Общие сведения о индексировании в Azure Cosmos DB
Область применения: ![]() Nosql
Nosql ![]() Mongodb
Mongodb ![]() Кассандра
Кассандра ![]() Гремлин
Гремлин ![]() Таблица
Таблица
Azure Cosmos DB — это база данных без использования схем, которая позволяет выполнять итерацию приложения, не отвлекаясь на управление схемами или индексами. По умолчанию Azure Cosmos DB автоматически индексирует каждое свойство всех элементов в контейнере. Разработчикам не нужно определять схемы или настраивать вторичные индексы.
В статье описан способы индексирования данных в Azure Cosmos DB и использования индексов для повышения производительности запросов. Перед изучением настройки политик индексирования рекомендуется ознакомиться с этим разделом.
От элементов к деревьям
Каждый раз, когда элемент сохраняется в контейнере, его содержимое проецируется как документ JSON, а затем преобразуется в представление в виде дерева. Это преобразование означает, что каждое свойство этого элемента представляется как узел в дереве. Псевдоузел корня создается как родительский элемент для всех свойств элемента первого уровня. Листовые узлы содержат фактические скалярные значения, перенесенные элементом.
Рассмотрим этот элемент в качестве примера:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Это дерево представляет пример элемента JSON:
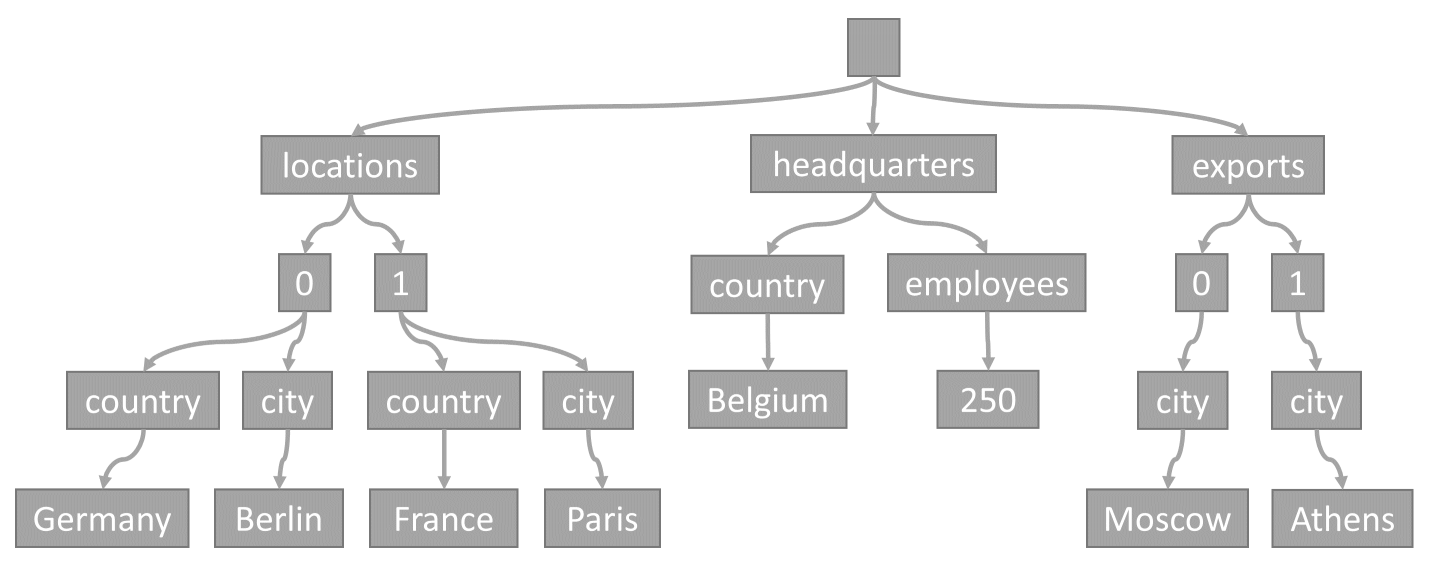
Обратите внимание, как массивы кодируются в дереве: каждая запись в массиве получает промежуточный узел с меткой индекса этой записи в массиве (0, 1 и т. д.).
