適用対象: ✔️ Linux VM
この記事では、Microsoft Azure の Linux 仮想マシン (VM) で発生するメモリ パフォーマンスの問題をトラブルシューティングする方法について説明します。
メモリ関連の問題に取り組む最初の手順は、次の項目を評価することです。
- システムでホストされているアプリケーションがメモリを使用する方法
- システム上の使用可能なメモリの適切なレベル
まず、ワークロード パターンを分析して、システムが正しく構成されているかどうかを判断できます。 次に、VM のスケーリングを検討するか、NUMA (非均一メモリ アクセス) アーキテクチャと UMA (Uniform Memory Access) アーキテクチャを選択する必要があります。 また、アプリケーションのパフォーマンスが Transparent HugePages (THP) の恩恵を受けるかどうかを検討する価値があります。 推奨されるメモリ要件を理解するために、アプリケーション ベンダーと共同作業することをお勧めします。
メモリの影響を受ける主要領域
プロセス メモリ割り当て - メモリは、カーネルを含むすべてのプロセスに必要なリソースです。 必要なメモリの量は、プロセスの設計と目的によって異なります。 通常、メモリはスタックまたはヒープに割り当てられます。 たとえば、SAP HANA などのメモリ内データベースは、データを効率的に格納および処理するためにメモリに大きく依存します。
ページ キャッシュの使用量 - ページ キャッシュの増加により、メモリを間接的に消費することもできます。 ページ キャッシュは、ディスクから以前に読み取られたファイルのメモリ内表現です。 このキャッシュは、ディスク読み取りの繰り返しを回避するのに役立ちます。 このプロセスの最良の例は、この基になるカーネル機能の利点を持つファイル サーバーです。
メモリ アーキテクチャ - 同じ VM で実行されているアプリケーションと、使用可能なメモリを競合させる可能性があるかどうかを把握することが重要です。 また、VM が NUMA アーキテクチャまたは UMA アーキテクチャを使用するように構成されているかどうかを確認する必要がある場合もあります。 プロセスのメモリ要件によっては、完全な RAM をペナルティなしで対処できるように、UMA アーキテクチャが望ましい場合があります。 一方、NUMA ノードのいずれかに適合する多数の小さなプロセスまたはプロセスを含むハイ パフォーマンス コンピューティング (HPC) では、CPU キャッシュのローカリティのメリットを得ることができます。
