Обучение модели регрессии с помощью автоматизированного машинного обучения и Python (пакет SDK версии 1)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python версии 1
Пакет SDK для Python версии 1
В этой статье вы узнаете, как обучить модель регрессии с помощью пакета SDK для Python Машинное обучение Azure с помощью Машинное обучение Azure автоматизированного машинного обучения. Модель регрессии прогнозирует тарифы на пассажиров для такси, работающих в Нью-Йорке (Нью-Йорк). Вы создаете код с помощью пакета SDK для Python, чтобы настроить рабочую область с подготовленными данными, обучить модель локально с помощью пользовательских параметров и изучить результаты.
Процесс принимает данные обучения и параметры конфигурации. Он автоматически выполняет итерацию с помощью сочетаний различных методов нормализации и стандартизации функций, моделей и параметров гиперпараметра, чтобы получить лучшую модель. На следующей схеме показан поток процесса для обучения модели регрессии:
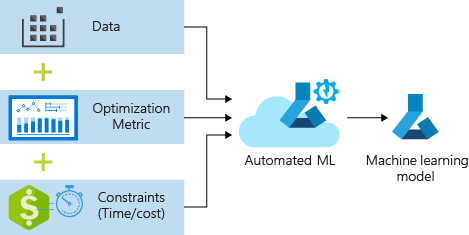
Необходимые компоненты
Подписка Azure. Вы можете создать бесплатную или платную учетную запись Машинное обучение Azure.
Машинное обучение Azure рабочей области или вычислительного экземпляра. Сведения о подготовке этих ресурсов см. в кратком руководстве по началу работы с Машинное обучение Azure.
Получите подготовленные примеры данных для упражнений руководства, загрузив записную книжку в рабочую область:
Перейдите в рабочую область в Студия машинного обучения Azure, выберите "Записные книжки" и перейдите на вкладку "Примеры".
В списке записных книжек разверните узел sdk>для примеров>версии 1>. Регрессия-automl-nyc-taxi-data.
Выберите записную книжку regression-automated-ml.ipynb .
Чтобы запустить каждую ячейку записной книжки в рамках этого руководства, выберите клонировать этот файл.
Альтернативный подход. Если вы предпочитаете, вы можете выполнить упражнения руководства в локальной среде. Руководство доступно в репозитории записных книжек Машинное обучение Azure на GitHub. Для этого подхода выполните следующие действия, чтобы получить необходимые пакеты:
pip install azureml-opendatasets azureml-widgetsВыполните команду на локальном компьютере, чтобы получить необходимые пакеты.
Скачивание и подготовка данных
Пакет Open Datasets содержит класс, представляющий каждый источник данных (например NycTlcGreen), чтобы легко фильтровать параметры даты перед загрузкой.
Следующий код импортирует необходимые пакеты:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Первым шагом является создание кадра данных для данных такси. При работе в среде, отличной от Spark, пакет Open Datasets позволяет загружать только один месяц данных одновременно с определенными классами. Этот подход помогает избежать MemoryError проблемы, которая может возникать с большими наборами данных.
Чтобы скачать данные такси, итеративно извлекает один месяц за раз. Перед добавлением следующего набора данных к green_taxi_df кадру данных случайным образом образец 2000 записей из каждого месяца, а затем предварительный просмотр данных. Этот подход помогает избежать раздувания кадра данных.
