GPOS - The Glyph Positioning Table (OpenType 1.6)
The Glyph Positioning table (GPOS) provides precise control over glyph placement for sophisticated text layout and rendering in each script and language system that a font supports.
Overview
Complex glyph positioning becomes an issue in writing systems, such as Vietnamese, that use diacritical and other marks to modify the sound or meaning of characters. These writing systems require controlled placement of all marks in relation to one another for legibility and linguistic accuracy.
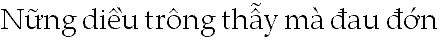
Other writing systems require sophisticated glyph positioning for correct typographic composition. For instance, Urdu glyphs are calligraphic and connect to one another along a descending, diagonal text line that proceeds from right to left. To properly render Urdu, a text-processing client must modify both the horizontal (X) and vertical (Y) positions of each glyph.
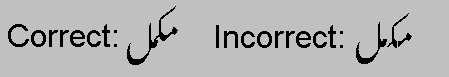
With the GPOS table, a font developer can define a complete set of positioning adjustment features in an OpenType™ font. GPOS data, organized by script and language system, is easy for a text-processing client to use to position glyphs.
Positioning Glyphs with TrueType 1.0
Glyph positioning in TrueType uses only two values, placement and advance, to specify a glyph’s position for text layout. If glyphs are positioned with respect to a virtual “pen point” that moves along a line of text, placement describes the glyph’s position with respect to the current pen point, and advance describes where to move the pen point to position the next glyph (see Figure 4c). For horizontal text, placement corresponds to the left side bearing, and advance corresponds to the advance width.

TrueType specifies placement and advance only in the X direction for horizontal layout and only in the Y direction for vertical layout. For simple Latin text layout, these two values may be adequate to position glyphs correctly. But, for texts that require more sophisticated layout, the values must cover a richer range. Placement and advance may need adjustment vertically, as well as horizontally.
The only positioning adjustment defined in TrueType is pair kerning, which modifies the horizontal spacing between two glyphs. A typical kerning table lists pairs of glyphs and specifies how much space a text-processing client should add or remove between the glyphs to properly display each pair. It does not provide specific information about how to adjust the glyphs in each pair, and cannot adjust contexts of more than two glyphs.
Positioning Glyphs with OpenType
OpenType fonts allow excellent control and flexibility for positioning a single glyph and for positioning multiple glyphs in relation to one another. By using both X and Y values that the GPOS table defines for placement and advance and by using glyph attachment points, a client can more precisely adjust the position of a glyph.
In addition, the GPOS table can reference a Device table to define subtle, device-dependent adjustments to any placement or advance value at any font size and device resolution. For example, a Device table can specify adjustments at 51 pixels per em (ppem) that do not occur at 50 ppem.
X and Y values specified in OpenType fonts for placement operations are always within the typical Cartesian coordinate system (origin at the baseline of the left side), regardless of the writing direction. Additionally, all values specified are done so in font unit measurements. This is especially convenient for font designers, since glyphs are drawn in the same coordinate system. However, it’s important to note that the meaning of “advance width” changes, depending on the writing direction.
For example, in left-to-right scripts, if the first glyph has an advance width of 100, then the second glyph begins at 100,0. In right-to-left scripts, if the first glyph has an advance width of 100, then the second glyph begins at -100,0. For a top-to-bottom feature, to increase the advance height of a glyph by 100, the YAdvance = 100. For any feature, regardless of writing direction, to lower the dieresis over an ‘o’ by 10 units, set the YPlacement = -10.
Other GPOS features can define attachment points to combine glyphs and position them with respect to one another. A glyph might have multiple attachment points. The point used will depend on the glyph to be attached. For instance, a base glyph could have attachment points for different diacritical marks.
To reduce the size of the font file, a base glyph may use the same attachment point for all mark glyphs assigned to a particular class. For example, a base glyph could have two attachment points, one above and one below the glyph. Then all marks that attach above glyphs would be attached at the high point, and all marks that attach below glyphs would be attached at the low point. Attachment points are useful in scripts, such as Arabic, that combine numerous glyphs with vowel marks.
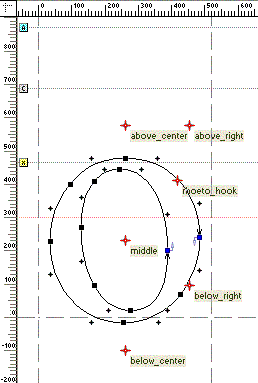
Attachment points also are useful for connecting cursive-style glyphs. Glyphs in cursive fonts can be designed to attach or overlap when rendered. Alternatively, the font developer can use OpenType to create a cursive attachment feature and define explicit exit and entry attachment points for each glyph (see Figure 4d).
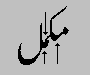
The GPOS table supports eight types of actions for positioning and attaching glyphs:
- A single adjustment positions one glyph, such as a superscript or subscript.
- A pair adjustment positions two glyphs with respect to one another. Kerning is an example of pair adjustment.
- A cursive attachment describes cursive scripts and other glyphs that are connected with attachment points when rendered.
- A MarkToBase attachment positions combining marks with respect to base glyphs, as when positioning vowels, diacritical marks, or tone marks in Arabic, Hebrew, and Vietnamese.
- A MarkToLigature attachment positions combining marks with respect to ligature glyphs. Because ligatures may have multiple points for attaching marks, the font developer needs to associate each mark with one of the ligature glyph’s components.
- A MarkToMark attachment positions one mark relative to another, as when positioning tone marks with respect to vowel diacritical marks in Vietnamese.
- Contextual positioning describes how to position one or more glyphs in context, within an identifiable sequence of specific glyphs, glyph classes, or varied sets of glyphs. One or more positioning operations may be performed on “input” context sequences. Figure 4e illustrates a context for positioning adjustments.
- Chaining Contextual positioning describes how to position one or more glyphs in a chained context, within an identifiable sequence of specific glyphs, glyph classes, or varied sets of glyphs. One or more positioning operations may be performed on “input” context sequences.
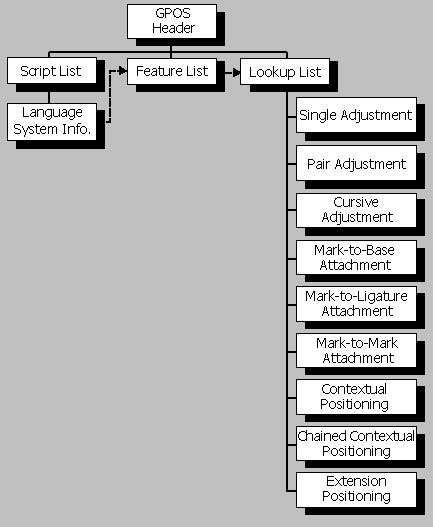
Table Organization
The GPOS table begins with a header that defines offsets to a ScriptList, a FeatureList, and a LookupList (see Figure 4f):
- The ScriptList identifies all the scripts and language systems in the font that use glyph positioning.
- The FeatureList defines all the glyph positioning features required to render these scripts and language systems.
- The LookupList contains all the lookup data needed to implement each glyph positioning feature.
For a detailed discussion of ScriptLists, FeatureLists, and LookupLists, see the chapter, OpenType Common Table Formats . The following discussion summarizes how the GPOS table works.
The GPOS table is organized so text processing clients can easily locate the features and lookups that apply to a particular script or language system. To access GPOS information, clients should use the following procedure:
- Locate the current script in the GPOS ScriptList table.
- If the language system is known, search the script for the correct LangSys table; otherwise, use the script’s default language system (DefaultLangSys table).
- The LangSys table provides index numbers into the GPOS FeatureList table to access a required feature and a number of additional features.
- Inspect the FeatureTag of each feature, and select the features to apply to an input glyph string.
- Each feature provides an array of index numbers into the GPOS LookupList table. Lookup data is defined in one or more subtables that contain information about specific glyphs and the kinds of operations to be performed on them.
- Assemble all lookups from the set of chosen features, and apply the lookups in the order given in the LookupList table.
A lookup uses subtables to define the specific conditions, type, and results of a positioning action used to implement a feature. All subtables in a lookup must be of the same LookupType, as listed in the LookupType Enumeration table:
LookupType Enumeration table for glyph positioning
| Value | Type | Description |
|---|---|---|
| 1 | Single adjustment | Adjust position of a single glyph |
| 2 | Pair adjustment | Adjust position of a pair of glyphs |
| 3 | Cursive attachment | Attach cursive glyphs |
| 4 | MarkToBase attachment | Attach a combining mark to a base glyph |
| 5 | MarkToLigature attachment | Attach a combining mark to a ligature |
| 6 | MarkToMark attachment | Attach a combining mark to another mark |
| 7 | Context positioning | Position one or more glyphs in context |
| 8 | Chained Context positioning | Position one or more glyphs in chained context |
| 9 | Extension positioning | Extension mechanism for other positionings |
| 10+ | Reserved | For future use (set to zero) |
Each LookupType is defined by one or more subtables, whose format depends on the type of positioning operation and the resulting storage efficiency. When glyph information is best presented in more than one format, a single lookup may define more than one subtable, as long as all the subtables are of the same LookupType. For example, within a given lookup, a glyph index array format may best represent one set of target glyphs, whereas a glyph index range format may be better for another set.
A series of positioning operations on the same glyph or string requires multiple lookups, one for each separate action. The values in the ValueRecords are accumulated in these cases. Each lookup is given a different array number in the LookupList table and is applied in the LookupList order.
During text processing, a client applies a lookup to each glyph in the string before moving to the next lookup. A lookup is finished for a glyph after the client locates the target glyph or glyph context and performs a positioning, if specified. To move to the “next” glyph, the client will typically skip all the glyphs that participated in the lookup operation: glyphs that were positioned as well as any other glyphs that formed a context for the operation.
There is just one exception: the “next” glyph in a sequence may be one of those that formed a context for the operation just performed. For example, in the case of pair positioning operations (i.e., kerning), if the position value record for the second glyph is null, that glyph is treated as the “next” glyph in the sequence.
This rest of this chapter describes the GPOS header and the subtables defined for each LookupType. Several GPOS subtables share other tables: ValueRecords, Anchor tables, and MarkArrays. For easy reference, the shared tables are described at the end of this chapter.
GPOS Header
The GPOS table begins with a header that contains a version number (Version) initially set to 1.0 (0x00010000) and offsets to three tables: ScriptList, FeatureList, and LookupList. For descriptions of these tables, see the chapter, OpenType Common Table Formats . Example 1 at the end of this chapter shows a GPOS Header table definition.
GPOS Header
| Value | Type | Description |
|---|---|---|
| Fixed | Version | Version of the GPOS table-initially = 0x00010000 |
| Offset | ScriptList | Offset to ScriptList table-from beginning of GPOS table |
| Offset | FeatureList | Offset to FeatureList table-from beginning of GPOS table |
| Offset | LookupList | Offset to LookupList table-from beginning of GPOS table |
Lookup Type 1: Single Adjustment Positioning Subtable
A single adjustment positioning subtable (SinglePos) is used to adjust the position of a single glyph, such as a subscript or superscript. In addition, a SinglePos subtable is commonly used to implement lookup data for contextual positioning.
A SinglePos subtable will have one of two formats: one that applies the same adjustment to a series of glyphs, or one that applies a different adjustment for each unique glyph.
Single Adjustment Positioning: Format 1
A SinglePosFormat1 subtable applies the same positioning value or values to each glyph listed in its Coverage table. For instance, when a font uses old-style numerals, this format could be applied to uniformly lower the position of all math operator glyphs.
The Format 1 subtable consists of a format identifier (PosFormat), an offset to a Coverage table that defines the glyphs to be adjusted by the positioning values (Coverage), and the format identifier (ValueFormat) that describes the amount and kinds of data in the ValueRecord.
The ValueRecord specifies one or more positioning values to be applied to all covered glyphs (Value). For example, if all glyphs in the Coverage table require both horizontal and vertical adjustments, the ValueRecord will specify values for both XPlacement and Yplacement.
Example 2 at the end of this chapter shows a SinglePosFormat1 subtable used to adjust the placement of subscript glyphs.
SinglePosFormat1 subtable: Single positioning value
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of SinglePos subtable |
| uint16 | ValueFormat | Defines the types of data in the ValueRecord |
| ValueRecord | Value | Defines positioning value(s)-applied to all glyphs in the Coverage table |
Single Adjustment Positioning: Format 2
A SinglePosFormat2 subtable provides an array of ValueRecords that contains one positioning value for each glyph in the Coverage table. This format is more flexible than Format 1, but it requires more space in the font file.
For example, assume that the Cyrillic script will be used in left-justified text. For all glyphs, Format 2 could define position adjustments for left side bearings to align the left edges of the paragraphs. To achieve this, the Coverage table would list every glyph in the script, and the SinglePosFormat2 subtable would define a ValueRecord for each covered glyph. Correspondingly, each ValueRecord would specify an XPlacement adjustment value for the left side bearing.
Note: All ValueRecords defined in a SinglePos subtable must have the same ValueFormat. In this example, if XPlacement is the only value that a ValueRecord needs to optically align the glyphs, then XPlacement will be the only value specified in the ValueFormat of the subtable.
As in Format 1, the Format 2 subtable consists of a format identifier (PosFormat), an offset to a Coverage table that defines the glyphs to be adjusted by the positioning values (Coverage), and the format identifier (ValueFormat) that describes the amount and kinds of data in the ValueRecords. In addition, the Format 2 subtable includes:
- A count of the ValueRecords (ValueCount). One ValueRecord is defined for each glyph in the Coverage table.
- An array of ValueRecords that specify positioning values (Value). Because the array follows the Coverage Index order, the first ValueRecord applies to the first glyph listed in the Coverage table, and so on.
Example 3 at the end of this chapter shows how to adjust the spacing of three dash glyphs with a SinglePosFormat2 subtable.
SinglePosFormat2 subtable: Array of positioning values
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of SinglePos subtable |
| uint16 | ValueFormat | Defines the types of data in the ValueRecord |
| uint16 | ValueCount | Number of ValueRecords |
| ValueRecord | Value [ValueCount] |
Array of ValueRecords-positioning values applied to glyphs |
Lookup Type 2: Pair Adjustment Positioning Subtable
A pair adjustment positioning subtable (PairPos) is used to adjust the positions of two glyphs in relation to one another-for instance, to specify kerning data for pairs of glyphs. Compared to a typical kerning table, however, a PairPos subtable offers more flexiblity and precise control over glyph positioning. The PairPos subtable can adjust each glyph in a pair independently in both the X and Y directions, and it can explicitly describe the particular type of adjustment applied to each glyph. In addition, a PairPos subtable can use Device tables to subtly adjust glyph positions at each font size and device resolution.
PairPos subtables can be either of two formats: one that identifies glyphs individually by index (Format 1), or one that identifies glyphs by class (Format 2).
Pair Positioning Adjustment: Format 1
Format 1 uses glyph indices to access positioning data for one or more specific pairs of glyphs. All pairs are specified in the order determined by the layout direction of the text.
Note: For text written from right to left, the right-most glyph will be the first glyph in a pair; conversely, for text written from left to right, the left-most glyph will be first.
A PairPosFormat1 subtable contains a format identifier (PosFormat) and two ValueFormats:
- ValueFormat1 applies to the ValueRecord of the first glyph in each pair. ValueRecords for all first glyphs must use ValueFormat1. If ValueFormat1 is set to zero (0), the corresponding glyph has no ValueRecord and, therefore, should not be repositioned.
- ValueFormat2 applies to the ValueRecord of the second glyph in each pair. ValueRecords for all second glyphs must use ValueFormat2. If ValueFormat2 is set to null, then the second glyph of the pair is the “next” glyph for which a lookup should be performed.
A PairPos subtable also defines an offset to a Coverage table (Coverage) that lists the indices of the first glyphs in each pair. More than one pair can have the same first glyph, but the Coverage table will list that glyph only once.
The subtable also contains an array of offsets to PairSet tables (PairSet) and a count of the defined tables (PairSetCount). The PairSet array contains one offset for each glyph listed in the Coverage table and uses the same order as the Coverage Index.
PairPosFormat1 subtable: Adjustments for glyph pairs
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of PairPos subtable-only the first glyph in each pair |
| uint16 | ValueFormat1 | Defines the types of data in ValueRecord1-for the first glyph in the pair -may be zero (0) |
| uint16 | ValueFormat2 | Defines the types of data in ValueRecord2-for the second glyph in the pair -may be zero (0) |
| uint16 | PairSetCount | Number of PairSet tables |
| Offset | PairSetOffset [PairSetCount] |
Array of offsets to PairSet tables-from beginning of PairPos subtable-ordered by Coverage Index |
A PairSet table enumerates all the glyph pairs that begin with a covered glyph. An array of PairValueRecords (PairValueRecord) contains one record for each pair and lists the records sorted by the GlyphID of the second glyph in each pair. PairValueCount specifies the number of PairValueRecords in the set.
PairSet table
| Value | Type | Description |
|---|---|---|
| uint16 | PairValueCount | Number of PairValueRecords |
| struct | PairValueRecord [PairValueCount] |
Array of PairValueRecords-ordered by GlyphID of the second glyph |
A PairValueRecord specifies the second glyph in a pair (SecondGlyph) and defines a ValueRecord for each glyph (Value1 and Value2). If ValueFormat1 is set to zero (0) in the PairPos subtable, ValueRecord1 will be empty; similarly, if ValueFormat2 is 0, Value2 will be empty.
Example 4 at the end of this chapter shows a PairPosFormat1 subtable that defines two cases of pair kerning.
PairValueRecord
| Value | Type | Description |
|---|---|---|
| GlyphID | SecondGlyph | GlyphID of second glyph in the pair-first glyph is listed in the Coverage table |
| ValueRecord | Value1 | Positioning data for the first glyph in the pair |
| ValueRecord | Value2 | Positioning data for the second glyph in the pair |
Pair Positioning Adjustment: Format 2
Format 2 defines a pair as a set of two glyph classes and modifies the positions of all the glyphs in a class. For example, this format is useful in Japanese scripts that apply specific kerning operations to all glyph pairs that contain punctuation glyphs. One class would be defined as all glyphs that may be coupled with punctuation marks, and the other classes would be groups of similar punctuation glyphs.
The PairPos Format2 subtable begins with a format identifier (PosFormat) and an offset to a Coverage table (Coverage), measured from the beginning of the PairPos subtable. The Coverage table lists the indices of the first glyphs that may appear in each glyph pair. More than one pair may begin with the same glyph, but the Coverage table lists the glyph index only once.
A PairPosFormat2 subtable also includes two ValueFormats:
- ValueFormat1 applies to the ValueRecord of the first glyph in each pair. ValueRecords for all first glyphs must use ValueFormat1. If ValueFormat1 is set to zero (0), the corresponding glyph has no ValueRecord and, therefore, should not be repositioned.
- ValueFormat2 applies to the ValueRecord of the second glyph in each pair. ValueRecords for all second glyphs must use ValueFormat2. If ValueFormat2 is set to null, then the second glyph of the pair is the “next” glyph for which a lookup should be performed.
PairPosFormat2 requires that each glyph in all pairs be assigned to a class, which is identified by an integer called a class value. (For details about classes, see the chapter, OpenType Common Table Formats.) Pairs are then represented in a two-dimensional array as sequences of two class values. Multiple pairs can be represented in one Format 2 subtable.
A PairPosFormat2 subtable contains offsets to two class definition tables: one that assigns class values to all the first glyphs in all pairs (ClassDef1), and one that assigns class values to all the second glyphs in all pairs (ClassDef2). If both glyphs in a pair use the same class definition, the offset value can be the same for ClassDef1 and ClassDef2, but they are not required to be the same. The subtable also specifies the number of glyph classes defined in ClassDef1 (Class1Count) and in ClassDef2 (Class2Count), including Class0.
For each class identified in the ClassDef1 table, a Class1Record enumerates all pairs that contain a particular class as a first component. The Class1Record array stores all Class1Records according to class value.
Note: Class1Records are not tagged with a class value identifier. Instead, the index value of a Class1Record in the array defines the class value represented by the record. For example, the first Class1Record enumerates pairs that begin with a Class 0 glyph, the second Class1Record enumerates pairs that begin with a Class1 glyph, and so on.
PairPosFormat2 subtable: Class pair adjustment
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of PairPos subtable-for the first glyph of the pair |
| uint16 | ValueFormat1 | ValueRecord definition-for the first glyph of the pair-may be zero (0) |
| uint16 | ValueFormat2 | ValueRecord definition-for the second glyph of the pair-may be zero (0) |
| Offset | ClassDef1 | Offset to ClassDef table-from beginning of PairPos subtable-for the first glyph of the pair |
| Offset | ClassDef2 | Offset to ClassDef table-from beginning of PairPos subtable-for the second glyph of the pair |
| uint16 | Class1Count | Number of classes in ClassDef1 table-includes Class0 |
| uint16 | Class2Count | Number of classes in ClassDef2 table-includes Class0 |
| struct | Class1Record [Class1Count] |
Array of Class1 records-ordered by Class1 |
Each Class1Record contains an array of Class2Records (Class2Record), which also are ordered by class value. One Class2Record must be declared for each class in the ClassDef2 table, including Class 0.
Class1Record
| Value | Type | Description |
|---|---|---|
| struct | Class2Record[Class2Count] | Array of Class2 records-ordered by Class2 |
A Class2Record consists of two ValueRecords, one for the first glyph in a class pair (Value1) and one for the second glyph (Value2). If the PairPos subtable has a value of zero (0) for ValueFormat1 or ValueFormat2, the corresponding record (ValueRecord1 or ValueRecord2) will be empty.
Example 5 at the end of this chapter demonstrates pair kerning with glyph classes in a PairPosFormat2 subtable.
Class2Record
| Value | Type | Description |
|---|---|---|
| ValueRecord | Value1 | Positioning for first glyph-empty if ValueFormat1 = 0 |
| ValueRecord | Value2 | Positioning for second glyph-empty if ValueFormat2 = 0 |
Lookup Type 3: Cursive Attachment Positioning Subtable
Some cursive fonts are designed so that adjacent glyphs join when rendered with their default positioning. However, if positioning adjustments are needed to join the glyphs, a cursive attachment positioning (CursivePos) subtable can describe how to connect the glyphs by aligning two anchor points: the designated exit point of a glyph, and the designated entry point of the following glyph.
The subtable has one format: CursivePosFormat1. It begins with a format identifier (PosFormat) and an offset to a Coverage table (Coverage), which lists all the glyphs that define cursive attachment data.
In addition, the subtable contains one EntryExitRecord for each glyph listed in the Coverage table, a count of those records (EntryExitCount), and an array of those records in the same order as the Coverage Index (EntryExitRecord).
CursivePosFormat1 subtable: Cursive attachment
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of CursivePos subtable |
| uint16 | EntryExitCount | Number of EntryExit records |
| struct | EntryExitRecord[EntryExitCount] | Array of EntryExit records-in Coverage Index order |
Each EntryExitRecord consists of two offsets: one to an Anchor table that identifies the entry point on the glyph (EntryAnchor), and an offset to an Anchor table that identifies the exit point on the glyph (ExitAnchor). (For a complete description of the Anchor table, see the end of this chapter.)
To position glyphs using the CursivePosFormat1 subtable, a text-processing client aligns the ExitAnchor point of a glyph with the EntryAnchor point of the following glyph. If no corresponding anchor point exists, either the EntryAnchor or ExitAnchor offset may be NULL.
At the end of this chapter, Example 6 describes cursive glyph attachment in the Urdu language.
EntryExitRecord
| Value | Type | Description |
|---|---|---|
| Offset | EntryAnchor | Offset to EntryAnchor table-from beginning of CursivePos subtable-may be NULL |
| Offset | ExitAnchor | Offset to ExitAnchor table-from beginning of CursivePos subtable-may be NULL |
Lookup Type 4: MarkToBase Attachment Positioning Subtable
The MarkToBase attachment (MarkBasePos) subtable is used to position combining mark glyphs with respect to base glyphs. For example, the Arabic, Hebrew, and Thai scripts combine vowels, diacritical marks, and tone marks with base glyphs.
In the MarkBasePos subtable, every mark glyph has an anchor point and is associated with a class of marks. Each base glyph then defines an anchor point for each class of marks it uses.
For example, assume two mark classes: all marks positioned above base glyphs (Class 0), and all marks positioned below base glyphs (Class 1). In this case, each base glyph that uses these marks would define two anchor points, one for attaching the mark glyphs listed in Class 0, and one for attaching the mark glyphs listed in Class 1.
To identify the base glyph that combines with a mark, the text-processing client must look backward in the glyph string from the mark to the preceding base glyph. To combine the mark and base glyph, the client aligns their attachment points, positioning the mark with respect to the final pen point (advance) position of the base glyph.
The MarkToBase Attachment subtable has one format: MarkBasePosFormat1. The subtable begins with a format identifier (PosFormat) and offsets to two Coverage tables: one that lists all the mark glyphs referenced in the subtable (MarkCoverage), and one that lists all the base glyphs referenced in the subtable (BaseCoverage).
For each mark glyph in the MarkCoverage table, a record specifies its class and an offset to the Anchor table that describes the mark’s attachment point (MarkRecord). A mark class is identified by a specific integer, called a class value. ClassCount specifies the total number of distinct mark classes defined in all the MarkRecords.
The MarkBasePosFormat1 subtable also contains an offset to a MarkArray table, which contains all the MarkRecords stored in an array (MarkRecord) by MarkCoverage Index. A MarkArray table also contains a count of the defined MarkRecords (MarkCount). (For details about MarkArrays and MarkRecords, see the end of this chapter.)
The MarkBasePosFormat1 subtable also contains an offset to a BaseArray table (BaseArray).
MarkBasePosFormat1 subtable: MarkToBase attachment point
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | MarkCoverage | Offset to MarkCoverage table-from beginning of MarkBasePos subtable |
| Offset | BaseCoverage | Offset to BaseCoverage table-from beginning of MarkBasePos subtable |
| uint16 | ClassCount | Number of classes defined for marks |
| Offset | MarkArray | Offset to MarkArray table-from beginning of MarkBasePos subtable |
| Offset | BaseArray | Offset to BaseArray table-from beginning of MarkBasePos subtable |
The BaseArray table consists of an array (BaseRecord) and count (BaseCount) of BaseRecords. The array stores the BaseRecords in the same order as the BaseCoverage Index. Each base glyph in the BaseCoverage table has a BaseRecord.
BaseArray table
| Value | Type | Description |
|---|---|---|
| uint16 | BaseCount | Number of BaseRecords |
| struct | BaseRecord[BaseCount] | Array of BaseRecords-in order of BaseCoverage Index |
A BaseRecord declares one Anchor table for each mark class (including Class 0) identified in the MarkRecords of the MarkArray. Each Anchor table specifies one attachment point used to attach all the marks in a particular class to the base glyph. A BaseRecord contains an array of offsets to Anchor tables (BaseAnchor). The zero-based array of offsets defines the entire set of attachment points each base glyph uses to attach marks. The offsets to Anchor tables are ordered by mark class.
Note: Anchor tables are not tagged with class value identifiers. Instead, the index value of an Anchor table in the array defines the class value represented by the Anchor table.
Example 7 at the end of this chapter defines mark positioning above and below base glyphs with a MarkBasePosFormat1 subtable.
