正規表現の概要
このユニットでは、正規表現の概要について説明します。 正規表現は、テキスト パターン マッチングを行う必要があるときに便利です。 これらは、開発者にもデータ科学者にも同じように使用されます。
正規表現 (regex) は非常に便利であり、いつかは使用する機会があります。 この難解で小規模の言語は、複雑なパターン マッチングに役立ちますが、最初は少し手強く見えるかもしれません。 しかし、正規表現は、ほとんどのテキスト エディターと言語および Python、SQL、Go、Scala などの多くのツールで目にすることができます。 これについて学習しておくと必ず価値があります。
Regular Expressions 101 はブックマークに登録しておくと便利なオンライン ツールであり、テスト入力に対して正規表現をテストすることができます。
リテラルと特殊文字
簡単に言えば、正規表現は、文字のパターンを定義するための使いやすい方法であり、通常、パターン識別、テキスト マイニング、または入力の検証で使用されます。 指定するパターンは、広範囲でも限定的でもよく、左から右に "厳密に" 読み取られます。 正規表現の入力は常にテキスト文字列です。
ほとんどの文字 (英字と数字) は特殊な機能を持たず、その文字にそのまま一致します。 SSH の正規表現は、文字列 "SSH" にのみ一致します。入力文字列が "ZSH" の場合、正規表現パターンによる一致は見つかりません。
前のユニットを完了している場合、開いた NASA データセットのサンプルがあるはずです。 このデータセットを使用し、Azure Cloud Shell のサンドボックスで正規表現を使用してパターン マッチングをいくつか行います。
Cloud Shell エディターで
codeコマンドを使って NASA-software-API.txt ファイルを開きます。code NASA-software-API.txtファイルは、統合エディターで Cloud Shell プロンプトの上に表示されます。
統合エディターの検索ボックスを開きます。
エディター内の任意の場所をマウスでクリックします。
Ctrl + F キー (Windows と Linux の場合) または Cmd + F キー (macOS の場合) を押します。
統合エディターの検索ボックスが開きます。
[正規表現] アイコン (
.*) を選び、エディター内でファイルの正規表現パターン マッチ検索を有効にします。![Cloud Shell の検索ボックスと選択された [正規表現] オプションを示すスクリーンショット。](media/cloud-shell-sandbox-search-regex-selected.png)
検索ボックスに文字列「
Open Source」を入力します。[正規表現] オプションを有効にすると、Cloud Shell により、コンテンツ内の入力文字列に一致するすべてのインスタンスが強調表示されます。 一致したインスタンス数が検索ボックスに表示されます。
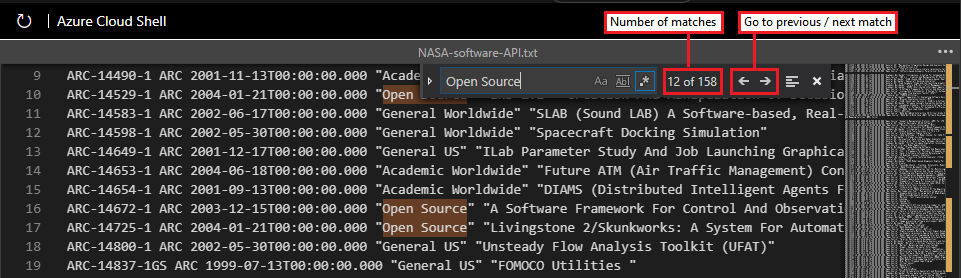
検索ボックスの左 (前) と右 (次) の矢印アイコンを使って、ファイル内の一致した各インスタンスを確認できます。
![Cloud Shell の検索ボックスと選択された [正規表現] オプションを示すスクリーンショット。](media/cloud-shell-sandbox-search-regex-selected.png#lightbox)

この手法は、検索ボックスの他の使用方法と何も違わないように見えるかもしれません。 正規表現の真の力は、特殊文字、範囲、アンカーを使い始めると発揮されます。
文字の一致と範囲
ここまで、正規表現を使用して文字のリテラル マッチングができることを学習しました。 ファイルで指定されているソフトウェアのバージョンを検索したいとしましょう。 関心があるのは、"v1" のような形式のバージョンです。
すべてのバージョンは文字 "v" で始まることがわかっています。一致する検索文字列の残りの部分を角かっこ [] で囲むことができます。 角かっこは、"この一覧に含まれる任意の文字" を意味します。1 から 5 までの数字で始まるバージョンを検索するには、v[12345] という正規表現で検索することができます。
この種類の正規表現パターンを NASA-software-API.txt ファイルで試してみましょう。
検索ボックスに「
ARC-14[456]」と入力し、"ARC-14" とそれに続く 4、5、または 6 という数字と一致するコンテンツを探します。12 件の結果が表示されるはずです。
検索ボックスの左と右の矢印アイコンを使って、ファイル内の一致した各インスタンスを確認します。
この例のような正規表現は簡単に使用できます。コンテンツに含まれる 3 つの数字 (4、5、6) を探すだけだからです。 しかし、アルファベットや数字の全体を、すべての文字または桁が多い数字を 1 文字ずつ書くことなく一致させるにはどうすればよいでしょうか?
