Руководство по производительности и масштабируемости действия копирования
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Иногда необходимо выполнить крупномасштабную миграцию данных из озера или корпоративного хранилища данных (EDW) в Azure. В других случаях требуется принимать большие объемы данных из разных источников в Azure для анализа больших данных. В каждом случае крайне важно обеспечить оптимальную производительность и масштабируемость.
Конвейеры Фабрики данных Azure и Azure Synapse Analytics предоставляют механизм приема данных со следующими преимуществами:
- Обработка больших объемов данных
- Высокая производительность
- Экономия
Эти преимущества идеально подходят для специалистов по работе с данными, желающих создавать масштабируемые конвейеры приема данных с высокой производительностью.
После прочтения этой статьи вы сможете ответить на следующие вопросы:
- Какого уровня производительности и масштабируемости можно достичь с помощью действия копирования для переноса данных и сценариев приема данных?
- Какие действия следует предпринять для настройки производительности действия копирования?
- Какие оптимизации производительности можно использовать при выполнении одного действия копирования?
- Какие еще внешние факторы следует учитывать при оптимизации производительности копирования?
Примечание.
Если вы не знакомы с действием копирования в целом, прочтите обзор действия копирования, прежде чем продолжить работу с этой статьей.
Производительность и масштабируемость копирования, достижимая с помощью конвейеров Фабрики данных Azure и Synapse
Конвейеры Фабрики данных Azure и Synapse предлагают бессерверную архитектуру, обеспечивающую параллелизм на различных уровнях.
Эта архитектура позволяет разрабатывать конвейеры, которые обеспечивают максимальную пропускную способность перемещения данных для вашей среды. Эти конвейеры полностью используют следующие ресурсы.
- Пропускная способность сети между исходным и целевым хранилищами данных.
- Операции ввода-вывода в секунду и пропускная способность исходного и целевого хранилищ данных.
Благодаря такому полноценному использованию вы можете оценить общую пропускную способность, измеряя минимальную пропускную способность, доступную для следующих ресурсов.
- Исходное хранилище данных
- Целевое хранилище данных
- Пропускная способность сети между исходным и целевым хранилищами данных
В таблице ниже показан расчет продолжительности перемещения данных. Продолжительность в каждой ячейке вычисляется на основе заданной пропускной способности сети и хранилища данных и заданного размера полезных данных.
Примечание.
Приведенная ниже продолжительность показывает достижимую производительность в комплексном решении по интеграции данных. Подразумевается использование одного метода оптимизации производительности или нескольких, описанных в статье Возможности оптимизации производительности при копировании, включая использование ForEach для секционирования и создание нескольких одновременных операций копирования. Мы рекомендуем выполнить шаги по настройке производительности, чтобы оптимизировать производительность копирования для конкретного набора данных и конфигурации системы. Следует использовать числа, полученные в тестах производительности при планировании развертывания, ресурсов и расходов для рабочей среды.
| Размер данных / bandwidth |
50 Мбит/с | 100 Мбит/с | 500 Мбит/с | 1 Гбит/с | 5 Гбит/с | 10 Гбит/с | 50 Гбит/с |
|---|---|---|---|---|---|---|---|
| 1 ГБ | 2,7 мин | 1,4 мин | 0,3 мин | 0,1 мин | 0,03 мин | 0,01 мин | 0,0 мин |
| 10 ГБ | 27,3 мин | 13,7 мин | 2,7 мин | 1,3 мин | 0,3 мин | 0,1 мин | 0,03 мин |
| 100 ГБ | 4,6 ч | 2,3 ч | 0,5 ч | 0,2 ч | 0,05 ч | 0,02 ч | 0,0 ч |
| 1 ТБ | 46,6 ч | 23,3 ч | 4,7 ч | 2,3 ч | 0,5 ч | 0,2 ч | 0,05 ч |
| 10 ТБ | 19,4 дн. | 9,7 дн. | 1,9 дн. | 0,9 дн. | 0,2 дн. | 0,1 дн. | 0,02 дн. |
| 100 ТБ | 194,2 дн. | 97,1 дн. | 19,4 дн. | 9,7 дн. | 1,9 дн. | 1 день | 0,2 дн. |
| 1 PB | 64,7 мес. | 32,4 мес. | 6,5 мес. | 3,2 мес. | 0,6 мес. | 0,3 мес. | 0,06 мес. |
| 10 ПБ | 647,3 мес. | 323,6 мес. | 64,7 мес. | 31,6 мес. | 6,5 мес. | 3,2 мес. | 0,6 мес. |
Копия масштабируется на разных уровнях:
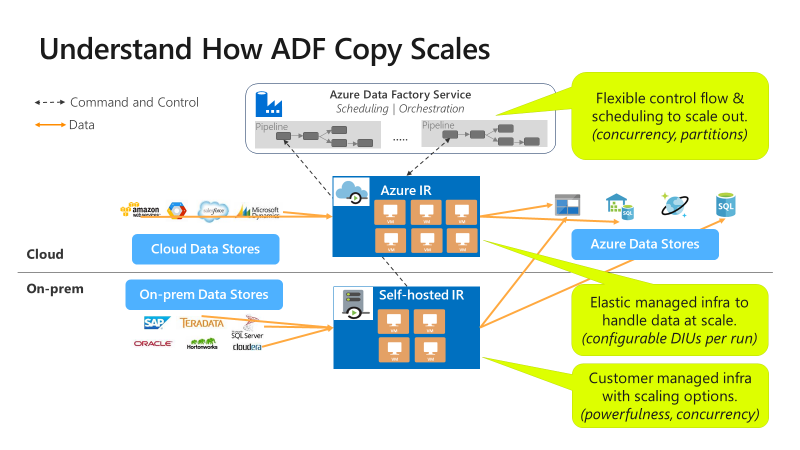
Поток управления может запускать несколько операций копирования параллельно, например с помощью цикла ForEach.
