Руководство. Обнаружение приложений Spring Boot, работающих в центре обработки данных (предварительная версия)
В этой статье описывается, как обнаружить приложения Spring Boot, работающие на серверах в центре обработки данных, с помощью средства обнаружения и оценки Службы "Миграция Azure". Процесс обнаружения полностью без агента; на целевых серверах не установлены агенты.
В этом руководстве описано следующее:
- Настройка устройства на основе Kubernetes для обнаружения приложений Spring Boot
- Настройка устройства и запуск непрерывного обнаружения
Примечание.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Поддерживаемые географические регионы
| Географические данные |
|---|
| Азиатско-Тихоокеанский регион |
| Республика Корея |
| Япония |
| США |
| Европа |
| Великобритания |
| Канада |
| Австралия |
| Франция |
Необходимые компоненты
- Прежде чем следовать этому руководству, чтобы обнаружить приложения Spring Boot, убедитесь, что вы выполнили обнаружение серверов с помощью устройства службы "Миграция Azure" с помощью следующих руководств:
- Убедитесь, что вы выполнили инвентаризацию программного обеспечения, предоставив учетные данные сервера в диспетчере конфигурации устройства. Подробнее.
- Поддерживаются только проекты миграции, созданные с помощью подключения к общедоступной конечной точке. Проекты частной конечной точки не поддерживаются.
Настройка устройства на основе Kubernetes
После выполнения обнаружения сервера и инвентаризации программного обеспечения с помощью устройства службы "Миграция Azure" можно включить обнаружение приложений Spring Boot, настроив устройство Kubernetes следующим образом:
Подключение устройства на основе Kubernetes
Переход на портал Azure. Войдите с помощью учетной записи Azure и выполните поиск службы "Миграция Azure".
На странице >"Обзор" серверы, базы данных и веб-приложения выберите "Обнаружение", "Оценка" и "Миграция".
Выберите проект, в котором вы настроили устройство службы "Миграция Azure" в рамках предварительных требований.
Вы увидите сообщение над плиткой "Миграция Azure: обнаружение и оценка", чтобы подключить устройство на основе Kubernetes, чтобы включить обнаружение приложений Spring Boot.
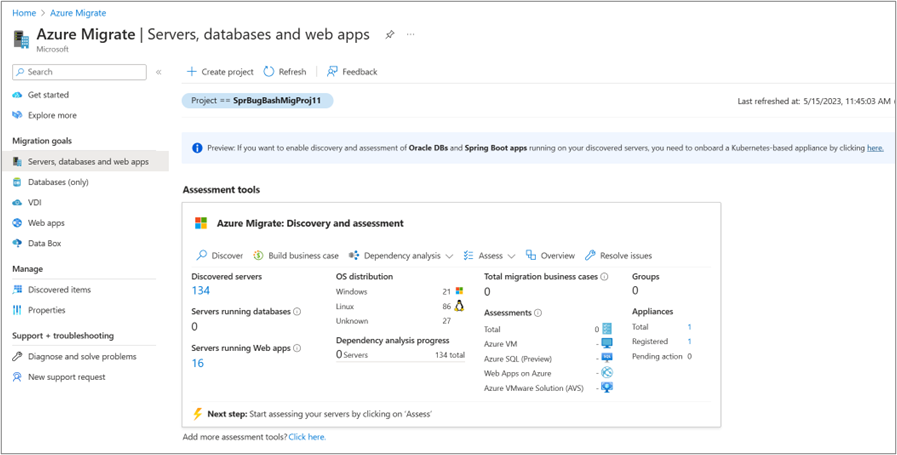
Вы можете продолжить, выбрав ссылку на сообщение, что помогает приступить к подключению устройства на основе Kubernetes.
Примечание.
Мы рекомендуем выбрать кластер Kubernetes с шифрованием дисков для своих служб. Дополнительные сведения о шифровании неактивных данных в Kubernetes.
В разделе "Выбор устройства" можно выбрать один из следующих вариантов:
- Установка устройства с помощью упаковаированного кластера Kubernetes. Этот параметр выбран по умолчанию, так как рекомендуется использовать сценарий установщика для скачивания и установки кластера Kubernetes на локальном сервере Linux для настройки устройства.
- Приведите собственный кластер Kubernetes. Необходимо создать собственный кластер Kubernetes, работающий локально, подключить его к Azure Arc и использовать скрипт установщика для настройки устройства.

- Установка устройства с помощью упаковаемого кластера Kubernetes (рекомендуется)
- Создание собственного кластера Kubernetes
В разделе "Предоставление сведений об устройстве службы "Миграция Azure" имя устройства предварительно заполнено, но вы можете указать собственное понятное имя для устройства.
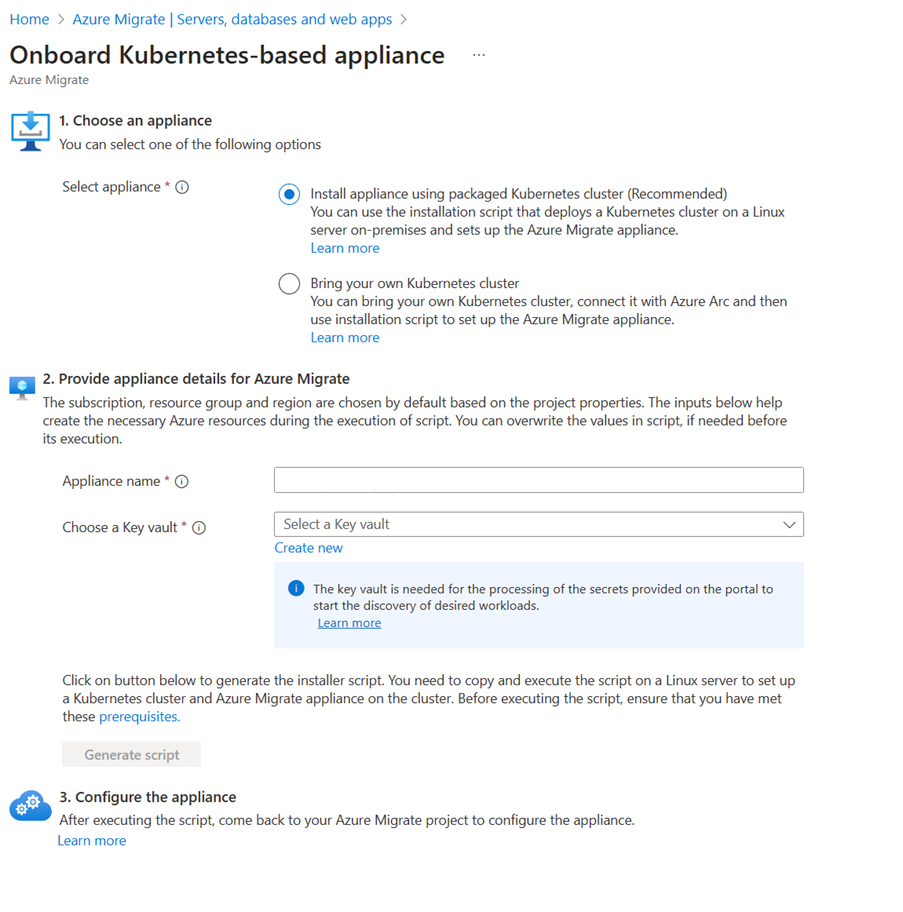
Выберите Key Vault из раскрывающегося списка или создайте новое хранилище ключей. Это хранилище ключей используется для обработки учетных данных, предоставленных в проекте, для запуска обнаружения приложений Spring Boot.
Примечание.
Хранилище ключей можно выбрать или создать в той же подписке и регионе, что и проект миграции Azure. При создании и выборе KV убедитесь, что защита очистки не включена, кроме того, возникают проблемы при обработке учетных данных через Key Vault.
После предоставления имени устройства и Key Vault выберите "Создать сценарий", чтобы создать скрипт установщика, который можно скопировать и вставить на локальном сервере Linux. Перед выполнением скрипта убедитесь, что на сервере Linux выполнены следующие предварительные требования:
Поддержка Сведения Поддерживаемая ОС Linux Ubuntu 20.04, RHEL 9 Необходимая конфигурация оборудования 8 ГБ ОЗУ с хранилищем размером 30 ГБ, 4 ядра ЦП Требования к сети Доступ к следующим конечным точкам:
.docker.io
.docker.com
api.snapcraft.io
https://dc.services.visualstudio.com/v2/track
Требования к сети Kubernetes с поддержкой Azure Arc
Конечные точки Azure CLI для обхода прокси-сервера

После копирования скрипта можно перейти на сервер Linux, сохраните скрипт как Deploy.sh на сервере.

Подключение с использованием исходящего прокси-сервера
Если компьютер находится за исходящим прокси-сервером, запросы должны направляться через исходящий прокси-сервер. Выполните следующие действия, чтобы предоставить параметры прокси-сервера:
- Откройте терминал на сервере и выполните следующую команду, чтобы настроить переменные среды в качестве корневого пользователя:
sudo su - - На компьютере развертывания задайте переменные среды, необходимые для
deploy.shиспользования исходящего прокси-сервера:export HTTP_PROXY=”<proxy-server-ip-address>:<port>” export HTTPS_PROXY=”<proxy-server-ip-address>:<port>” export NO_PROXY=”” - Если прокси-сервер использует сертификат, укажите абсолютный путь к сертификату.
export PROXY_CERT=””
Примечание.
Компьютер использует сведения о прокси-сервере при установке необходимых компонентов для запуска скрипта deploy.sh . Он не переопределит параметры прокси-сервера кластера Kubernetes с поддержкой Azure Arc.
Выполнение скрипта установщика
После сохранения скрипта на сервере Linux выполните следующие действия.
Примечание.
Этот скрипт необходимо запустить после подключения к компьютеру Linux на своем терминале, который соответствовал требованиям сети и совместимости ОС.
Убедитесь, что на сервере установлен curl. Для Ubuntu его можно установить с помощью команды sudo apt-get install curl, а для другой ОС (RHEL/CentOS) можно использовать команду yum install curl.
Внимание
Не изменяйте скрипт, если вы не хотите очистить программу установки.
Откройте терминал на сервере и выполните следующую команду, чтобы выполнить скрипт в качестве корневого пользователя:
sudo su -Измените каталог, на который вы сохранили скрипт и выполните скрипт с помощью команды:
bash deploy.shСледуйте инструкциям в скрипте и войдите с помощью учетной записи пользователя Azure при появлении запроса.
Скрипт выполняет следующие задачи.
- Установка необходимых расширений CLI.
- Регистрация поставщиков ресурсов Azure
- Проверка необходимых компонентов, таких как подключение к необходимым конечным точкам
- Настройка кластера MicroK8s Kubernetes
- Установка необходимых операторов в кластере
- Создание необходимых ресурсов миграции
После успешного выполнения скрипта настройте устройство через портал.
переустановка;
Примечание.
Если во время выполнения скрипта возникла проблема, необходимо повторно запустить скрипт и возобновить работу с последним успешным состоянием. Если вы хотите выполнить полную новую установку, ознакомьтесь со сведениями о настройке перед повторным запуском скрипта.
Шифрование при хранении
При настройке упаковаемого устройства мы несут общую ответственность за обеспечение защиты секретов.
- Мы рекомендуем выбрать виртуальную машину Linux с шифрованием дисков для своих служб.
Настройка устройства на основе Kubernetes
После успешной настройки устройства с помощью скрипта установщика необходимо настроить устройство, выполнив следующие действия.
Перейдите в проект службы "Миграция Azure", где вы начали подключение устройства на основе Kubernetes.
На плитке "Миграция Azure: обнаружение и оценка " выберите количество устройств для ожидающих действий в сводке по устройствам.