BaseRecord
| Value | Type | Description |
|---|---|---|
| Offset | BaseAnchor[ClassCount] | Array of offsets (one per class) to Anchor tables-from beginning of BaseArray table-ordered by class-zero-based |
Lookup Type 5: MarkToLigature Attachment Positioning Subtable
The MarkToLigature attachment (MarkLigPos) subtable is used to position combining mark glyphs with respect to ligature base glyphs. With MarkToBase attachment, described previously, a single base glyph defines an attachment point for each class of marks. In contrast, MarkToLigature attachment describes ligature glyphs composed of several components that can each define an attachment point for each class of marks.
As a result, a ligature glyph may have multiple base attachment points for one class of marks. The specific attachment point for a mark is defined by the ligature component that the subtable associates with the mark.
The MarkLigPos subtable can be used to define multiple mark-to-ligature attachments. In the subtable, every mark glyph has an anchor point and is associated with a class of marks. Every ligature glyph specifies a two-dimensional array of data: each component in a ligature defines an array of anchor points, one for each class of marks.
For example, assume two mark classes: all marks positioned above base glyphs (Class 0), and all marks positioned below base glyphs (Class 1). In this case, each component of a base ligature glyph may define two anchor points, one for attaching the mark glyphs listed in Class 0, and one for attaching the mark glyphs listed in Class 1. Alternatively, if the language system does not allow marks on the second component, the first ligature component may define two anchor points, one for each class of marks, and the second ligature component may define no anchor points.
To position a combining mark using a MarkToLigature attachment subtable, the text-processing client must work backward from the mark to the preceding ligature glyph. To correctly access the subtables, the client must keep track of the component associated with the mark. Aligning the attachment points combines the mark and ligature.
The MarkToLigature attachment subtable has one format: MarkLigPosFormat1. The subtable begins with a format identifier (PosFormat) and offsets to two Coverage tables that list all the mark glyphs (MarkCoverage) and Ligature glyphs (LigatureCoverage) referenced in the subtable.
For each glyph in the MarkCoverage table, a MarkRecord specifies its class and an offset to the Anchor table that describes the mark’s attachment point. A mark class is identified by a specific integer, called a class value. ClassCount records the total number of distinct mark classes defined in all MarkRecords.
The MarkBasePosFormat1 subtable contains an offset, measured from the beginning of the subtable, to a MarkArray table, which contains all MarkRecords stored in an array (MarkRecord) by MarkCoverage Index. (For details about MarkArrays and MarkRecords, see the end of this chapter.)
The MarkLigPosFormat1 subtable also contains an offset to a LigatureArray table (LigatureArray).
MarkLigPosFormat1 subtable: MarkToLigature attachment
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | MarkCoverage | Offset to Mark Coverage table-from beginning of MarkLigPos subtable |
| Offset | LigatureCoverage | Offset to Ligature Coverage table-from beginning of MarkLigPos subtable |
| uint16 | ClassCount | Number of defined mark classes |
| Offset | MarkArray | Offset to MarkArray table-from beginning of MarkLigPos subtable |
| Offset | LigatureArray | Offset to LigatureArray table-from beginning of MarkLigPos subtable |
The LigatureArray table contains a count (LigatureCount) and an array of offsets (LigatureAttach) to LigatureAttach tables. The LigatureAttach array lists the offsets to LigatureAttach tables, one for each ligature glyph listed in the LigatureCoverage table, in the same order as the LigatureCoverage Index.
LigatureArray table
| Value | Type | Description |
|---|---|---|
| uint16 | LigatureCount | Number of LigatureAttach table offsets |
| Offset | LigatureAttach [LigatureCount] |
Array of offsets to LigatureAttach tables-from beginning of LigatureArray table-ordered by LigatureCoverage Index |
Each LigatureAttach table consists of an array (ComponentRecord) and count (ComponentCount) of the component glyphs in a ligature. The array stores the ComponentRecords in the same order as the components in the ligature. The order of the records also corresponds to the writing direction of the text. For text written left to right, the first component is on the left; for text written right to left, the first component is on the right.
LigatureAttach table
| Value | Type | Description |
|---|---|---|
| uint16 | ComponentCount | Number of ComponentRecords in this ligature |
| struct | ComponentRecord[ComponentCount] | Array of Component records-ordered in writing direction |
A ComponentRecord, one for each component in the ligature, contains an array of offsets to the Anchor tables that define all the attachment points used to attach marks to the component (LigatureAnchor). For each mark class (including Class 0) identified in the MarkArray records, an Anchor table specifies the point used to attach all the marks in a particular class to the ligature base glyph, relative to the component.
In a ComponentRecord, the zero-based LigatureAnchor array lists offsets to Anchor tables by mark class. If a component does not define an attachment point for a particular class of marks, then the offset to the corresponding Anchor table will be NULL.
Example 8 at the end of this chapter shows a MarkLisPosFormat1 subtable used to attach mark accents to a ligature glyph in the Arabic script.
ComponentRecord
| Value | Type | Description |
|---|---|---|
| Offset | LigatureAnchor [ClassCount] |
Array of offsets (one per class) to Anchor tables-from beginning of LigatureAttach table-ordered by class-NULL if a component does not have an attachment for a class-zero-based array |
Lookup Type 6: MarkToMark Attachment Positioning Subtable
The MarkToMark attachment (MarkMarkPos) subtable is identical in form to the MarkToBase attachment subtable, although its function is different. MarkToMark attachment defines the position of one mark relative to another mark as when, for example, positioning tone marks with respect to vowel diacritical marks in Vietnamese.
The attaching mark is Mark1, and the base mark being attached to is Mark2. In the MarkMarkPos subtable, every Mark1 glyph has an anchor attachment point and is associated with a class of marks. Each Mark2 glyph defines an anchor point for each class of marks. For example, assume two Mark1 classes: all marks positioned to the left of Mark2 glyphs (Class 0), and all marks positioned to the right of Mark2 glyphs (Class 1). Each Mark2 glyph that uses these marks defines two anchor points: one for attaching the Mark1 glyphs listed in Class 0, and one for attaching the Mark1 glyphs listed in Class 1.
The Mark2 glyph that combines with a Mark1 glyph is the glyph preceding the Mark1 glyph in glyph string order (skipping glyphs according to LookupFlags). The subtable applies precisely when that Mark2 glyph is covered by Mark2Coverage. To combine the mark glyphs, the Mark1 glyph is moved such that the relevant attachment points coincide. The input context for MarkToBase, MarkToLigature and MarkToMark positioning tables is the mark that is being positioned. If a sequence contains several marks, a lookup may act on it several times, to position them.
The MarkToMark attachment subtable has one format: MarkMarkPosFormat1. The subtable begins with a format identifier (PosFormat) and offsets to two Coverage tables: one that lists all the Mark1 glyphs referenced in the subtable (Mark1Coverage), and one that lists all the Mark2 glyphs referenced in the subtable (Mark2Coverage).
For each mark glyph in the Mark1Coverage table, a MarkRecord specifies its class and an offset to the Anchor table that describes the mark’s attachment point. A mark class is identified by a specific integer, called a class value. (For details about classes, see the chapter, OpenType Common Table Formats.) ClassCount specifies the total number of distinct mark classes defined in all the MarkRecords.
The MarkMarkPosFormat1 subtable also contains two offsets, measured from the beginning of the subtable, to two arrays:
- The MarkArray table contains all MarkRecords stored by Mark1Coverage Index in an array (MarkRecord). The MarkArray table also contains a count of the number of defined MarkRecords (MarkCount).
- The Mark2Array table consists of an array (Mark2Record) and count (Mark2Count) of Mark2Records.
For details about MarkArrays and MarkRecords, see the end of this chapter.
MarkMarkPosFormat1 subtable: MarkToMark attachment
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Mark1Coverage | Offset to Combining Mark Coverage table-from beginning of MarkMarkPos subtable |
| Offset | Mark2Coverage | Offset to Base Mark Coverage table-from beginning of MarkMarkPos subtable |
| uint16 | ClassCount | Number of Combining Mark classes defined |
| Offset | Mark1Array | Offset to MarkArray table for Mark1-from beginning of MarkMarkPos subtable |
| Offset | Mark2Array | Offset to Mark2Array table for Mark2-from beginning of MarkMarkPos subtable |
The Mark2Array, shown next, contains one Mark2Record for each Mark2 glyph listed in the Mark2Coverage table. It stores the records in the same order as the Mark2Coverage Index.
Mark2Array table
| Value | Type | Description |
|---|---|---|
| uint16 | Mark2Count | Number of Mark2 records |
| struct | Mark2Record [Mark2Count] |
Array of Mark2 records-in Coverage order |
Each Mark2Record contains an array of offsets to Anchor tables (Mark2Anchor). The array of zero-based offsets, measured from the beginning of the Mark2Array table, defines the entire set of Mark2 attachment points used to attach Mark1 glyphs to a specific Mark2 glyph. The Anchor tables in the Mark2Anchor array are ordered by Mark1 class value.
A Mark2Record declares one Anchor table for each mark class (including Class 0) identified in the MarkRecords of the MarkArray. Each Anchor table specifies one Mark2 attachment point used to attach all the Mark1 glyphs in a particular class to the Mark2 glyph.
Example 9 at the end of the chapter shows a MarkMarkPosFormat1 subtable for attaching one mark to another in the Arabic script.
Mark2Record
| Value | Type | Description |
|---|---|---|
| Offset | Mark2Anchor [ClassCount] |
Array of offsets (one per class) to Anchor tables-from beginning of Mark2Array table-zero-based array |
Lookup Type 7:
Contextual Positioning Subtables
A Contextual Positioning (ContextPos) subtable defines the most powerful type of glyph positioning lookup. It describes glyph positioning in context so a text-processing client can adjust the position of one or more glyphs within a certain pattern of glyphs. Each subtable describes one or more “input” glyph sequences and one or more positioning operations to be performed on that sequence.
ContextPos subtables can have one of three formats, which closely mirror the formats used for contextual glyph substitution. One format applies to specific glyph sequences (Format 1), one defines the context in terms of glyph classes (Format 2), and the third format defines the context in terms of sets of glyphs (Format 3).
All three formats of ContextPos subtables specify positioning data in a PosLookupRecord. A description of that record follows.
PosLookupRecord
All contextual positioning subtables specify the positioning data in a PosLookupRecord. Each record contains a SequenceIndex, which indicates where the positioning operation will occur in the glyph sequence. In addition, a LookupListIndex identifies the lookup to be applied at the glyph position specified by the SequenceIndex.
The order in which lookups are applied to the entire glyph sequence, called the “design order,” can be significant, so PosLookupRecord data should be defined accordingly.
The contextual substitution subtables defined in Examples 10, 11, and 12 show PosLookupRecords.
PosLookupRecord
| Value | Type | Description |
|---|---|---|
| uint16 | SequenceIndex | Index to input glyph sequence-first glyph = 0 |
| uint16 | LookupListIndex | Lookup to apply to that position-zero-based |
Context Positioning Subtable: Format 1
Format 1 defines the context for a glyph positioning operation as a particular sequence of glyphs. For example, a context could be <To>, <xyzabc>, <!?*#@>, or any other glyph sequence.
Within the context, Format 1 identifies particular glyph positions (not glyph indices) as the targets for specific adjustments. When a text-processing client locates a context in a string of text, it makes the adjustment by applying the lookup data defined for a targeted position at that location.
For example, suppose that accent mark glyphs above lowercase x-height vowel glyphs must be lowered when an overhanging capital letter glyph precedes the vowel. When the client locates this context in the text, the subtable identifies the position of the accent mark and a lookup index. A lookup specifies a positioning action that lowers the accent mark over the vowel so that it does not collide with the overhanging capital.
ContextPosFormat1 defines the context in two places. A Coverage table specifies the first glyph in the input sequence, and a PosRule table identifies the remaining glyphs. To describe the context used in the previous example, the Coverage table lists the glyph index of the first component of the sequence (the overhanging capital), and a PosRule table defines indices for the lowercase x-height vowel glyph and the accent mark.
A single ContextPosFormat1 subtable may define more than one context glyph sequence. If different context sequences begin with the same glyph, then the Coverage table should list the glyph only once because all first glyphs in the table must be unique. For example, if three contexts each start with an “s” and two start with a “t,” then the Coverage table will list one “s” and one “t.”
For each context, a PosRule table lists all the glyphs, in order, that follow the first glyph. The table also contains an array of PosLookupRecords that specify the positioning lookup data for each glyph position (including the first glyph position) in the context.
All the PosRule tables defining contexts that begin with the same first glyph are grouped together and defined in a PosRuleSet table. For example, the PosRule tables that define the three contexts that begin with an “s” are grouped in one PosRuleSet table, and the PosRule tables that define the two contexts that begin with a “t” are grouped in a second PosRuleSet table. Each unique glyph listed in the Coverage table must have a PosRuleSet table that defines all the PosRule tables for a covered glyph.
To locate a context glyph sequence, the text-processing client searches the Coverage table each time it encounters a new text glyph. If the glyph is covered, the client reads the corresponding PosRuleSet table and examines each PosRule table in the set to determine whether the rest of the context defined there matches the subsequent glyphs in the text. If the context and text string match, the client finds the target glyph position, applies the lookup for that position, and completes the positioning action.
A ContextPosFormat1 subtable contains a format identifier (PosFormat), an offset to a Coverage table (Coverage), a count of the number of PosRuleSets that are defined (PosRuleSetCount), and an array of offsets to the PosRuleSet tables (PosRuleSet). As mentioned, one PosRuleSet table must be defined for each glyph listed in the Coverage table.
In the PosRuleSet array, the PosRuleSet tables are ordered in the Coverage Index order. The first PosRuleSet in the array applies to the first GlyphID listed in the Coverage table, the second PosRuleSet in the array applies to the second GlyphID listed in the Coverage table, and so on.