メモリのオーバーコミット - カーネルがメモリのオーバーコミットを許可するかどうかを判断することも重要です。 構成によっては、要求された量が使用できなくなるまで、すべてのメモリ要求が満たされます。
スワップ領域 スワップを有効にすると、メモリ不足状態の間にバッファーを提供することで、システム全体の安定性が向上します。 このバッファーは、システムが圧力の下で回復力を維持するのに役立ちます。 詳細については、 この Linux カーネルの記事を参照してください。
メモリのトラブルシューティング ツールについて
次のコマンド ライン ツールを使用してトラブルシューティングを行うことができます。
無料
システムで使用可能なメモリと使用されているメモリの量を表示するには、 free コマンドを使用します。

このコマンドは、合計スワップ領域と使用済みスワップ領域を含む、予約済みおよび使用可能なメモリの概要を生成します。
pidstat と vmstat
個々のプロセスによるメモリ使用量の詳細な表示については、 pidstat -r コマンドを使用します。
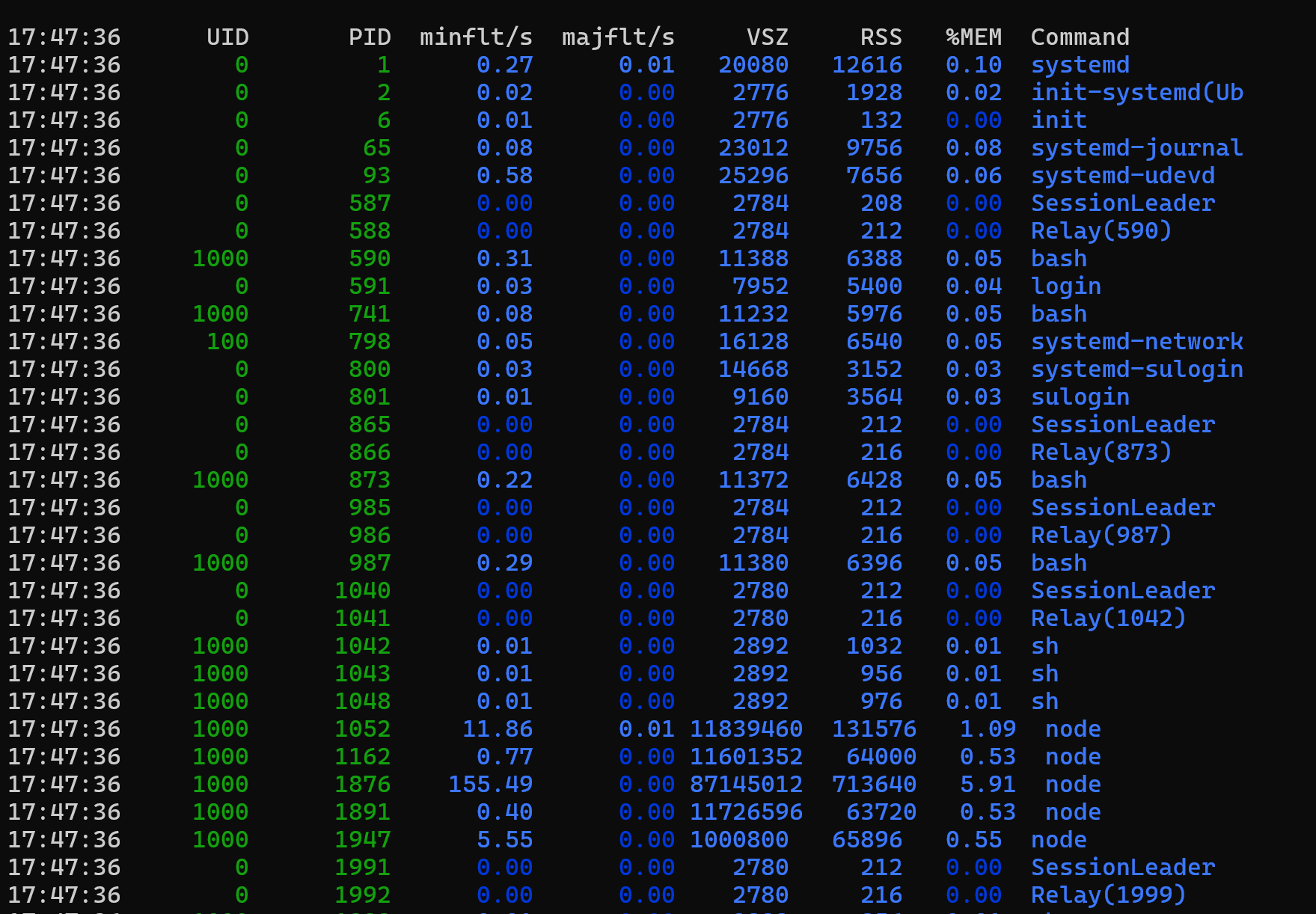
メモリ使用量レポートを分析する場合、観察すべき 2 つの重要な列は VSZ と RSSです。
- VSZ (仮想セット サイズ) は、プロセスが予約する仮想メモリの合計量 (KB 単位) を示します。
- RSS (常駐セット サイズ) は、現在 RAM に保持されている仮想メモリの量 (コミットされたメモリなど) を示します。
もう 1 つの便利なメトリックは、 majflt/s (1 秒あたりのメジャー ページ フォールトの数) です。 この数値は、スワップ デバイスからメモリ ページを読み取る必要がある頻度を測定します。 スワップ メモリの使用率の高さについて懸念がある場合は、 vmstat ツールを使用して、ページインとページアウトの統計情報を時間の経過と同時に監視して量を確認します。
サンプル vmstat 出力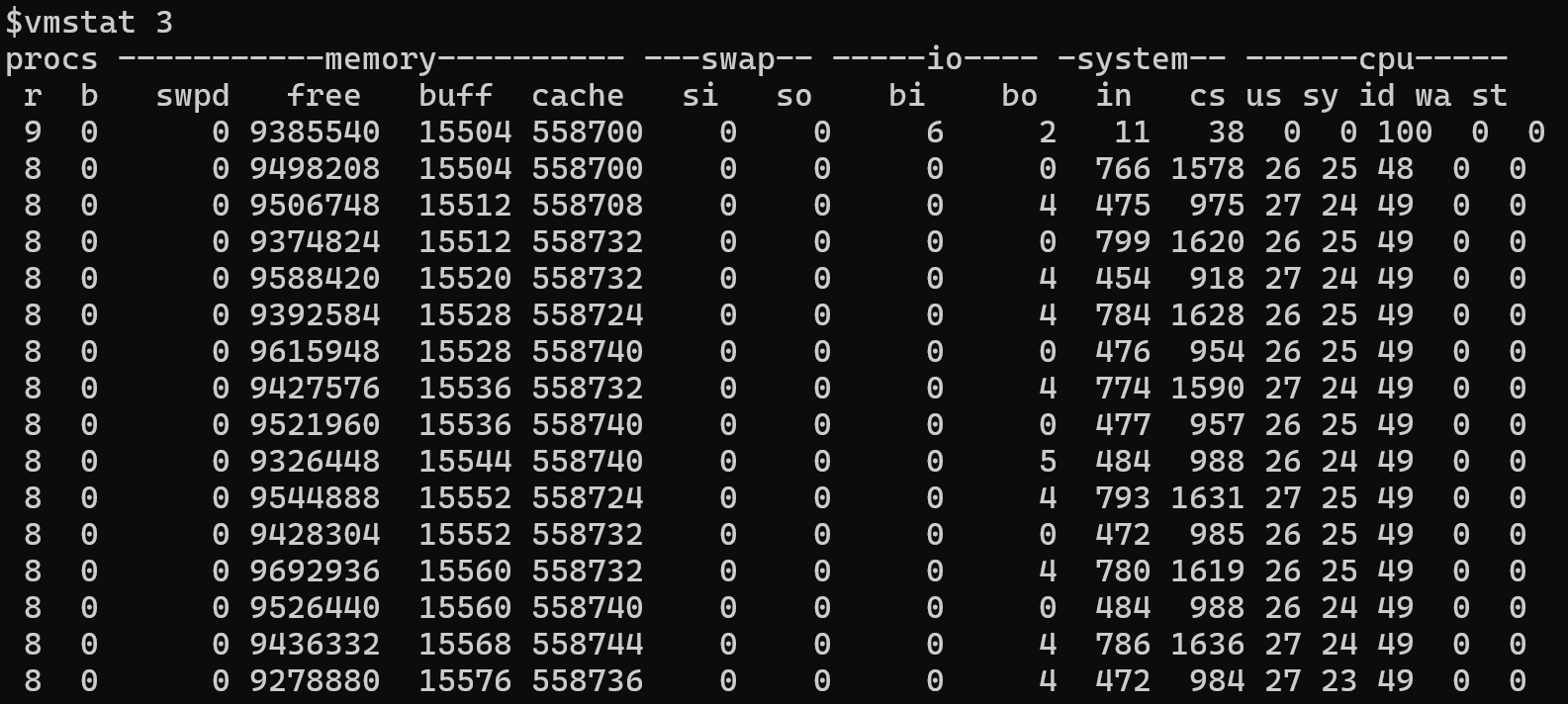