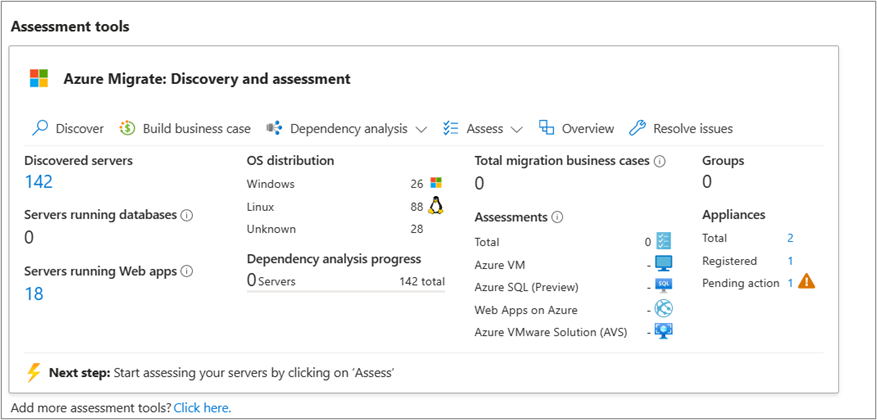
В разделе "Общие сведения>об управлении устройствами>" отображается отфильтрованный список устройств с ожидающих действий.
Найдите настроенное устройство на основе Kubernetes и выберите состояние "Учетные данные" для настройки устройства.
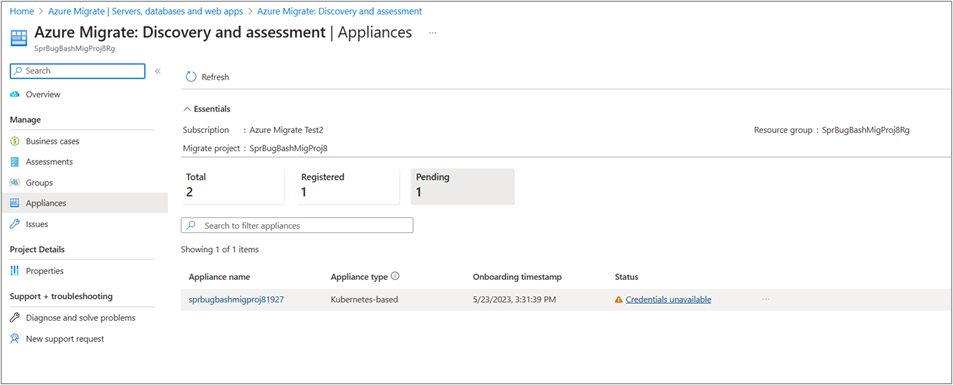
На странице "Управление учетными данными" добавьте учетные данные для запуска обнаружения приложений Spring Boot, работающих на серверах.
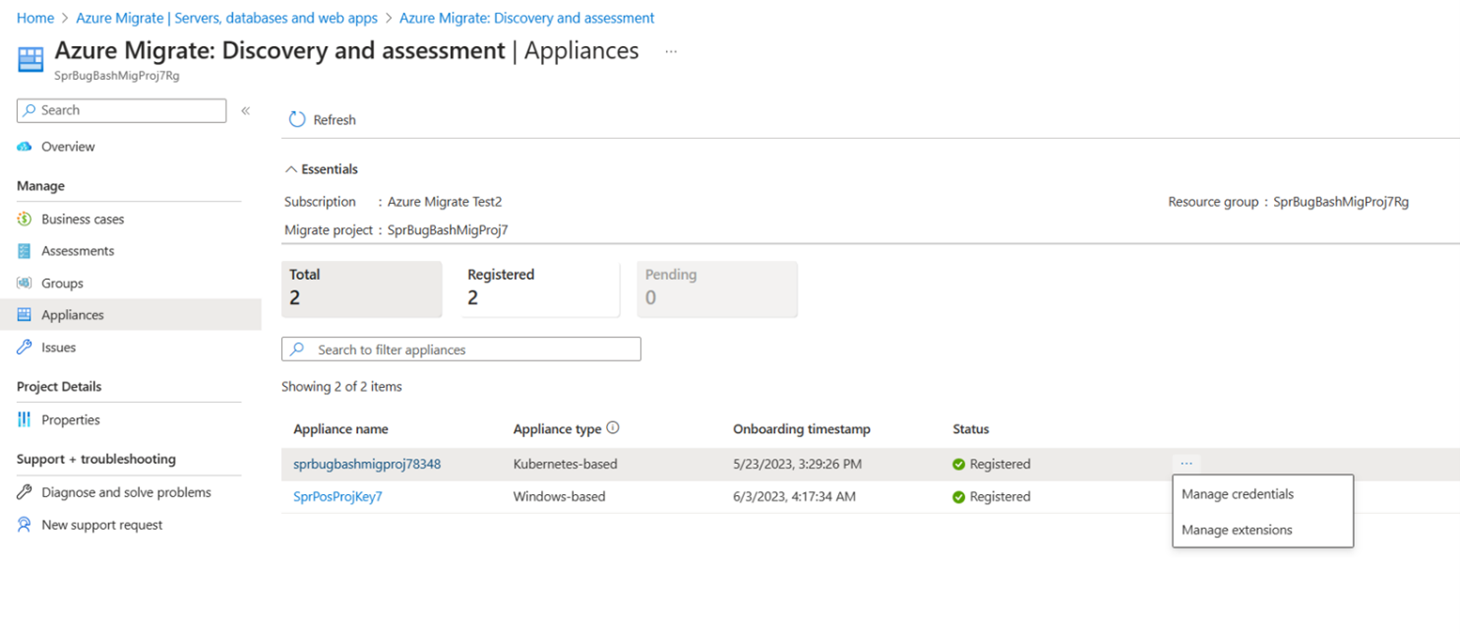
Выберите " Добавить учетные данные", выберите тип учетных данных из Linux (не доменных) или доменных учетных данных, укажите понятное имя, имя пользователя и пароль. Выберите Сохранить.
Примечание.
- Учетные данные, добавленные на портале, обрабатываются с помощью Azure Key Vault, выбранного в начальных шагах подключения устройства на основе Kubernetes. Затем учетные данные синхронизируются (сохраняются в зашифрованном формате) с кластером Kubernetes на устройстве и удаляются из Azure Key Vault.
- После успешной синхронизации учетных данных они будут использоваться для обнаружения конкретной рабочей нагрузки в следующем цикле обнаружения.
После добавления учетных данных необходимо обновить страницу, чтобы просмотреть состояние синхронизации учетных данных. Если состояние является неполным, можно выбрать состояние, чтобы просмотреть обнаруженную ошибку и выполнить рекомендуемое действие. После успешной синхронизации учетных данных дождитесь 24 часов, прежде чем вы сможете просмотреть обнаруженную инвентаризацию, отфильтровав определенную рабочую нагрузку на странице "Обнаруженные серверы ".
Примечание.