ContextPosFormat1 subtable: Simple context positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of ContextPos subtable |
| uint16 | PosRuleSetCount | Number of PosRuleSet tables |
| Offset | PosRuleSet [PosRuleSetCount] |
Array of offsets to PosRuleSet tables-from beginning of ContextPos subtable-ordered by Coverage Index |
A PosRuleSet table consists of an array of offsets to PosRule tables (PosRule), ordered by preference, and a count of the PosRule tables defined in the set (PosRuleCount).
PosRuleSet table: All contexts beginning with the same glyph
| Value | Type | Description |
|---|---|---|
| uint16 | PosRuleCount | Number of PosRule tables |
| Offset | PosRule [PosRuleCount] |
Array of offsets to PosRule tables-from beginning of PosRuleSet-ordered by preference |
A PosRule table consists of a count of the glyphs to be matched in the input context sequence (GlyphCount), including the first glyph in the sequence, and an array of glyph indices that describe the context (Input). The Coverage table specifies the index of the first glyph in the context, and the Input array begins with the second glyph in the context sequence. As a result, the first index position in the array is specified with the number one (1), not zero (0). The Input array lists the indices in the order the corresponding glyphs appear in the text. For text written from right to left, the right-most glyph will be first; conversely, for text written from left to right, the left-most glyph will be first.
A PosRule table also contains a count of the positioning operations to be performed on the input glyph sequence (PosCount) and an array of PosLookupRecords (PosLookupRecord). Each record specifies a position in the input glyph sequence and a LookupList index to the positioning lookup to be applied there. The array should list records in design order, or the order the lookups should be applied to the entire glyph sequence.
Example 10 at the end of this chapter demonstrates glyph kerning in context with a ContextPosFormat1 subtable.
PosRule subtable
| Value | Type | Description |
|---|---|---|
| uint16 | GlyphCount | Number of glyphs in the Input glyph sequence |
| uint16 | PosCount | Number of PosLookupRecords |
| GlyphID | Input [GlyphCount - 1] |
Array of input GlyphIDs-starting with the second glyph |
| struct | PosLookupRecord[PosCount] | Array of positioning lookups-in design order |
Context Positioning Subtable: Format 2
Format 2, more flexible than Format 1, describes class-based context positioning. For this format, a specific integer, called a class value, must be assigned to each glyph in all context glyph sequences. Contexts are then defined as sequences of class values. This subtable may define more than one context.
To clarify the notion of class-based context rules, suppose that certain sequences of three glyphs need special kerning. The glyph sequences consist of an uppercase glyph that overhangs on the right side, a punctuation mark glyph, and then a quote glyph. In this case, the set of uppercase glyphs would constitute one glyph class (Class1), the set of punctuation mark glyphs would constitute a second glyph class (Class 2), and the set of quote mark glyphs would constitute a third glyph class (Class 3). The input context might be specified with a context rule (PosClassRule) that describes “the set of glyph strings that form a sequence of three glyph classes, one glyph from Class 1, followed by one glyph from Class 2, followed by one glyph from Class 3.”
Each ContextPosFormat2 subtable contains an offset to a class definition table (ClassDef), which defines the class values of all glyphs in the input contexts that the subtable describes. Generally, a unique ClassDef will be declared in each instance of the ContextPosFormat2 subtable that is included in a font, even though several Format 2 subtables may share ClassDef tables. Classes are exclusive sets; a glyph cannot be in more than one class at a time. The output glyphs that replace the glyphs in the context sequence do not need class values because they are specified elsewhere by GlyphID.
The ContextPosFormat2 subtable also contains a format identifier (PosFormat) and defines an offset to a Coverage table (Coverage). For this format, the Coverage table lists indices for the complete set of glyphs (not glyph classes) that may appear as the first glyph of any class-based context. In other words, the Coverage table contains the list of glyph indices for all the glyphs in all classes that may be first in any of the context class sequences. For example, if the contexts begin with a Class 1 or Class 2 glyph, then the Coverage table will list the indices of all Class 1 and Class 2 glyphs.
A ContextPosFormat2 subtable also defines an array of offsets to the PosClassSet tables (PosClassSet), along with a count (including Class0) of the PosClassSet tables (PosClassSetCnt). In the array, the PosClassSet tables are ordered by ascending class value (from 0 to PosClassSetCnt - 1).
A PosClassSet array contains one offset for each glyph class, including Class 0. PosClassSets are not explicitly tagged with a class value; rather, the index value of the PosClassSet in the PosClassSet array defines the class that a PosClassSet represents.
For example, the first PosClassSet listed in the array contains all the PosClassRules that define contexts beginning with Class 0 glyphs, the second PosClassSet contains all PosClassRules that define contexts beginning with Class 1 glyphs, and so on. If no PosClassRules begin with a particular class (that is, if a PosClassSet contains no PosClassRules), then the offset to that particular PosClassSet in the PosClassSet array will be set to NULL.
ContextPosFormat2 subtable: Class-based context glyph positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of ContextPos subtable |
| Offset | ClassDef | Offset to ClassDef table-from beginning of ContextPos subtable |
| uint16 | PosClassSetCnt | Number of PosClassSet tables |
| Offset | PosClassSet [PosClassSetCnt] |
Array of offsets to PosClassSet tables-from beginning of ContextPos subtable-ordered by class-may be NULL |
All the PosClassRules that define contexts beginning with the same class are grouped together and defined in a PosClassSet table. Consequently, the PosClassSet table identifies the class of a context’s first component.
A PosClassSet enumerates all the PosClassRules that begin with a particular glyph class. For instance, PosClassSet0 represents all the PosClassRules that describe contexts starting with Class 0 glyphs, and PosClassSet1 represents all the PosClassRules that define contexts starting with Class 1 glyphs.
Each PosClassSet table consists of a count of the PosClassRules defined in the PosClassSet (PosClassRuleCnt) and an array of offsets to PosClassRule tables (PosClassRule). The PosClassRule tables are ordered by preference in the PosClassRule array of the PosClassSet.
PosClassSet table: All contexts beginning with the same class
| Value | Type | Description |
|---|---|---|
| uint16 | PosClassRuleCnt | Number of PosClassRule tables |
| Offset | PosClassRule[PosClassRuleCnt] | Array of offsets to PosClassRule tables-from beginning of PosClassSet-ordered by preference |
For each context, a PosClassRule table contains a count of the glyph classes in a given context (GlyphCount), including the first class in the context sequence. A class array lists the classes, beginning with the second class, that follow the first class in the context. The first class listed indicates the second position in the context sequence.
Note: Text order depends on the writing direction of the text. For text written from right to left, the right-most glyph will be first. Conversely, for text written from left to right, the left-most glyph will be first.
The values specified in the Class array are those defined in the ClassDef table. For example, consider a context consisting of the sequence: Class 2, Class 7, Class 5, Class 0. The Class array will read: Class[0] = 7, Class[1] = 5, and Class[2] = 0. The first class in the sequence, Class 2, is defined by the index into the PosClassSet array of offsets. The total number and sequence of glyph classes listed in the Class array must match the total number and sequence of glyph classes contained in the input context.
A PosClassRule also contains a count of the positioning operations to be performed on the context (PosCount) and an array of PosLookupRecords (PosLookupRecord) that supply the positioning data. For each position in the context that requires a positioning operation, a PosLookupRecord specifies a LookupList index and a position in the input glyph class sequence where the lookup is applied. The PosLookupRecord array lists PosLookupRecords in design order, or the order in which lookups are applied to the entire glyph sequence.
Example 11 at the end of this chapter demonstrates a ContextPosFormat2 subtable that uses glyph classes to modify accent positions in glyph strings.
PosClassRule table: One class context definition
| Value | Type | Description |
|---|---|---|
| uint16 | GlyphCount | Number of glyphs to be matched |
| uint16 | PosCount | Number of PosLookupRecords |
| uint16 | Class [GlyphCount - 1] |
Array of classes-beginning with the second class-to be matched to the input glyph sequence |
| struct | PosLookupRecord[PosCount] | Array of positioning lookups-in design order |
Context Positioning Subtable: Format 3
Format 3, coverage-based context positioning, defines a context rule as a sequence of coverages. Each position in the sequence may specify a different Coverage table for the set of glyphs that matches the context pattern. With Format 3, the glyph sets defined in the different Coverage tables may intersect, unlike Format 2 which specifies fixed class assignments for the lookup (they cannot be changed at each position in the context sequence) and exclusive classes (a glyph cannot be in more than one class at a time).
For example, consider an input context that contains an uppercase glyph (position 0), followed by any narrow uppercase glyph (position 1), and then another uppercase glyph (position 2). This context requires three Coverage tables, one for each position:
- In position 0, the first position, the Coverage table lists the set of all uppercase glyphs.
- In position 1, the second position, the Coverage table lists the set of all narrow uppercase glyphs, which is a subset of the glyphs listed in the Coverage table for position 0.
- In position 2, the Coverage table lists the set of all uppercase glyphs again.
Note: Both position 0 and position 2 can use the same Coverage table.
Unlike Formats 1 and 2, this format defines only one context rule at a time. It consists of a format identifier (PosFormat), a count of the number of glyphs in the sequence to be matched (GlyphCount), and an array of Coverage offsets that describe the input context sequence (Coverage).
Note: The Coverage tables listed in the Coverage array must be listed in text order according to the writing direction. For text written from right to left, the right-most glyph will be first. Conversely, for text written from left to right, the left-most glyph will be first.
The subtable also contains a count of the positioning operations to be performed on the input Coverage sequence (PosCount) and an array of PosLookupRecords (PosLookupRecord) in design order, or the order in which lookups are applied to the entire glyph sequence.
Example 12 at the end of this chapter changes the positions of math sign glyphs in math equations with a ContextPosFormat3 subtable.
ContextPosFormat3 subtable: Coverage-based context glyph positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 3 |
| uint16 | GlyphCount | Number of glyphs in the input sequence |
| uint16 | PosCount | Number of PosLookupRecords |
| Offset | Coverage [GlyphCount] |
Array of offsets to Coverage tables-from beginning of ContextPos subtable |
| struct | PosLookupRecord [PosCount] |
Array of positioning lookups-in design order |
LookupType 8: Chaining Contextual Positioning Subtable
A Chaining Contextual Positioning subtable(ChainContextPos)describes glyph positioning in context with an ability to look back and/or look ahead in the sequence of glyphs. The design of the Chaining Contextual Positioning subtable is parallel to that of the Contextual Positioning subtable, including the availability of three formats.
To specify the context, the coverage table lists the first glyph in the input sequence, and the ChainPosRule subtable defines the rest. Once a covered glyph is found at position i, the client reads the corresponding ChainPosRuleSet table and examines each table to determine if it matches the surrounding glyphs in the text. There is a match if the string <backtrack sequence>+<input sequence>+<lookahead sequence> matches with the glyphs at position i - BacktrackGlyphCount in the text.
If there is a match, then the client finds the target glyphs for positioning and performs the operations. Please note that (just like in the ContextPosFormat1 subtable) these lookups are required to operate within the range of text from the covered glyph to the end of the input sequence. No positioning operations can be defined for the backtracking sequence or the lookahead sequence.
To clarify the ordering of glyph arrays for input, backtrack and lookahead sequences, the following illustration is provided. Input sequence match begins at i where the input sequence match begins. The backtrack sequence is ordered beginning at i - 1 and increases in offset value as one moves away from i. The lookahead sequence begins after the input sequence and increases in logical order.
| Logical order - | a | b | c | d | e | f | g | h | i | j |
| i | ||||||||||
| Input sequence - | 0 | 1 | ||||||||
| Backtrack sequence - | 3 | 2 | 1 | 0 | ||||||
| Lookahead sequence - | 0 | 1 | 2 | 3 |
Chaining Context Positioning Format 1: Simple Chaining Context Glyph Positioning
This Format is identical to Format 1 of Context Positioning lookup except that the PosRule table is replaced with a ChainPosRule table. (Correspondingly, the ChainPosRuleSet table differs from the PosRuleSet table only in that it lists offsets to ChainPosRule subtables instead of PosRule tables; and the ChainContextPosFormat1 subtable lists offsets to ChainPosRuleSet subtables instead of PosRuleSet subtables.)
ChainContextPosFormat1 subtable: Simple context positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 1 |
| Offset | Coverage | Offset to Coverage table-from beginning of ContextPos subtable |
| uint16 | ChainPosRuleSetCount | Number of ChainPosRuleSet tables |
| Offset | ChainPosRuleSet [ChainPosRuleSetCount] |
Array of offsets to ChainPosRuleSet tables-from beginning of ContextPos subtable-ordered by Coverage Index |
A ChainPosRuleSet table consists of an array of offsets to ChainPosRule tables (ChainPosRule), ordered by preference, and a count of the ChainPosRule tables defined in the set (ChainPosRuleCount).
ChainPosRuleSet table: All contexts beginning with the same glyph
| Value | Type | Description |
|---|---|---|
| uint16 | ChainPosRuleCount | Number of ChainPosRule tables |
| Offset | ChainPosRule [ChainPosRuleCount] |
Array of offsets to ChainPosRule tables-from beginning of ChainPosRuleSet-ordered by preference |
ChainPosRule subtable
| Type | Name | Description |
|---|---|---|
| uint16 | BacktrackGlyphCount | Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph) |
| GlyphID | Backtrack [BacktrackGlyphCount] |
Array of backtracking GlyphID’s (to be matched before the input sequence) |
| uint16 | InputGlyphCount | Total number of glyphs in the input sequence (includes the first glyph) |
| GlyphID | Input [InputGlyphCount - 1] |
Array of input GlyphIDs (start with second glyph) |
| uint16 | LookaheadGlyphCount | Total number of glyphs in the look ahead sequence (number of glyphs to be matched after the input sequence) |
| GlyphID | LookAhead [LookAheadGlyphCount] |
Array of lookahead GlyphID’s (to be matched after the input sequence) |
| uint16 | PosCount | Number of PosLookupRecords |
| struct | PosLookupRecord [PosCount] |
Array of PosLookupRecords (in design order) |
Chaining Context Positioning Format 2: Class-based Chaining Context Glyph Positioning
This lookup Format is parallel to the Context Positioning format 2, with PosClassSet subtable changed to ChainPosClassSet subtable, and PosClassRule subtable changed to ChainPosClassRule subtable.
