DML_MULTIHEAD_ATTENTION_OPERATOR_DESC 構造体 (directml.h)
マルチヘッド アテンション操作を実行します (詳細については、「必要なものはアテンション」を参照してください)。 スタックされているかどうかに関係なく、1 つのクエリ、キー、値のテンソルのみが存在する必要があります。 たとえば、StackedQueryKey が指定されている場合、クエリテンソルとキー テンソルの両方が null である必要があります。これらは既にスタック レイアウトで提供されているためです。 StackedKeyValue と StackedQueryKeyValue も同様です。 スタックされたテンソルは常に 5 つの次元を持ち、常に 4 番目の次元に積み上げされます。
論理的には、アルゴリズムを次の操作に分解できます (角かっこ内の操作は省略可能)。
[Add Bias to query/key/value] -> GEMM(Query, Transposed(Key)) * Scale -> [Add RelativePositionBias] -> [Add Mask] -> Softmax -> GEMM(SoftmaxResult, Value);
重要
この API は、DirectML スタンドアロン再頒布可能パッケージの一部として使用できます (Microsoft.AI.DirectML バージョン 1.12 以降を参照してください)。 DirectML バージョン履歴も参照してください。
構文
struct DML_MULTIHEAD_ATTENTION_OPERATOR_DESC
{
_Maybenull_ const DML_TENSOR_DESC* QueryTensor;
_Maybenull_ const DML_TENSOR_DESC* KeyTensor;
_Maybenull_ const DML_TENSOR_DESC* ValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* BiasTensor;
_Maybenull_ const DML_TENSOR_DESC* MaskTensor;
_Maybenull_ const DML_TENSOR_DESC* RelativePositionBiasTensor;
_Maybenull_ const DML_TENSOR_DESC* PastKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* PastValueTensor;
const DML_TENSOR_DESC* OutputTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentValueTensor;
FLOAT Scale;
FLOAT MaskFilterValue;
UINT HeadCount;
DML_MULTIHEAD_ATTENTION_MASK_TYPE MaskType;
};
メンバー
QueryTensor
型: _Maybenull_ const DML_TENSOR_DESC*
hiddenSize = headCount * headSize の場合、図形 [batchSize, sequenceLength, hiddenSize] を使用してクエリを実行します。 このテンソルは、StackedQueryKeyTensor および StackedQueryKeyValueTensor と相互に排他的です。 テンソルは、先頭の次元が 1 である限り、4 つまたは 5 つの次元を持つこともできます。
KeyTensor
型: _Maybenull_ const DML_TENSOR_DESC*
hiddenSize = headCount * headSize の場合の、形状 [batchSize, keyValueSequenceLength, hiddenSize] のキー。 このテンソルは、StackedQueryKeyTensor、StackedKeyValueTensor、および StackedQueryKeyValueTensor と相互に排他的です。 テンソルは、先頭の次元が 1 である限り、4 つまたは 5 つの次元を持つこともできます。
ValueTensor
型: _Maybenull_ const DML_TENSOR_DESC*
valueHiddenSize = headCount * valueHeadSize の場合に形状 [batchSize, keyValueSequenceLength, valueHiddenSize] を持つ値。 このテンソルは、StackedKeyValueTensor および StackedQueryKeyValueTensor と相互に排他的です。 テンソルは、先頭の次元が 1 である限り、4 つまたは 5 つの次元を持つこともできます。
StackedQueryKeyTensor
型: _Maybenull_ const DML_TENSOR_DESC*
