Конвейеры и действия в Фабрике данных Azure и Azure Synapse Analytics
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Внимание
Поддержка Машинное обучение Azure Studio (классическая) завершится 31 августа 2024 г. Мы рекомендуем перейти на Машинное обучение Azure по этой дате.
По состоянию на 1 декабря 2021 г. нельзя создавать новые ресурсы Машинное обучение Studio (классический) (рабочая область и план веб-службы). До 31 августа 2024 г. вы можете продолжать использовать существующие эксперименты Машинное обучение Studio (классические) и веб-службы. Дополнительные сведения см. в разделе:
- Миграция на Машинное обучение Azure из студии Машинное обучение (классическая версия)
- Что такое Машинное обучение Azure?
Машинное обучение Studio (классическая) документация не обновляется и может не обновляться в будущем.
В этой статье вы ознакомитесь с принципом работы конвейеров и действий в Фабрике данных Azure и Azure Synapse Analytics и узнаете, как с их помощью создавать комплексные рабочие процессы, управляемые данными, для сценариев перемещения и обработки данных.
Обзор
Рабочая область Фабрики данных или Synapse может содержать один или несколько конвейеров. Конвейеры — это логические группы действий, которые вместе отвечают за выполнение задачи. Например, конвейер может содержать набор действий, вставляющих и очищающих данные журнала, а затем запускающий поток данных сопоставления для анализа данных журнала. Конвейер позволяет управлять действиями в наборе, а не каждым из них в отдельности. Вы развертываете и планируете конвейер, а не действия отдельно.
Действия в конвейере определяют действия, выполняемые с данными. Например, вы можете использовать действие копирования, чтобы скопировать данные из SQL Server в хранилище BLOB-объектов Azure. Затем с помощью действия потока данных или записной книжки Databricks вы можете обработать данные из хранилища BLOB-объектов и преобразовать их в пул Azure Synapse Analytics, на основе которого разрабатываются решения для создания отчетов с бизнес-аналитикой.
Фабрика данных Azure и Azure Synapse Analytics содержат три группы действий: действия перемещения данных, действия преобразования данных и действия управления. У каждого действия может быть несколько входных наборов данных или же ни одного, и каждое действие может производить один или несколько выходных наборов данных. На следующей схеме показана связь между конвейером, действием и набором данных:

Входной набор данных представляет входные данные для действия в конвейере, а выходной набор данных — выходные данные для действия. Наборы данных представляют данные в разных хранилищах, например в таблицах, файлах, папках и документах. Созданные наборы данных можно использовать для действий в конвейере. Например, можно указать входной или выходной набор данных для действия HDInsightHive или действия копирования. Дополнительные сведения о наборах данных см. в статье Наборы данных в фабрике данных Azure.
Примечание.
По умолчанию используется обратимое ограничение не более 80 действий на конвейер, включающее внутренние действия для контейнеров.
Действия перемещения данных
Действие копирования в Фабрике данных копирует данные из хранилища-источника в хранилище-приемник. Фабрика данных поддерживает хранилища данных, перечисленные в таблице в этом разделе. Данные из любого источника можно записывать в любой приемник.
Дополнительные сведения см. в статье Действие копирования в фабрике данных Azure.
Щелкните название хранилища, чтобы узнать, как скопировать данные из него или в него.
Примечание.
Пометка предварительная версия возле соединителя означает, что с ним можно поработать и оставить отзыв. Если вы хотите использовать в своем решении зависимость от соединителей в предварительной версии, обратитесь в службу поддержки Azure.
Действия преобразования данных
Фабрика данных Azure и Azure Synapse Analytics поддерживают указанные ниже действия преобразования, которые вы можете добавлять в конвейеры как по отдельности, так и в связи с другим действием.