Следующий код создает кадр данных, извлекает данные и загружает его в кадр данных:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
В следующей таблице показаны многие столбцы значений в примере данных такси:
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1,88 | нет | нет | -73.996155 | 40.690903 | -73.964287 | ... | 1 | 15,0 | 1.0 | 0,5 | 0,3 | 4,00 | 0,0 | нет | 20.80 | 1.0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | нет | нет | -73.978508 | 40.687984 | -73.955116 | ... | 1 | 11,5 | 0,5 | 0,5 | 0,3 | 2.55 | 0,0 | нет | 15.35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3,54 | нет | нет | -73.957787 | 40.721779 | -73.963005 | ... | 1 | 13,5 долл. США | 0,5 | 0,5 | 0,3 | 2,80 | 0,0 | нет | 17.60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1.00 | нет | нет | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6,5 | 0,0 | 0,5 | 0,3 | 0.00 | 0,0 | нет | 7,30 | 1.0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5,10 | нет | нет | -73.943710 | 40.825439 | -73.982964 | ... | 1 | 18.5 | 0,0 | 0,5 | 0,3 | 3.85 | 0,0 | нет | 23.15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7.41 | нет | нет | -73.940918 | 40.839714 | -73.994339 | ... | 1 | 24,0 | 0,0 | 0,5 | 0,3 | 4,80 | 0,0 | нет | 29.60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1,03 | нет | нет | -73.985718 | 40.685646 | -73.996773 | ... | 1 | 6,5 | 0,0 | 0,5 | 0,3 | 1,30 | 0,0 | нет | 8.60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2,94 | нет | нет | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0,0 | 0,5 | 0,3 | 0.00 | 0,0 | нет | 13.30 | 1.0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3.00 | нет | нет | -73.957939 | 40.721928 | -73.926247 | ... | 1 | 14,0 | 0,5 | 0,5 | 0,3 | 2.00 | 0,0 | нет | 17.30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2,31 | нет | нет | -73.943825 | 40.810257 | -73.943062 | ... | 1 | 10.0 | 0,0 | 0,5 | 0,3 | 2.00 | 0,0 | нет | 12,80 | 1.0 |
Полезно удалить некоторые столбцы, которые не требуются для обучения или другого здания компонентов. Например, можно удалить столбец lpepPickupDatetime , так как автоматизированное машинное обучение автоматически обрабатывает функции на основе времени.
Следующий код удаляет 14 столбцов из примера данных:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Удаление данных
Следующим шагом является очистка данных.
Следующий код запускает функцию describe() в новом кадре данных для создания сводной статистики для каждого поля:
green_taxi_df.describe()
В следующей таблице приведена сводная статистика по оставшимся полям в примерах данных:
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| count | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 |
| mean | 1.777625 | 1.373625 | 2.893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| std | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2.901199 | 1.599776 | 12.339749 |
| min | 1,00 | 0.00 | 0.00 | -74.357101 | 0.00 | -74.342766 | 0.00 | -120.80 |
| 25% | 2.00 | 1.00 | 1,05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8,00 |
| 50% | 2.00 | 1.00 | 1,93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11,30 |
| 75% | 2.00 | 1.00 | 3.70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17,80 |
| max | 2.00 | 8,00 | 154.28 | 0.00 | 41.109089 | 0.00 | 40.982826 | 425.00 |
Сводная статистика показывает несколько полей, которые являются выбросами, которые являются значениями, которые снижают точность модели. Чтобы устранить эту проблему, отфильтруйте поля широты/долготы (lat/long), чтобы значения находятся в пределах манхэттенского района. Этот подход фильтрует более длительные поездки на такси или поездки, которые выпадают в отношении их отношений с другими функциями.
Затем отфильтруйте tripDistance поле для значений, которые больше нуля, но менее 31 миль (расстояние между двумя парами lat/long). Этот метод устраняет длительные поездки, которые имеют несогласованные затраты на поездку.
Наконец, totalAmount поле имеет отрицательные значения для тарифов на такси, которые не имеют смысла в контексте модели. Поле passengerCount также содержит плохие данные, в которых минимальное значение равно нулю.
Следующий код фильтрует эти аномалии значений с помощью функций запроса. Затем код удаляет последние несколько столбцов, которые не нужны для обучения:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Последний шаг этой последовательности — снова вызвать describe() функцию в данных, чтобы обеспечить очистку, как ожидалось. Теперь у вас есть подготовленный и очищенный набор данных о такси, празднике и погоде для использования для обучения модели машинного обучения:
final_df.describe()
Настройка рабочей области
В существующей рабочей области создайте объект. Класс Workspace принимает сведения о подписке и ресурсах Azure. Он также создает облачный ресурс для мониторинга и отслеживания работы модели.
Следующий код вызывает Workspace.from_config() функцию для чтения файла config.json и загрузки сведений проверки подлинности в объект с именем ws.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Объект ws используется в остальной части кода в этом руководстве.