To chain contexts, three classes are used in the glyph ClassDef table: Backtrack ClassDef, Input ClassDef, and Lookahead ClassDef.
ChainContextPosFormat2 subtable: Chaining class-based context glyph positioning
| Value | Type | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 2 |
| Offset | Coverage | Offset to Coverage table-from beginning of ChainContextPos subtable |
| Offset | BacktrackClassDef | Offset to ClassDef table containing backtrack sequence context-from beginning of ChainContextPos subtable |
| Offset | InputClassDef | Offset to ClassDef table containing input sequence context-from beginning of ChainContextPos subtable |
| Offset | LookaheadClassDef | Offset to ClassDef table containing lookahead sequence context-from beginning of ChainContextPos subtable |
| uint16 | ChainPosClassSetCnt | Number of ChainPosClassSet tables |
| Offset | ChainPosClassSet [ChainPosClassSetCnt] |
Array of offsets to ChainPosClassSet tables-from beginning of ChainContextPos subtable-ordered by input class-may be NULL |
All the ChainPosClassRules that define contexts beginning with the same class are grouped together and defined in a ChainPosClassSet table. Consequently, the ChainPosClassSet table identifies the class of a context’s first component.
ChainPosClassSet table: All contexts beginning with the same class
| Value | Type | Description |
|---|---|---|
| uint16 | ChainPosClassRuleCnt | Number of ChainPosClassRule tables |
| Offset | ChainPosClassRule[ChainPosClassRuleCnt] | Array of offsets to ChainPosClassRule tables-from beginning of ChainPosClassSet-ordered by preference |
ChainPosClassRule subtable
| Type | Name | Description |
|---|---|---|
| uint16 | BacktrackGlyphCount | Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph) |
| uint16 | Backtrack [BacktrackGlyphCount] |
Array of backtracking classes(to be matched before the input sequence) |
| uint16 | InputGlyphCount | Total number of classes in the input sequence (includes the first class) |
| uint16 | Input [InputGlyphCount - 1] |
Array of input classes(start with second class; to be matched with the input glyph sequence) |
| uint16 | LookaheadGlyphCount | Total number of classes in the look ahead sequence (number of classes to be matched after the input sequence) |
| uint16 | LookAhead [LookAheadGlyphCount] |
Array of lookahead classes(to be matched after the input sequence) |
| uint16 | PosCount | Number of PosLookupRecords |
| struct | PosLookupRecord [ChainPosCount] |
Array of PosLookupRecords (in design order) |
Chaining Context Positioning Format 3: Coverage-based Chaining Context Glyph Positioning
Format 3 defines a chaining context rule as a sequence of Coverage tables. Each position in the sequence may define a different Coverage table for the set of glyphs that matches the context pattern. With Format 3, the glyph sets defined in the different Coverage tables may intersect, unlike Format 2 which specifies fixed class assignments (identical for each position in the backtrack, input, or lookahead sequence) and exclusive classes (a glyph cannot be in more than one class at a time).
Note: The order of the Coverage tables listed in the Coverage array must follow the writing direction. For text written from right to left, then the right-most glyph will be first. Conversely, for text written from left to right, the left-most glyph will be first.
The subtable also contains a count of the positioning operations to be performed on the input Coverage sequence (PosCount) and an array of PosLookupRecords (PosLookupRecord) in design order: that is, the order in which lookups should be applied to the entire glyph sequence.
ChainContextPosFormat3 subtable: Coverage-based chaining context glyph positioning
| Type | Name | Description |
|---|---|---|
| uint16 | PosFormat | Format identifier-format = 3 |
| uint16 | BacktrackGlyphCount | Number of glyphs in the backtracking sequence |
| Offset | Coverage[BacktrackGlyphCount] | Array of offsets to coverage tables in backtracking sequence, in glyph sequence order |
| uint16 | InputGlyphCount | Number of glyphs in input sequence |
| Offset | Coverage[InputGlyphCount] | Array of offsets to coverage tables in input sequence, in glyph sequence order |
| uint16 | LookaheadGlyphCount | Number of glyphs in lookahead sequence |
| Offset | Coverage[LookaheadGlyphCount] | Array of offsets to coverage tables in lookahead sequence, in glyph sequence order |
| uint16 | PosCount | Number of PosLookupRecords |
| struct | PosLookupRecord [PosCount] |
Array of PosLookupRecords,in design order |
LookupType 9: Extension Positioning
This lookup provides a mechanism whereby any other lookup type’s subtables are stored at a 32-bit offset location in the 'GPOS' table. This is needed if the total size of the subtables exceeds the 16-bit limits of the various other offsets in the 'GPOS' table. In this specification, the subtable stored at the 32-bit offset location is termed the “extension” subtable.
ExtensionPosFormat1 subtable
| Type | Name | Description |
|---|---|---|
| USHORT | PosFormat | Format identifier. Set to 1. |
| USHORT | ExtensionLookupType | Lookup type of subtable referenced by ExtensionOffset (i.e. the extension subtable). |
| ULONG | ExtensionOffset | Offset to the extension subtable, of lookup type ExtensionLookupType, relative to the start of the ExtensionPosFormat1 subtable. |
ExtensionLookupType must be set to any lookup type other than 9. All subtables in a LookupType 9 lookup must have the same ExtensionLookupType. All offsets in the extension subtables are set in the usual way, i.e. relative to the extension subtables themselves.
When an OpenType layout engine encounters a LookupType 9 Lookup table, it shall:
- Proceed as though the Lookup table’s LookupType field were set to the ExtensionLookupType of the subtables.
- Proceed as though each extension subtable referenced by ExtensionOffset replaced the LookupType 9 subtable that referenced it.
Shared Tables: ValueRecord, Anchor Table, and MarkArray
Several lookup subtables described earlier in this chapter refer to one or more of the same tables for positioning data: ValueRecord, Anchor table, and MarkArray. For easy reference, those shared tables are described here.
Example 14 at the end of the chapter uses a ValueFormat table and ValueRecord to specify positioning values in GPOS.
ValueRecord
GPOS subtables use ValueRecords to describe all the variables and values used to adjust the position of a glyph or set of glyphs. A ValueRecord may define any combination of X and Y values (in design units) to add to (positive values) or subtract from (negative values) the placement and advance values provided in the font. A ValueRecord also may contain an offset to a Device table for each of the specified values. If a ValueRecord specifies more than one value, the values should be listed in the order shown in the ValueRecord definition.
The text-processing client must be aware of the flexible and multi-dimensional nature of ValueRecords in the GPOS table. Because the GPOS table uses ValueRecords for many purposes, the sizes and contents of ValueRecords may vary from subtable to subtable.
ValueRecord (all fields are optional)
| Value | Type | Description |
|---|---|---|
| int16 | XPlacement | Horizontal adjustment for placement-in design units |
| int16 | YPlacement | Vertical adjustment for placement-in design units |
| int16 | XAdvance | Horizontal adjustment for advance-in design units (only used for horizontal writing) |
| int16 | YAdvance | Vertical adjustment for advance-in design units (only used for vertical writing) |
| Offset | XPlaDevice | Offset to Device table for horizontal placement-measured from beginning of PosTable (may be NULL) |
| Offset | YPlaDevice | Offset to Device table for vertical placement-measured from beginning of PosTable (may be NULL) |
| Offset | XAdvDevice | Offset to Device table for horizontal advance-measured from beginning of PosTable (may be NULL) |
| Offset | YAdvDevice | Offset to Device table for vertical advance-measured from beginning of PosTable (may be NULL) |
A data format (ValueFormat), usually declared at the beginning of each GPOS subtable, defines the types of positioning adjustment data that ValueRecords specify. Usually, the same ValueFormat applies to every ValueRecord defined in the particular GPOS subtable.
The ValueFormat determines whether the ValueRecords:
- Apply to placement, advance, or both.
- Apply to the horizontal position (X coordinate), the vertical position (Y coordinate), or both.
- May refer to one or more Device tables for any of the specified values.
Each one-bit in the ValueFormat corresponds to a field in the ValueRecord and increases the size of the ValueRecord by 2 bytes. A ValueFormat of 0x0000 corresponds to an empty ValueRecord, which indicates no positioning changes.
To identify the fields in each ValueRecord, the ValueFormat uses the bit settings shown below. To specify multiple fields with a ValueFormat, the bit settings of the relevant fields are added with a logical OR operation.
For example, to adjust the left-side bearing of a glyph, the ValueFormat will be 0x0001, and the ValueRecord will define the XPlacement value. To adjust the advance width of a different glyph, the ValueFormat will be 0x0004, and the ValueRecord will describe the XAdvance value. To adjust both the XPlacement and XAdvance of a set of glyphs, the ValueFormat will be 0x0005, and the ValueRecord will specify both values in the order they are listed in the ValueRecord definition.
ValueFormat bit enumeration (indicates which fields are present)
| Mask | Name | Description |
|---|---|---|
| 0x0001 | XPlacement | Includes horizontal adjustment for placement |
| 0x0002 | YPlacement | Includes vertical adjustment for placement |
| 0x0004 | XAdvance | Includes horizontal adjustment for advance |
| 0x0008 | YAdvance | Includes vertical adjustment for advance |
| 0x0010 | XPlaDevice | Includes horizontal Device table for placement |
| 0x0020 | YPlaDevice | Includes vertical Device table for placement |
| 0x0040 | XAdvDevice | Includes horizontal Device table for advance |
| 0x0080 | YAdvDevice | Includes vertical Device table for advance |
| 0xF000 | Reserved | For future use (set to zero) |
Anchor Table
A GPOS table uses anchor points to position one glyph with respect to another. Each glyph defines an anchor point, and the text-processing client attaches the glyphs by aligning their corresponding anchor points.
To describe an anchor point, an Anchor table can use one of three formats. The first format uses design units to specify a location for the anchor point. The other two formats refine the location of the anchor point using contour points (Format 2) or Device tables (Format 3).
Anchor Table: Format 1
AnchorFormat1 consists of a format identifier (AnchorFormat) and a pair of design unit coordinates (XCoordinate and YCoordinate) that specify the location of the anchor point. This format has the benefits of small size and simplicity, but the anchor point cannot be hinted to adjust its position for different device resolutions.
Example 15 at the end of this chapter uses AnchorFormat1.
AnchorFormat1 table: Design units only
| Value | Type | Description |
|---|---|---|
| uint16 | AnchorFormat | Format identifier-format = 1 |
| int16 | XCoordinate | Horizontal value-in design units |
| int16 | YCoordinate | Vertical value-in design units |
Anchor Table: Format 2
Like AnchorFormat1, AnchorFormat2 specifies a format identifier (AnchorFormat) and a pair of design unit coordinates for the anchor point (Xcoordinate and Ycoordinate).
For fine-tuning the location of the anchor point, AnchorFormat2 also provides an index to a glyph contour point (AnchorPoint) that is on the outline of a glyph (AnchorPoint). Hinting can be used to move the AnchorPoint. In the rendered text, the AnchorPoint will provide the final positioning data for a given ppem size.
Example 16 at the end of this chapter uses AnchorFormat2.
AnchorFormat2 table: Design units plus contour point /p>
| Value | Type | Description |
|---|---|---|
| uint16 | AnchorFormat | Format identifier-format = 2 |
| int16 | XCoordinate | Horizontal value-in design units |
| int16 | YCoordinate | Vertical value-in design units |
| uint16 | AnchorPoint | Index to glyph contour point |
Anchor Table: Format 3
Like AnchorFormat1, AnchorFormat3 specifies a format identifier (AnchorFormat) and locates an anchor point (Xcoordinate and Ycoordinate). And, like AnchorFormat 2, it permits fine adjustments to the coordinate values. However, AnchorFormat3 uses Device tables, rather than a contour point, for this adjustment.
With a Device table, a client can adjust the position of the anchor point for any font size and device resolution. AnchorFormat3 can specify offsets to Device tables for the the X coordinate (XDeviceTable) and the Y coordinate (YDeviceTable). If only one coordinate requires adjustment, the offset to the Device table may be set to NULL for the other coordinate.
Example 17 at the end of the chapter shows an AnchorFormat3 table.
AnchorFormat3 table: Design units plus Device tables
| Value | Type | Description |
|---|---|---|
| uint16 | AnchorFormat | Format identifier-format = 3 |
| int16 | XCoordinate | Horizontal value-in design units |
| int16 | YCoordinate | Vertical value-in design units |
| Offset | XDeviceTable | Offset to Device table for X coordinate- from beginning of Anchor table (may be NULL) |
| Offset | YDeviceTable | Offset to Device table for Y coordinate- from beginning of Anchor table (may be NULL) |
Mark Array
The MarkArray table defines the class and the anchor point for a mark glyph. Three GPOS subtables-MarkToBase, MarkToLigature, and MarkToMark Attachment-use the MarkArray table to specify data for attaching marks.
The MarkArray table contains a count of the number of mark records (MarkCount) and an array of those records (MarkRecord). Each mark record defines the class of the mark and an offset to the Anchor table that contains data for the mark.