このサンプルでは、多くのメモリ ページが読み取られたり、スワップに書き込まれたりしている場合があります。 通常、これらの大きい値は、システムが使用可能なメモリ不足で実行されていることを示します。 この状態は、複数のプロセスがメモリを競合しているか、またはほとんどのアプリケーションで使用可能なメモリを使用できないために発生する可能性があります。
メモリが使用できない一般的な理由は、HugePages の使用です。 HugePages は予約済みメモリです。 すべてのアプリケーションで予約済みメモリを使用できるわけではありません。 状況によっては、アプリケーションが HugePages を必要とするか、Transparent HugePages (THP) を使用してより効果的に動作するかを評価する必要があります。 THP を使用すると、カーネルは大規模なメモリ ページを動的に管理できます。 たとえば、Java 仮想マシン (JVM) は、次のフラグを有効にすることで THP を利用できます。
-XX:+UseTransparentHugePages
THP の詳細については、「 Transparent HugePage のサポート」を参照してください。
HugePages の詳細については、「 HugeTLB Pages」を参照してください。
サンプル プログラムでの THP 使用率のテスト
システムで THP がどのように使用されているかを確認するには、約 256 MB の RAM を割り当てる小さな C プログラムを実行します。 このプログラムでは、 madvise システム呼び出しを使用して、THP がサポートされている場合、このメモリ領域で巨大なページを使用する必要があることを Linux カーネルに通知します。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <unistd.h>
#define LARGE_MEMORY_SIZE (256 * 1024 * 1024) // 256MB
int main() {
char str[2];
// Allocate a large memory area
void *addr = mmap(NULL, LARGE_MEMORY_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (addr == MAP_FAILED) {
perror("mmap");
return 1;
}
// Use madvise to give advice about the memory usage