Разделение данных на обучающий и тестовый наборы
Разделение данных на наборы обучения и тестирования с помощью train_test_split функции в библиотеке scikit-learn . Эта функция выполняет разделение данных на набор данных X (функции) для обучения модели и набор данных Y (прогнозируемые значения) для тестирования.
Параметр test_size определяет процент данных, выделяемых для тестирования. Параметр random_state задает начальное значение для случайного генератора, чтобы разделение тестового обучения было детерминированным.
Следующий код вызывает функцию train_test_split для загрузки наборов данных x и y:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Этот шаг предназначен для подготовки точек данных для тестирования готовой модели, которая не используется для обучения модели. Эти точки используются для измерения истинной точности. Хорошо обученная модель — это модель, которая может сделать точные прогнозы из невидимых данных. Теперь у вас есть данные, подготовленные для автоматического обучения модели машинного обучения.
Автоматическое обучение модели
Чтобы автоматически обучить модель, выполните следующие действия.
Определите параметры для запуска эксперимента. Вложите данные для обучения в конфигурацию и измените параметры, которые управляют процессом обучения.
Отправьте эксперимент для настройки модели. После отправки эксперимента процесс выполняет итерацию с помощью различных алгоритмов машинного обучения и параметров гиперпараметра, придерживаясь определенных ограничений. Он выбирает наиболее подходящую модель путем оптимизации метрики точности.
Определение параметров обучения
Определите параметры эксперимента и модели для обучения. Просмотрите полный список параметров здесь. Отправка эксперимента с этими параметрами по умолчанию занимает около 5–20 минут. Чтобы уменьшить время выполнения, уменьшите experiment_timeout_hours значение параметра.
| Свойство | Значение в этом руководстве | Description |
|---|---|---|
iteration_timeout_minutes |
10 | Максимальная длительность каждой итерации в минутах. Увеличьте это значение для больших наборов данных, которым требуется больше времени для каждой итерации. |
experiment_timeout_hours |
0,3 | Максимальное количество времени в часах, в течение которого могут быть пройдены все итерации до завершения эксперимента. |
enable_early_stopping |
Истина | Пометка, чтобы включить досрочное завершение, если оценка не улучшается в краткосрочной перспективе. |
primary_metric |
spearman_correlation | Метрика, который вы хотите оптимизировать. Модель лучшего соответствия выбирается на основе этой метрики. |
featurization |
авто | Автоматическое значение позволяет эксперименту предварительно обработать входные данные, включая обработку отсутствующих данных, преобразование текста в числовой и т. д. |
verbosity |
logging.INFO | Определяет уровень ведения журнала. |
n_cross_validations |
5 | Количество разбиений перекрестной проверки для выполнения, когда данные проверки не указаны. |
Следующий код отправляет эксперимент:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Следующий код позволяет использовать определенные параметры обучения в качестве **kwargs параметра для AutoMLConfig объекта. Кроме того, вы указываете данные обучения и тип модели, что regression в данном случае.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Примечание.
Автоматические этапы предварительной обработки машинного обучения (нормализация функций, обработка отсутствующих данных, преобразование текста в числовые и т. д.) становятся частью базовой модели. При использовании модели для прогнозирования те же предварительные действия, применяемые во время обучения, применяются автоматически к входным данным.
Обучение модели автоматической регрессии
Создайте объект эксперимента в рабочей области. Эксперимент выступает в качестве контейнера для отдельных заданий. Передайте определенный automl_config объект в эксперимент и задайте для вывода значение True для просмотра хода выполнения задания.
После запуска эксперимента отображаемые выходные данные обновляются в режиме выполнения эксперимента. Для каждой итерации отображается тип модели, длительность выполнения и точность обучения. Поле BEST отслеживает лучший показатель обучения на основе типа метрик:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Появятся следующие выходные данные.
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Изучите результаты.
Просмотрите результаты автоматического обучения с помощью мини-приложения Jupyter. Мини-приложение позволяет просматривать график и таблицу всех отдельных итераций выполнения задания, а также метрики и метаданные точности обучения. Кроме того, с помощью раскрывающегося списка вы можете выполнить фильтрацию по метрикам точности, отличным от основной.