A class value can be 0 (zero), but the MarkRecord must explicitly assign that class value (this differs from the ClassDef table, in which all glyphs not assigned class values automatically belong to Class 0). The GPOS subtables that refer to MarkArray tables use the class assignments for indexing zero-based arrays that contain data for each mark class.
In Example 18 at the end of the chapter, a MarkArray table and two MarkRecords define two mark classes.
MarkArray table
| Value | Type | Description |
|---|---|---|
| uint16 | MarkCount | Number of MarkRecords |
| struct | MarkRecord [MarkCount] |
Array of MarkRecords-in Coverage order |
MarkRecord
| Value | Type | Description |
|---|---|---|
| uint16 | Class | Class defined for this mark |
| Offset | MarkAnchor | Offset to Anchor table-from beginning of MarkArray table |
GPOS Subtable Examples
The rest of this chapter describes examples of all the GPOS subtable formats, including each of the three formats available for contextual positioning. All the examples reflect unique parameters described below, but the samples provide a useful reference for building subtables specific to other situations.
All the examples have three columns showing hex data, source, and comments.
Example 1: GPOS Header Table
Example 1 shows a typical GPOS Header table definition with offsets to a ScriptList, FeatureList, and LookupList.
Example 1
| Hex Data | Source | Comments |
|---|---|---|
|
GPOSHeader
TheGPOSHeader |
GPOSHeader table definition | |
| 00010000 | 0x00010000 | Version |
| 000A | TheScriptList | offset to ScriptList table |
| 001E | TheFeatureList | offset to FeatureList table |
| 002C | TheLookupList | offset to LookupList table |
Example 2: SinglePosFormat1 Subtable
Example 2 uses the SinglePosFormat1 subtable to lower the Y placement of subscript glyphs in a font. The LowerSubscriptsSubTable defines one Coverage table, called LowerSubscriptsCoverage, which lists one range of glyph indices for the numeral/numeric subscript glyphs. The subtable’s ValueFormat setting indicates that the ValueRecord specifies only the YPlacement value, lowering each subscript glyph by 80 design units.
Example 2
| Hex Data | Source | Comments |
|---|---|---|
|
SinglePosFormat1
LowerSubscriptsSubTable |
SinglePos subtable definition | |
| 0001 | 1 | PosFormat |
| 0008 | LowerSubscriptsCoverage | offset to Coverage table |
| 0002 | 0x0002 | ValueFormat, YPlacement,Value[0], move Y position down |
| FFB0 | -80 |
|
|
CoverageFormat2
LowerSubscriptsCoverage |
Coverage table definition | |
| 0002 | 2 | CoverageFormat |
| 0001 | 1 | RangeCount RangeRecord[0] |
| 01B3 | ZeroSubscriptGlyphID | Start, first glyphID |
| 01BC | NineSubscriptGlyphID | End, last glyphID |
| 0000 | 0 | StartCoverageIndex |
Example 3: SinglePosFormat2 Subtable
This example uses a SinglePosFormat2 subtable to adjust the spacing of three dash glyphs by different amounts. The em dash spacing changes by 10 units, the en dash spacing changes by 25 units, and spacing of the standard dash changes by 50 units.
The DashSpacingSubTable contains one Coverage table with three dash glyph indices, plus an array of ValueRecords, one for each covered glyph. The ValueRecords use the same ValueFormat to modify the XPlacement and XAdvance values of each glyph. The ValueFormat bit setting of 0x0005 is produced by adding the XPlacement and XAdvance bit settings.
Example 3
| Hex Data | Source | Comments |
|---|---|---|
|
SinglePosFormat2
DashSpacingSubTable |
SinglePos subtable definition | |
| 0002 | 2 | PosFormat |
| 0014 | DashSpacingCoverage | offset to Coverage table |
| 0005 | 0x0005 | ValueFormat for XPlacement and XAdvance |
| 0003 | 3 | ValueCount Value[0], for dash glyph |
| 0032 | 50 | XPlacement |
| 0032 | 50 | XAdvance Value[1], for en dash glyph |
| 0019 | 25 | XPlacement |
| 0019 | 25 | XAdvance Value[2], for em dash glyph |
| 000A | 10 | XPlacement |
| 000A | 10 | XAdvance
|
|
CoverageFormat1
DashSpacingCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0003 | 3 | GlyphCount |
| 004F | DashGlyphID | GlyphArray[0] |
| 0125 | EnDashGlyphID | GlyphArray[1] |
| 0129 | EmDashGlyphID | GlyphArray[2] |
Example 4: PairPosFormat1 Subtable
Example 4 uses a PairPosFormat1 subtable to kern two glyph pairs - “Po” and “To” - by adjusting the XAdvance of the first glyph and the XPlacement of the second glyph. Two ValueFormats are defined, one for each glyph. The subtable contains a Coverage table that lists the index of the first glyph in each pair. It also contains an offset to a PairSet table for each covered glyph.
A PairSet table defines an array of PairValueRecords to specify all the glyph pairs that contain a covered glyph as their first component. In this example, the PairSet table has one PairValueRecord that identifies the second glyph in the "Po" pair and two ValueRecords, one for the first glyph and one for the second. The PairSet table also has one PairValueRecord that lists the second glyph in the “To” pair and two ValueRecords, one for each glyph.
Example 4
| Hex Data | Source | Comments |
|---|---|---|
|
PairPosFormat1
PairKerningSubTable |
PairPos subtable definition | |
| 0001 | 1 | PosFormat |
| 001E | PairKerningCoverage | offset to Coverage table |
| 0004 | 0x0004 | ValueFormat1 XAdvance only |
| 0001 | 0x0001 | ValueFormat2 XPlacement only |
| 0002 | 2 | PairSetCount |
| 000E | PairSetTable | PairSet[0] |
| 0016 | PairSetTable | PairSet[1]
|
|
PairSetTable
PairSetTable |
PairSet table definition | |
| 0001 | 1 | PairValueCount, one pair in set PairValueRecord[0] |
| 0059 | LowercaseOGlyphID | SecondGlyph |
| FFE2 | -30 | Value 1, XAdvance adjustment for first glyph |
| FFEC | -20 | Value 2, XPlacement adjustment for second glyph
|
|
PairSetTable
PairSetTable |
PairSet table definition | |
| 0001 | 1 | PairValueCount one pair in set PairValueRecord[0] |
| 0059 | LowercaseOGlyphID | SecondGlyph |
| FFD8 | -40 | Value1 XAdvance adjustment for first glyph |
| FFE7 | -25 | Value 2 XPlacement adjustment for second glyph
|
|
CoverageFormat1
PairKerningCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0002 | 2 | GlyphCount |
| 002D | UppercasePGlyphID | GlyphArray[0] |
| 0031 | UppercaseTGlyphID | GlyphArray[1] |
Example 5: PairPosFormat2 Subtable
The PairPosFormat2 subtable in this example defines pairs composed of two glyph classes. Two ClassDef tables are defined, one for each glyph class. The first glyph in each pair is in a class of lowercase glyphs with diagonal shapes (v, w, y), defined Class1 in the LowercaseClassDef table. The second glyph in each pair is in a class of punctuation glyphs (comma and period), defined in Class1 in the PunctuationClassDef table. The Coverage table only lists the indices of the glyphs in the LowercaseClassDef table since they occupy the first position in the pairs.
The subtable defines two Class1Records for the classes defined in LowecaseClassDef, including Class0. Each record, in turn, defines a Class2Record for each class defined in PunctuationClassDef, including Class0. The Class2Records specify the positioning adjustments for the glyphs.
The pairs are kerned by reducing the XAdvance of the first glyph by 50 design units. Because no positioning change applies to the second glyph, its ValueFormat2 is set to 0, to indicate that Value2 is empty for each pair.
Since no pairs begin with Class0 or Class2 glyphs, all the ValueRecords referenced in Class1Record[0] contain values of 0 or are empty. However, Class1Record[1] does define an XAdvance value in its Class2Record[1] for kerning all pairs that contain a Class1 glyph followed by a Class2 glyph.
Example 5
| Hex Data | Source | Comments |
|---|---|---|
|
PairPosFormat2
PunctKerningSubTable |
PairPos subtable definition | |
| 0002 | 2 | PosFormat |
| 0018 | PunctKerningCoverage | offset to Coverage table |
| 0004 | 0x0004 | ValueFormat1 XAdvance only |
| 0000 | 0 | ValueFormat2 no ValueRecord for second glyph |
| 0022 | LowercaseClassDef | offset to ClassDef1 table for first class in pair |
| 0032 | PunctuationClassDef | offset to ClassDef2 table for second class in pair |
| 0002 | 2 | Class1Count |
| 0002 | 2 | Class2Count Class1Record[0], no contexts begin with Class0 Class2Record[0] |
| 0000 | 0 | Value1- no change for first glyph, Value2 no ValueRecord for second glyph Class2Record[1] |
| 0000 | 0 | Value1- no change for first glyph, Value2 no ValueRecord for second glyph Class1Record[1], for contexts beginning with Class1 Class2Record[0] no contexts with Class0 as second glyph |
| 0000 | 0 | Value1-no change for first glyph, Value2-no ValueRecord for second glyph Class2Record[1]contexts with Class1 as second glyph |
| FFCE | -50 | Value1- move punctuation glyph left, Value2- no ValueRecord for second glyph
|
|
CoverageFormat1
PunctKerningCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat, lists |
| 0003 | 3 | GlyphCount |
| 0046 | LowercaseVGlyphID | GlyphArray[0] |
| 0047 | LowercaseWGlyphID | GlyphArray[1] |
| 0049 | LowercaseYGlyphID | GlyphArray[2]
|
|
ClassDefFormat2
LowercaseClassDef |
ClassDef table definition | |
| 0002 | 2 | ClassFormat |
| 0002 | 2 | ClassRangeCount ClassRangeRecord[0] |
| 0046 | LowercaseVGlyphID | Start |
| 0047 | LowercaseWGlyphID | End |
| 0001 | 1 | Class ClassRangeRecord[1] |
| 0049 | LowercaseYGlyphID | Start |
| 0049 | LowercaseYGlyphID | End |
| 0001 | 1 | Class
|
|
ClassDefFormat2
PunctuationClassDef |
ClassDef table definition | |
| 0002 | 2 | ClassFormat |
| 0001 | 1 | ClassRangeCount ClassRangeRecord[0] |
| 006A | PeriodPunctGlyphID | Start |
| 006B | CommaPunctGlyphID | End |
| 0001 | 1 | Class |
Example 6: CursivePosFormat1 Subtable
In Example 6, the Urdu language system uses a CursivePosFormat1 subtable to attach glyphs along a diagonal baseline that descends from right to left. Two glyphs are defined with attachment data and listed in the Coverage table-the Kaf and Ha glyphs. For each glyph, the subtable contains an EntryExitRecord that defines offsets to two Anchor tables, an entry attachment point, and an exit attachment point. Each Anchor table defines X and Y coordinate values. To render Urdu down and diagonally, the entry point’s Y coordinate is above the baseline and the exit point’s Y coordinate is located below the baseline.
Example 6
| Hex Data | Source | Comments |
|---|---|---|
|
CursivePosFormat1
DiagonalWritingSubTable |
CursivePos subtable definition | |
| 0001 | 1 | PosFormat |
| 000E | DiagonalWritingCoverage | offset to Coverage table |
| 0002 | 2 | EntryExitCount EntryExitRecord[0] for Kaf glyph |
| 0016 | KafEntryAnchor | offset to EntryAnchor table |
| 001C | KafExitAnchor | offset to ExitAnchor table EntryExitRecord[1] for Ha glyph |
| 0022 | HaEntryAnchor | offset to EntryAnchor table |
| 0028 | HaExitAnchor | offset to ExitAnchor table
|
|
CoverageFormat1
DiagonalWritingCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0002 | 2 | GlyphCount |
| 0203 | KafGlyphID | GlyphArray[0] |
| 027E | HaGlyphID | GlyphArray[1]
|
|
AnchorFormat1
KafEntryAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 05DC | 1500 | XCoordinate |
| 002C | 44 | YCoordinate
|
|
AnchorFormat1
KafExitAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 0000 | 0 | XCoordinate |
| FFEC | -20 | YCoordinate
|
|
AnchorFormat1
HaEntryAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 05DC | 1500 | XCoordinate |
| 002C | 44 | YCoordinate
|
|
AnchorFormat1
HaExitAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 0000 | 0 | XCoordinate |
| FFEC | -20 | Ycoordinate |
Example 7: MarkBasePosFormat1 Subtable
The MarkBasePosFormat1 subtable in Example 7 defines one Arabic base glyph, Tah, and two Arabic mark glyphs: a fathatan mark above the base glyph, and a kasra mark below the base glyph. The BaseGlyphsCoverage table lists the base glyph, and the MarkGlyphsCoverage table lists the mark glyphs.
Each mark is also listed in the MarkArray, along with its attachment point data and a mark Class value. The MarkArray defines two mark classes: Class0 consists of marks located above base glyphs, and Class1 consists of marks located below base glyphs.
The BaseArray defines attachment data for base glyphs. In this array, one BaseRecord is defined for the Tah glyph with offsets to two BaseAnchor tables, one for each class of marks. AboveBaseAnchor defines an attachment point for marks placed above the Tah base glyph, and BelowBaseAnchor defines an attachment point for marks placed below it.