if (madvise(addr, LARGE_MEMORY_SIZE, MADV_HUGEPAGE) != 0) {
perror("madvise");
munmap(addr, LARGE_MEMORY_SIZE);
return 1;
}
// Initialize the memory
int *array = (int *)addr;
for (int i = 0; i < LARGE_MEMORY_SIZE / sizeof(int); i++) {
array[i] = i;
}
memset(addr, 0, LARGE_MEMORY_SIZE);
printf("Press Enter to continue\n");
fgets(str,2,stdin);
// Clean up
if (munmap(addr, LARGE_MEMORY_SIZE) == -1) {
perror("munmap");
return 1;
}
return 0;
}
プログラムを実行した場合、THP がプログラムによって使用されているかどうかは直接観察できません。
/proc/meminfo ファイルを調べることで、システムの全体的な THP 使用率を確認できます。
AnonHugePages フィールドを調べて、THP を使用しているメモリの量を確認します。 このファイルは、システム全体の統計情報のみを提供します。
プロセスで THP が使用されているかどうかを確認するには、該当するプロセスの/proc ディレクトリにあるsmaps ファイルを調べる必要があります。 たとえば、 /proc/2275/smapsで、 heap という単語を含む行を検索します (右端に示されています)。
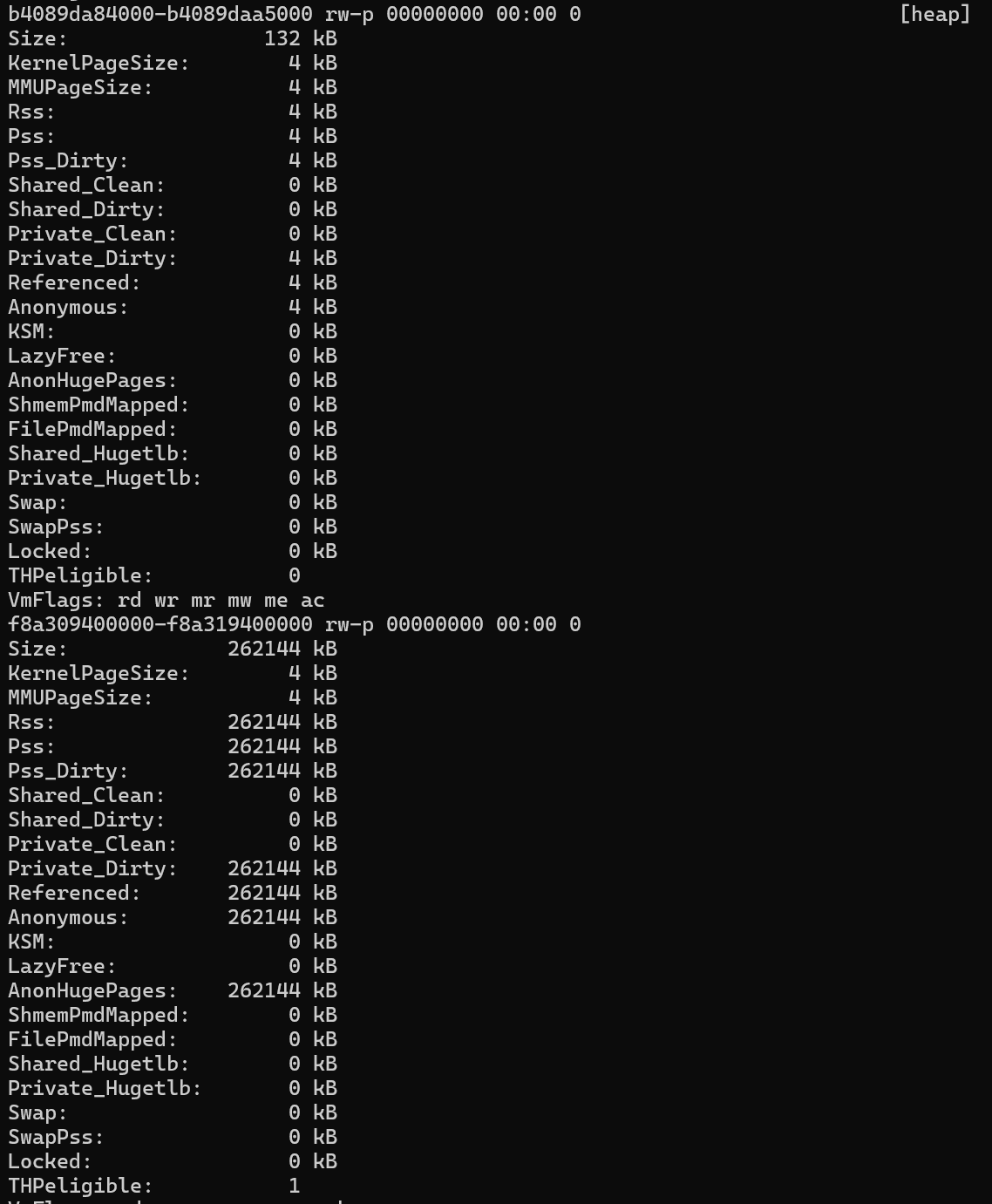
この例は、大きなメモリ セグメントが割り当てられ、 THPeligible (THP が使用中) としてマークされたことを示しています。
madvice syscallを使用すると、このメモリ ブロックの割り当てがはるかに効率的になります。 Huge Pages を使用すると、同じ効率を実現できます。 割り当てのサイズによっては、カーネルによって標準の 4 KB ページまたはより大きな連続したブロックが割り当てられる場合があります。 この最適化により、メモリ集中型アプリケーションのパフォーマンスが向上します。