Вы можете добавлять и обновлять учетные данные в любое время, перейдя на страницу "Миграция Azure: обнаружение и оценка>>>"Управление устройствами", выбрав "Управление учетными данными" из параметров, доступных на устройстве на основе Kubernetes.



Очистка установки
Чтобы очистить, выполните следующий сценарий в режиме удаления:
В скрипте, созданном порталом, после всех аргументов пользователя (после строки 19 на следующем изображении) добавьте export DELETE= “true” и снова запустите тот же скрипт. Это очищает все существующие компоненты, созданные во время создания устройства.

Общие сведения о результатах обнаружения
На экране обнаруженных серверов приведены следующие сведения:
- Отображает все запущенные рабочие нагрузки Spring Boot в серверной среде.
- Выводит основные сведения о каждом сервере в формате таблицы.

Выберите любое веб-приложение для просмотра сведений. На экране веб-приложений приведены следующие сведения:
- Предоставляет комплексное представление каждого процесса Spring Boot на каждом сервере.
- Отображает подробные сведения о каждом процессе, в том числе:
- Версия JDK и версия Spring Boot.
- Имена переменных среды и параметры JVM, настроенные.
- Используемые файлы конфигурации приложений и сертификатов.
- Расположение JAR-файла для процесса на сервере.
- Расположения статического содержимого и порты привязки.

Следующие шаги
- Оценка приложений Spring Boot для миграции.
- Просмотрите данные, собранные устройством во время обнаружения.
Кері байланыс
Жақында қолжетімді болады: 2024 жыл бойы біз GitHub Issues жүйесін мазмұнға арналған кері байланыс механизмі ретінде біртіндеп қолданыстан шығарамыз және оны жаңа кері байланыс жүйесімен ауыстырамыз. Қосымша ақпаратты мұнда қараңыз: https://aka.ms/ContentUserFeedback.
Жіберу және пікірді көру