Настройка высокого уровня доступности в SUSE с помощью устройства ограничения
В этой статье мы рассмотрим шаги по настройке высокого уровня доступности (HA) в крупных экземплярах HANA в операционной системе SUSE с помощью устройства ограничения.
Примечание
Это руководство составлено по итогам успешной проверки настройки в среде крупных экземпляров Microsoft HANA. Команда управления службами Майкрософт для крупных экземпляров HANA не занимается поддержкой операционной системы. Для устранения неполадок и уточнений на уровне операционной системы обратитесь в SUSE.
Команда управления службами Майкрософт настраивает и полностью поддерживает устройство ограничения. Она также помогает в устранении неполадок с устройством ограничения.
Предварительные требования
Чтобы настроить высокий уровень доступности с помощью кластеризации SUSE, вам потребуется следующее.
- Подготовленные крупные экземпляры HANA.
- Установите и зарегистрируйте операционную систему с последними исправлениями.
- Подключите серверы крупных экземпляров HANA к серверу SMT для получения исправлений и пакетов.
- Настроенный сервер времени NTP.
- Вы ознакомились с последней версией документации SUSE по настройке HA.
Сведения о настройке
В этом руководстве используется следующая конфигурация:
- операционная система: SLES 12 с пакетом обновления 1 (SP1) для SAP;
- крупные экземпляры HANA: 2xS192 (4 сокета, 2 ТБ);
- версия HANA: HANA 2.0 с пакетом обновления 1 (SP1);
- имена серверов: sapprdhdb95 (node1) и sapprdhdb96 (node2);
- устройство ограничения: на основе iSCSI;
- NTP на одном из узлов крупных экземпляров HANA.
При настройке крупных экземпляров HANA с репликацией системы HANA вы можете попросить команду управления службами Майкрософт настроить для вас устройство ограничения. Сделайте это на этапе подготовке к работе.
Если вы уже являетесь нашим клиентом и используете подготовленные крупные экземпляры HANA, это не помешает нам настроить для вас устройство ограничения. Предоставьте в запросе на обслуживание приведенные ниже сведения для команды управления службами Майкрософт. Форму запроса на обслуживание (SRF) можно получить у менеджера по технической поддержке или представителя Майкрософт по подключению крупных экземпляров HANA.
- Имя и IP-адрес сервера (например, myhanaserver1 и 10.35.0.1).
- Расположение (например, восточная часть США).
- Имя клиента (например, корпорация Майкрософт).
- Идентификатор системы HANA (SID) (например, H11).
После настройки устройства ограничения команда управления службами Майкрософт предоставит вам имя SBD и IP-адрес хранилища iSCSI. Эти сведения можно использовать для настройки ограничения.
Выполните действия, описанные в следующих разделах, чтобы настроить высокий уровень доступности с помощью устройства ограничения.
Идентификация устройства SBD
Примечание
Этот раздел относится только к существующим клиентам. Если вы наш новый клиент, команда управления службами Майкрософт предоставит вам имя устройства SBD, так что просто пропустите этот раздел.
Измените /etc/iscsi/initiatorname.isci на:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Специалисты по управлению службами Майкрософт предоставят эту строку. Измените файл на обоих узлах. Но номера узлов на них будут отличаться.

Измените /etc/iscsi/iscsid.conf, задав
node.session.timeo.replacement_timeout=5иnode.startup = automatic. Измените файл на обоих узлах.Выполните следующую команду обнаружения на обоих узлах.
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260В результатах отображаются четыре сеанса.

Выполните следующую команду на обоих узлах, чтобы войти на устройство iSCSI.
iscsiadm -m node -lВ результатах отображаются четыре сеанса.

Используйте следующую команду, чтобы запустить сценарий повторного сканирования rescan-scsi-bus.sh. Отобразятся созданные диски. Выполните ее на обоих узлах.
rescan-scsi-bus.shРезультат должен содержать номер LUN, который должен быть больше нуля (например, 1, 2 и т. д.).
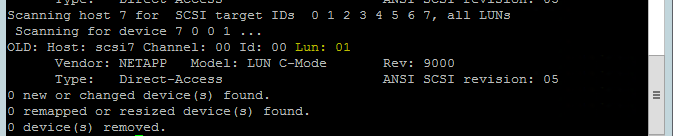
Чтобы получить имя устройства, выполните следующую команду на обоих узлах.
fdisk –lВ результатах выберите устройство размером 178 МиБ.

Инициализация устройства SBD
Используйте следующую команду, чтобы инициализировать устройство SBD на обоих узлах.
sbd -d <SBD Device Name> create
Используйте следующую команду на обоих узлах, чтобы проверить, что было записано на устройство.
sbd -d <SBD Device Name> dump
Настройка кластера SUSE с высоким уровнем доступности
Используйте следующую команду, чтобы проверить, установлены ли шаблоны ha_sles и SAPHanaSR-doc на обоих узлах. Если они не установлены, установите их.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc

Настройте кластер с помощью команды
ha-cluster-initили мастера YaST2. В этом примере мы используем мастер YaST2. Это действие выполняется только на первичном узле.Go to YaST2>High Availability>Cluster (YaST2 > Высокая доступность > Кластер).