詳細については、「 Transparent Hugepage Support」を参照してください。
NUMA
複数のノードを持つ NUMA システムでアプリケーションが実行されている場合は、各ノードのメモリ容量を把握することが重要です。 すべてのノードは、システムの合計メモリにアクセスできます。 ただし、特定の NUMA ノードで実行されるプロセスがそのノードの直接制御下にあるメモリで動作する場合は、最適なパフォーマンスが得られます。 ローカル ノードがメモリ要求を満たさない場合、システムは別のノードからメモリを割り当てます。 ただし、ノード間でメモリにアクセスすると待機時間が発生し、パフォーマンスが低下する可能性があります。 そのため、メモリの局所性を監視して、ワークロードが割り当てられた NUMA ノードのメモリ リソースと一致していることを確認する必要があります。
次のスクリーンショットは、システムの NUMA 構成のサンプルを示しています。
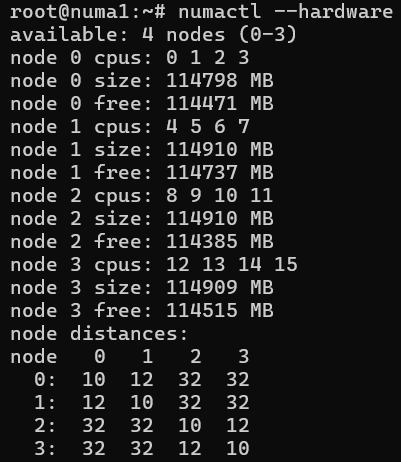
この構成は、同じノード内のメモリにアクセスする距離レベルが 10 であることを示しています。
Node 0からNode 1のメモリにアクセスする場合、このプロセスの距離値が高く、12ですが、対処可能です。 ただし、NODE 0からNODE 3のメモリにアクセスする場合、距離レベルは 32 になります。 このプロセスはまだ実行できますが、3 倍遅くなります。 パフォーマンスの問題を診断したり、メモリバインドワークロードを最適化したりする際には、これらの違いを考慮することが重要です。 詳細については、 この Linux カーネルの記事を参照してください。
numactl ツールの説明については、numactl(8) を参照してください。
プロセスの再調整が存在し、別のノードが必要かどうかを判断するには、 numastat ツールを使用します。 このツールのドキュメントは 、numastat(8) で入手できます。
migratepages ツール migratepages(8) は、メモリ ページを適切なノードに移動するのに役立ちます。
オーバーコミットとOOMキラー
オーバーコミットは、システムのパフォーマンスと安定性に深刻な影響を与える可能性のある重要な設計の選択です。 Linux カーネルでは、次の 3 つのモードがサポートされています。
- 'ヒューリスティック'