Дополнительные сведения см. в статье Преобразование данных в фабрике данных Azure.
| Действия по преобразованию данных | Вычислительная среда |
|---|---|
| Поток данных | Кластеры Apache Spark под управлением Фабрики данных Azure |
| Функция Azure | Функции Azure |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Потоковая передача Hadoop | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Действия Студии машинного обучения Azure (классическая версия): пакетное выполнение и обновление ресурса | Azure |
| Хранимая процедура | Azure SQL, Azure Synapse Analytics или SQL Server |
| U-SQL | Аналитика озера данных Azure |
| Настраиваемое действие | Пакетная служба Azure |
| Databricks Notebook | Azure Databricks |
| Действие JAR в Databricks | Azure Databricks |
| Действие Python в Databricks | Azure Databricks |
| Действие Записной книжки Synapse | Azure Synapse Analytics |
Действия в потоке управления
Поддерживаются следующие действия потока управления:
| Действие управления | Description |
|---|---|
| Добавление переменной | Добавление значения к имеющейся переменной типа “массив”. |
| Выполнение конвейера | Действие Execute Pipeline позволяет конвейеру Фабрики данных или Synapse вызвать другой конвейер. |
| Фильтр | Применение выражения фильтра ко входному массиву |
| Для каждого | Действие ForEach определяет повторяющийся поток управления в конвейере. Это действие используется для выполнения итерации коллекции и выполняет указанные в цикле действия. Реализация цикла этого действия аналогична структуре цикла Foreach на языках программирования. |
| Получение метаданных | Действие GetMetadata можно использовать для получения метаданных для любых данных в конвейере Фабрики данных Azure или Synapse. |
| Действие условия If | Это действие можно использовать для создания ветви на основе условия, результатом расчета которого является значение True или False. Действие условия If предоставляет те же функциональные возможности, что и инструкция if в языках программирования. Оно определяет один набор действий, если условие принимает значение true, и другой набор действий, если условие принимает значение false.. |
| Действие поиска | Действие поиска можно использовать для считывания или поиска записи, имени таблицы и значения из внешних источников. На эти выходные данные можно затем ссылаться в последующих действиях. |
| Установка значения переменной | Установка значения существующей переменной. |
| Действие Until | Реализует цикл Do Until, который аналогичен циклической структуре Do-Until в языках программирования. Оно выполняет набор действий в цикле, пока условие, связанное с действием, не получит значение true. Можно указать значение времени ожидания для действия until. |
| Действие проверки | Гарантирует, что выполнение конвейера продолжается только при наличии эталонного набора данных, отвечающего заданным условиям, или по истечении времени ожидания. |
| Действие ожидания | Если в конвейере используется действие Wait, он приостанавливает обработку на указанное время, прежде чем перейти к выполнению последующих действий. |
| Веб-действие | Веб-действие можно использовать для вызова из конвейера пользовательской конечной точки REST. Вы можете передать наборы данных и связанные службы, которые будет использовать это действие и к которым оно будет обращаться. |
| Действие веб-перехватчика | С помощью действия веб-перехватчика можно вызвать конечную точку и передать URL-адрес обратного вызова. Выполнение конвейера дожидается обратного вызова, после чего переходит к следующему действию. |
Создание конвейера с помощью пользовательского интерфейса
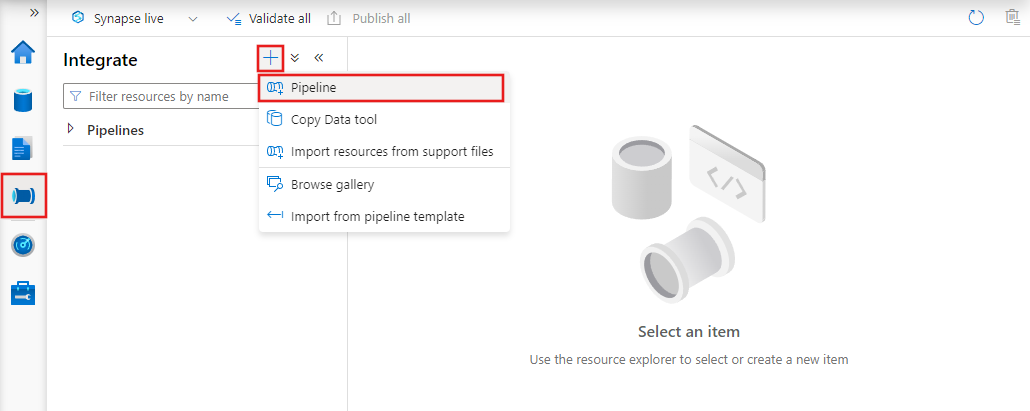
Чтобы создать конвейер, перейдите на вкладку "Author" (Создание) в Data Factory Studio (со значком карандаша), затем щелкните знак "плюс" и в меню выберите "Pipeline" (Конвейер), а затем снова выберите "Pipeline" (Конвейер) в подменю.
