Перенос кластера HDInsight в более новую версию
Чтобы воспользоваться преимуществами новых возможностей HDInsight, мы рекомендуем регулярно переносить кластеры HDInsight в последнюю версию. HDInsight не поддерживает обновления на месте, когда существующий кластер обновляется до более новой версии компонента. Необходимо создать новый кластер с нужной версией компонента и платформы, а затем перенести приложения для использования нового кластера. Выполните следующие инструкции, чтобы перенести версию кластера HDInsight.
Примечание.
Если вы создаете кластер Hive с основным контейнером хранилища, скопируйте его из существующего кластера HDInsight. Tt скопируйте полное содержимое. Скопируйте только папки данных, настроенные.
Задачи миграции
Рабочий процесс для обновления кластера HDInsight выглядит так.
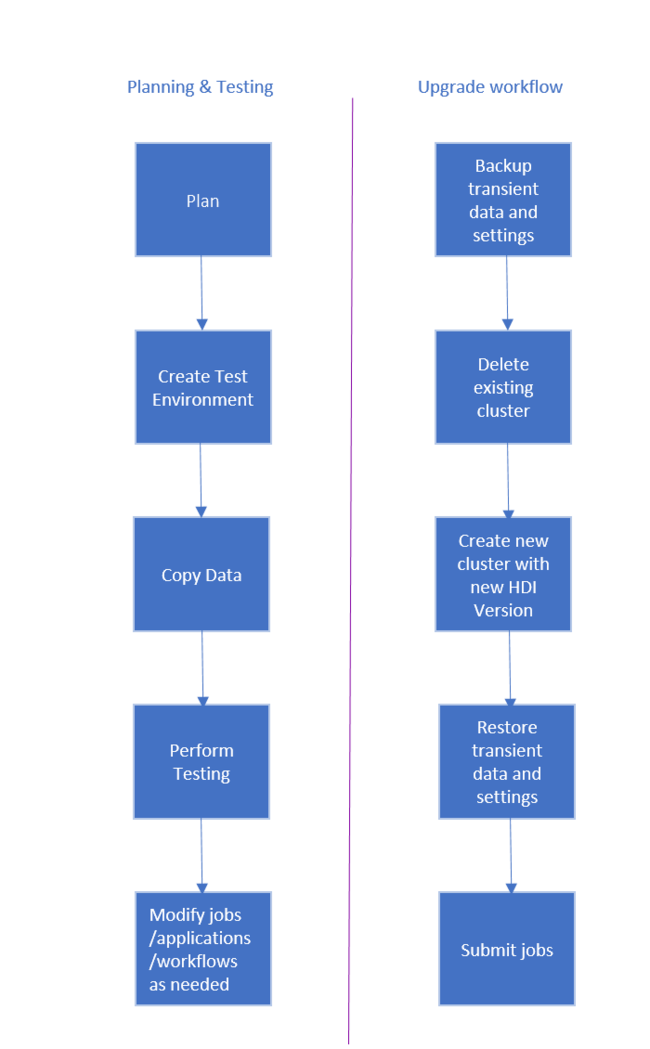
- Ознакомьтесь со всеми разделами этого документа. Там описаны изменения, которые могут потребоваться при обновлении кластера HDInsight.
- Создайте кластер как среду тестирования и контроля качества. См. дополнительные сведения о создании кластеров под управлением Linux в HDInsight.
- Скопируйте в новую среду существующие задания, источники данных и приемники.
- Выполните проверочное тестирование, чтобы убедиться, что задания должным образом работают новом кластере.
Убедившись, что все работает правильно, запланируйте время простоя для миграции. Во время этого простоя выполните следующие действия.
- Создайте резервную копию всех временных данных, хранящихся локально на узлах кластера. Например, к ним могут относиться данные, которые хранятся непосредственно на головном узле.
- Удалите существующий кластер.
- Создайте кластер в той же подсети виртуальной сети, в которой находится последняя (или поддерживаемая) версия HDI, используя то же хранилище данных по умолчанию, что и для предыдущего кластера. Это позволит новому кластеру продолжить работу с существующими рабочими данными.
