分類モデルとは
分類モデルは、決定を下したり、項目をカテゴリに割り当てたりするために使用されます。 高さや重みなどの連続する数値を出力する回帰モジュールとは異なり、分類モデルでは、ブール値 ( true または false) またはカテゴリの決定 ( apple、 banana、 cherryなど) が出力されます。
分類モデルにはさまざまな種類があります。 従来の回帰モデルと同様に動作するものもあれば、根本的に異なるものもあります。 最初に学習するのに最適なモデルの 1 つは、ロジスティック回帰と呼ばれます。
ロジスティック回帰とは
ロジスティック回帰は、線形回帰と同様に機能する 分類 モデルの一種です。 この回帰と線形回帰の違いは、曲線の形状です。 単純な線形回帰はデータに直線を適合させますが、ロジスティック回帰モデルは s 型の曲線に適合します。
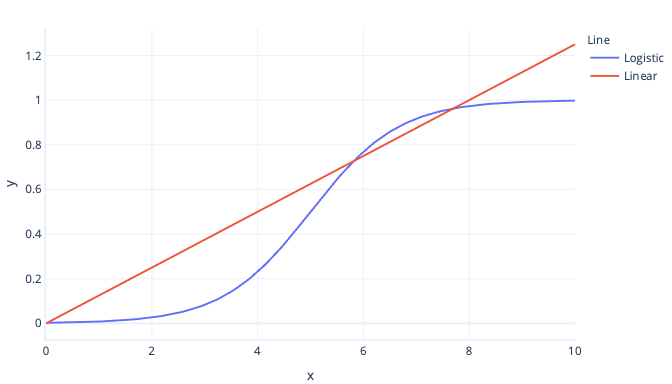
ロジスティック曲線は常に 0 (false) から 1 (true) の値を生成するため、ロジスティック回帰は線形回帰よりもブール値の結果を推定する場合に適しています。 これら 2 つの値の間の何でも確率と考えることができます。
たとえば、現在雪崩が発生する可能性があるかどうかを予測しようとしているとします。 ロジスティック回帰モデルの値が 0.3 の場合、雪崩の確率は 30% と推定されます。
出力をカテゴリに変換する
ロジスティック回帰では、単純な true/false 値ではなく、これらの確率が得られますので、結果をカテゴリに変換するための追加の手順を実行する必要があります。 この変換を行う最も簡単な方法は、しきい値を適用することです。 たとえば、次のグラフでは、しきい値は 0.5 に設定されています。 このしきい値は、0.5 未満の y 値が false (左下のボックス) に変換され、0.5 を超える値が true (右上のボックス) に変換されることを意味します。
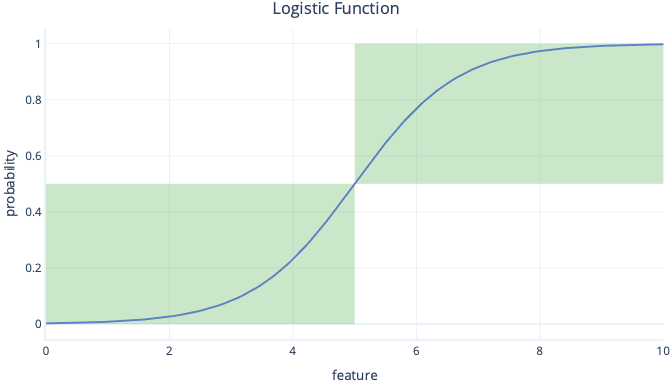
グラフを見ると、特徴が 5 未満の場合、確率が 0.5 未満で false に変換されることがわかります。 5 より上の特徴値は 0.5 を超える確率を与え、true に変換されます。
ロジスティック回帰を真偽の結果に限定する必要はないという点は注目に値します。また、 rain、 snow、 sunなど、3 つ以上の潜在的な結果がある場合にも使用できます。 この種の結果には、 多項式ロジスティック回帰 と呼ばれる、少し複雑な設定が必要です。次のいくつかの演習では多項式ロジスティック回帰を練習しませんが、バイナリではない予測を行う必要がある状況では考慮する必要があります。
また、ロジスティック回帰では複数の入力機能を使用できることにも注目する必要があります。このケースでは、間もなくさらに多くの入力機能が使用されます。