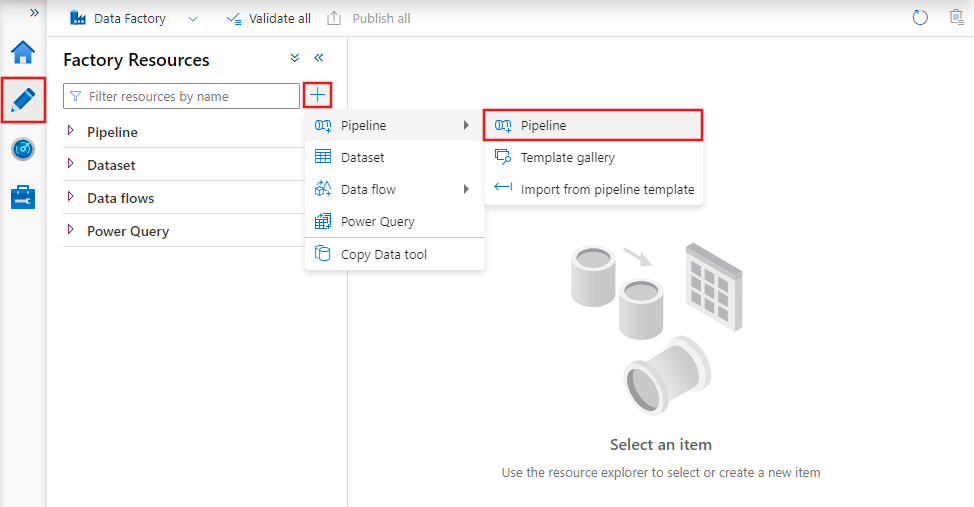
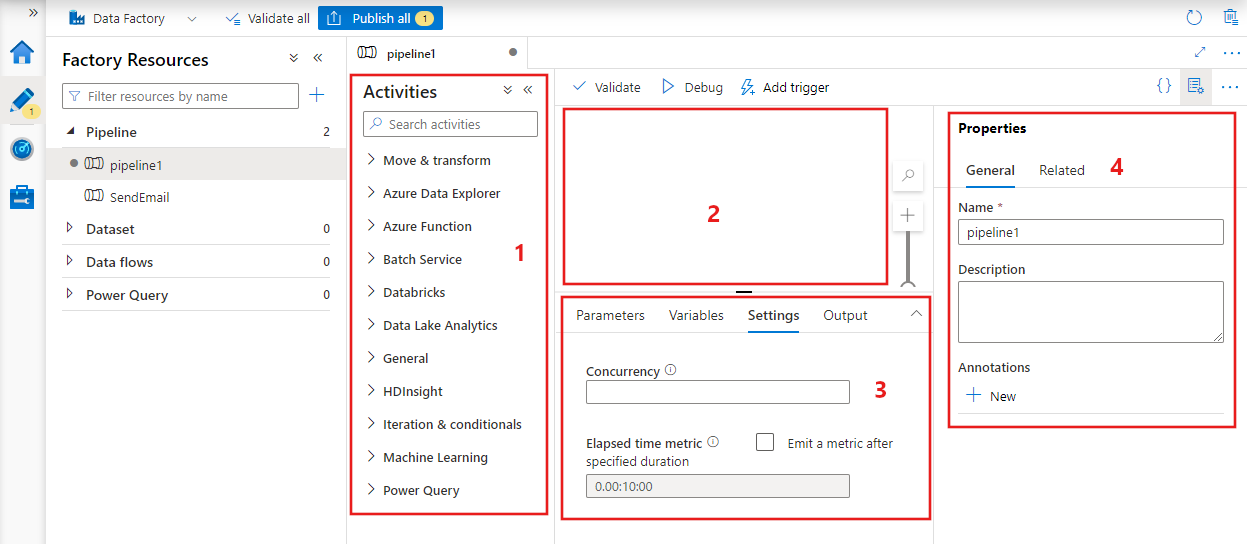
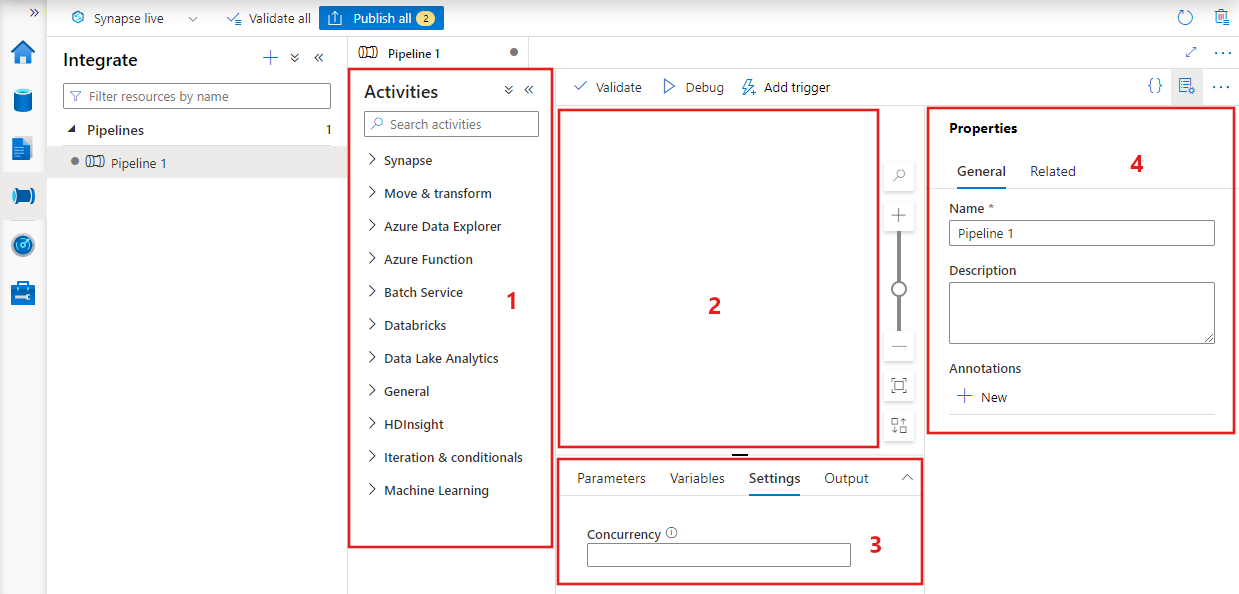
В Фабрике данных отобразится редактор конвейеров, в котором доступно следующее:
- все действия, которые могут использоваться в конвейере;
- холст редактора конвейеров, где будут отображаться добавленные в конвейер действия;
- область настройки конвейера, включая параметры, переменные, общие параметры и выходные данные;
- область свойств конвейера, где можно настроить имя конвейера, необязательное описание и заметки. В этой области также будут показаны связанные с конвейером элементы в фабрике данных.
JSON-файл конвейера.
Вот, как конвейер определяется в формате JSON:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Тег | Описание | Тип | Обязательное поле |
|---|---|---|---|
| name | Имя конвейера. Укажите имя, представляющее действие, которое выполняет конвейер.
|
Строка | Да |
| описание | Укажите текст, описывающий, для чего используется конвейер. | Строка | Нет |
| activities | В разделе activities можно определить одно или несколько действий. Дополнительные сведения об элементе JSON действий см. в разделе JSON действия. | Массив | Да |
| parameters | В разделе Параметры может быть задан один или несколько параметров, определенных в конвейере, которые делают конвейер гибким для повторного использования. | List | No |
| параллелизм | Максимальное количество одновременных выполнений данного конвейера. По умолчанию верхний предел не установлен. При достижении предела параллелизма дополнительные выполнения конвейера ставятся в очередь, где дожидаются завершения запущенных ранее операций. | Число | No |
| annotations | Список тегов, связанных с конвейером | Массив | No |
Действие JSON
В разделе activities можно определить одно или несколько действий. Существует два основных типа действий: действия выполнения и действия управления.
