Ескерім
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Жүйеге кіруді немесе каталогтарды өзгертуді байқап көруге болады.
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Каталогтарды өзгертуді байқап көруге болады.
Примечание.
Сведения о языковых стандартах, поддерживаемых идентификатором viseme и фигурами смешения, см . в списке всех поддерживаемых языков. Масштабируемая векторная графика (SVG) поддерживается только для языкового en-US стандарта.
Визема — это визуальное описание фонемы в устной речи. Она определяет положение лица и рта в тот или иной момент речи. Каждая визема отображает основные расположения лица для определенного набора фонем.
Виземы можно использовать для управления перемещением двухмерной и трехмерной моделей аватара, чтобы положения лица лучше соответствовали синтезируемой речи. Например, доступны следующие возможности:
- Создать анимированный виртуальный голосовой помощник для интеллектуальных киосков при создании интегрированных служб с несколькими режимами для ваших клиентов.
- Создать иммерсивные трансляции новостей и улучшить восприятие аудиторией натурального лица или движений рта.
- Создать больше интерактивных игровых аватаров и персонажей мультфильмов, умеющих разговаривать с динамичным содержимым.
- Создать более эффективные видеоматериалы по изучению языка, которые помогут обучающимся понимать движения рта во время произношения слов и фонем.
- Люди с нарушениями слуха также могут визуально различать звуки и читать речь по губам с помощью визем на анимированном лице.
Дополнительные сведения о виземах см. в этом вступительном видеоролике.
Общий рабочий процесс создания визем с речью
Нейронный текст для речи (Нейронный TTS) преобразует входной текст или SSML (язык разметки синтеза речи) в синтезируемую речь. Речевые выходные данные могут сопровождаться идентификатором виземы, масштабируемой векторной графикой (SVG) или смешанными фигурами. С помощью двух- или трехмерного обработчика визуализации эти события виземы можно использовать для анимации аватара.
Общий рабочий процесс, связанный с виземой, показан на следующей блок-схеме.
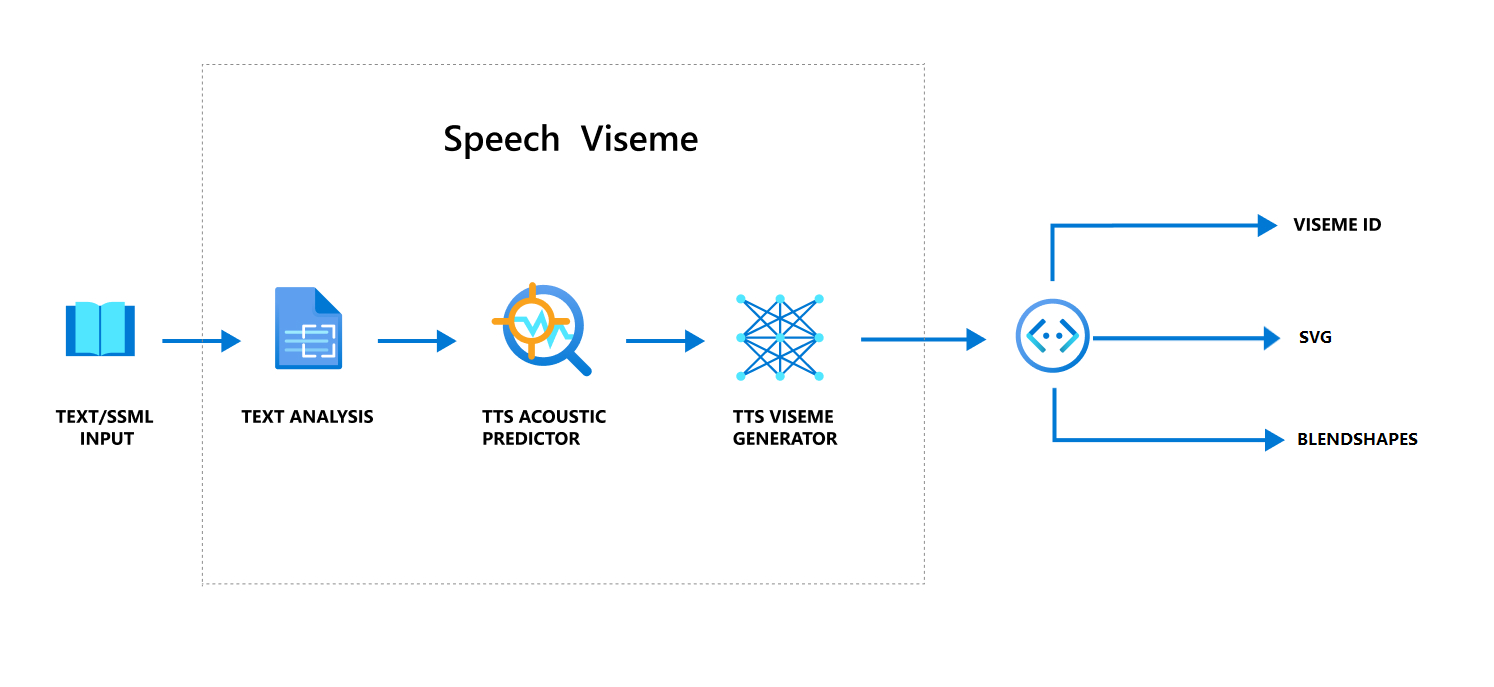
Идентификатор виземы
Идентификатор виземы — это целое число, указывающее на конкретную визему. Мы предлагаем 22 виземы, каждая из которых показывает положение рта для определенного набора фонем. Между виземами и фонемами нет однозначного соответствия. Часто несколько фонем соответствуют одному виземе, потому что они выглядят одинаково на лице говорящего, когда они производятся, например s и z. Более подробные сведения см. в таблице для сопоставления фонем с идентификаторами визем.
Речевые выходные данные могут сопровождаться идентификаторами визем и Audio offset.
Audio offset указывает метку времени смещения, представляющую время начала каждой виземы в тактах (100 наносекунд).
Сопоставление фонем и визем
Виземы зависят от языка и языкового стандарта. Каждый языковой стандарт обладает набором визем, соответствующих его определенным фонемам. В документе Фонетические алфавиты SSML идентификаторы визем сопоставляются с соответствующими фонемами международного фонетического алфавита (IPA). В таблице в этом разделе показана связь между идентификаторами виземы и позициями рта, в которой перечислены типичные телефонные мемы IPA для каждого идентификатора viseme.
| Идентификатор виземы | МФА | Положение рта |
|---|---|---|
| 0 | Тишина |

