Репликация разделов Apache Kafka с помощью Kafka в HDInsight и MirrorMaker
Узнайте, как реплицировать разделы во вторичный кластер с помощью функции зеркального отображения Apache Kafka. Зеркальное отображение можно выполнять как непрерывный процесс или периодически для переноса данных из одного кластера в другой.
В этой статье зеркальное отображение используется для репликации разделов между двумя кластерами HDInsight. Эти кластеры находятся в разных виртуальных сетях и в разных центрах обработки данных.
Предупреждение
Не используйте зеркальное отображение как средство для достижения отказоустойчивости. Из-за разного смещения элементов в разделах основного и вторичного кластеров они не могут использоваться как взаимозаменяемые. Если вас интересует отказоустойчивость, настройте репликацию для разделов в пределах кластера. Дополнительные сведения см. в статье по началу работы с Apache Kafka в HDInsight.
Как работает зеркальное отображение Apache Kafka
Зеркальное отображение работает с помощью средства MirrorMaker, которое является частью Apache Kafka. MirrorMaker использует записи из разделов в основном кластере, а затем создает локальную копию в дополнительном кластере. MirrorMaker использует один получатель (или несколько), которые считывают основной кластер, и производитель, который записывает данные в локальный (вторичный) кластер.
В наиболее полезной настройке зеркального отображения для аварийного восстановления используются кластеры Kafka в разных регионах Azure. Для этого виртуальные сети, в которых находятся кластеры, находятся в одноранговом узле.
На следующей схеме показан процесс зеркального отображения и обмен данными между кластерами.

Основной и вторичный кластеры могут отличаться количеством узлов и секций. Смещения в темах также отличаются. Зеркальное отображение сохраняет значение ключа, который используется для секционирования, поэтому порядок записей сохраняется вместе с этими значениями.
Зеркальное отображение в пределах сети
Чтобы реализовать зеркальное отображение между кластерами Kafka в разных сетях, следует учитывать следующее.
Шлюзы: сети должны взаимодействовать на уровне TCP/IP.
Серверная адресация: можно выбрать адреса узлов кластера, используя их IP-адреса или полные доменные имена.
IP-адреса: если вы настраиваете кластеры Kafka для использования объявления IP-адресов, продолжить установку зеркального отображения можно, используя IP-адреса узлов брокера и узлов ZooKeeper.
Доменные имена: если вы не настраиваете кластеры Kafka для объявления IP-адресов, кластеры должны иметь возможность подключаться друг к другу с помощью полных доменных имен (FQDN). Потребуется установить в каждой сети сервер службы доменных имен (DNS), который настроен для пересылки запросов в другие сети. При создании виртуальной сети Azure вместо использования автоматического DNS, предоставленного сетью, необходимо указать пользовательские DNS-сервер и IP-адрес для сервера. После создания виртуальной сети необходимо создать виртуальную машину Azure, которая использует этот IP-адрес. Затем на ней устанавливается и настраивается программное обеспечение DNS.
Важно!
Создайте и настройте пользовательский DNS-сервер, прежде чем устанавливать HDInsight в виртуальной сети. HDInsight не нужно дополнительно настраивать для использования DNS-сервера, настроенного для виртуальной сети.
Дополнительные сведения о подключении двух виртуальных сетей Azure см. в статье Настройка подключения.
Зеркальное отображение архитектуры
Эта архитектура включает в себя два кластера в разных группах ресурсов и виртуальных сетях: первичный и вторичный.
Этапы создания
Создание двух новых групп ресурсов
Группа ресурсов Расположение kafka-primary-rg Центральная часть США kafka-secondary-rg Центрально-северная часть США Создайте новую виртуальную сеть kafka-primary-vnet в расположении kafka-primary-rg. Оставьте параметры по умолчанию.
Создайте новую виртуальную сеть kafka-secondary-vnet в расположении kafka-secondary-rg, также с параметрами по умолчанию.
Создайте два новых кластера Kafka:
Имя кластера Группа ресурсов Виртуальная сеть Учетная запись хранения kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Создайте пиринг между виртуальными сетями. На этом шаге будет создано два пиринга: один из kafka-primary-vnet в kafka-secondary-vnet и один наоборот из kafka-secondary-vnet в kafka-primary-vnet.
Выберите виртуальную сеть kafka-primary-vnet.
В разделе Параметры щелкните Пиринги.
Выберите Добавить.
На экране Добавить пиринг введите сведения, как показано на снимке экрана ниже.

Настройка объявления IP-адресов
Настройте объявления IP-адресов, чтобы разрешить клиенту подключаться по IP-адресам брокера вместо доменных имен.
Перейдите на панель мониторинга Ambari для основного кластера:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Выберите Службы>Kafka. Выберите вкладку Конфигурации .
Добавьте следующие строки конфигурации в нижнюю секцию шаблон kafka-env. Щелкните Сохранить.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesВведите примечание на экране Сохранения конфигурации и выберите Сохранить.
Если вы получаете предупреждение о конфигурации, выберите Все равно продолжить.
В области Сохранить изменения конфигурации выберите OK.