Действия выполнения
Действия выполнения включают в себя действия перемещения данных и преобразования данных. Они имеют следующую структуру верхнего уровня:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
В приведенной ниже таблице описаны свойства, используемые в определениях JSON действия:
| Тег | Description | Обязательное поле |
|---|---|---|
| name | Имя действия . Укажите имя, представляющее операцию, которую выполняет действие.
|
Да |
| описание | Текст, описывающий, для чего используется действие | Да |
| type | Тип действия. Разные типы действий описаны в разделах, посвященных действиям перемещения данных, действиям преобразования данных и действиям управления. | Да |
| linkedServiceName | Имя связанной службы, используемой действием. Для действия может потребоваться указать связанную службу, которая связывается с требуемой вычислительной средой. |
Обязательно для действия HDInsight, действия пакетной оценки в Студии машинного обучения (классической) и действия хранимой процедуры. Нет — для всех остальных |
| typeProperties | Свойства в разделе typeProperties зависят от каждого типа действия. Чтобы просмотреть свойства типа для действия, щелкните ссылки на действие в предыдущем разделе. | No |
| policy | Политики, которые влияют на поведение во время выполнения действия. Это свойство включает время ожидания и логику повторных попыток. Если оно не указано, используются значения по умолчанию. Дополнительные сведения см. в разделе Политика действий. | No |
| Свойство dependsOn | Это свойство используется для определения зависимостей между последующими и предыдущими действиями. Дополнительные сведения см. в разделе Зависимости действий. | No |
Политика действий
Политики влияют на поведение действия во время его выполнения, предоставляя возможность настройки параметров. Они доступны только для действий выполнения.
Activity policy JSON definition (Определение JSON политики действия)
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| Имя JSON | Description | Допустимые значения | Обязательное поле |
|---|---|---|---|
| timeout | Указывает время ожидания для выполнения действия. | Временной диапазон | № Время ожидания по умолчанию — 12 часов, минимум 10 минут. |
| повтор | Максимальное количество повторных попыток | Целое | № Значение по умолчанию — 0. |
| retryIntervalInSeconds | Задержка между повторными попытками (в секундах) | Целое | № Значение по умолчанию: 30 секунд |
| secureOutput | Если задано значение true, выходные данные действия будут рассматриваться как безопасные. Они не будут регистрироваться для мониторинга. | Логический | № По умолчанию — false. |
Действие управления
Действие управления имеет следующую структуру верхнего уровня:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Тег | Description | Обязательное поле |
|---|---|---|
| name | Имя действия . Укажите имя, представляющее операцию, которую выполняет действие.
|
Да |
| описание | Текст, описывающий, для чего используется действие | Да |
| type | Тип действия. Разные типы действий описаны в разделах, посвященных действиям перемещения данных, действиям преобразования данных и действиям управления. | Да |
| typeProperties | Свойства в разделе typeProperties зависят от каждого типа действия. Чтобы просмотреть свойства типа для действия, щелкните ссылки на действие в предыдущем разделе. | No |
| Свойство dependsOn | Это свойство используется для определения зависимостей между последующими и предыдущими действиями. Дополнительные сведения см. в разделе Зависимости действий. | No |
Зависимость действий
Зависимость действий определяет, как последующие действия зависят от предыдущих, указывая, следует ли продолжать выполнение следующей задачи. Действие может зависеть от одного или нескольких предыдущих действий с разными условиями зависимости.
Различные условия зависимости: "Выполнено", "Сбой", "Пропущено", "Завершено".
Например, если в конвейере есть действие A -> действие B, возможны различные сценарии:
- Действие B имеет условие зависимости от действия А с условием Выполнено: действие B выполняется, только если действие А имеет конечное состояние "Выполнено".
- Действие B имеет условие зависимости от действия А с условием Сбой: действие B выполняется, только если действие А имеет конечное состояние "Сбой".
- Действие Б имеет условие зависимости от действия А с условием Завершено: действие B выполняется, если действие А имеет конечное состояние "Выполнено" или "Сбой".