От деревьев к путям к свойствам
Причина, по которой Azure Cosmos DB преобразует элементы в деревья, заключается в том, что система позволяет системе ссылаться на свойства с помощью путей в этих деревьях. Чтобы получить путь к свойству, мы можем перемещаться по дереву с корневого узла к этому свойстве и объединять метки каждого пройденного узла.
Ниже приведены пути для каждого свойства из примера элемента, описанного ранее:
/locations/0/country: "Германия"/locations/0/city: "Берлин"/locations/1/country: "Франция"/locations/1/city: "Париж"/headquarters/country: "Бельгия"/headquarters/employees: 250/exports/0/city: "Москва"/exports/1/city: "Афины"
Azure Cosmos DB эффективно индексирует путь каждого свойства и соответствующее значение при записи элемента.
Типы индексов
В настоящее время Azure Cosmos DB поддерживает три типа индексов. Такие типы индексов можно настроить при определении политики индексации.
Индекс диапазона
Индексы диапазона основаны на упорядоченной структуре дерева. Индексы диапазонов используются в следующих случаях:
Запросы на равенство:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")совпадение для элемента массива
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Запросы к диапазону:
SELECT * FROM container c WHERE c.property > 'value'Примечание.
(для
>,<,>=,<=,!=)Проверка наличия свойства:
SELECT * FROM c WHERE IS_DEFINED(c.property)Строковые системные функции:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")Запросы
ORDER BY:SELECT * FROM container c ORDER BY c.propertyЗапросы
JOIN:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Индексы диапазона можно использовать для скалярных значений (строка или число). Политика индексирования по умолчанию, задаваемая для только что созданных контейнеров, применяет диапазонные индексы для любых строк или чисел. Сведения о настройке индексов диапазонов см. в разделе с примерами политики диапазонной индексации.
Примечание.
Предложение ORDER BY, которое упорядочивается по одному свойству, всегда требует индекс диапазона, и если у пути, на который оно ссылается, его нет, оно завершится ошибкой. Аналогичным образом запросу ORDER BY, который упорядочивается по нескольким свойствам, всегда требуется составной индекс.
Пространственный индекс
Пространственные индексы позволяют выполнять эффективные запросы к геопространственным объектам, таким как точки, линии и многоугольники. В этих запросах используются ключевые слова ST_DISTANCE, ST_WITHIN и ST_INTERSECTS. Ниже приведены некоторые примеры, которые используют пространственные индексы:
Геопространственные запросы расстояний:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Геопространственные запросы включения:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Геопространственные запросы пересечения:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Пространственные индексы можно использовать для правильно отформатированных объектов GeoJSON. В настоящее время поддерживаются Points, LineStrings, Polygons и MultiPolygons. Сведения о настройке пространственных индексов см. в разделе с примерами политики пространственной индексации.
Составные индексы
Составные индексы повышают эффективность при выполнении операций с несколькими полями. Составные индексы используются в таких случаях:
Запросы
ORDER BYк нескольким свойствам:SELECT * FROM container c ORDER BY c.property1, c.property2Запросы с фильтром и
ORDER BY. Эти запросы могут использовать составной индекс, если свойство фильтра добавлено в предложениеORDER BY.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Запросы с фильтром для двух или более свойств, в которых по крайней мере одно свойство является фильтром проверки на равенство
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Если один предикат фильтра использует один из типов индекса, обработчик запросов оценивает это сначала перед сканированием остальной части. Например, вас есть SQL-запрос SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
Приведенный выше запрос сначала фильтрует записи со значением firstName = "Andrew", используя индекс. Затем он передает все записи firstName = Andrew через последующий конвейер для оценки предиката фильтра CONTAINS.
Вы можете ускорить запросы и избежать полного сканирования контейнеров при использовании функций, выполняющих полную проверку, например CONTAINS. Вы можете добавить дополнительные предикаты фильтров, которые используют индекс для ускорения этих запросов. Порядок предложений фильтра не важен. Модуль запросов определяет, какие предикаты являются более выборочными и выполняют запрос соответствующим образом.
Сведения о настройке составных индексов см. в разделе с примерами политики составной индексации.
Векторные индексы
Индексы векторов повышают эффективность при выполнении векторного поиска с помощью системной VectorDistance функции. Векторы поиска будут иметь значительно меньшую задержку, более высокую пропускную способность и меньше потребления единиц запросов при использовании векторного индекса.
Сведения о настройке векторных индексов см . в примерах политики индексирования векторов.
ORDER BYзапросы векторного поиска:SELECT c.name FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Проекция оценки сходства в векторных поисковых запросах:
SELECT c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Фильтры диапазона по оценке сходства.
SELECT c.name FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)Внимание
Векторные индексы должны быть определены во время создания контейнера и не могут быть изменены после создания. В будущем выпуске индексы векторов будут изменяться.
Использование индексов
Существует пять способов, с помощью которых механизм запросов может оценивать фильтры запросов, отсортированные от наиболее эффективных до наименее эффективных.
- Поиск в индексе
- Точная проверка индексов
- Расширенная проверка индекса
- Полная проверка индекса
- Полная проверка
При индексировании путей свойств обработчик запросов автоматически использует индекс как можно эффективнее. Помимо индексирования новых путей свойств, для оптимизации того, как запросы используют индекс, не нужно настраивать что-либо еще. Оплата за единицу запроса — это сочетание оплаты за единицу использования индекса и оплаты за единицу при загрузке элементов.
Ниже приведена таблица, в которую приведены различные способы использования индексов в Azure Cosmos DB:
| Тип поиска индекса | Description | Распространенные примеры | Плата за единицу использования индекса | Плата за единицу запросов от загрузки элементов из хранилища транзакций |
|---|---|---|---|---|
| Поиск в индексе | Чтение только необходимых индексированных значений и загрузка только совпадающих элементов из транзакционного хранилища данных | Фильтры равенства, IN | Константа для фильтра равенства | Увеличивается на основе числа элементов в результатах запроса |
| Точная проверка индексов | Двоичный поиск индексированных значений и загрузка только совпадающих элементов из транзакционного хранилища данных | Сравнения диапазонов (>, <, <=, или >=), StartsWith | При сравнении с поиском по индексу немного увеличивается в зависимости от количества элементов индексированных свойств | Увеличивается на основе числа элементов в результатах запроса |
| Расширенная проверка индекса | Оптимизированный поиск (но менее эффективный, чем двоичный поиск) индексированных значений и загрузка только совпадающих элементов из транзакционного хранилища данных | StartsWith (без учета регистра), StringEquals (без учета регистра) | Немного увеличивается в зависимости от количества элементов индексированных свойств | Увеличивается на основе числа элементов в результатах запроса |
| Полная проверка индекса | Чтение конкретного набора индексированных значений и загрузка только совпадающих элементов из транзакционного хранилища данных | Contains, EndsWith, RegexMatch, LIKE | Увеличивается линейно в зависимости от количества элементов индексированных свойств | Увеличивается на основе числа элементов в результатах запроса |
| Полная проверка | Загрузка всех элементов из хранилища транзакционных данных | Upper, Lower | Н/П | Увеличивается на основе числа элементов в контейнере |
При написании запросов следует использовать предикаты фильтров, которые используют индекс максимально эффективно. Например, если для вашего варианта использования используется любой StartsWith или Contains другой вариант, следует выбрать StartsWith , так как он выполняет точное сканирование индекса вместо полного сканирования индекса.