- 常に自分の限界を超えて取り組む
- 無理をしないでください
既定では、システムは Heuristic スキームを使用します。 このモードでは、メモリの過剰コミットを常に許可することと、厳密に拒否する間のバランスの取れたトレードオフが提供されます。 詳細については、 カーネルのドキュメントを参照してください。
オーバーコミット設定が正しくないと、メモリ ページがメモリを割り当てなくなる可能性があります。 この状態が原因で、新しいプロセスの作成が妨げられる可能性や、内部カーネル構造が十分なメモリを取得できなくなる可能性があります。
問題がメモリ割り当てに関連していることを確認した場合、この問題の最も可能性の高い原因は、カーネルに残っているリソースが不足していることです。 このような状況では、OOM (Out-Of-Memory) キラーが呼び出される可能性があります。 そのジョブは、カーネル タスクまたはその他のアプリケーションで使用するために、いくつかのメモリ ページを解放することです。 OOM キラーを呼び出すと、システムはリソース制限に達したことを警告します。 メモリ リークの可能性を排除できる場合、この状態の原因は、実行されているプロセスが多すぎること、または大量のメモリを消費しているプロセスである可能性があります。 この問題を解決するには、VM のサイズを大きくするか、一部のアプリケーションを別のサーバーに移動することを検討してください。
OOM イベント中に生成されたシステム ログ
このセクションでは、OOM キラーがトリガーされる瞬間を識別し、システムによってログに記録される情報を学習する手法について説明します。
次に示す単純な C プログラムは、システムで失敗するまでに動的に割り当てることができるメモリの量をテストします。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define ONEGB (1 << 30)
int main() {
int count = 0;
while (1) {
int *p = malloc(ONEGB);
if (p == NULL) {
printf("malloc refused after %d GB\n", count);
return 0;
}
memset(p,1,ONEGB);
printf("got %d GB\n", ++count);
}
}