形状 [batchSize, sequenceLength, headCount, 2, headSize] のスタック クエリとキー。 このテンソルは、QueryTensor、KeyTensor、StackedKeyValueTensor、StackedQueryKeyValueTensor と相互に排他的です。
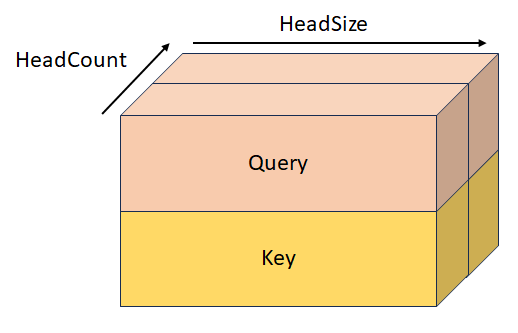
StackedKeyValueTensor
型: _Maybenull_ const DML_TENSOR_DESC*
形状 [batchSize, keyValueSequenceLength, headCount, 2, headSize] のスタック キーと値。 このテンソルは、KeyTensor、ValueTensor、StackedQueryKeyTensor、StackedQueryKeyValueTensor と相互に排他的です。
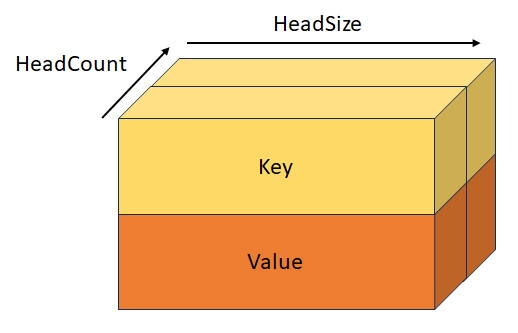
StackedQueryKeyValueTensor
型: _Maybenull_ const DML_TENSOR_DESC*
形状 [batchSize, sequenceLength, headCount, 3, headSize] のスタック クエリ、キー、値。 このテンソルは、QueryTenso、KeyTensor、ValueTensor、StackedQueryKeyTensor、StackedKeyValueTensor と相互に排他的です。

BiasTensor
型: _Maybenull_ const DML_TENSOR_DESC*
これは、最初の GEMM 操作の前にクエリ/キー/値に追加される形状 [hiddenSize + hiddenSize + valueHiddenSize] のバイアスです。 このテンソルは、先頭の寸法が 1 である限り、2、3、4、または 5 次元を持つこともできます。
MaskTensor
型: _Maybenull_ const DML_TENSOR_DESC*
これは、QxK GEMM 操作の後に MaskFilterValue に設定された値を取得する要素を決定するマスクです。 このマスクの動作は MaskType の値に依存し、RelativePositionBiasTensor の後、または RelativePositionBiasTensor が null の場合は最初の GEMM 操作の後に適用されます。 詳細については、MaskType の定義を参照してください。
RelativePositionBiasTensor
型: _Maybenull_ const DML_TENSOR_DESC*
これは、最初の GEMM 操作の結果に追加されるバイアスです。
PastKeyTensor
型: _Maybenull_ const DML_TENSOR_DESC*
形状 [batchSize, headCount, pastSequenceLength, headSize] を持つ、前のイテレーションのキー テンソル。 このテンソルが null でない場合は、鍵 テンソルと連結され、形状 [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize] のテンソルになります。
PastValueTensor
型: _Maybenull_ const DML_TENSOR_DESC*
形状 [batchSize, headCount, pastSequenceLength, headSize] の、前のイテレーションの値テンソル。 このテンソルが null でない場合は、ValueDesc と連結され、形状 [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize] のテンソルになります。
OutputTensor
型: const DML_TENSOR_DESC*
形状 [batchSize, sequenceLength, valueHiddenSize] の出力。
OutputPresentKeyTensor
型: _Maybenull_ const DML_TENSOR_DESC*
形状 [batchSize, headCount, keyValueSequenceLength, headSize] の場合はクロス アテンション キーの、形状 [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize] の場合はセルフ アテンション キーの現在の状態。 キー テンソルの内容、または次のイテレーションに渡す連結された PastKey + キー テンソルの内容が含まれます。
OutputPresentValueTensor
型: _Maybenull_ const DML_TENSOR_DESC*
形状 [batchSize, headCount, keyValueSequenceLength, headSize] の場合はクロス アテンション値の、形状 [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize] の場合はセルフ アテンション 値の現在の状態。 値テンソルの内容、または次のイテレーションに渡すまたは連結された PastValue + Value テンソルの内容が含まれます。