- Импортируйте все временные данные из резервной копии.
- Запустите задания и продолжите обработку с помощью нового кластера.
Руководство по конкретной рабочей нагрузке
Следующие документы содержат рекомендации по переносу конкретных рабочих нагрузок:
Резервное копирование и восстановление
Дополнительные сведения о резервном копировании и восстановлении базы данных см. в статье Восстановление базы данных в Базе данных SQL Azure с помощью автоматических резервных копий базы данных.
Варианты обновления
Как упоминалось выше, корпорация Майкрософт рекомендует регулярно переносить кластеры HDInsight на последнюю версию, чтобы воспользоваться преимуществами новых функций и исправлений. Ознакомьтесь со следующим списком причин, по которым мы можем запросить удаление и повторное развертывание кластера:
- Версия кластера прекращена или возникает проблема с кластером, которая будет решена с более новой версией.
- Основная причина проблемы с кластером связана с недостаточным размером виртуальной машины. Просмотр рекомендуемой конфигурации узла Майкрософт.
- Клиент создает обращение в службу поддержки, и группа инженеров Майкрософт определяет, что проблема уже исправлена в более новой версии кластера.
- База данных хранилища метаданных по умолчанию (Ambari, Hive, Oozie, Ranger) достигла предела использования. Корпорация Майкрософт просит повторно создать кластер с помощью пользовательской базы данных хранилища метаданных.
- Основная причина проблемы с кластером связана с неподдерживаемой операцией. Ниже приведены некоторые распространенные неподдерживаемые операции:
- Перемещение или добавление службы в Ambari. При просмотре сведений о службах кластеров в Ambari одно из действий, доступных в меню действий службы, — это Переместить [имя службы]. Другое действие — Добавить [имя службы]. Оба эти вариант не поддерживаются.
- Повреждение пакета Python. Кластеры HDInsight зависят от встроенной среды Python (Python 2.7 и Python 3.5). Установка пользовательских пакетов непосредственно в этих встроенных средах по умолчанию может привести к непредвиденным изменениям версий библиотек и прерыванию кластера. Узнайте, как безопасно установить пользовательские внешние пакеты Python для приложений Spark.
- Стороннее программное обеспечение. Клиенты могут устанавливать сторонние программы на своих кластерах HDInsight. Тем не менее рекомендуется повторно создать кластер, если он нарушает существующие функциональные возможности.
- Несколько рабочих нагрузок в одном кластере. В HDInsight 4.0 для Hive Warehouse Connector требуются отдельные кластеры для рабочих нагрузок Spark и Interactive Query. Выполните следующие действия, чтобы настроить эти кластеры в Azure HDInsight. Аналогично, интеграция Spark с HBASE требует два разных кластера.
- Изменен пароль пользовательской базы данных Ambari. Пароль базы данных Ambari задается во время создания кластера, и текущий механизм его обновления отсутствует. Если клиент развертывает кластер с настраиваемой базой данных Ambari, у них есть возможность изменить пароль базы данных в базе данных SQL. Однако этот пароль для работающего кластера HDInsight невозможно обновить.
- Изменение подсистем балансировки нагрузки HDInsight. Подсистемы балансировки нагрузки HDInsight, которые автоматически развертываются для доступа Ambari и SSH, не должны быть изменены или удалены. Если вы изменяете подсистему балансировки нагрузки HDInsight и нарушаете функциональные возможности кластера, рекомендуется повторно развернуть кластер.
- Повторное использованием баз данных Ranger 4.X в версии 5.X. HDInsight 5.1 имеет Apache Ranger версии 2.3.0 , которая является основной версией обновления с версии 1.2.0 в кластерах HDInsight 4.X. Повторное использование базы данных HDInsight 4.X Ranger в HDInsight 5.1 не позволит службе Ranger начать работу из-за различий в схеме базы данных. Для успешного развертывания кластеров HDInsight 5.1 ESP необходимо создать пустую базу данных Ranger.