このプログラムは、約 3 GB 後にメモリ割り当てが失敗することを示します。

システムがメモリ不足になると、OOM キラーが呼び出されます。 関連するログは、 dmesg コマンドを使用して表示できます。 ログ エントリは、通常、次のスクリーンショットに示すように開始されます。

通常、エントリはメモリ状態の概要で終わります。

これらのエントリの間には、メモリ使用量と、終了用に選択されたプロセスに関する詳細情報が表示されます。
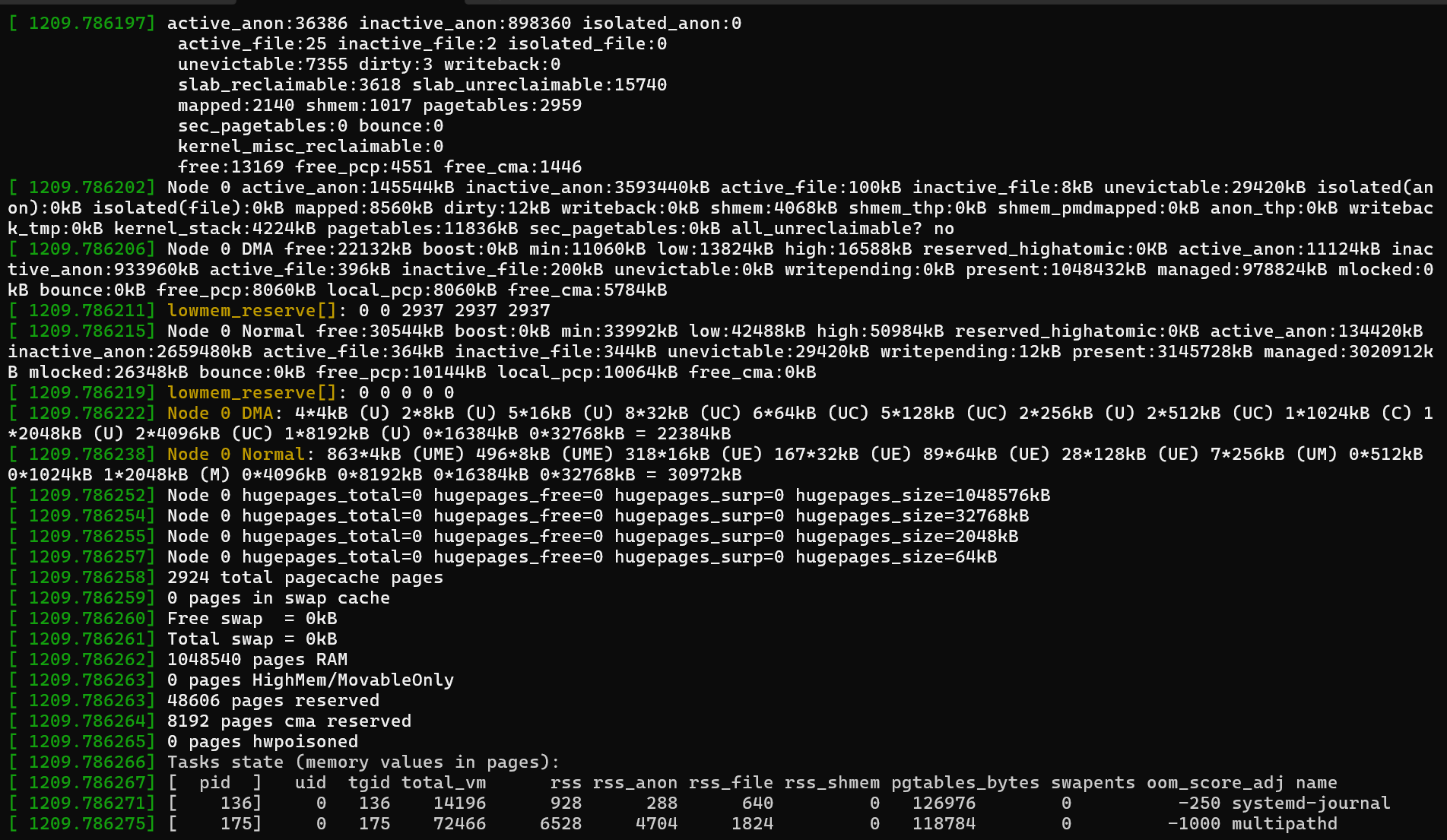
この情報から、次の分析情報を抽出できます。
4194160 kBytes physical memory
No swap space
3829648 kBytes are in use
次のログの例では、malloc プロセスが 4 KB のページ (order=0) を 1 つ要求しました。 4 KB ページは小さいですが、システムは既に負荷がかかっていました。 ログには、メモリが "標準ゾーン" から割り当てられていたことが示されます。

使用可能なメモリ (free) は 29,500 KB です。 ただし、最小透かし (min) は 34,628 KB です。 システムがこのしきい値を下回っているため、カーネルのみが残りのメモリを使用でき、ユーザー空間アプリケーションは拒否されます。 この時点で OOM キラーが呼び出されます。
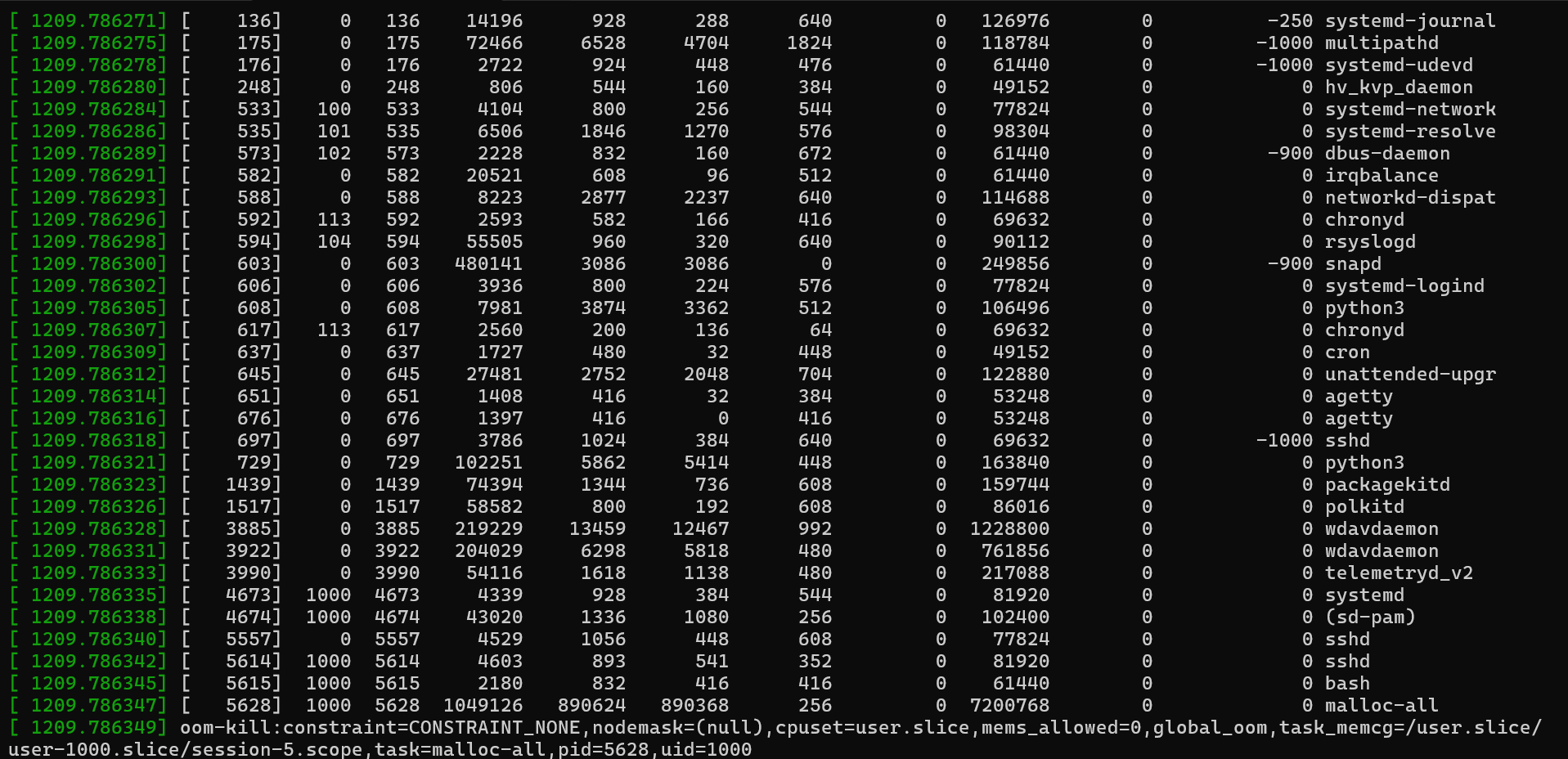
oom_scoreとメモリ使用量が最も多いプロセス ('RSS') を選択します。 この例では、malloc プロセスの oom_score は 0 ですが、 RSS も最も高くなっています (917760)。 したがって、終了のターゲットとして選択されます。
段階的なメモリの増加を監視する
OOM イベントは、関連するメッセージがコンソールとシステム ログに記録されるため、簡単に検出できます。 ただし、OOM イベントを引き起こさないメモリ使用量が徐々に増加すると、検出が困難になる可能性があります。
時間の経過に伴うメモリ使用量を監視するには、sysstat パッケージのsar ツールを使用します。 メモリの詳細に注目するには、"r" オプション ("sar -r" など) を使用します。
出力例
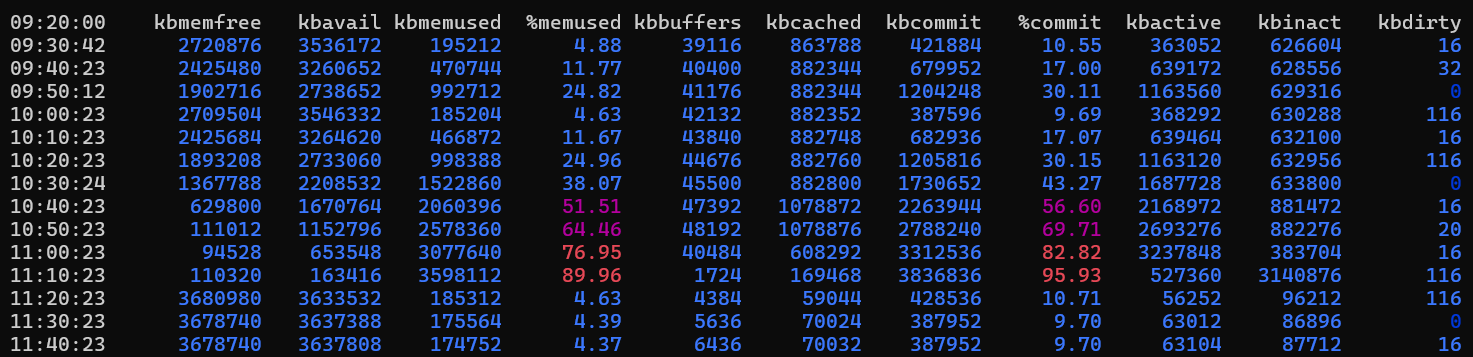
