Azure Search と Xamarin.Forms を使用してデータを検索する
 サンプルのダウンロード
サンプルのダウンロードAzure Search は、アップロードされたデータのインデックス作成とクエリ実行の機能を提供するクラウド サービスです。 これにより、従来、アプリケーションでの検索機能の実装に付きものであったインフラストラクチャの要件と検索アルゴリズムの複雑さがなくなります。 この記事では、Microsoft Azure Search Library を使用して Azure Search を Xamarin.Forms アプリケーションに統合する方法を見ていきます。
概要
データは、インデックスとドキュメントとして Azure Search に格納されます。 "インデックス" は、Azure Search Service で検索できるデータのストアであり、概念的にはデータベースのテーブルに似ています。 "ドキュメント" は、インデックス内で検索可能なデータの 1 つの単位であり、概念的にはデータベースの行に似ています。 Azure Search にドキュメントをアップロードして検索クエリを送信するときは、検索サービス内の特定のインデックスに対する要求が行われます。
Azure Search に対して行われる各要求には、サービスの名前と API キーが含まれている必要があります。 API キーには 2 つの種類があります。
- "管理者キー" は、すべての操作に対する完全な権限を付与します。 これには、サービスの管理、インデックスの作成と削除、データ ソースが含まれます。
- "クエリ キー" は、インデックスとドキュメントに対する読み取り専用アクセスを許可し、検索要求を発行するアプリケーションで使う必要があります。
Azure Search に対する最も一般的な要求は、クエリを実行することです。 送信できるクエリには、2 つの種類があります。
- "検索" クエリは、インデックス内のすべての検索可能なフィールドで 1 つ以上の項目を検索します。 検索クエリは、簡略化された構文つまり Lucene クエリ構文を使って構築されます。 詳しくは、Azure Search での単純なクエリ構文および Azure Search での Lucene クエリ構文に関する記事をご覧ください。
- "フィルター" クエリは、インデックス内のすべてのフィルター可能なフィールドに対してブール式を評価します。 フィルター クエリは、OData フィルター言語のサブセットを使って構築されます。 詳しくは、Azure Search の OData 式構文に関する記事をご覧ください。
検索クエリとフィルター クエリは、個別または一緒に使用できます。 一緒に使うと、最初にフィルター クエリがインデックス全体に適用された後、フィルター クエリの結果に対して検索クエリが実行されます。
Azure Search では、検索入力に基づく提案の取得もサポートされています。 詳しくは、「提案クエリ」をご覧ください。
Note
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
段取り
Azure Search を Xamarin.Forms アプリケーションに統合するプロセスは次のとおりです。
- Azure 検索サービスを作成します。 詳しくは、Azure portal を使用した Azure 検索サービスの作成に関する記事をご覧ください。
- Xamarin.Forms ソリューションのポータブル クラス ライブラリ (PCL) からターゲット フレームワークとしての Silverlight を削除します。 これを実現するには、クロスプラットフォーム開発はサポートしているものの Silverlight はサポートしていないプロファイル (プロファイル 151 やプロファイル 92 など) に、PCL プロファイルを変更します。
- Microsoft Azure Search Library NuGet パッケージを、Xamarin.Forms ソリューションの PCL プロジェクトに追加します。
以上の手順を行った後は、Microsoft Search Library API を使って、検索インデックスとデータ ソースの管理、ドキュメントのアップロードと管理、クエリの実行を行うことができます。
Azure Search インデックスの作成
検索対象のデータの構造にマップするインデックス スキーマを定義する必要があります。 これは、Azure portal で、または SearchServiceClient クラスを使ってプログラムで、行うことができます。 このクラスは Azure Search への接続を管理し、インデックスの作成に使用できます。 次のコード例では、このクラスのインスタンスを作成する方法を見ていきます。
var searchClient =
new SearchServiceClient(Constants.SearchServiceName, new SearchCredentials(Constants.AdminApiKey));
SearchServiceClient コンストラクターのオーバーロードは、検索サービスの名前と SearchCredentials オブジェクトを引数として受け取ります。SearchCredentials オブジェクトは、Azure 検索サービスの "管理者キー" をラップしています。 インデックスを作成するには、"管理者キー" が必要です。
Note
Azure Search への接続が多くなりすぎないように、アプリケーションで使う SearchServiceClient インスタンスは 1 つにする必要があります。
次のコード例で示すように、インデックスは Index オブジェクトによって定義されます。
static void CreateSearchIndex()
{
var index = new Index()
{
Name = Constants.Index,
Fields = new[]
{
new Field("id", DataType.String) { IsKey = true, IsRetrievable = true },
new Field("name", DataType.String) { IsRetrievable = true, IsFilterable = true, IsSortable = true, IsSearchable = true },
new Field("location", DataType.String) { IsRetrievable = true, IsFilterable = true, IsSortable = true, IsSearchable = true },
new Field("details", DataType.String) { IsRetrievable = true, IsFilterable = true, IsSearchable = true },
new Field("imageUrl", DataType.String) { IsRetrievable = true }
},
Suggesters = new[]
{
new Suggester("nameSuggester", SuggesterSearchMode.AnalyzingInfixMatching, new[] { "name" })
}
};
searchClient.Indexes.Create(index);
}
Index.Name プロパティにはインデックスの名前を設定し、Index.Fields プロパティには Field オブジェクトの配列を設定する必要があります。 各 Field インスタンスでは、名前、型、フィールドの使用方法を指定する任意のプロパティを指定します。 これには次のようなプロパティがあります。
IsKey: フィールドがインデックスのキーかどうかを示します。 インデックス内のDataType.String型のフィールドを 1 つだけ、キー フィールドとして指定する必要があります。IsFacetable: このフィールドでファセット ナビゲーションを実行できるかどうかを示します。 既定値はfalseです。IsFilterable: そのフィールドをフィルター クエリで使用できるかどうかを示します。 既定値はfalseです。IsRetrievable: そのフィールドを検索結果で取得できるかどうかを示します。 既定値はtrueです。IsSearchable: そのフィールドがフルテキスト検索に含まれるかどうかを示します。 既定値はfalseです。IsSortable: そのフィールドをOrderBy式で使用できるかどうかを示します。 既定値はfalseです。
Note
デプロイ後にインデックスを変更したら、データを再構築して再度読み込む必要があります。
Index オブジェクトでは、必要に応じて、オートコンプリートまたは提案クエリをサポートするために使われるインデックス内のフィールドを定義する Suggesters プロパティを指定できます。 Suggesters プロパティには、検索候補の結果を作成するために使われるフィールドを定義する Suggester オブジェクトの配列を設定する必要があります。
Index オブジェクトを作成した後、SearchServiceClient インスタンスで Indexes.Create を呼び出してインデックスを作成します。
Note
応答性を維持する必要があるアプリケーションからインデックスを作成する場合は、Indexes.CreateAsync メソッドを使います。
詳しくは、.NET SDK を使用した Azure Search インデックスの作成に関する記事をご覧ください。
Azure Search インデックスの削除
インデックスは、SearchServiceClient インスタンスで Indexes.Delete を呼び出して削除できます。
searchClient.Indexes.Delete(Constants.Index);
Azure Search インデックスへのデータのアップロード
インデックスを定義した後は、2 つのモデルのいずれかを使ってデータをそれにアップロードできます。
- プル モデル: データは、Azure Cosmos DB、Azure SQL Database、Azure Blob Storage、または Azure 仮想マシンでホストされている SQL Server から定期的に取り込まれます。
- プッシュ モデル: データは、プログラムによってインデックスに送信されます。 これは、この記事で採用されているモデルです。
インデックスにデータをインポートするには、SearchIndexClient インスタンスを作成する必要があります。 これは、次のコード例で示すように、SearchServiceClient.Indexes.GetClient メソッドを呼び出して実現できます。
static void UploadDataToSearchIndex()
{
var indexClient = searchClient.Indexes.GetClient(Constants.Index);
var monkeyList = MonkeyData.Monkeys.Select(m => new
{
id = Guid.NewGuid().ToString(),
name = m.Name,
location = m.Location,
details = m.Details,
imageUrl = m.ImageUrl
});
var batch = IndexBatch.New(monkeyList.Select(IndexAction.Upload));
try
{
indexClient.Documents.Index(batch);
}
catch (IndexBatchException ex)
{
// Sometimes when the Search service is under load, indexing will fail for some
// documents in the batch. Compensating actions like delaying and retrying should be taken.
// Here, the failed document keys are logged.
Console.WriteLine("Failed to index some documents: {0}",
string.Join(", ", ex.IndexingResults.Where(r => !r.Succeeded).Select(r => r.Key)));
}
}
インデックスにインポートするデータは、IndexAction オブジェクトのコレクションをカプセル化している IndexBatch オブジェクトとしてパッケージ化します。 各 IndexAction インスタンスには、ドキュメントと、ドキュメントに対して実行するアクションを Azure Search に指示するプロパティが含まれています。 上のコード例では IndexAction.Upload アクションが指定されているため、ドキュメントは、新しい場合はインデックスに挿入され、既に存在する場合は置き換えられます。 その後、SearchIndexClient オブジェクトで Documents.Index メソッドを呼び出して、IndexBatch オブジェクトをインデックスに送信します。 他のインデックス作成アクションについては、使用するインデックス作成アクションの決定に関する記事をご覧ください。
Note
1 つのインデックス作成要求に含めることができるドキュメントは 1000 個のみです。
上のコード例では、monkeyList コレクションを Monkey オブジェクトのコレクションから匿名オブジェクトとして作成していることに注意してください。 これにより、id フィールドのデータが作成され、パスカル ケースの Monkey プロパティ名からキャメル ケースの検索インデックス フィールド名へのマッピングが解決されます。 または、Monkey クラスに [SerializePropertyNamesAsCamelCase] 属性を追加して、このマッピングを実現することもできます。
詳しくは、.NET SDK を使用した Azure Search へのデータのアップロードに関する記事をご覧ください。
Azure Search インデックスのクエリ
インデックスのクエリを実行するには、SearchIndexClient インスタンスを作成する必要があります。 アプリケーションでクエリを実行するときは、最小特権の原則に従い、SearchIndexClient を直接作成して、"クエリ キー" を引数として渡すことをお勧めします。 これにより、ユーザーはインデックスとドキュメントに対して読み取り専用アクセス権を持つようになります。 このアプローチは次のコード例で示されています。
SearchIndexClient indexClient =
new SearchIndexClient(Constants.SearchServiceName, Constants.Index, new SearchCredentials(Constants.QueryApiKey));
SearchIndexClient コンストラクターのオーバーロードは、検索サービスの名前、インデックスの名前、SearchCredentials オブジェクトを引数として受け取ります。SearchCredentials オブジェクトは、Azure 検索サービスの "クエリ キー" をラップしています。
検索クエリ
次のコード例で示すように、インデックスのクエリを実行するには、SearchIndexClient インスタンスで Documents.SearchAsync メソッドを呼び出します。
async Task AzureSearch(string text)
{
Monkeys.Clear();
var searchResults = await indexClient.Documents.SearchAsync<Monkey>(text);
foreach (SearchResult<Monkey> result in searchResults.Results)
{
Monkeys.Add(new Monkey
{
Name = result.Document.Name,
Location = result.Document.Location,
Details = result.Document.Details,
ImageUrl = result.Document.ImageUrl
});
}
}
SearchAsync メソッドは、検索テキストの引数と、クエリをさらに絞り込むために使用できるオプションの SearchParameters オブジェクトを受け取ります。 検索クエリは検索テキスト引数として指定するのに対し、フィルター クエリは、SearchParameters 引数の Filter プロパティを設定して指定できます。 次のコード例では、両方のクエリの種類を見ていきます。
var parameters = new SearchParameters
{
Filter = "location ne 'China' and location ne 'Vietnam'"
};
var searchResults = await indexClient.Documents.SearchAsync<Monkey>(text, parameters);