Данные об использовании индекса
В этом разделе описано, как запросы используют индексы. Этот уровень детализации не требуется для изучения начала работы с Azure Cosmos DB, но подробно описан для любопытных пользователей. Мы ссылаемся на пример элемента, доступного ранее в этом документе:
Элементы для примера.
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB использует инвертированный индекс. Индекс работает путем сопоставления каждого пути JSON с набором элементов, содержащих это значение. Сопоставление идентификаторов элементов представлено на множестве разных страниц индекса для контейнера. Ниже приведен пример схемы инвертированного индекса для контейнера, включающего два примера элементов:
| Путь | Значение | Список идентификаторов элементов |
|---|---|---|
| /locations/0/country | Германия | 1 |
| /locations/0/country | Ирландия | 2 |
| /locations/0/city | Берлин | 1 |
| /locations/0/city | Дублин | 2 |
| /locations/1/country | Франция | 1 |
| /locations/1/city | Париж | 1 |
| /headquarters/country | Бельгия | 1, 2 |
| /headquarters/employees | 200 | 2 |
| /headquarters/employees | 250 | 1 |
Инвертированный индекс имеет два важных атрибута.
- Для данного пути значения сортируются в возрастающем порядке. Таким образом, обработчик запросов может легко обслуживать
ORDER BYиндекса. - Для конкретного пути обработчик запросов может проверить по отдельному набору возможных значений, чтобы определить страницы индекса, на которых имеются результаты.
Обработчик запросов может использовать инвертированный индекс четырьмя разными способами.
Поиск в индексе
Обратите внимание на следующий запрос:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'`
Предикат запроса (фильтрация по элементам, где любое расположение имеет "Франция" в качестве страны или региона) будет соответствовать пути, выделенному на этой схеме:
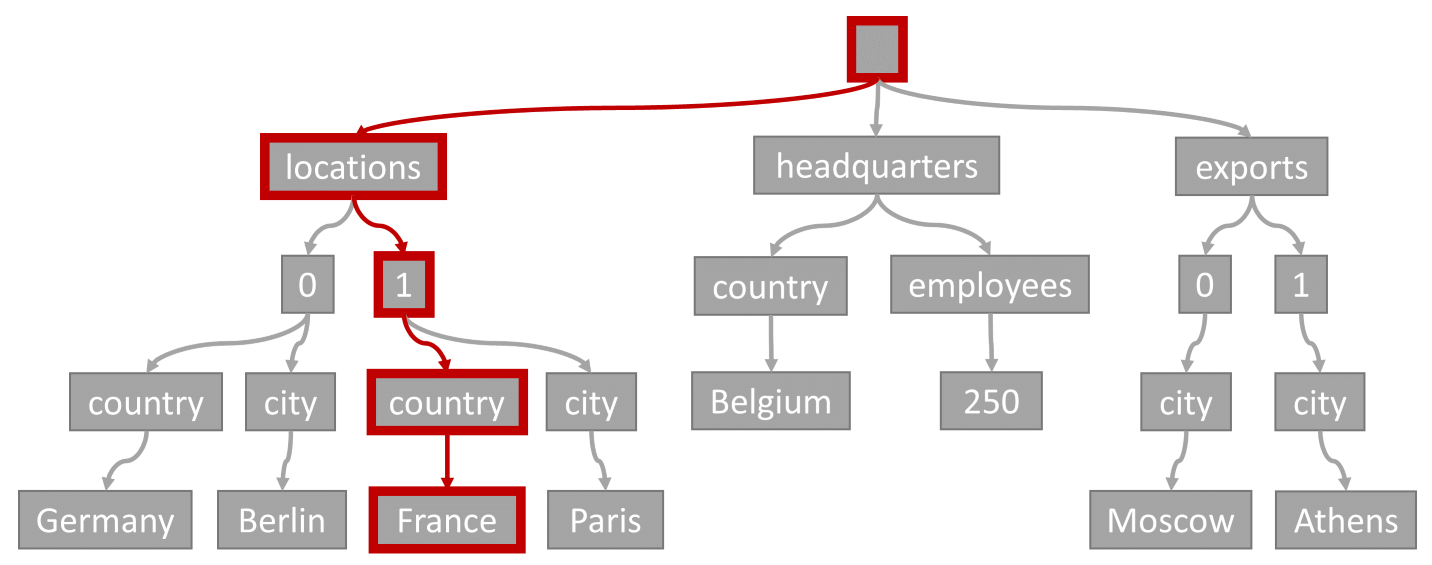
Поскольку этот запрос имеет фильтр равенства, после обхода этого дерева можно быстро определить страницы индекса, содержащие результаты запроса. В этом случае обработчик запросов будет считывать страницы индекса, содержащие элемент 1. Поиск по индексу является наиболее эффективным способом использования индекса. При поиске индекса мы считываем только необходимые страницы индекса и загружаем только элементы в результатах запроса. Таким образом, время уточняющего запроса индекса и единица оплаты единицы поиска по индексу чрезвычайно низкие, независимо от общего объема данных.
