分類モデルの評価
機械学習の大部分は、モデルがどれだけうまく機能するかを評価することです。 この評価は、トレーニング中、モデルの整形に役立ち、トレーニング後にモデルが実際の世界で使用できるかどうかを判断するために行われます。 分類モデルには回帰モデルと同様に評価が必要ですが、この評価の方法は少し複雑になる場合があります。
コストの復習
トレーニング中に、モデルのパフォーマンスがどのくらい悪いかを計算し、この コスト ( 損失) と呼びます。 たとえば、線形回帰では、多くの場合、平均二乗誤差 (MSE) と呼ばれるメトリックを使用します。 MSE は、予測と実際のラベルを比較し、差を 2 乗し、結果の平均を取得することによって計算されます。 モデルに合わせて MSE を使用し、その動作を報告できます。
分類のコスト関数
分類モデルは、出力確率 (雪崩の可能性が 40% など) または最終的なラベル (no avalanche または avalanche) で判断されます。 出力確率を使用すると、トレーニング中に有利になる場合があります。 モデルのわずかな変更は、最終的な決定を変更するのに十分でない場合でも、確率の変化に反映されます。 コスト関数に最終的なラベルを使用する方が、モデルの実際のパフォーマンスを見積もる場合に便利です。たとえば、テスト セットでは、実際の使用では確率ではなく最終的なラベルを使用するためです。
ログ損失
ログ損失は、単純な分類で最も一般的なコスト関数の 1 つです。 ログ損失は出力確率に適用されます。 MSE と同様に、エラーの量が少ない場合はコストが小さくなりますが、中程度のエラーは大きなコストになります。 次のグラフに、正しい回答が 0 (false) であったラベルのログ損失をプロットします。
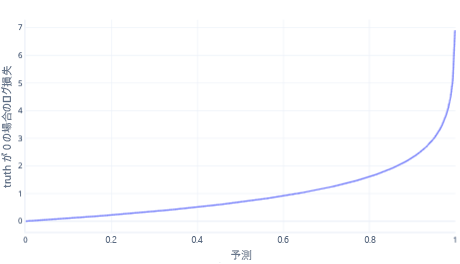
x 軸は、可能なモデル出力 (0 から 1 までの確率) を示し、y 軸にはコストを示します。 モデルの信頼度が高く、正しい応答が 0 である場合 (0.1 の予測など)。 その後、このインスタンスでは正しい応答が 0 であるため、コストは低くなります。 モデルが自信を持って結果を誤って予測している場合 (0.9 の予測など)、コストが高くなります。 実際、x=1 ではコストが非常に高いため、グラフを読みやすくするために、ここで x 軸を 0.999 にトリミングします。
なぜ MSE ではないのですか?
MSE とログ損失は同様のメトリックです。 ロジスティック回帰で対数損失が優先される複雑な理由がいくつかありますが、いくつかのより単純な理由もあります。 たとえば、 ログ損失 は、MSE よりもはるかに強く間違った回答を罰します。 たとえば、正しい回答が 0 である次のグラフでは、0.8 を超える予測の方が MSE よりも対数損失のコストが高くなります。
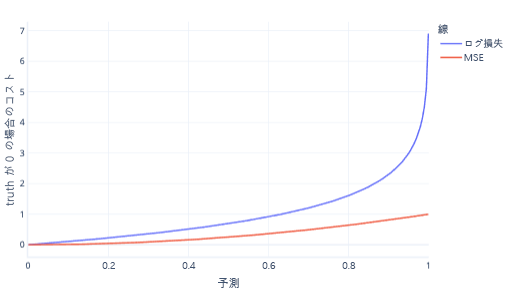
この方法でコストを高くすると、線の勾配が急上昇するため、モデルの学習速度が向上します。 同様に、対数損失は、モデルが正しい答えを与えることに対する自信を高めてくれるのに役立ちます。 前のプロットでは、0.2 より小さい値の MSE コストは小さく、グラデーションはほぼフラットであることに注意してください。 この関係により、修正に近いモデルのトレーニングが遅くなります。 ログ損失では、これらの値の勾配が急に高くなり、モデルの学習速度が向上します。
コスト関数の制限事項
モデルの人間による評価に 1 つのコスト関数を使用することは、モデルがどのような誤りを犯しているのかを示さないため、常に制限されます。 たとえば、雪崩の予測シナリオを考えてみましょう。 ログ損失の値が高い場合は、モデルが何もない場合に雪崩を繰り返し予測している可能性があります。または、発生する雪崩の予測に繰り返し失敗している可能性があります。
モデルの理解を深めるために、複数の数値を使用して適切に機能するかどうかを評価する方が簡単です。 この大きなテーマについては、他の学習資料で取り上げていますが、次の演習で説明します。