Scale
型: FLOAT
QxK GEMM 操作の結果を、Softmax 操作の前にスケーリングし、乗算します。 通常、その値は 1/sqrt(headSize) です。
MaskFilterValue
型: FLOAT
マスクが埋め込み要素として定義した位置で、 QxK GEMM 操作の結果に追加される値。 この値は、非常に大きな負の数 (通常は -10000.0f) にする必要があります。
HeadCount
型: UINT
アテンション ヘッドの数。
MaskType
型: DML_MULTIHEAD_ATTENTION_MASK_TYPE
MaskTensor の動作について説明します。
DML_MULTIHEAD_ATTENTION_MASK_TYPE_BOOLEAN。 マスクに 0 の値が含まれている場合、MaskFilterValue が追加されますが、値 1 が含まれている場合、何も追加されません。
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_LENGTH。 形状 [1, batchSize] のマスクには、各バッチの埋め込みなし領域のシーケンス長が含まれており、シーケンスの長さより後のすべての要素の値が MaskFilterValue に設定されます。
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_END_START。 形状 [2, batchSize] のマスクには、埋め込みなしの領域の終了 (排他) インデックスと開始 (包括) インデックスが含まれており、領域外のすべての要素の値が MaskFilterValue に設定されます。
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_QUERY_SEQUENCE_LENGTH_START_END。 形状 [batchSize * 3 + 2]のマスクには、次の値があります: [keyLength[0], ..., keyLength[batchSize - 1], queryStart[0], ..., queryStart[batchSize - 1], queryEnd[batchSize - 1], keyStart[0], ..., keyStart[batchSize - 1], keyEnd[batchSize - 1]]。
可用性
この演算子は、DML_FEATURE_LEVEL_6_1で導入されました。
Tensor 制約
BiasTensor、KeyTensor、OutputPresentKeyTensor、OutputPresentValueTensor、OutputTensor、PastKeyTensor、PastValueTensor、QueryTensor、RelativePositionBiasTensor、StackedKeyValueTensor、StackedQueryKeyTensor、StackedQueryKeyValueTensor、および ValueTensor には、同じ DataType が必要です。
Tensor のサポート
| Tensor | 種類 | サポートされているディメンション数 | サポートされるデータ型 |
|---|---|---|---|
| QueryTensor | 省略可能な入力 | 3 から 5 まで | FLOAT32、FLOAT16 |
| KeyTensor | 省略可能な入力 | 3 から 5 まで | FLOAT32、FLOAT16 |
| ValueTensor | 省略可能な入力 | 3 から 5 まで | FLOAT32、FLOAT16 |
| StackedQueryKeyTensor | 省略可能な入力 | 5 | FLOAT32、FLOAT16 |
| StackedKeyValueTensor | 省略可能な入力 | 5 | FLOAT32、FLOAT16 |
| StackedQueryKeyValueTensor | 省略可能な入力 | 5 | FLOAT32、FLOAT16 |
| BiasTensor | 省略可能な入力 | 1 から 5 | FLOAT32、FLOAT16 |
| MaskTensor | 省略可能な入力 | 1 から 5 | INT32 |
| RelativePositionBiasTensor | 省略可能な入力 | 4 から 5 | FLOAT32、FLOAT16 |
| PastKeyTensor | 省略可能な入力 | 4 から 5 | FLOAT32、FLOAT16 |
| PastValueTensor | 省略可能な入力 | 4 から 5 | FLOAT32、FLOAT16 |
| OutputTensor | 出力 | 3 から 5 まで | FLOAT32、FLOAT16 |
| OutputPresentKeyTensor | 省略可能な出力 | 4 から 5 | FLOAT32、FLOAT16 |
| OutputPresentValueTensor | 省略可能な出力 | 4 から 5 | FLOAT32、FLOAT16 |
要件
| ヘッダー | directml.h |