連続する文字または数字の範囲を定義することができます。 すべての数字の場合は、[0-9] という範囲を作成します。 アルファベットの小文字の場合は、範囲 [a-z] を使用できます。
"ARC-14" の後に任意の数字が続くインスタンスをすべて見つけましょう。
検索ボックスに「
ARC-14[0-9]」と入力し、"ARC-14" とそれに続く任意の数字と一致するコンテンツを探します。22 件の結果が表示されるはずです。
このパターンに一致するファイル内の行の一部を次に示します。
ARC-14293-1 ARC 2005-09-19T00:00:00.000 "Open Source" "Genetic Graphs (JavaGenes)" ... ARC-14400-1 ARC 2001-01-29T00:00:00.000 "General US" "PLOT3D Version 4.0" ... ARC-14837-1GS ARC 1999-07-13T00:00:00.000 "General US" "FOMOCO Utilities " ... ARC-14932-1 ARC 2005-01-12T00:00:00.000 "Open Source" "Mission Simulation Toolkit (MST)"
ワイルドカード
ピリオド (.) 文字は、"ワイルドカード" と呼ばれる特殊文字の種類です。 文字、数字、空白、改行、句読点、記号など、任意の文字を表すために使用できます。 たとえば、文字 "g" で始まり文字 "t" で終わる 3 文字の組み合わせをすべて見つけるには、正規表現 g.t を使います。
正規表現でよく使われるパターンは、ピリオドとそれに続くアスタリスク (.*) です。 この正規表現構文を使うと、0 個以上の任意の文字と一致させることができます。
この正規表現ワイルドカード パターンを使って、"NASA" とそれに続く任意の文字に一致するテキストを探してみましょう。
検索ボックスに「
NASA.*」と入力し、一致するテキストを探します。26 件の結果が表示されるはずです。
このパターンに一致したファイル内の行の一部を次に示します。
NASA Root Cause Analysis Tool ... NASA's Moderate Resolution Imaging Spectrometer (MODIS)-Combined Ocean Color ... NASA, Average-Passage Multistage Turbomachinery Flow Field Analysis Code ... NASA - Average Passage Flow Solver) ... NASA/NESSUS 6.2c Probabilistic Structural Analysis Software
アンカー
文字の行または単語の特定の部分に出現するシーケンスと一致させる場合は、"アンカー" と呼ばれます。 アンカーには次の 2 種類があります。
- 行の先頭: 検索パターンで、一致する部分が行の "先頭" に出現した場合のみ、文字シーケンスを一致と見なす場合は、キャレット (
^) 記号を使います。 - 行の末尾: 検索パターンで、一致する部分が行の "末尾" に出現した場合のみ、文字シーケンスを一致と見なす場合は、ドル (
$) 記号を使います。
これで、行の先頭 ^[0-9] または行の末尾 [0-9]$ にある数字と一致する正規表現を作成できるようになりました。
入力文字列の最初または最後の文字が "A" である一致を検索する正規表現アンカー パターンを試してみましょう。
A から G の文字で始まるテキストを探すには、検索ボックスに「
^[A-G]」と入力します。258 件の結果が表示されるはずです。
A から G の文字で終わるテキストを探すには、「
[A-G]$」と入力します。3 件の結果があります。
LAR-16939-GS LaRC 2000-11-07T00:00:00.000 "General Public" DeMAID1m.sea ... GSC-16207-1 GSFC 2011-04-12T00:00:00.000 "Open Source" "Goddard Mission Services Evolution Center Architecture Application Programming Interface (GMSEC ... LEW-16018-1 GRC 2003-01-05T00:00:00.000 "General US" CARES/LIFE
文字のエスケープ
たとえば、ピリオド (.) が最後の文字である行を検索するとします。 ドル記号 ($) が行末のアンカーであることがわかっているので、検索ボックスに「.$」と入力します。 ただし、この正規表現では、求める一致が返されません。 先ほど説明したように、ピリオド (.) は任意の 1 文字と一致します。 すべての行が文字で終わるため、結果ではすべての行が返されます。
特殊文字そのものを検索したい場合、正規表現でその文字が機能しないようにするにはどうすればよいでしょうか? 検索する文字をエスケープするには、バックスラッシュ (\) を使います。 ピリオド (.) が最後の文字である行を検索するには、正規表現 \.$ を使います。
NASA ファイルの正規表現パターン検索でエスケープ文字を使ってみましょう。
検索ボックスに「
\.$」と入力し、ピリオド (.) で終わるテキストを探します。結果は 0 件です。 ファイル内にピリオドで終わる行がありません。
検索ボックスに「
\*\*」と入力し、ファイル内のダブル アスタリスク (**) のインスタンスを探します。ファイル内の 1 行が次の検索パターンに一致します。
LLEW-17324-1 GRC 2001-01-05T00:00:00.000 "General US" "CANCELLED ** Same As LEW-16855-1 (APNASA - Average Passage Flow Solver)"
正規表現の早見表
このユニットでは、正規表現とそれを使用してできることについて簡単に説明しました。 正規表現を使用して作成できる複雑なパターンは、他にも多くあります。 以下は、正規表現の便利な早見表です。
| Regex | 定義 |
|---|---|
| ^ | 行の先頭に一致します。 |
| $ | 行の末尾に一致します。 |
| . | 任意の文字と一致します。 |
| \s | 空白文字に一致します。 |
| \S | 任意の空白以外の文字に一致します。 |
| * | ある文字を 0 回以上繰り返します。 |
| *? | ある文字を 0 回以上繰り返します (最短一致)。 |
| + | ある文字を 1 回以上繰り返します。 |
| +? | ある文字を 1 回以上繰り返します (最短一致)。 |
| [aeiou] | 記載された一連の文字のうち 1 字に一致します。 |
| [^XYZ] | 記載された一連の文字にない 1 字に一致します。 |
| [a-z0-9] | 一連の文字に範囲を含めることができます。 |
| ( | 文字列の抽出を開始する場所を示します。 |
| ) | 文字列の抽出を終了する場所を示します。 |
Visual Studio Code と正規表現の詳細については、Visual Studio Code ドキュメントを参照してください。