Следующий код создает граф для изучения результатов:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
Сведения о выполнении мини-приложения Jupyter:

Диаграмма диаграммы для мини-приложения Jupyter:

Получение оптимальной модели
Следующий код позволяет выбрать лучшую модель из итерации. Функция get_output возвращает лучшее выполнение и соответствующую модель для последнего соответствующего вызова. Используя перегрузки get_output функции, вы можете получить оптимальную модель запуска и установленной модели для любой метрики журнала или определенной итерации.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Проверка оптимальной точности модели
Используйте лучшую модель для выполнения прогнозирования в тестовом наборе данных, чтобы прогнозировать тарифы на такси. Функция predict использует лучшую модель и прогнозирует значения y, затраты на поездку из x_test набора данных.
Следующий код выводит первые 10 прогнозируемых значений y_predict затрат из набора данных:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Вычислите значение root mean squared error результатов. Преобразуйте y_test кадр данных в список и сравните с прогнозируемыми значениями. Функция mean_squared_error принимает два массива значений и вычисляет среднюю квадратную ошибку между ними. Квадратный корень из результата позволяет получить оценку ошибку в тех же единицах, что и для переменной y (стоимость). Она обозначает, насколько далеки полученные прогнозы тарифов на такси от фактических тарифов.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Чтобы вычислить среднюю абсолютную погрешность в процентах (MAPE), запустите следующий код с помощью полных наборов данных y_actual и y_predict. Эта метрика вычисляет абсолютное отклонение между каждой парой прогнозируемого и фактического значения, а затем суммирует все отклонения. Затем эта сумма выражается в процентах от общей суммы фактических значений.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Появятся следующие выходные данные.
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
Из двух метрик точности прогнозирования вы видите, что модель достаточно хороша в прогнозировании тарифов на такси на основе функций набора данных, обычно в пределах + - 4,00 доллара США и приблизительной погрешностью 15%.
Традиционный процесс разработки модели машинного обучения является очень ресурсоемким. Для выполнения и сравнения результатов десятков моделей требуется значительное знание домена и время выполнения. Использование автоматического машинного обучения является отличным способом быстро протестировать множество различных моделей для вашего сценария.
Очистка ресурсов
Если вы не планируете работать с другими руководствами Машинное обучение Azure, выполните следующие действия, чтобы удалить ресурсы, которые больше не нужны.
Остановка вычисления
Если вы использовали вычислительные ресурсы, вы можете остановить виртуальную машину, если вы не используете ее, и сократить затраты:
Перейдите в рабочую область в Студия машинного обучения Azure и выберите "Вычисления".
В списке выберите вычислительные ресурсы, которые нужно остановить, и нажмите кнопку "Остановить".
Когда вы будете готовы снова использовать вычислительные ресурсы, можно перезапустить виртуальную машину.
Удаление других ресурсов
Если вы не планируете использовать ресурсы, созданные в этом руководстве, их можно удалить и избежать дополнительных расходов.
Выполните следующие действия, чтобы удалить группу ресурсов и все ресурсы:
На портале Azure перейдите на страницу Группы ресурсов.
В списке выберите группу ресурсов, созданную в этом руководстве, и выберите команду "Удалить группу ресурсов".
В командной строке подтверждения введите имя группы ресурсов и нажмите кнопку "Удалить".
Если вы хотите сохранить группу ресурсов и удалить только одну рабочую область, выполните следующие действия.
В портал Azure перейдите в группу ресурсов, содержащую рабочую область, которую нужно удалить.
Выберите рабочую область, выберите "Свойства" и нажмите кнопку "Удалить".
Следующий шаг
Кері байланыс
Жақында қолжетімді болады: 2024 жыл бойы біз GitHub Issues жүйесін мазмұнға арналған кері байланыс механизмі ретінде біртіндеп қолданыстан шығарамыз және оны жаңа кері байланыс жүйесімен ауыстырамыз. Қосымша ақпаратты мұнда қараңыз: https://aka.ms/ContentUserFeedback.
Жіберу және пікірді көру