Точная проверка индексов
Обратите внимание на следующий запрос:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Предикат запроса (фильтрация по элементам, в которых имеется более 200 сотрудников) можно оценить с помощью точного просмотра индекса пути headquarters/employees. При выполнении точной проверки индекса обработчик запросов начинает с двоичного поиска по отдельному набору возможных значений, чтобы найти расположение значения 200 для пути headquarters/employees. Так как значения для каждого пути сортируются в возрастающем порядке, обработчику запросов достаточно выполнить двоичный поиск. После того как обработчик запросов обнаружит значение 200, он начнет считывать все оставшиеся страницы индекса (в направлении возрастания).
Так как обработчик запросов может выполнять двоичный поиск, чтобы избежать сканирования ненужных страниц индекса, точная проверка индекса, как правило, обеспечивает сравнимую задержку и оплату в единицах запроса за операции поиска по индексу.
Расширенная проверка индекса
Обратите внимание на следующий запрос:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Предикат запроса (фильтрация по элементам, в которых находится штаб-квартира в расположении, которое начинается с нечувствительного регистра "United") можно оценить с развернутым сканированием headquarters/country индекса пути. Операции, которые выполняют расширенное сканирование индекса, имеют оптимизацию, которая помогает избежать необходимости сканировать каждую страницу индекса, но немного дороже, чем двоичный поиск, осуществляемый при точном поиске по индексу.
Например, при оценке без StartsWithучета регистра подсистема запросов проверяет индекс на наличие различных возможных сочетаний значений верхнего и нижнего регистра. Эта оптимизация позволяет обработчику запросов избежать чтения большинства страниц индексов. Различные системные функции имеют различные оптимизации, которые они могут использовать, чтобы избежать чтения каждой страницы индекса, поэтому они широко классифицируются как расширенная проверка индекса.
Полная проверка индекса
Обратите внимание на следующий запрос:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Предикат запроса (фильтрация по элементам с штаб-квартирой в расположении, в котором содержится "United") можно оценить с помощью сканирования headquarters/country индекса пути. В отличие от точного сканирования индекса, полная проверка индекса всегда проверяется с помощью определенного набора возможных значений, чтобы определить страницы индекса, в которых есть результаты. В этом случае Contains выполняется в индексе. Время поиска по индексу и цена за единицу для сканирования индекса увеличивается по мере увеличения количества элементов пути. Иными словами, чем больше возможных уникальных значений, которые механизму запросов необходимо сканировать, тем выше время задержки и оплата в единицах запроса, участвующие в выполнении полного сканирования индекса.