У уведомлении Требуется перезагрузка выберите Перезапустить>Перезапустить все затронутое. Нажмите Подтвердить перезапуск всех.

Настройте Kafka для прослушивания всех сетевых интерфейсов
- Оставайтесь на вкладке Конфигурации в разделе Службы>Kafka. В разделе Kafka Broker(Брокер Kafka) задайте для свойства слушатели значение
PLAINTEXT://0.0.0.0:9092. - Щелкните Сохранить.
- Выберите Перезапустить>Подтвердить перезапуск всех.
Запись IP-адреса брокера и адреса ZooKeeper для основного кластера.
Выберите Узлы на панели мониторинга Ambari.
Запишите IP-адреса для брокера и ZooKeeper. Узлы брокера имеют wn в качестве первых двух букв имени узла, а узлы ZooKeeper имеют zk в качестве первых двух букв имени узла.

Повторите предыдущие три шага для второго кластера kafka-secondary-cluster. Настройте объявления IP-адресов, установите прослушиватели, а также запишите IP-адреса брокера иZooKeeper.
Создание разделов
Подключитесь к основному кластеру с помощью SSH.
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netЗамените
sshuserименем пользователя SSH, которое использовалось при создании кластера. ЗаменитеPRIMARYCLUSTERбазовым именем, которое использовалось при создании кластера.Дополнительные сведения см. в статье Использование SSH с Hadoop на основе Linux в HDInsight из Linux, Unix или OS X.
Используйте следующую команду, чтобы создать две переменные среды с узлами Apache ZooKeeper и брокера для основного кластера. Замените такие строки, как
ZOOKEEPER_IP_ADDRESS1, фактическими IP-адресами, записанными ранее, например10.23.0.11и10.23.0.7. То же самое касаетсяBROKER_IP_ADDRESS1. Если вы используете разрешение полного доменного имени для настраиваемого DNS-сервера, выполните указанные далее действия, чтобы получить имена брокера и ZooKeeper.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Создайте раздел с именем
testtopicс помощью следующей команды:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSС помощью этой команды проверьте, создан ли раздел:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSОтвет содержит
testtopic.Чтобы просмотреть сведения об узле брокера для этого (основного) кластера, выполните следующую команду:
echo $PRIMARY_BROKERHOSTSЭта команда возвращает следующую информацию:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Сохраните эти сведения. Они будут использоваться в следующем разделе.
Настройка зеркального отображения
Подключитесь к вторичному кластеру с помощью другого сеанса SSH:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netЗамените
sshuserименем пользователя SSH, которое использовалось при создании кластера. ЗаменитеSECONDARYCLUSTERименем, которое использовалось при создании кластера.Дополнительные сведения см. в статье Использование SSH с Hadoop на основе Linux в HDInsight из Linux, Unix или OS X.
Используйте файл
consumer.propertiesдля настройки обмена данными с основным кластером. Чтобы создать файл, используйте следующую команду:nano consumer.propertiesДобавьте в файл
consumer.propertiesследующее содержимое:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupЗамените
PRIMARY_BROKERHOSTSна IP-адрес узла брокера из основного кластера.Этот файл содержит сведения о получателе, которые используются при считывании данных из основного кластера Kafka. Дополнительные сведения см. в статье Пользовательская конфигурация в
kafka.apache.org.Чтобы сохранить файл, нажмите Ctrl+X, нажмите Y, а затем нажмите Enter.
Перед настройкой производителя, который обменивается данными с дополнительным кластером, настройте переменную для IP-адресов брокера вторичного кластера. Для создания этой переменной используйте следующие команды:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Команда
echo $SECONDARY_BROKERHOSTSвозвращает информацию приблизительно следующего содержания:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Используйте файл
producer.propertiesдля обмена данными со вторичным кластером. Чтобы создать файл, используйте следующую команду:nano producer.propertiesДобавьте в файл
producer.propertiesследующее содержимое:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneЗамените
SECONDARY_BROKERHOSTSIP-адресами брокера, которые использовались на предыдущем шаге.Дополнительные сведения см. в статье Конфигурация производителя в
kafka.apache.org.Используйте следующие команды, чтобы создать переменную среды с IP-адресами узлов ZooKeeper для вторичного кластера:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'В конфигурации по умолчанию для Kafka в HDInsight не предусматривается автоматическое создание разделов. Прежде чем начать процесс зеркального отображения, используйте один из следующих параметров:
Создание разделов на вторичном кластере. Этот параметр также позволяет задать число секций и коэффициент репликации.
Вы можете создать разделы заранее, выполнив следующую команду:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSЗамените
testtopicименем создаваемого раздела.Настройте кластер на автоматическое создание тем. Этот параметр позволяет MirrorMaker автоматически создавать темы. Обратите внимание, что он может создавать их с другим количеством разделов или с другим фактором репликации, отличным от основной темы.
Чтобы настроить автоматическое создание разделов во вторичном кластере, выполните следующие действия.
- Перейдите на панель мониторинга Ambari для вторичного кластера:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Выберите Службы>Kafka. Выберите вкладку Конфигурации.
