケットの内容の検査やそれ以外の操作は行われません。 これを使用して、コンテンツベースのルーティングを実装することはできません。
すべてのクライアント要求は、バックエンド プール内の VM によって終了されます。 Load Balancer はクライアントに表示されません。 使用可能な VM がない場合、クライアントの要求は失敗します。 クライアント アプリケーションでは、Load Balancer や、そのコンポーネントのいずれかと通信したり、それらの状態を調査したりすることはできません。
メッセージの内容に基づいて負荷分散を実装する必要がある場合は、Azure Application Gateway の使用を検討してください。 または、プロキシ Web サーバーを構成して、受信クライアント要求を処理し、特定の VM にそれらを送信することもできます。