Например, рассмотрим два свойства: town и country. Кратность города составляет 5000, а кратность country составляет 200. Ниже приведены два примера запросов, каждая из которых содержит системную функцию Contains, которая выполняет полное сканирование индекса для свойства town. Первый запрос использует больше единиц запросов, чем второй запрос, так как кратность города выше country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Полная проверка
В некоторых случаях обработчик запросов может не вычислить фильтр запроса с помощью индекса. В этом случае обработчик запросов должен загрузить все элементы из хранилища транзакций, чтобы оценить фильтр запроса. Полные проверки не используют индекс и имеют плату за единицу запросов, которая увеличивается линейно с общим размером данных. К счастью, операции, требующие полной проверки, являются редкими.
Векторные поисковые запросы без определенного векторного индекса
Если вы не определяете политику векторного индекса и используете VectorDistance системную функцию в ORDER BY предложении, это приведет к полному сканированию и взимается плата за единицу запроса выше, чем если вы определили политику векторного индекса. Сходство, если вы используете VectorDistance с логическим набором логических значений trueметодом подбора и не имеет flat индекса, определенного для пути вектора, будет выполняться полная проверка.
Запросы со сложными выражениями фильтра
В предыдущих примерах мы рассматривали только запросы с простыми выражениями фильтра (например, запросы только с одним фильтром равенства или диапазоном). В реальности большинство запросов имеют гораздо более сложные критерии фильтра.
Обратите внимание на следующий запрос:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Для выполнения этого запроса обработчик запросов должен выполнить поиск по индексу для headquarters/employees и полный просмотр индекса для headquarters/country. Обработчик запросов имеет внутренние эвристики, используемые для вычисления выражения фильтра запросов как можно быстрее. В этом случае механизму запросов не нужно считывать ненужные страницы индекса, сначала выполнив поиск по индексу. Например, только 50 элементов соответствовали фильтру равенства, обработчик запросов должен будет оценить Contains только на страницах индекса, содержащих эти 50 элементов. Полное сканирование индекса всего контейнера не потребуется.
Использование индексов для скалярных агрегатных функций
Запросы с агрегатными функциями должны зависеть только от индекса, чтобы его можно было использовать.
В некоторых случаях индекс может возвращать ложные положительные результаты. Например, при вычислении Contains на индексе количество совпадений в индексе может превышать число результатов запроса. Обработчик запросов загружает все совпадения индекса, вычисляет фильтр для загруженных элементов и возвращает только правильные результаты.
Для большинства запросов загрузка совпадений с ложным положительным индексом не оказывает заметного влияния на использование индекса.
Например, рассмотрим следующий запрос:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Системная Contains функция может возвращать некоторые ложные положительные совпадения, поэтому обработчик запросов должен проверить, соответствует ли каждый загруженный элемент выражению фильтра. В этом примере подсистеме запросов может потребоваться только загрузка дополнительных элементов, поэтому влияние на использование индекса и плата за единицу запросов минимальна.
Однако запросы с агрегатными функциями должны зависеть только от индекса, чтобы его можно было использовать. Например, рассмотрим следующий запрос с агрегатной функцией Count.
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Как и в первом примере, системная функция Contains может вернуть несколько ложных положительных совпадений. Однако в отличие от запроса SELECT *, запрос Count не может вычислить критерий фильтра загруженных элементов для проверки всех совпадений индекса. Запрос Count должен полагаться исключительно на индекс, поэтому если есть вероятность, что выражение фильтра возвращает ложные положительные совпадения, обработчик запросов применяется к полному сканированию.
Запросы со следующими агрегатными функциями должны зависеть только от индекса, поэтому для оценки некоторых системных функций требуется полная проверка.
Следующие шаги
Дополнительные сведения об индексировании вы найдете в следующих статьях.
Кері байланыс
Жақында қолжетімді болады: 2024 жыл бойы біз GitHub Issues жүйесін мазмұнға арналған кері байланыс механизмі ретінде біртіндеп қолданыстан шығарамыз және оны жаңа кері байланыс жүйесімен ауыстырамыз. Қосымша ақпаратты мұнда қараңыз: https://aka.ms/ContentUserFeedback.
Жіберу және пікірді көру