- В поле Фильтр введите значение параметра
auto.create. Будет отфильтрован список свойств и отобразится параметрauto.create.topics.enable. - Измените значение параметра
auto.create.topics.enableнаtrueи выберите Сохранить. Добавьте заметку и выберите Сохранить еще раз. - Выберите службу Kafka и щелкните Перезапустить, а затем выберите Restart all affected (Перезапустить все затронутые). Когда появится запрос, выберите Conform Restart All (Подтвердить перезапуск всех).
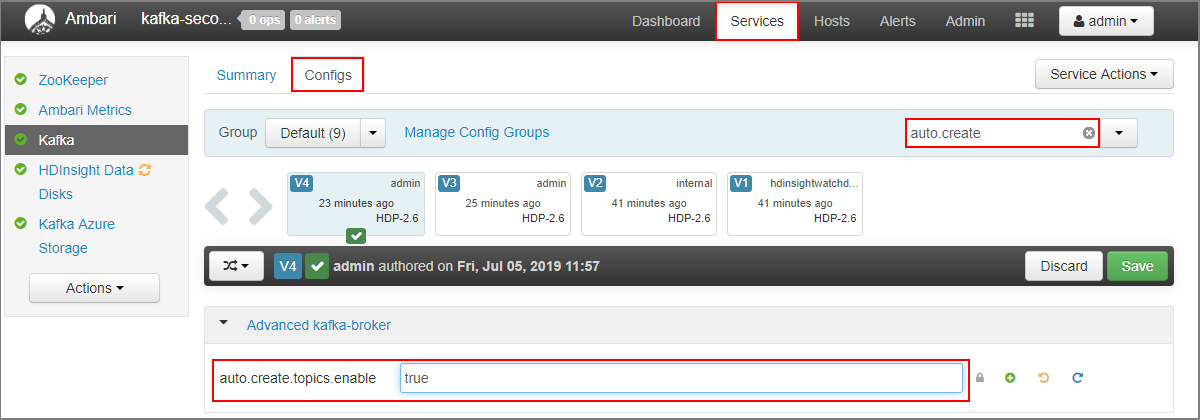
- Перейдите на панель мониторинга Ambari для вторичного кластера:
Запуск MirrorMaker
Примечание
В этой статье содержатся ссылки на термин, который корпорация Майкрософт больше не использует. Когда этот термин будет удален из программного обеспечения, мы удалим его из статьи.
Чтобы запустить процесс MirrorMaker, выполните следующие команды в рамках SSH-подключения к вторичному кластеру:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4В этом примере используются следующие параметры.
Параметр Описание --consumer.configуказывает файл, который содержит свойства получателя. Эти свойства используются для создания получателя, который считывает данные из основного кластера Kafka. --producer.configуказывает файл, который содержит свойства производителя. Эти свойства используются для создания производителя, который записывает данные во вторичный кластер Kafka. --whitelistСписок разделов, которые MirrorMaker реплицирует из основного кластера во вторичный. --num.streamsчисло создаваемых потоков получателя. Потребитель на вторичном узле ожидает получения сообщений.
Чтобы запустить производитель и отправить сообщения в раздел, выполните следующую команду из SSH-подключения к основному кластеру:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicПри переходе в пустую строку с курсором введите несколько текстовых сообщений. Сообщения отправляются в раздел в основном кластере. По завершении нажмите клавиши Ctrl+C, чтобы завершить процесс производителя.
Чтобы завершить процесс MirrorMaker, нажмите клавиши Ctrl+C в рамках SSH-подключения к вторичному кластеру. Завершение этого процесса может занять несколько секунд. Чтобы проверить состояние репликации сообщений во вторичный кластер, используйте следующую команду:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningТеперь в списке разделов есть раздел
testtopic, который создается, когда MirrorMaster зеркально отражает раздел из основного кластера во вторичный. Сообщения, полученные из раздела, совпадают с введенными в основном кластере.
Удаление кластера
Предупреждение
Счета за кластеры HDInsight выставляются пропорционально в минутах, независимо от их использования. Обязательно удалите кластер, когда завершите его использование. Дополнительные сведения см. в статье Удаление кластера HDInsight с помощью браузера, PowerShell или классического интерфейса Azure CLI.
Действия, описанные в этом документе, создают кластеры в разных группах ресурсов Azure. Чтобы удалить все созданные ресурсы, можно удалить две созданные группы ресурсов: kafka-primary-rg и kafka-secondary-rg. При удалении групп ресурсов удаляются все ресурсы, созданные в следующем документе, включая кластеры, виртуальные сети и учетные записи хранения.
Дальнейшие действия
Из этого документа вы узнали, как создать реплику кластера Apache Kafka с помощью MirrorMaker. Другие материалы, посвященные работе с Kafka, доступны по следующим ссылкам:
- Документация по Apache Kafka MirrorMaker на сайте cwiki.apache.org.
- Рекомендации для Kafka Mirror Maker
- Get started with Apache Kafka on HDInsight (preview) (Приступая к работе с Apache Kafka в HDInsight (предварительная версия))
- Использование Apache Spark с Apache Kafka в HDInsight
- Подключение к Apache Kafka с помощью виртуальной сети Azure