このフィルター クエリはインデックス全体に適用され、location フィールドが China でも Vietnam でもないドキュメントを結果から削除します。 フィルター処理の後、フィルター クエリの結果に対して検索クエリが実行されます。
Note
検索を行わずにフィルター処理するには、検索テキスト引数として * を渡します。
SearchAsync メソッドは、クエリ結果を含む DocumentSearchResult オブジェクトを返します。 このオブジェクトが列挙され、各 Document オブジェクトが Monkey オブジェクトとして作成されて、表示のために MonkeysObservableCollection に追加されます。 次のスクリーンショットは、Azure Search から返された検索クエリの結果を示しています。
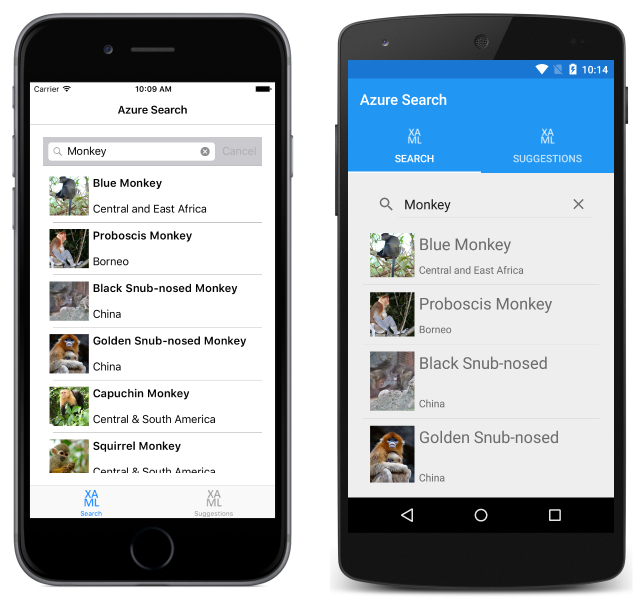
検索とフィルター処理について詳しくは、.NET SDK を使用した Azure Search インデックスのクエリに関する記事をご覧ください。
提案クエリ
Azure Search では、SearchIndexClient インスタンスで Documents.SuggestAsync メソッドを呼び出して、検索クエリに基づく提案を要求できます。 次のコード例ではこれを見ていきます。
async Task AzureSuggestions(string text)
{
Suggestions.Clear();
var parameters = new SuggestParameters()
{
UseFuzzyMatching = true,
HighlightPreTag = "[",
HighlightPostTag = "]",
MinimumCoverage = 100,
Top = 10
};
var suggestionResults =
await indexClient.Documents.SuggestAsync<Monkey>(text, "nameSuggester", parameters);
foreach (var result in suggestionResults.Results)
{
Suggestions.Add(new Monkey
{
Name = result.Text,
Location = result.Document.Location,
Details = result.Document.Details,
ImageUrl = result.Document.ImageUrl
});
}
}
SuggestAsync メソッドは、検索テキスト引数、使用する suggester の名前 (インデックスで定義されているもの)、クエリをさらに絞り込むために使用できるオプションの SuggestParameters オブジェクトを受け取ります。 SuggestParameters インスタンスは、次のプロパティを設定します。
UseFuzzyMatching:trueに設定すると、Azure Search は、検索テキストに置換文字または不足文字がある場合でも、提案を検索します。HighlightPreTag: 提案ヒットの前に付けるタグ。HighlightPostTag: 提案ヒットの後に付けるタグ。MinimumCoverage: クエリが成功と報告されるために、提案クエリによってカバーされている必要があるインデックスの割合を表します。 既定値は 80 です。Top: 取得する提案の数。 1 から 100 の間の整数である必要があり、既定値は 5 です。
全体的な効果として、インデックスの上位 10 件の結果がヒットを強調表示して返され、結果にはスペルが似ている検索語句を含むドキュメントが含まれます。
SuggestAsync メソッドは、クエリ結果を含む DocumentSuggestResult オブジェクトを返します。 このオブジェクトが列挙され、各 Document オブジェクトが Monkey オブジェクトとして作成されて、表示のために MonkeysObservableCollection に追加されます。 次のスクリーンショットは、Azure Search から返された提案の結果を示しています。
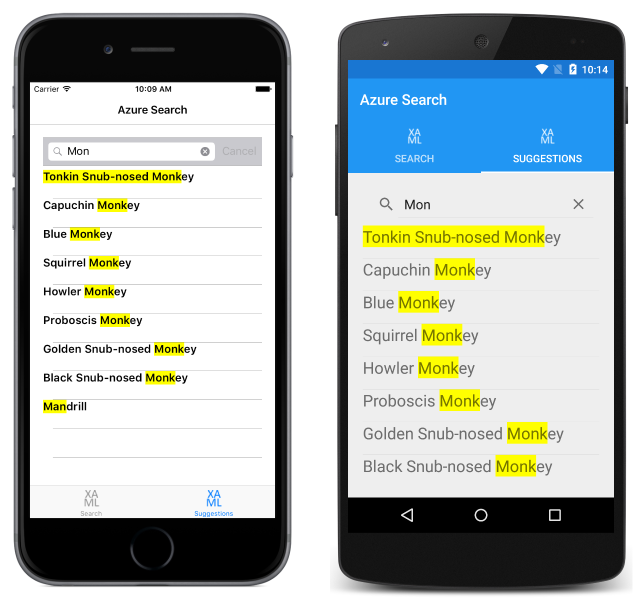
サンプル アプリケーションの SuggestAsync メソッドは、ユーザーが検索語句の入力を終えたときにのみ呼び出されることに注意してください。 ただし、キーが押されるたびに実行し、オートコンプリート検索クエリをサポートするために使うこともできます。
まとめ
この記事では、Microsoft Azure Search Library を使って Azure Search を Xamarin.Forms アプリケーションに統合する方法を見てきました。 Azure Search は、アップロードされたデータのインデックス作成とクエリ実行の機能を提供するクラウド サービスです。 これにより、従来、アプリケーションでの検索機能の実装に付きものであったインフラストラクチャの要件と検索アルゴリズムの複雑さがなくなります。