|
| 1 |
æ, , əʌ |

|
| 2 | ɑ |

|
| 3 | ɔ |

|
| 4 |
ɛ, ʊ |

|
| 5 | ɝ |

|
| 6 |
j, , iɪ |

|
| 7 |
w, u |

|
| 8 | o |

|
| 9 | aʊ |

|
| 10 | ɔɪ |

|
| 11 | aɪ |

|
| 12 | h |

|
| 13 (тринадцать) | ɹ |

|
| 14 | l |

|
| 15 |
s, z |

|
| 16 |
ʃ, , tʃdʒʒ |

|
| 17 | ð |

|
| 18 |
f, v |

|
| 19 |
d, , tnθ |

|
| 20 |
k, , gŋ |

|
| двадцать один |
p, , bm |

|
Двумерная анимация SVG
В случае с двумерными персонажами можно разработать персонаж, подходящего для вашего сценария, и использовать SVG для каждого идентификатора виземы, чтобы получить положение лица на основе времени.
С темпоральными тегами, предоставляемыми в событии viseme, эти хорошо разработанные SVG обрабатываются с изменением сглаживания и обеспечивают надежную анимацию для пользователей. Например, на следующем рисунке показан красный символ, предназначенный для обучения языка.

Трехмерная анимация смешанных фигур
Смешанные фигуры позволяют управлять движениями лица трехмерного персонажа, разработанного вами.
Строка JSON смешанных фигур представляется в виде двумерной матрицы. Каждая строка представляет один кадр. Каждый кадр (при 60 кадрах/с) содержит массив из 55 положений лица.
Получение событий виземы с помощью пакета SDK для службы "Речь"
Чтобы получить визему с вашей синтезированной речью, подпишитесь на событие VisemeReceived в пакете SDK для службы "Речь".
Примечание.
Чтобы запросить выходные данные SVG или фигур смешения, используйте элемент mstts:viseme в SSML. Дополнительные сведения см. в статье об использовании элемента виземы в SSML.
В следующем фрагменте показано, как подписаться на событие виземы.
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Пример выходных данных виземы.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
После получения выходных данных виземы с помощью этих событий можно создавать анимации персонажей. Вы можете создавать собственных персонажей и автоматически анимировать их.