- Для действия Б задано условие зависимости от действия А с условием Пропущено: действие B выполняется, если действие А находится в окончательном состоянии "Пропущено". Конечное состояние "Пропущено" происходит в таком сценарии: действие X -> действие Y -> действие Z, где каждое действие выполняется, только если предыдущее действие завершается успешно. При сбое действия X действие Y остается в состоянии "Пропущено", так как оно никогда не выполнится. Аналогично, действие Z находится в состоянии "Пропущено".
Пример. Действие 2 зависит от успешного завершения действия 1
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Пример конвейера копирования
В следующем примере конвейера содержится одно действие типа Copy in the действий . В этом примере действие копирования копирует данные из Хранилища BLOB-объектов Azure в Базу данных SQL Azure.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Обратите внимание на следующие аспекты:
- В разделе действий доступно только одно действие, параметр type которого имеет значение Copy.
- Для этого действия параметру input присвоено значение InputDataset, а параметру output — значение OutputDataset. Сведения об определении наборов данных в JSON см. в статье Наборы данных.
- В разделе typeProperties в качестве типа источника указано BlobSource, а в качестве типа приемника — SqlSink. В разделе Действия перемещения данных щелкните хранилище данных, которое хотите использовать как источник или приемник, чтобы подробнее узнать о перемещении данных из этого хранилища или в него.
Полное пошаговое руководство по созданию этого конвейера см. в статье Краткое руководство. Создание фабрики данных Azure с помощью PowerShell.
Пример конвейера преобразования
В следующем примере конвейера содержится одно действие типа HDInsightHive in the действий . В этом примере действие HDInsight Hive преобразовывает данные из хранилища BLOB-объектов Azure, запуская файл сценария Hive в кластере Azure HDInsight Hadoop.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Обратите внимание на следующие аспекты:
- В разделе activities есть только одно действие, параметр type которого имеет значение HDInsightHive.
- Файл сценария Hive, partitionweblogs.hql, хранится в учетной записи хранения Azure (указывается с помощью свойства scriptLinkedService, имеющего значение AzureStorageLinkedService) в папке script в контейнере
adfgetstarted. - Раздел
definesиспользуется, чтобы указать параметры среды выполнения, передаваемые скрипту Hive в качестве значений конфигурации Hive (например,{hiveconf:inputtable}, $${hiveconf:partitionedtable}).
Разделы typeProperties для каждого действия преобразования отличаются. Для получения дополнительных сведений о свойствах типа, поддерживаемых для действия преобразования, щелкните такое действие в таблице Действия по преобразованию данных.
Полное пошаговое руководство по созданию этого конвейера см. в статье Преобразование данных в облаке с помощью действия Spark в фабрике данных Azure.
Несколько действий в конвейере
В двух предыдущих примерах конвейеров присутствует только одно действие. Конвейер может содержать сразу несколько действий. Если в конвейере есть несколько действий, а последующие действия не зависят от предыдущих действий, действия могут выполняться параллельно.
Два действия можно соединить с помощью зависимости действий, определяющей зависимость последующих действий от предыдущих, а также то, следует ли продолжать выполнение следующей задачи. Действие может зависеть от одного или нескольких предыдущих действий с разными условиями зависимости.
Планирование конвейеров
Конвейеры планируются триггерами. Есть различные типы триггеров, например триггер планировщика, позволяющий запускать конвейеры по расписанию, а также ручной триггер, который запускает конвейеры по требованию. Дополнительные сведения см. в статье Pipeline execution and triggers in Azure Data Factory (Выполнение конвейера и триггеры в фабрике данных Azure).
Чтобы триггер выполнял конвейер, включите в определении триггера ссылку на нужный конвейер. Конвейеры и триггеры имеют связь n-m. Один триггер может запускать несколько конвейеров, и несколько триггеров могут запускать один конвейер. После определения триггера необходимо активировать его, чтобы он начал запуск конвейера. Дополнительные сведения см. в статье Pipeline execution and triggers in Azure Data Factory (Выполнение конвейера и триггеры в фабрике данных Azure).
Предположим, что у вас есть триггер по расписанию (триггер A), который должен запускать конвейер MyCopyPipeline. Этот триггер определяется, как показано в следующем примере:
Определение триггера А
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}