Одно действие копирования может использовать масштабируемые вычислительные ресурсы.
- При использовании среды выполнения интеграции Azure (IR) можно указать до 256 единиц интеграции данных (DIU) для каждого действия копирования в рамках бессерверных вычислений.
- При использовании локальной среды IR можно использовать любой из следующих подходов:
- Вручную увеличить масштаб компьютера.
- Горизонтально увеличить масштаб на несколько компьютеров (до 4 узлов), при этом одно действие копирования будет секционировать набор файлов по всем узлам.
Одно действие копирования считывает данные из хранилища данных и записывает их в него с помощью нескольких потоков параллельно.
Этапы настройки производительности
Выполните следующие действия, чтобы настроить производительность службы с помощью действия копирования.
Выберите тестовый набор данных и установите базовые показатели.
Протестируйте конвейер на этапе разработки, выполнив действие копирования на примере репрезентативных данных. Выбранный набор данных должен соответствовать типичным шаблонам данных по следующим атрибутам.
- Структура папок
- Шаблон файлов
- Схема данных
Набор данных должен быть достаточно большим, чтобы оценить производительность копирования. Оптимальный объем данных должен быть таким, чтобы на его копирование потребовалось не менее 10 минут. Сведения о процессе выполнения и характеристики производительности см. в разделе Мониторинг действия копирования.
Как повысить производительность одного действия копирования
Рекомендуется сначала повысить производительность с помощью одного действия копирования.
Если действие копирования выполняется в среде выполнения интеграции Azure
Начните со значений по умолчанию для параметров Единицы интеграции данных (DIU) и параллельного копирования.
Если действие копирования выполняется в локальной среде выполнения интеграции
Для размещения среды выполнения интеграции рекомендуется использовать выделенный компьютер. Компьютер должен быть отделен от сервера, на котором размещено хранилище данных. Начните со значений по умолчанию для параметра параллельного копирования и используйте один узел для локальной среды IR.
Выполните тест производительности. Запишите полученный уровень производительности. Включите фактические значения, например DUI и параллельные копии. Сведения о том, как получить результаты выполнения и используемые параметры производительности, см. в статье Мониторинг действия копирования. Узнайте, как устранять проблемы с производительностью действий копирования, чтобы определить и устранить узкие места.
Проведите дополнительные тесты производительности, следуя указаниям по устранению неполадок и настройке. Как только выполнение одной операции копирования достигнет максимальной пропускной способности, рассмотрите возможность еще больше увеличить общую пропускную способность, одновременно выполняя несколько действий копирования. Этот вариант рассматривается в следующем списке.
Как максимально увеличить общую пропускную способность, выполняя несколько действий копирования одновременно
Пока вы максимально увеличили производительность одного действия копирования. Если вы еще не достигли верхних пределов пропускной способности вашей среды, вы можете запускать несколько действий копирования параллельно. Параллельное выполнение возможно с помощью конструкций потока управления. Одна из таких конструкций — цикл For Each. Дополнительные сведения о шаблонах решений вы найдете в следующих статьях:
Расширьте эту конфигурацию на весь набор данных.
Если вас устраивают результаты выполнения и производительность, можно задать это определение и конвейер для всего набора данных.
Устранение проблем с производительностью действий копирования
Выполните шаги по настройке производительности, чтобы спланировать и провести тест производительности для своего сценария. Узнайте, как устранять проблемы производительности каждого выполнения действия копирования, в разделе Устранение проблем с производительностью действий копирования.
Функции для оптимизации производительности копирования
Служба предоставляет следующие возможности оптимизации производительности.
- Единицы интеграции данных
- Масштабируемость локальной среды выполнения интеграции
- Параллельное копирование
- Промежуточное копирование
Единицы интеграции данных
Единица интеграции данных (DIU) — это мера мощности одной единицы в конвейере Фабрики данных Azure и Synapse. Мощность объединяет в себе ЦП, память и сетевые ресурсы. DIU применяется только в среде выполнения интеграции Azure. DIU не применяется в локальной среде выполнения интеграции. Дополнительные сведения см. здесь.
Масштабируемость локальной среды выполнения интеграции
Возможно, вам потребуется разместить возрастающую параллельную рабочую нагрузку или повысить производительность для текущей рабочей нагрузки. Увеличить масштаб обработки можно с помощью следующих подходов.
- Вы можете вертикально увеличить масштаб локальной среды IR, увеличив число параллельных заданий, которые могут выполняться на узле.
Увеличение вертикального масштаба работает только в том случае, если процессор и память узла используются не полностью. - Чтобы горизонтально увеличить масштаб локальной среды IR, добавьте дополнительные узлы (компьютеры).
Дополнительные сведения см. в разделе:
- Возможности оптимизации производительности действия копирования: масштабируемость локальной среды выполнения интеграции
- Создание и настройка локальной среды выполнения интеграции: рекомендации по масштабированию
Параллельное копирование
Вы можете задать свойство parallelCopies, чтобы указать желаемый параллелизм для действия копирования. Это свойство следует рассматривать как максимальное число потоков в рамках действия копирования. Потоки работают параллельно. Потоки либо считываются из исходного хранилища данных, либо записываются в целевое. Подробнее.
промежуточное копирование
Операция копирования данных может отправить данные непосредственно в целевое хранилище данных. Кроме того, вы можете использовать хранилище BLOB-объектов в качестве промежуточного хранилища. Подробнее.
Связанный контент
См. другие статьи о действии копирования: