Настройка потоков данных в операциях Интернета вещей Azure
Внимание
Предварительная версия операций Интернета вещей Azure, включенная Azure Arc в настоящее время в предварительной версии. Не следует использовать это программное обеспечение предварительной версии в рабочих средах.
Вам потребуется развернуть новую установку Операций Интернета вещей Azure, когда общедоступная версия станет доступной. Вы не сможете обновить предварительную установку.
Юридические условия, применимые к функциям Azure, которые находятся в бета-версии, предварительной версии или в противном случае еще не выпущены в общедоступную версию, см . в дополнительных условиях использования для предварительных версий Microsoft Azure.
Поток данных — это путь, который данные принимают из источника в место назначения с необязательными преобразованиями. Поток данных можно настроить, создав пользовательский ресурс потока данных или используя портал Azure IoT Operations Studio. Поток данных состоит из трех частей: источника, преобразования и назначения.

Чтобы определить источник и назначение, необходимо настроить конечные точки потока данных. Преобразование является необязательным и может включать такие операции, как обогащение данных, фильтрация данных и сопоставление данных с другим полем.
Внимание
Каждый поток данных должен иметь локальную конечную точку брокера MQTT Azure IoT по умолчанию в качестве источника или назначения.
Вы можете использовать интерфейс операций в операциях Интернета вещей Azure для создания потока данных. Интерфейс операций предоставляет визуальный интерфейс для настройки потока данных. Вы также можете использовать Bicep для создания потока данных с помощью файла шаблона Bicep или использовать Kubernetes для создания потока данных с помощью YAML-файла.
Продолжайте чтение, чтобы узнать, как настроить источник, преобразование и назначение.
Необходимые компоненты
Вы можете развернуть потоки данных сразу после того, как у вас есть экземпляр Azure IoT Operations Preview с помощью профиля потока данных по умолчанию и конечной точки. Однако может потребоваться настроить профили потоков данных и конечные точки для настройки потока данных.
Профиль потока данных
Профиль потока данных указывает количество экземпляров для используемых потоков данных. Если вам не требуется несколько групп потоков данных с различными параметрами масштабирования, можно использовать профиль потока данных по умолчанию. Сведения о настройке профиля потока данных см. в разделе "Настройка профилей потоков данных".
Конечные точки потока данных
Конечные точки потока данных необходимы для настройки источника и назначения для потока данных. Чтобы быстро приступить к работе, можно использовать конечную точку потока данных по умолчанию для локального брокера MQTT. Вы также можете создавать другие типы конечных точек потока данных, таких как Kafka, Центры событий или Azure Data Lake Storage. Сведения о настройке каждого типа конечной точки потока данных см. в разделе "Настройка конечных точек потока данных".
Начало работы
После получения необходимых компонентов можно приступить к созданию потока данных.
Чтобы создать поток данных в операциях, выберите "Создать поток> данных". Затем вы увидите страницу, на которой можно настроить источник, преобразование и назначение для потока данных.
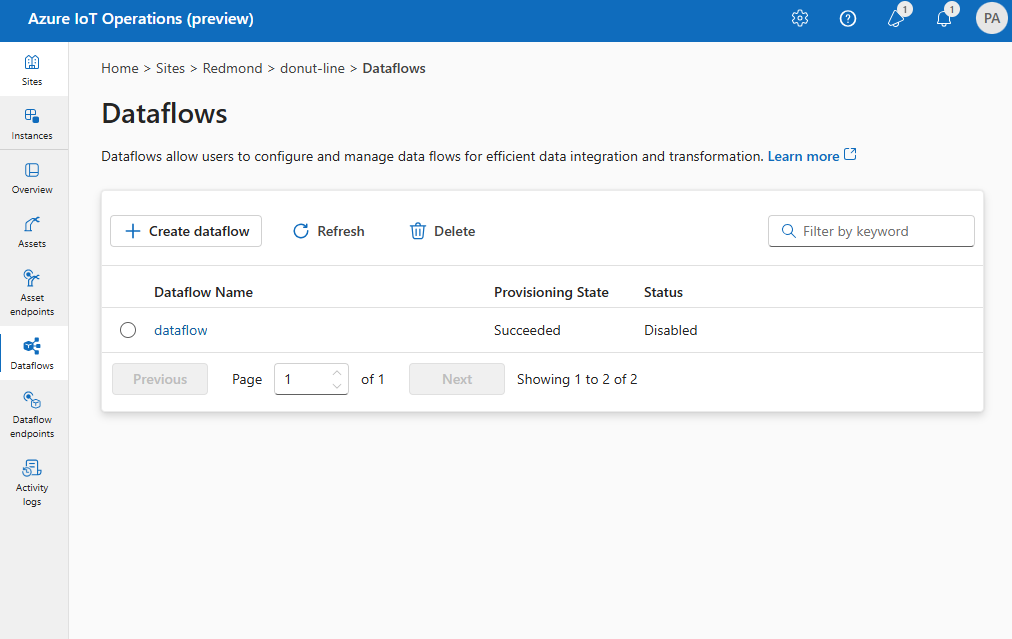
Ознакомьтесь со следующими разделами, чтобы узнать, как настроить типы операций потока данных.
Исходный код
Чтобы настроить источник для потока данных, укажите ссылку на конечную точку и список источников данных для конечной точки.
Использование ресурса в качестве источника
Ресурс можно использовать в качестве источника потока данных. Использование ресурса в качестве источника доступно только в интерфейсе операций.
В разделе "Исходные сведения" выберите "Ресурс".
Выберите ресурс, который вы хотите использовать в качестве исходной конечной точки.
Выберите Продолжить.
Отображается список точек данных для выбранного ресурса.
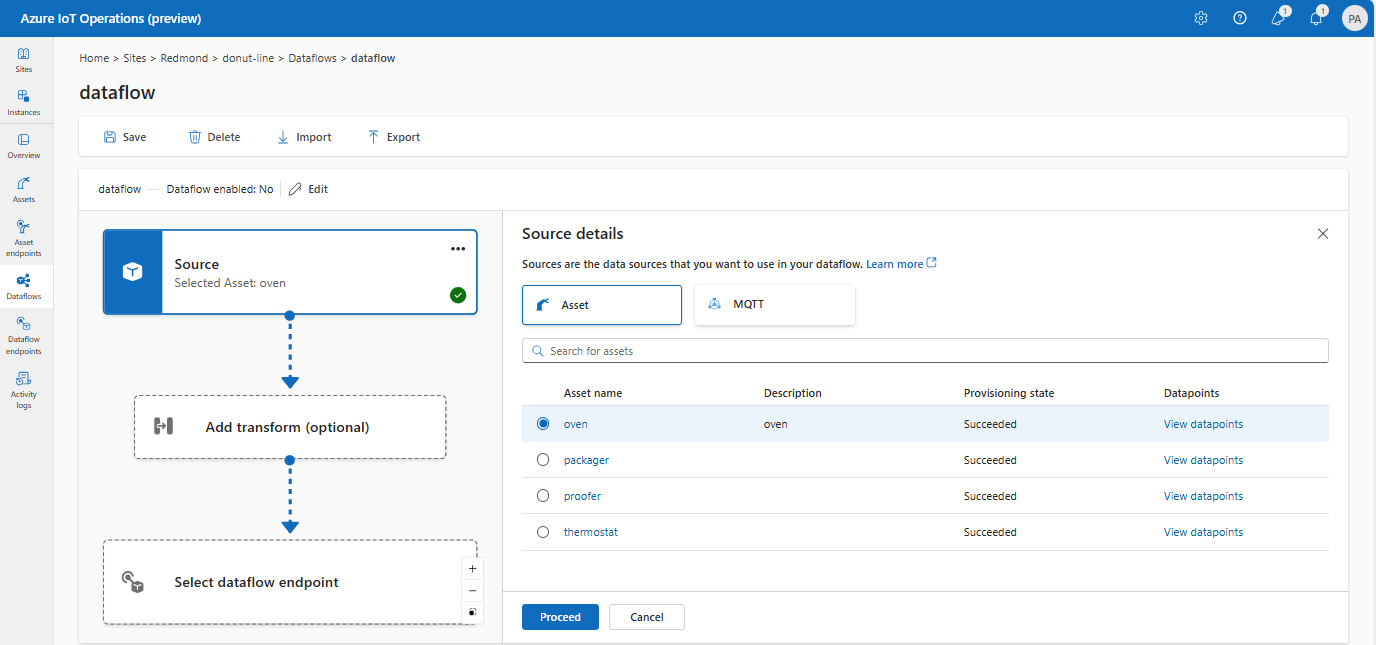
Выберите "Применить" , чтобы использовать ресурс в качестве исходной конечной точки.
При использовании ресурса в качестве источника определение ресурса используется для вывода схемы потока данных. Определение ресурса включает схему для точек данных ресурса. Дополнительные сведения см. в статье "Удаленное управление конфигурациями ресурсов".
После настройки данные из ресурса достигли потока данных через локальный брокер MQTT. Таким образом, при использовании ресурса в качестве источника поток данных использует локальную конечную точку брокера MQTT по умолчанию в качестве источника в действительности.
Использование конечной точки MQTT по умолчанию в качестве источника
В разделе "Исходные сведения" выберите MQTT.
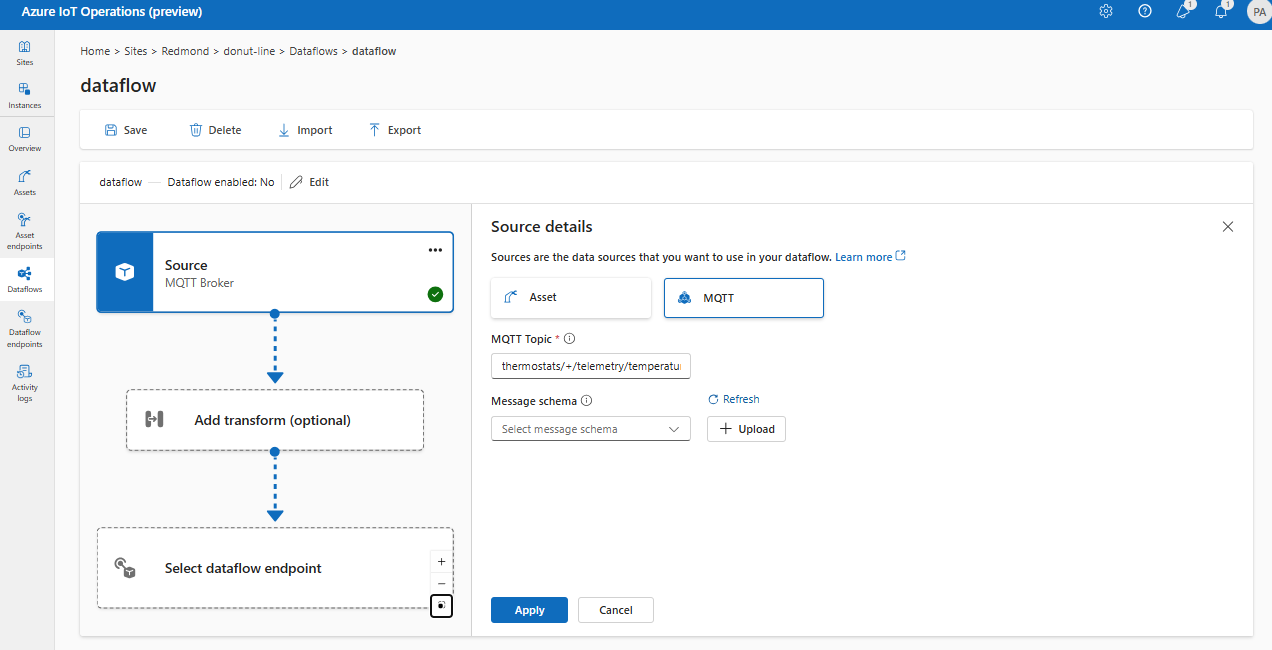
Введите следующие параметры для источника MQTT:
Параметр Description Раздел MQTT Фильтр раздела MQTT для подписки на входящие сообщения. См. статью "Настройка MQTT" или "Kafka". Схема сообщений Схема, используемая для десериализации входящих сообщений. См. раздел "Указание схемы для десериализации данных". Выберите Применить.
Если конечная точка по умолчанию не используется в качестве источника, она должна использоваться в качестве назначения. Дополнительные сведения см. в статье "Потоки данных" должны использовать локальную конечную точку брокера MQTT.
Использование пользовательской конечной точки потока данных MQTT или Kafka в качестве источника
Если вы создали пользовательскую конечную точку потока данных MQTT или Kafka (например, для использования с сеткой событий или Центрами событий), ее можно использовать в качестве источника для потока данных. Помните, что конечные точки типа хранилища, такие как Data Lake или Fabric OneLake, нельзя использовать в качестве источника.
Чтобы настроить, используйте YAML или Bicep Kubernetes. Замените значения заполнителей именем и разделами настраиваемой конечной точки.
Использование пользовательской конечной точки MQTT или Kafka в качестве источника в настоящее время не поддерживается в операциях.
Настройка источников данных (разделы MQTT или Kafka)
Можно указать несколько разделов MQTT или Kafka в источнике, не изменив конфигурацию конечной точки потока данных. Такая гибкость означает, что одна и та же конечная точка может использоваться повторно в нескольких потоках данных, даже если разделы различаются. Дополнительные сведения см. в разделе "Повторное использование конечных точек потока данных".
Темы MQTT
Если источником является конечная точка MQTT (включенная сетка событий), можно использовать фильтр раздела MQTT для подписки на входящие сообщения. Фильтр разделов может включать подстановочные знаки для подписки на несколько разделов. Например, thermostats/+/telemetry/temperature/# подписывается на все сообщения телеметрии температуры из термостатов. Чтобы настроить фильтры раздела MQTT, выполните следующие действия.
В сведениях о источнике потока данных для операций выберите MQTT, а затем используйте поле раздела MQTT, чтобы указать фильтр раздела MQTT для подписки на входящие сообщения.
Примечание.
В интерфейсе операций можно указать только один фильтр раздела MQTT. Чтобы использовать несколько фильтров разделов MQTT, используйте Bicep или Kubernetes.
Общие подписки
Чтобы использовать общие подписки с источниками MQTT, можно указать раздел общей подписки в виде $shared/<GROUP_NAME>/<TOPIC_FILTER>.
В сведениях о источнике потока данных для операций выберите MQTT и используйте поле раздела MQTT, чтобы указать общую группу подписок и раздел.
Если число экземпляров в профиле потока данных больше 1, общая подписка автоматически включается для всех потоков данных, использующих источник MQTT. В этом случае $shared добавляется префикс и имя общей группы подписок автоматически создается. Например, если у вас есть профиль потока данных с числом экземпляров 3, а поток данных использует конечную точку MQTT в качестве источника, настроенную с разделами topic1 , и topic2они автоматически преобразуются в общие подписки как $shared/<GENERATED_GROUP_NAME>/topic1 и $shared/<GENERATED_GROUP_NAME>/topic2. Если вы хотите использовать другой идентификатор группы общих подписок, его можно переопределить в разделе, например $shared/mygroup/topic1.
Внимание
Потоки данных, требующие общей подписки, если число экземпляров больше 1 важно при использовании брокера MQTT Сетки событий в качестве источника, так как он не поддерживает общие подписки. Чтобы избежать отсутствия сообщений, задайте для экземпляра профиля потока данных значение 1 при использовании брокера MQTT сетки событий в качестве источника. Это происходит, когда поток данных является подписчиком и получает сообщения из облака.
Темы Kafka
Если источником является конечная точка Kafka (включенные центры событий), укажите отдельные разделы kafka для подписки на входящие сообщения. Подстановочные знаки не поддерживаются, поэтому необходимо указать каждый раздел статически.
Примечание.
При использовании Центров событий через конечную точку Kafka каждый отдельный концентратор событий в пространстве имен — это раздел Kafka. Например, если у вас есть пространство имен Центров событий с двумя концентраторами событий и thermostats humidifiersможно указать каждый концентратор событий в качестве раздела Kafka.
Чтобы настроить разделы Kafka, выполните следующие действия.
Использование конечной точки Kafka в качестве источника в настоящее время не поддерживается в операциях.
Указание схемы для десериализации данных
Если исходные данные имеют необязательные поля или поля с различными типами, укажите схему десериализации, чтобы обеспечить согласованность. Например, данные могут содержать поля, которые не присутствуют во всех сообщениях. Без схемы преобразование не может обрабатывать эти поля, так как они будут иметь пустые значения. С помощью схемы можно указать значения по умолчанию или игнорировать поля.
Указание схемы имеет значение только при использовании источника MQTT или Kafka. Если источник является ресурсом, схема автоматически выводится из определения ресурса.
Чтобы настроить схему, используемую для десериализации входящих сообщений из источника:
В операциях с сведениями о источнике потока данных выберите MQTT и используйте поле схемы сообщения, чтобы указать схему. Для отправки файла схемы можно использовать кнопку "Отправить ". Дополнительные сведения см. в статье "Общие сведения о схемах сообщений".
Преобразование
Операция преобразования заключается в том, что перед отправкой данных в место назначения можно преобразовать данные из источника. Преобразования являются необязательными. Если вам не нужно вносить изменения в данные, не включайте операцию преобразования в конфигурацию потока данных. Несколько преобразований объединяются на этапах независимо от порядка, в котором они указаны в конфигурации. Порядок этапов всегда:
- Обогащение, переименование или добавление нового свойства: добавление дополнительных данных в исходные данные с заданным набором данных и условием для сопоставления.
- Фильтр. Фильтрация данных на основе условия.
- Сопоставление или вычисление. Перемещение данных из одного поля в другое с необязательным преобразованием.
В интерфейсе операций выберите "Добавить преобразование потока>данных" (необязательно).
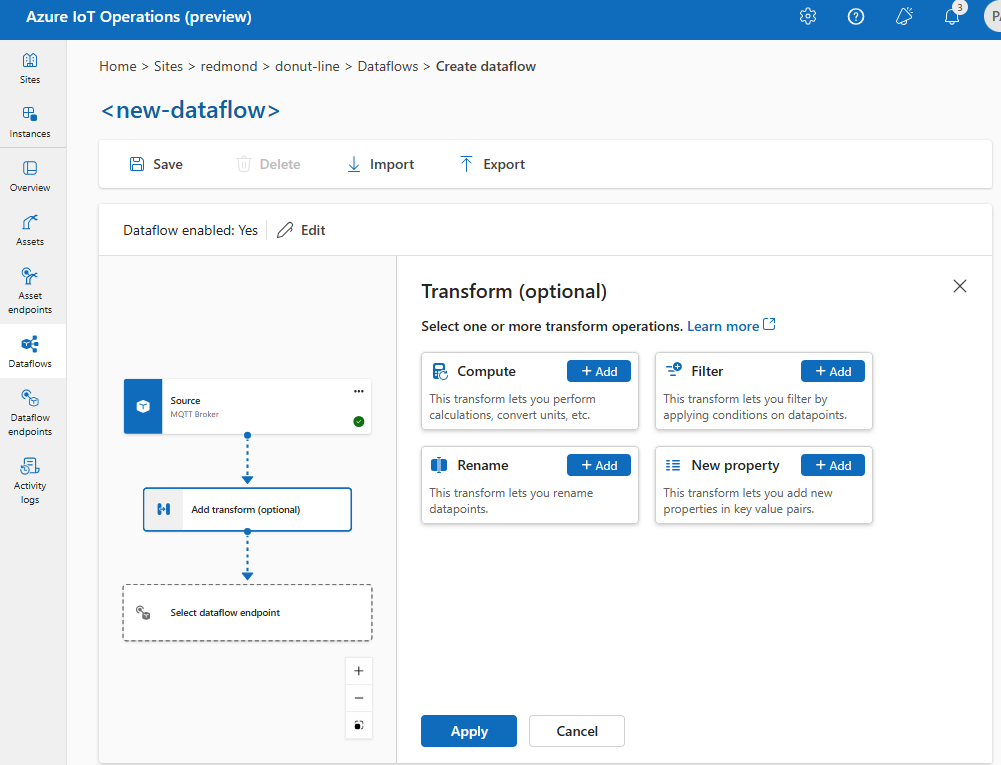
Обогащение: добавление ссылочных данных
Для обогащения данных можно использовать эталонный набор данных в распределенном хранилище состояний Операций Интернета вещей Azure (DSS). Набор данных используется для добавления дополнительных данных в исходные данные на основе условия. Условие указывается в качестве поля в исходных данных, которые соответствуют полю в наборе данных.
Образец данных можно загрузить в DSS с помощью примера средства набора DSS. Имена ключей в распределенном хранилище состояний соответствуют набору данных в конфигурации потока данных.
В ходе операций этап "Обогащение" в настоящее время поддерживается с помощью преобразований свойств "Переименовать" и "Создать".
В интерфейсе операций выберите поток данных, а затем добавьте преобразование (необязательно).
Выберите "Переименовать" или "Создать", а затем нажмите кнопку "Добавить".

Если набор данных содержит запись с asset полем, аналогично:
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
Данные из источника с deviceId сопоставлением thermostat1 полей имеют location manufacturer поля, доступные на этапах фильтрации и сопоставления.
Дополнительные сведения о синтаксисе условий см. в разделе "Обогащение данных с помощью потоков данных" и "Преобразование данных с помощью потоков данных".
Фильтр: фильтрация данных на основе условия
Чтобы отфильтровать данные по условию filter , можно использовать этап. Условие указывается в качестве поля в исходных данных, которые соответствуют значению.
В разделе "Преобразование( необязательно)" выберите "Добавить фильтр>".
Выберите точки данных для включения в набор данных.
Добавьте условие фильтра и описание.
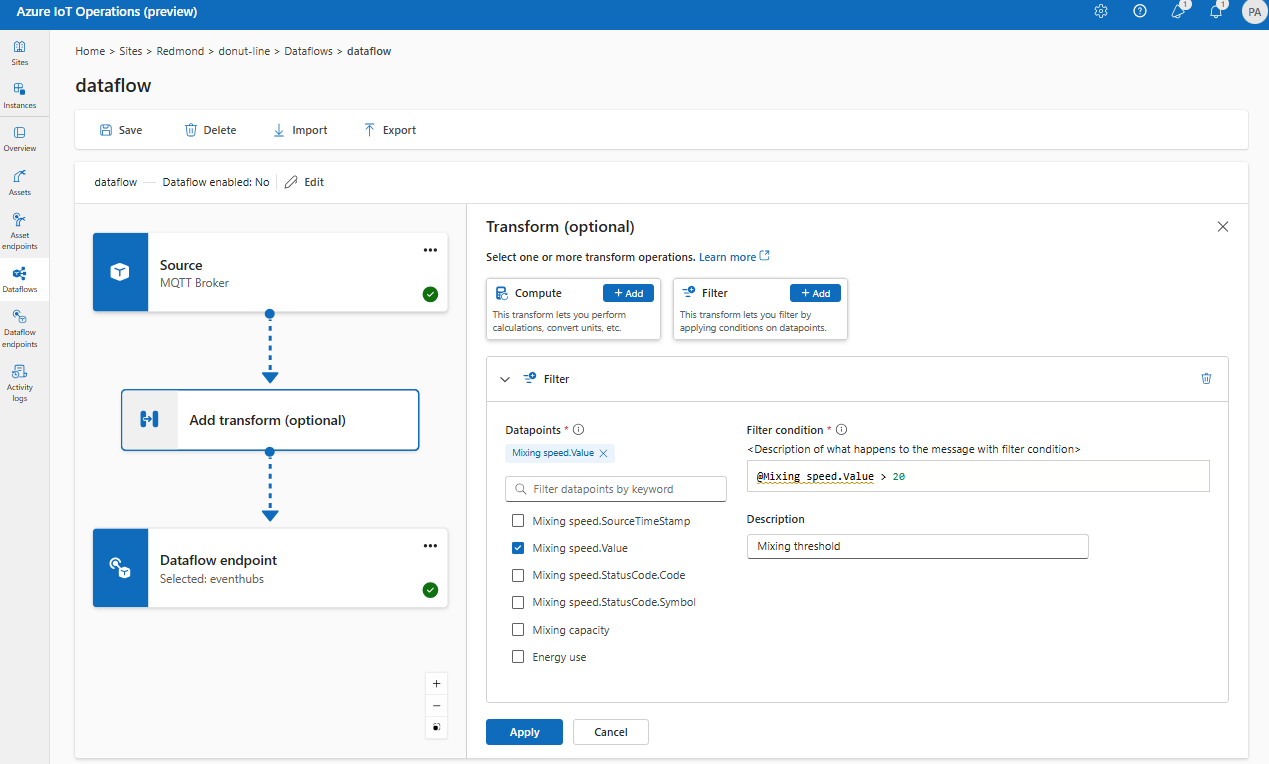
Выберите Применить.
Например, можно использовать условие фильтра, например temperature > 20 фильтрацию данных меньше или равно 20 на основе поля температуры.
Карта: перемещение данных из одного поля в другое
Чтобы сопоставить данные с другим полем с необязательным преобразованием map , можно использовать операцию. Преобразование указывается в виде формулы, которая использует поля в исходных данных.
В интерфейсе операций сопоставление в настоящее время поддерживается с помощью преобразований вычислений .
В разделе "Преобразование( необязательно)" выберите "Добавить вычисления>".
Введите обязательные поля и выражения.
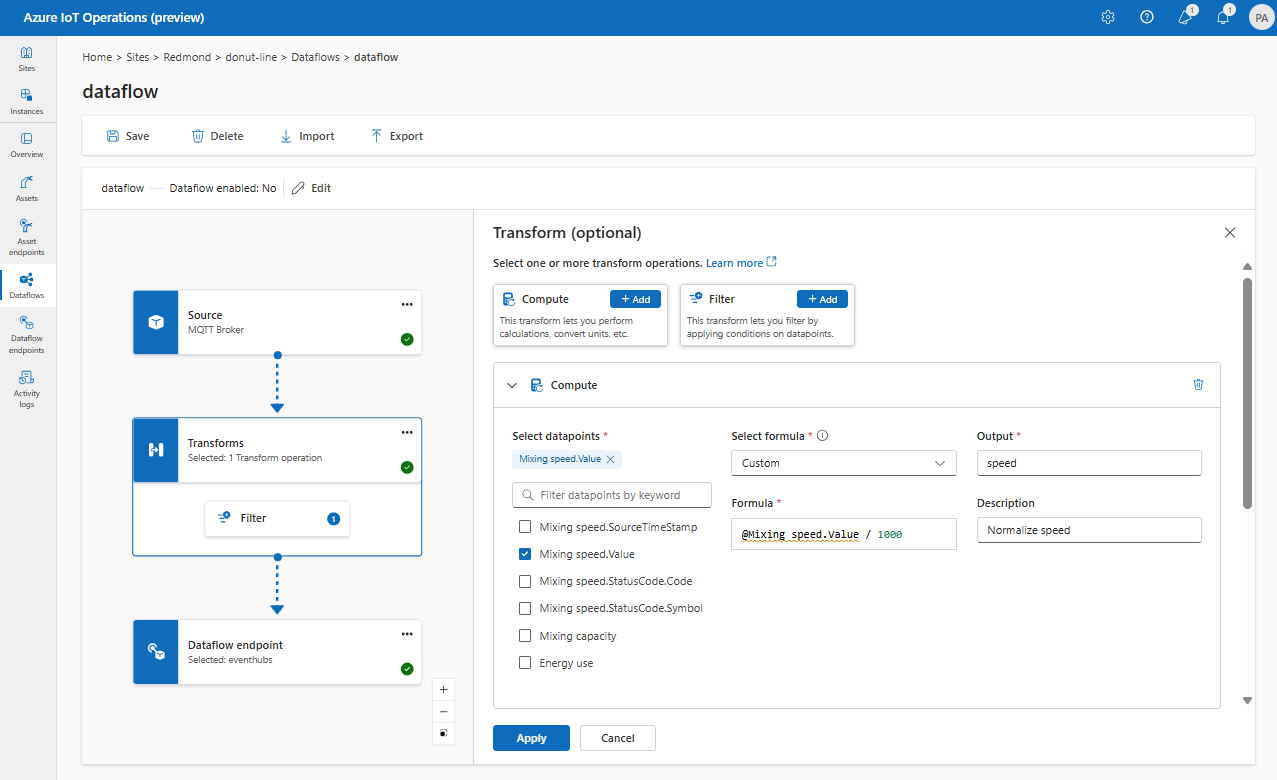
Выберите Применить.
Дополнительные сведения см. в статье "Сопоставление данных с помощью потоков данных" и "Преобразование данных с помощью потоков данных".
Сериализация данных в соответствии со схемой
Если необходимо сериализовать данные перед отправкой в место назначения, необходимо указать формат схемы и сериализации. В противном случае данные сериализуются в ФОРМАТЕ JSON с выводом типов. Конечные точки хранилища, такие как Microsoft Fabric или Azure Data Lake, требуют схемы для обеспечения согласованности данных. Поддерживаемые форматы сериализации — Parquet и Delta.
В настоящее время указание выходной схемы и сериализации не поддерживается в операциях.
Дополнительные сведения о реестре схем см. в разделе "Общие сведения о схемах сообщений".
Назначение
Чтобы настроить назначение для потока данных, укажите ссылку на конечную точку и назначение данных. Список назначений данных для конечной точки можно указать.
Чтобы отправить данные в место назначения, отличное от локального брокера MQTT, создайте конечную точку потока данных. Сведения о настройке конечных точек потока данных см. в статье "Настройка конечных точек потока данных". Если назначение не является локальным брокером MQTT, его необходимо использовать в качестве источника. Дополнительные сведения см. в статье "Потоки данных" должны использовать локальную конечную точку брокера MQTT.
Внимание
Для конечных точек хранилища требуется ссылка на схему. Если вы создали конечные точки назначения хранилища для Microsoft Fabric OneLake, ADLS 2-го поколения, Azure Data Explorer и локального хранилища, необходимо указать ссылку на схему.
Выберите конечную точку потока данных, используемую в качестве назначения.
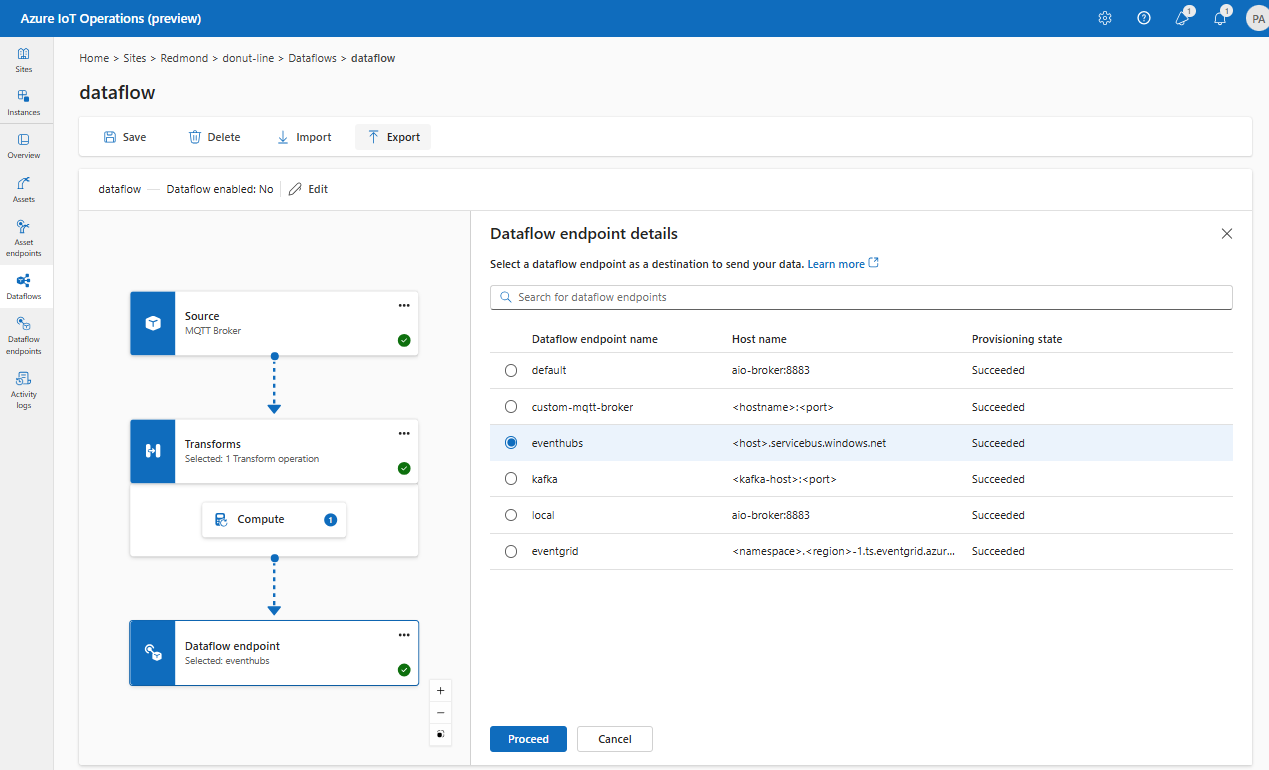
Нажмите кнопку "Продолжить", чтобы настроить назначение.
Введите необходимые параметры для назначения, включая раздел или таблицу для отправки данных. Дополнительные сведения см. в разделе "Настройка назначения данных" (раздел, контейнер или таблица).
Настройка назначения данных (раздел, контейнер или таблица)
Как и источники данных, назначение данных — это концепция, используемая для повторного использования конечных точек потока данных в нескольких потоках данных. По сути, он представляет подкаталог в конфигурации конечной точки потока данных. Например, если конечная точка потока данных является конечной точкой хранения, назначение данных — это таблица в учетной записи хранения. Если конечная точка потока данных является конечной точкой Kafka, назначение данных — это раздел Kafka.
| Тип конечной точки | Значение назначения данных | Description |
|---|---|---|
| MQTT (или сетка событий) | Раздел | Раздел MQTT, в котором отправляются данные. Поддерживаются только статические разделы, без подстановочных знаков. |
| Kafka (или Центры событий) | Раздел | Раздел Kafka, в котором отправляются данные. Поддерживаются только статические разделы, без подстановочных знаков. Если конечная точка является пространством имен Центров событий, назначение данных — это отдельный концентратор событий в пространстве имен. |
| Azure Data Lake Storage | Контейнер | Контейнер в учетной записи хранения. Не таблица. |
| Microsoft Fabric OneLake | Таблица или папка | Соответствует типу настроенного пути для конечной точки. |
| Azure Data Explorer | Таблица | Таблица в базе данных Azure Data Explorer. |
| Локальное хранилище | Папка | Имя папки или каталога в локальном хранилище постоянного тома. При использовании хранилища контейнеров Azure, включенного томами Azure Arc Cloud Ingest Edge, это должно соответствовать параметру spec.path созданного подволока. |
Чтобы настроить назначение данных, выполните следующие действия.
При использовании интерфейса операций поле назначения данных автоматически интерпретируется на основе типа конечной точки. Например, если конечная точка потока данных является конечной точкой хранилища, страница сведений о назначении предложит ввести имя контейнера. Если конечная точка потока данных является конечной точкой MQTT, страница сведений о назначении предложит ввести раздел и т. д.

Пример
В следующем примере показана конфигурация потока данных, которая использует конечную точку MQTT для источника и назначения. Источник фильтрует данные из раздела azure-iot-operations/data/thermostatMQTT. Преобразование преобразует температуру в Fahrenheit и фильтрует данные, в которых температура умножается на влажность менее 100000. Назначение отправляет данные в раздел factoryMQTT.
Пример конфигурации см. на вкладках Bicep или Kubernetes.
Дополнительные примеры конфигураций потока данных см. в статье AZURE REST API — поток данных и краткое руководство по Bicep.
Проверка работы потока данных
Следуйте инструкциям из руководства. Мост MQTT двунаправленного MQTT для Сетка событий Azure для проверки работы потока данных.
Экспорт конфигурации потока данных
Чтобы экспортировать конфигурацию потока данных, можно использовать операции или экспортировать пользовательский ресурс потока данных.
Выберите поток данных, который вы хотите экспортировать, и выберите " Экспорт " на панели инструментов.
Правильная конфигурация потока данных
Чтобы убедиться, что поток данных работает должным образом, проверьте следующее:
- Конечная точка потока данных MQTT по умолчанию должна использоваться как источник или назначение.
- Профиль потока данных существует и ссылается на конфигурацию потока данных.
- Источник — это конечная точка MQTT, конечная точка Kafka или ресурс. Конечные точки типа хранилища нельзя использовать в качестве источника.
- При использовании Сетки событий в качестве источника число экземпляров профиля потока данных имеет значение 1, так как брокер MQTT сетки событий не поддерживает общие подписки.
- При использовании Центров событий в качестве источника каждый концентратор событий в пространстве имен является отдельным разделом Kafka и должен быть указан в качестве источника данных.
- Преобразование, если используется, настроено с правильным синтаксисом, включая надлежащее экранирование специальных символов.
- При использовании конечных точек типа хранилища в качестве назначения указывается схема.