Example 7
| Hex Data | Source | Comments |
|---|---|---|
|
MarkBasePosFormat1
MarkBaseAttachSubTable |
MarkBasePos subtable definition | |
| 0001 | 1 | PosFormat |
| 000C | MarkGlyphsCoverage | offset to MarkCoverage table |
| 0014 | BaseGlyphsCoverage | offset to BaseCoverage table |
| 0002 | 2 | ClassCount |
| 001A | MarkGlyphsArray | offset to MarkArray table |
| 0030 | BaseGlyphsArray | offset to BaseArray table
|
|
CoverageFormat1
MarkGlyphsCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0002 | 2 | GlyphCount |
| 0333 | fathatanMarkGlyphID | GlyphArray[0] |
| 033F | kasraMarkGlyphID | GlyphArray[1]
|
|
CoverageFormat1
BaseGlyphsCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0001 | 1 | GlyphCount |
| 0190 | tahBaseGlyphID | GlyphArray[0]
|
|
MarkArray
MarkGlyphsArray |
MarkArray table definition | |
| 0002 | 2 | MarkCount MarkRecord[0] in CoverageIndex order |
| 0000 | 0 | Class, for marks over base |
| 000A | fathatanMarkAnchor | offset to Anchor table MarkRecord[1] |
| 0001 | 1 | Class, for marks under |
| 0010 | kasraMarkAnchor | offset to Anchor table
|
|
AnchorFormat1
fathatanMarkAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 015A | 346 | XCoordinate |
| FF9E | -98 | YCoordinate
|
|
AnchorFormat1
kasraMarkAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 0105 | 261 | XCoordinate |
| 0058 | 88 | YCoordinate
|
|
BaseArray
BaseGlyphsArray |
BaseArray table definition | |
| 0001 | 1 | BaseCount BaseRecord[0] |
| 0006 | AboveBaseAnchor | BaseAnchor[0] |
| 000C | BelowBaseAnchor | BaseAnchor[1] |
|
AnchorFormat1
AboveBaseAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 033E | 830 | XCoordinate |
| 0640 | 1600 | YCoordinate
|
|
AnchorFormat1
BelowBaseAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 033E | 830 | XCoordinate |
| FFAD | -83 | Ycoordinate |
Example 8: MarkLigPosFormat1 Subtable
Example 8 uses the MarkLigPosFormat1 subtable to attach marks to a ligature glyph in the Arabic script. The hypothetical ligature is composed of three glyph components: a Lam (initial form), a meem (medial form), and a jeem (medial form). Accent marks are defined for the first two components: the sukun accent is positioned above lam, and the kasratan accent is placed below meem.
The LigGlyphsCoverage table lists the ligature glyph and the MarkGlyphsCoverage table lists the two accent marks. Each mark is also listed in the MarkArray, along with its attachment point data and a mark Class value. The MarkArray defines two mark classes: Class0 consists of marks located above base glyphs, and Class1 consists of marks located below base glyphs.
The LigGlyphsArray has an offset to one LigatureAttach table for the covered ligature glyph. This table, called LamWithMeemWithJeemLigAttach, defines a count and array of the component glyphs in the ligature. Each ComponentRecord defines offsets to two Anchor tables, one for each mark class.
In the example, the first glyph component, lam, specifies a high attachment point for positioning accents above, but does not specify a low attachment point for placing accents below. The second glyph component, meem, defines a low attachment point for placing accents below, but not above. The third component, jeem, has no attachment points since the example defines no accents for it.
Example 8
| Hex Data | Source | Comments |
|---|---|---|
|
MarkLigPosFormat1
MarkLigAttachSubTable |
MarkLigPos subtable definition | |
| 0001 | 1 | PosFormat |
| 000C | MarkGlyphsCoverage | offset to MarkCoverage table |
| 0014 | LigGlyphsCoverage | offset to LigatureCoverage table |
| 0002 | 2 | ClassCount |
| 001A | MarkGlyphsArray | offset to MarkArray table |
| 0030 | LigGlyphsArray | offset to LigatureArray table
|
|
CoverageFormat1
MarkGlyphsCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0002 | 2 | GlyphCount |
| 033C | sukunMarkGlyphID | GlyphArray[0] |
| 033F | kasratanMarkGlyphID | GlyphArray[1]
|
|
CoverageFormat1
LigGlyphsCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0001 | 1 | GlyphCount |
| 0234 | LamWithMeemWithJeem LigatureGlyphID |
GlyphArray[0]
|
|
MarkArray
MarkGlyphsArray |
MarkArray table definition | |
| 0002 | 2 | MarkCount MarkRecord[0] in CoverageIndex order |
| 0000 | 0 | Class, for marks above components |
| 000A | sukunMarkAnchor | offset to Anchor table MarkRecord[1] |
| 0001 | 1 | Class, for marks below components |
| 0010 | kasratanMarkAnchor | offset to Anchor table
|
|
AnchorFormat1
sukunMarkAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 015A | 346 | XCoordinate |
| FF9E | -98 | YCoordinate
|
|
AnchorFormat1
kasratanMarkAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 0105 | 261 | XCoordinate |
| 01E8 | 488 | YCoordinate
|
|
LigatureArray
LigGlyphsArray |
LigatureArray table definition | |
| 0001 | 1 | LigatureCount |
| 0004 | LamWithMeemWithJeemLigAttach | offset to LigatureAttach table
|
|
LigatureAttach
LamWithMeemWithJeemLigAttach |
LigatureAttach table definition | |
| 0003 | 3 | ComponentCount ComponentRecord[0] Right-to-Left text order |
| 000E | AboveLamAnchor | offset to LigatureAnchor table ordered by mark class value for Class0 marks (above) |
| 0000 | NULL | offset to LigatureAnchor table no attachment points for Class1 marks ComponentRecord[1] |
| 0000 | NULL | offset to LigatureAnchor table no attachment points for Class0 marks |
| 0014 | BelowMeemAnchor | offset to LigatureAnchor table for Class1 marks (below) ComponentRecord[2] |
| 0000 | NULL | offset to LigatureAnchor table no attachment points for Class0 marks |
| 0000 | NULL | offset to LigatureAnchor table no attachment points for Class1 marks
|
|
AnchorFormat1
AboveLamAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 0271 | 625 | XCoordinate |
| 0708 | 1800 | YCoordinate
|
|
AnchorFormat1
BelowMeemAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 0178 | 376 | XCoordinate |
| FE90 | -368 | Ycoordinate |
Example 9: MarkMarkPosFormat1 Subtable
The MarkMarkPosFormat1 subtable in Example 9 defines two Arabic marks glyphs. The hanza mark, the base mark (Mark2), is identified in the Mark2GlyphsCoverage table. The damma mark, the attaching mark (Mark1), is defined in the Mark1GlyphsCoverage table.
Each Mark1 glyph is also listed in the Mark1Array, along with its attachment point data and a mark Class value. The Mark1GlyphsArray defines one mark class, Class0, that consists of marks located above Mark2 base glyphs. The Mark1GlyphsArray contains an offset to a dammaMarkAnchor table to specify the coordinate of the damma mark’s attachment point.
The Mark2GlyphsArray table defines a count and an array of Mark2Records, one for each covered Mark2 base glyph. Each record contains an offset to a Mark2Anchor table for each Mark1 class. One Anchor table, AboveMark2Anchor, specifies a coordinate value for attaching the damma mark above the hanza base mark.
Example 9
| Hex Data | Source | Comments |
|---|---|---|
|
MarkMarkPosFormat1
MarkMarkAttachSubTable |
MarkBasePos subtable definition | |
| 0001 | 1 | PosFormat |
| 000C | Mark1GlyphsCoverage | offset to Mark1Coverage table |
| 0012 | Mark2GlyphsCoverage | offset to Mark2Coverage table |
| 0001 | 1 | ClassCount |
| 0018 | Mark1GlyphsArray | offset to Mark1Array table |
| 0024 | Mark2GlyphsArray | offset to Mark2Array table
|
|
CoverageFormat1
Mark1GlyphsCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0001 | 1 | GlyphCount |
| 0296 | dammaMarkGlyphID | GlyphArray[0]
|
|
CoverageFormat1
Mark2GlyphsCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0001 | 1 | GlyphCount |
| 0289 | hanzaMarkGlyphID | GlyphArray[1]
|
|
MarkArray
Mark1GlyphsArray |
MarkArray table definition | |
| 0001 | 1 | MarkCount MarkRecord[0] in CoverageIndex order |
| 0000 | 0 | Class for marks above base mark |
| 0006 | dammaMarkAnchor | offset to Anchor table
|
|
AnchorFormat1
dammaMarkAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 00BD | 189 | XCoordinate |
| FF99 | -103 | YCoordinate
|
|
Mark2Array
Mark2GlyphsArray |
Mark2Array table definition | |
| 0001 | 1 | Mark2Count Mark2Record[0] |
| 0004 | AboveMark2Anchor | offset to Anchor table[0]
|
|
AnchorFormat1
AboveMark2Anchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 00DD | 221 | XCoordinate |
| 012D | 301 | Ycoordinate |
Example 10: ContextPosFormat1 Subtable and PosLookupRecord
Example 10 uses a ContextPosFormat1 subtable to adjust the spacing between three Arabic glyphs in a word. The context is the glyph sequence (from right to left): heh (initial form), thal (final form), and heh (isolated form). In the rendered word, the first two glyphs are connected, but the last glyph (the isolated form of heh), is separate. This subtable reduces the amount of space between the last glyph and the rest of the word.
The subtable contains a WordCoverage table that lists the first glyph in the word, heh (initial), and one PosRuleSet table, called WordPosRuleSet, that defines all contexts beginning with this covered glyph.
The WordPosRuleSet contains one PosRule that describes a word context of three glyphs and identifies the second and third glyphs (the first glyph is identified by the WordPosRuleSet). When a text-processing client locates this context in text, it applies a SinglePos lookup (not shown in the example) at position 2 to reduce the spacing between the glyphs.
Example 10
| Hex Data | Source | Comments |
|---|---|---|
|
ContextPosFormat1
MoveHehInSubtable |
ContextPos subtable definition | |
| 0001 | 1 | PosFormat |
| 0008 | WordCoverage | offset to Coverage table |
| 0001 | 1 | PosRuleSetCount |
| 000E | WordPosRuleSet | offset to PosRuleSet[0] table
|
|
CoverageFormat1 WordCoverage |
Coverage table offset | |
| 0001 | 1 | CoverageFormat |
| 0001 | 1 | GlyphCount |
| 02A6 | hehInitialGlyphID | GlyphArray[0]
|
|
PosRuleSet
WordPosRuleSet |
PosRuleSet table definition | |
| 0001 | 1 | PosRuleCount |
| 0004 | WordPosRule | Offset to PosRule[0] table
|
|
PosRule
WordPosRule |
PosRule table definition | |
| 0003 | 3 | GlyphCount |
| 0001 | 1 | PosCount |
| 02DD | thalFinalGlyphID | Input[1] |
| 02C6 | hehIsolatedGlyphID | Input[0] PosLookupRecord[0] |
| 0002 | 2 | SequenceIndex |
| 0001 | 1 | LookupListIndex |
Example 11: ContextPosFormat2 Subtable
The ContextPosFormat2 subtable in Example 11 defines context strings for five glyph classes: Class1 consists of uppercase glyphs that overhang and create a wide open space on their right side; Class2 consists of uppercase glyphs that overhang and create a narrow space on their right side; Class3 contains lowercase x-height vowels; and Class4 contains accent glyphs placed over the lowercase vowels. The rest of the glyphs in the font fall into Class0.
The MoveAccentsSubtable defines two similar context strings. The first consists of a Class1 uppercase glyph followed by a Class3 lowercase vowel glyph with a Class4 accent glyph over the vowel. When this context is found in the text, the client lowers the accent glyph over the vowel so that it does not collide with the overhanging glyph shape. The second context consists of a Class2 uppercase glyph, followed by a Class3 lowercase vowel glyph with a Class4 accent glyph over the vowel. When this context is found in the text, the client increases the advance width of the uppercase glyph to expand the space between it and the accented vowel.
The MoveAccents subtable defines a MoveAccentsCoverage table that identifies the first glyphs in the two contexts and offsets to five PosClassSet tables, one for each class defined in the ClassDef table. Since no contexts begin with Class0, Class3, or Class4 glyphs, the offsets to the PosClassSet tables for these classes are NULL. PosClassSet[1] defines all contexts beginning with Class1 glyphs; it is called UCWideOverhangPosClass1Set. PosClassSet[2] defines all contexts beginning with Class2 glyphs, and it is called UCNarrowOverhangPosClass1Set.
Each PosClassSet defines one PosClassRule. The UCWideOverhangPosClass1Set uses the UCWideOverhangPosClassRule to specify the first context. The first class in this context string is identified by the PosClassSet that includes a PosClassRule, in this case Class1. The PosClassRule table lists the second and third classes in the context as Class3 and Class4. A SinglePos Lookup (not shown) lowers the accent glyph in position 3 in the context string.
The UCNarrowOverhangPosClass1Set defines the UCNarrowOverhangPosClassRule for the second context. This PosClassRule is identical to the UCWideOverhangPosClassRule, except that the first class in the context string is a Class2 lowercase glyph. A SinglePos Lookup (not shown) increases the advance width of the overhanging uppercase glyph in position 0 in the context string.