この場合、メモリ使用量は約 2 時間増加します。 その後、4% に戻ります。 この動作は、ログイン時間のピーク時やリソースを集中的に使用するレポート タスクなど、予想される場合があります。 この動作が正常かどうかを判断するには、数日間にわたって使用状況を監視し、それをアプリケーション アクティビティと関連付ける必要があります。 メモリ使用量が多い場合は必ずしも問題ではありません。 これは、ワークロードと、アプリケーションがメモリを使用するように設計されている方法によって異なります。
最も多くのメモリを消費しているプロセスを見つけるには、 pidstatを使用します。
出力例
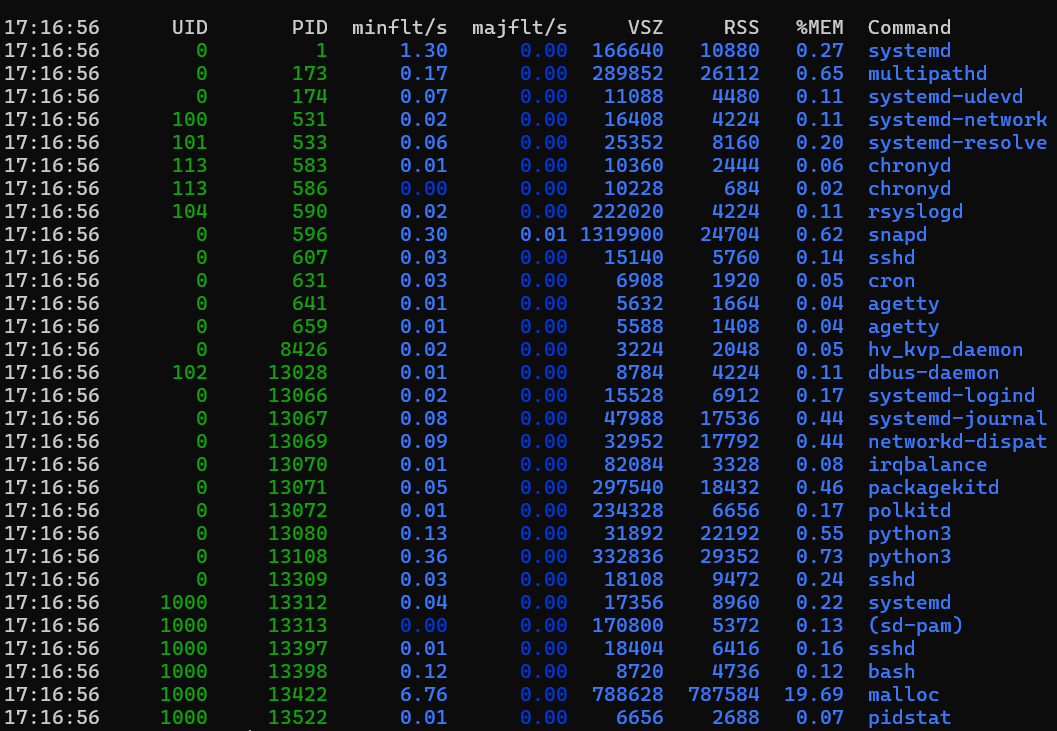
この出力には、実行中のすべてのプロセスとその統計情報が表示されます。 もう 1 つの方法は、'ps' ツールを使用して同様の結果を得る方法です。 ps aux --sort=-rss | head -n 10
出力例

RSS で並べ替える理由
常駐セット サイズ (RSS) は、RAM (スワップされていない物理メモリ) に保持されているプロセス メモリの部分です。 これに対し、仮想セット サイズ (VSZ) は、コミットされていないメモリを含め、プロセスが予約するメモリの合計量を表します。
Committed memory は、実際に物理メモリに書き込まれるページを指します。 最も物理メモリ (スワップを含む) を使用しているプロセスを特定しようとしている場合は、 RSS 列に注目します。 出力例では、 snapd プロセスは大量のメモリを使用しているように見えますが、 RSS 値は低くなっています。
malloc プロセスには、1.3 GB を超えるメモリがアクティブに使用されていることを示す、同様のVSZとRSSの値があります。
サードパーティのお問い合わせ窓口に関する免責事項
マイクロソフトは、このトピックについての追加情報を見つけるのに役立つよう、サードパーティの連絡先情報を提供しています。 この連絡先情報は予告なしに変更されることがあります。 マイクロソフトは、第三者の連絡先情報の正確性を保証しません。
お問い合わせはこちらから
質問がある場合やヘルプが必要な場合は、 サポートリクエストを作成するか、 Azure コミュニティ サポートに問い合わせてください。 Azure フィードバック コミュニティに製品フィードバックを送信することもできます。