Example 11
| Hex Data | Source | Comments |
|---|---|---|
|
ContextPosFormat2
MoveAccentsSubtable |
ContextPos subtable definition | |
| 0002 | 2 | PosFormat |
| 0012 | MoveAccentsCoverage | Offset to Coverage table |
| 0020 | MoveAccentsClassDef | Offset to ClassDef |
| 0005 | 5 | PosClassSetCnt |
| 0000 | NULL | PosClassSet[0], no contexts begin with Class0 glyphs |
| 0060 | UCWideOverhangPosClass1Set | PosClassSet[1] contexts beginning with Class1 glyphs |
| 0070 | UCNarrowOverhangPosClass2Set | PosClassSet[2] context beginning with Class2 glyphs |
| 0000 | NULL | PosClassSet[3], no contexts begin with Class3 glyphs |
| 0000 | NULL | PosClassSet[4], no contexts begin with Class4 glyphs
|
|
CoverageFormat1
MoveAccentsCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0005 | 5 | GlyphCount |
| 0029 | UppercaseFGlyphID | GlyphArray[0] |
| 0033 | UppercasePGlyphID | GlyphArray[1] |
| 0037 | UppercaseTGlyphID | GlyphArray[2] |
| 0039 | UppercaseVGlyphID | GlyphArray[3] |
| 003A | UppercaseWGlyphID | GlyphArray[4]
|
|
ClassDefFormat2
MoveAccentsClassDef |
ClassDef table definition defines five classes = 0 (all else), 1 (T, V, W: UCUnderhang), 2 (F, P: UCOverhang), 3 (a, e, I, o, u: LCVowels), 4 (tilde, umlaut) | |
| 0002 | 2 | ClassFormat, ranges |
| 000A | 10 | ClassRangeCount ClassRangeRecord[0] |
| 0029 | UppercaseFGlyphID | Start |
| 0029 | UppercaseFGlyphID | End |
| 0002 | 2 | Class ClassRangeRecord[1] |
| 0033 | UppercasePGlyphID | Start |
| 0033 | UppercasePGlyphID | End |
| 0002 | 2 | Class ClassRangeRecord[2] |
| 0037 | UppercaseTGlyphID | Start |
| 0037 | UppercaseTGlyphID | End |
| 0001 | 1 | Class ClassRangeRecord[3] |
| 0039 | UppercaseVGlyphID | Start |
| 003A | UppercaseWGlyphID | End |
| 0001 | 1 | Class ClassRangeRecord[4] |
| 0042 | LowercaseAGlyphID | Start |
| 0042 | LowercaseAGlyphID | End |
| 0003 | 3 | Class ClassRangeRecord[5] |
| 0046 | LowercaseEGlyphID | Start |
| 0046 | LowercaseEGlyphID | End |
| 0003 | 3 | Class ClassRangeRecord[6] |
| 004A | LowercaseIGlyphID | Start |
| 004A | LowercaseIGlyphID | End |
| 0003 | 3 | Class ClassRangeRecord[7] |
| 0051 | LowercaseOGlyphID | Start |
| 0051 | LowercaseOGlyphID | End |
| 0003 | 3 | Class ClassRangeRecord[8] |
| 0056 | LowercaseUGlyphID | Start |
| 0056 | LowercaseUGlyphID | End |
| 0003 | 3 | Class ClassRangeRecord[9] |
| 00F5 | TildeAccentGlyphID | Start |
| 00F6 | UmlautAccentGlyphID | End |
| 0004 | 4 | Class
|
|
PosClassSet
UCWideOverhangPosClass1Set |
PosClassSet table definition | |
| 0001 | 1 | PosClassRuleCnt |
| 0004 | UCWideOverhangPosClassRule | PosClassRule[0]
|
|
PosClassRule
UCWideOverhangPosClassRule |
PosClassRule table definition | |
| 0003 | 3 | GlyphCount |
| 0001 | 1 | PosCount |
| 0003 | 3 | Class[1], lowercase vowel |
| 0004 | 4 | Class[2], accent PosLookupRecord[0] |
| 0002 | 2 | SequenceIndex |
| 0001 | 1 | LookupListIndex, lower the accent
|
|
PosClassSet
UCNarrowOverhangPosClass2Set |
PosClassSet table definition | |
| 0001 | 1 | PosClassRuleCnt |
| 0004 | UCNarrowOverhangPosClassRule | PosClassRule[0]
|
|
PosClassRule
UCNarrowOverhangPosClassRule |
PosClassRule table definition | |
| 0003 | 3 | GlyphCount |
| 0001 | 1 | PosCount |
| 0003 | 3 | Class[1], lowercase vowel |
| 0004 | 4 | Class[2], accent PosLookupRecord[0] |
| 0000 | 0 | SequenceIndex |
| 0002 | 2 | LookupListIndex increase overhang advance width |
Example 12: ContextPosFormat3 Subtable
Example 12 uses a ContextPosFormat3 subtable to lower the position of math signs in math equations consisting of a lowercase descender or x-height glyph, a math sign glyph, and any lowercase glyph. Format3 is better to use for this context than the class-based Format2 because the sets of covered glyphs for positions 0 and 2 overlap.
The LowerMathSignsSubtable contains offsets to three Coverage tables (XhtDescLCCoverage, MathSignCoverage, and LCCoverage), one for each position in the context glyph string. When the client finds the context in the text stream, it applies the PosLookupRecord data at position 1 and repositions the math sign.
Example 12
| Hex Data | Source | Comments |
|---|---|---|
|
ContextPosFormat3
LowerMathSignsSubtable |
ContextPos subtable definition | |
| 0003 | 3 | PosFormat |
| 0003 | 3 | GlyphCount |
| 0001 | 1 | PosLookup |
| 0010 | XhtDescLCCoverage | Offset to Coverage[0] table |
| 003C | MathSignCoverage | Offset to Coverage[1] table |
| 0044 | LCCoverage | Offset to Coverage[2] table PosLookupRecord[0] |
| 0001 | 1 | SequenceIndex |
| 0001 | 1 | LookupListIndex
|
|
CoverageFormat1
XhtDescLCCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0014 | 20 | GlyphCount |
| 0033 | LCaGlyphID | GlyphArray[0] |
| 0035 | LCcGlyphID | GlyphArray[1] |
| 0037 | LCeGlyphID | GlyphArray[2] |
| 0039 | LCgGlyphID | GlyphArray[3] |
| 003B | LCiGlyphID | GlyphArray[4] |
| 003C | LCjGlyphID | GlyphArray[5] |
| 003F | LCmGlyphID | GlyphArray[6] |
| 0040 | LCnGlyphID | GlyphArray[7] |
| 0041 | LCoGlyphID | GlyphArray[8] |
| 0042 | LCpGlyphID | GlyphArray[9] |
| 0043 | LCqGlyphID | GlyphArray[10] |
| 0044 | LCrGlyphID | GlyphArray[11] |
| 0045 | LCsGlyphID | GlyphArray[12] |
| 0046 | LCtGlyphID | GlyphArray[13] |
| 0047 | LCuGlyphID | GlyphArray[14] |
| 0048 | LCvGlyphID | GlyphArray[15] |
| 0049 | LCwGlyphID | GlyphArray[16] |
| 004A | LCxGlyphID | GlyphArray[17] |
| 004B | LCyGlyphID | GlyphArray[18] |
| 004C | LCzGlyphID | GlyphArray[19]
|
|
CoverageFormat1
MathSignCoverage |
Coverage table definition | |
| 0001 | 1 | CoverageFormat |
| 0002 | 2 | GlyphCount |
| 011E | EqualsSignGlyphID | GlyphArray[0] |
| 012D | PlusSignGlyphID | GlyphArray[1]
|
|
CoverageFormat2
LCCoverage |
Coverage table definition | |
| 0002 | 2 | CoverageFormat |
| 0001 | 1 | RangeCount RangeRecord[0] |
| 0033 | LCaGlyphID | Start |
| 004C | LCzGlyphID | End |
| 0000 | 0 | StartCoverageIndex |
Example 13: PosLookupRecord
The PosLookupRecord in Example 13 identifies a lookup to apply at the second glyph position in a context glyph string.
Example 13
| Hex Data | Source | Comments |
|---|---|---|
|
PosLookupRecord
PosLookupRecord[0] |
PosLookupRecord definition | |
| 0001 | 1 | SequenceIndex for second glyph position |
| 0001 | 1 | LookupListIndex, apply this lookup to second glyph position |
Example 14: ValueFormat Table and ValueRecord
Example 14 demonstrates how to specify positioning values in the GPOS table. Here, a SinglePosFormat1 subtable defines the ValueFormat and ValueRecord. The ValueFormat bit setting of 0x0099 says that the corresponding ValueRecord contains values for a glyph’s XPlacement and YAdvance. Device tables specify pixel adjustments for these values at font sizes from 11 ppem to 15 ppem.
Example 14
| Hex Data | Source | Comments |
|---|---|---|
|
SinglePosFormat1
OnesSubtable |
SinglePos subtable definition | |
| 0001 | 1 | PosFormat |
| 000E | Cov | Offset to Coverage table |
| 0099 | 0x0099 | ValueFormat, for XPlacement, YAdvance, XPlaDevice, YAdvaDevice Value |
| 0050 | 80 | Xplacement value |
| 00D2 | 210 | Yadvance value |
| 0018 | XPlaDeviceTable | Offset to XPlaDevice table |
| 0020 | YAdvDeviceTable | Offset to YAdvDevice table
|
|
CoverageFormat2
Cov |
Coverage table definition | |
| 0002 | 2 | CoverageFormat |
| 0001 | 1 | RangeCount RangeRecord[0] |
| 00C8 | 200 | Start, first glyph ID in range |
| 00D1 | 209 | End, last glyph ID in range |
| 0000 | 0 | StartCoverageIndex
|
|
DeviceTableFormat1
XPlaDeviceTable |
Device Table definition | |
| 000B | 11 | StartSize |
| 000F | 15 | EndSize |
| 0001 | 1 | DeltaFormat |
| 1 | increase 11ppem by 1 pixel | |
| 1 | increase 12ppem by 1 pixel | |
| 1 | increase 13ppem by 1 pixel | |
| 1 | increase 14ppem by 1 pixel | |
| 5540 | 1 | increase 15ppem by 1 pixel
|
|
DeviceTableFormat1
YAdvDeviceTable |
Device Table definition | |
| 000B | 11 | StartSize |
| 000F | 15 | EndSize |
| 0001 | 1 | DeltaFormat |
| 1 | increase 11ppem by 1 pixel | |
| 1 | increase 12ppem by 1 pixel | |
| 1 | increase 13ppem by 1 pixel | |
| 1 | increase 14ppem by 1 pixel | |
| 5540 | 1 | increase 15ppem by 1 pixel |
Example 15: AnchorFormat1 Table
Example 15 illustrates an Anchor table for the damma mark glyph in the Arabic script. Format1 is used to specify X and Y coordinate values in design units.
Example 15
| Hex Data | Source | Comments |
|---|---|---|
|
AnchorFormat1
dammaMarkAnchor |
Anchor table definition | |
| 0001 | 1 | AnchorFormat |
| 00BD | 189 | XCoordinate |
| FF99 | -103 | YCoordinate |
Example 16: AnchorFormat2 Table
Example 16 shows an AnchorFormat2 table for an attachment point placed above a base glyph. With this format, the coordinate value for the Anchor depends on the final position of a specific contour point on the base glyph after hinting. The coordinates are specified in design units.
Example 16
| Hex Data | Source | Comments |
|---|---|---|
|
AnchorFormat2
AboveBaseAnchor |
Anchor table definition | |
| 0002 | 2 | AnchorFormat |
| 0142 | 322 | XCoordinate |
| 0384 | 900 | Ycoordinate |
| 000D | 13 | AnchorPoint glyph contour point index |
Example 17: AnchorFormat3 Table
Example 17 shows an AnchorFormat3 table that specifies an attachment point above a base glyph. Device tables modify the X and Y coordinates of the Anchor for the point size and resolution of the output font. Here, the Device tables define pixel adjustments for font sizes from 12 ppem to 17 ppem.
Example 17
| Hex Data | Source | Comments |
|---|---|---|
|
AnchorFormat3
AboveBaseAnchor |
Anchor table definition | |
| 0003 | 3 | AnchorFormat |
| 0117 | 279 | XCoordinate |
| 0515 | 1301 | YCoordinate |
| 000A | XDevice | offset to DeviceTable for X coordinate (may be NULL) |
| 0014 | YDevice | offset to Device table for Y coordinate (may be NULL)
|
|
DeviceTableFormat2
XDevice |
Device Table definition | |
| 000C | 12 | StartSize |
| 0011 | 17 | EndSize |
| 0002 | 2 | DeltaFormat |
| 1 | increase 12ppem by 1 pixel | |
| 1 | increase 13ppem by 1 pixel | |
| 1 | increase 14ppem by 1 pixel | |
| 1111 | 1 | increase 15ppem by 1 pixel |
| 2 | increase 16ppem by 1 pixel | |
| 2200 | 2 | increase 17ppem by 1 pixel
|
|
DeviceTableFormat2
YDevice |
Device Table definition | |
| 000C | 12 | StartSize |
| 0011 | 17 | EndSize |
| 0002 | 2 | DeltaFormat |
| 1 | increase 12ppem by 1 pixel | |
| 1 | increase 13ppem by 1 pixel | |
| 1 | increase 14ppem by 1 pixel | |
| 1111 | 1 | increase 15ppem by 1 pixel |
| 2 | increase 16ppem by 1 pixel | |
| 2200 | 2 | increase 17ppem by 1 pixel |
Example 18: MarkArray Table and MarkRecord
Example 18 shows a MarkArray table with class and attachment point data for two accent marks, a grave and a cedilla. Two MarkRecords are defined, one for each covered mark glyph. The first MarkRecord assigns a mark class value of 0 to accents placed above base glyphs, such as the grave, and has an offset to a graveMarkAnchor table. The second MarkRecord assigns a mark class value of 1 for all accents positioned below base glyphs, such as the cedilla, and has an offset to a cedillaMarkAnchor table.
Example 18
| Hex Data | Source | Comments |
|---|---|---|
|
MarkArray
MarkGlyphsArray |
MarkArray table definition | |
| 0002 | 2 | MarkCount MarkRecord[0] for first mark in MarkCoverage table, grave |
| 0000 | 0 | Class, for marks placed above base glyphs |
| 000A | graveMarkAnchor | offset to Anchor table MarkRecord[1] for second mark in MarkCoverage table = cedilla |
| 0001 | 1 | Class, for marks placed below base glyphs |
| 0010 | cedillaMarkAnchor | offset to Anchor table |
OpenType specification