В появившемся диалоговом окне об установке пакета hawk нажмите кнопку Cancel (Отмена), так как пакет halk2 уже установлен.

В появившемся диалоговом окне нажмите кнопку Continue (Продолжить).

Ожидаемое значение — число развернутых узлов (в нашем примере это 2). Выберите Далее.
Добавьте имена узлов, а затем выберите команду Add suggested files (Добавить рекомендуемые файлы).

Выберите элемент Turn csync2 ON (Включить csync2).
Нажмите Generate Pre-Shared-Keys (Сгенерировать общий ключ).
Во всплывающем сообщении нажмите кнопку ОК.

Аутентификация выполняется с помощью IP-адресов и общих ключей в Csync2. Файл ключа создается с помощью
csync2 -k /etc/csync2/key_hagroup.После создания файла key_hagroup вручную скопируйте его во все элементы кластера. Убедитесь, что файл скопирован с узла 1 на узел 2. Выберите Далее.

По умолчанию параметр Booting (Загрузка) имеет значение Off (Отключено). Измените значение на On (Включено), чтобы служба pacemaker запускалась при загрузке. Выбор можно сделать на основе требований к установке.

Щелкните Next (Далее), чтобы завершить настройку кластера.
Настройка службы наблюдения softdog
Добавьте следующую строку в /etc/init.d/boot.local на обоих узлах.
modprobe softdog
Используйте следующую команду, чтобы обновить файл /etc/sysconfig/sbd на обоих узлах.
SBD_DEVICE="<SBD Device Name>"
Загрузите модуль ядра на обоих узлах, выполнив следующую команду.
modprobe softdog
Используйте следующую команду, чтобы убедиться, что softdog работает на обоих узлах.
lsmod | grep dog
Используйте следующую команду, чтобы запустить устройство SBD на обоих узлах.
/usr/share/sbd/sbd.sh start
Используйте следующую команду, чтобы протестировать управляющую программу SBD на обоих узлах.
sbd -d <SBD Device Name> listВ результатах отобразятся две записи после настройки на обоих узлах.

Отправьте следующее тестовое сообщение на один из ваших узлов.
sbd -d <SBD Device Name> message <node2> <message>На втором узле (node2) используйте следующую команду, чтобы проверить состояние сообщения.
sbd -d <SBD Device Name> list
Чтобы принять конфигурацию SBD, обновите файл /etc/sysconfig/sbd следующим образом на обоих узлах.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""Используйте следующую команду, чтобы запустить службу pacemaker на основном узле (node1).
systemctl start pacemaker
В случае сбоя службы pacemaker см. раздел Сценарий 5. Сбой службы pacemaker далее в этой статье.
Соедините узел с кластером.
Выполните следующую команду на node2, чтобы узел мог соединиться с кластером.
ha-cluster-join
Если при присоединении кластера появляется сообщение об ошибке, см. раздел Сценарий 6. node2 не может присоединиться к кластеру далее в этой статье.
Проверка кластера
Чтобы проверить и при необходимости запустить кластер в первый раз на обоих узлах, используйте следующие команды.
systemctl status pacemaker systemctl start pacemaker
Выполните следующую команду, чтобы убедиться, что оба узла находятся в сети. Ее можно выполнить на любом узле кластера.
crm_mon
Кроме того, для проверки состояния кластера можно войти в hawk:
https://\<node IP>:7630. Пользователь по умолчанию — hacluster, пароль — linux. При необходимости можно изменить пароль с помощью командыpasswd.
Настройка свойств и ресурсов кластера
В этом разделе описаны действия по настройке кластерных ресурсов. В этом примере вы настроите следующие ресурсы. При необходимости информацию о настройке остальных ресурсов можно найти в руководстве по настройке высокого уровня доступности в SUSE.
- Начальная загрузка кластера
- Устройство ограничения
- Виртуальный IP-адрес
Выполните настройку только на основном узле.
Создайте файл начальной загрузки кластера и настройте его, добавив следующий текст.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"Выполните следующую команду, чтобы добавить конфигурацию в кластер.
crm configure load update crm-bs.txt
Настройте устройство ограничения, добавив ресурс, создав файл и добавив текст, как показано ниже.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"Выполните следующую команду, чтобы добавить конфигурацию в кластер.
crm configure load update crm-sbd.txtДобавьте виртуальный IP-адрес для ресурса, создав файл и добавив следующий текст.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"Выполните следующую команду, чтобы добавить конфигурацию в кластер.
crm configure load update crm-vip.txtИспользуйте команду
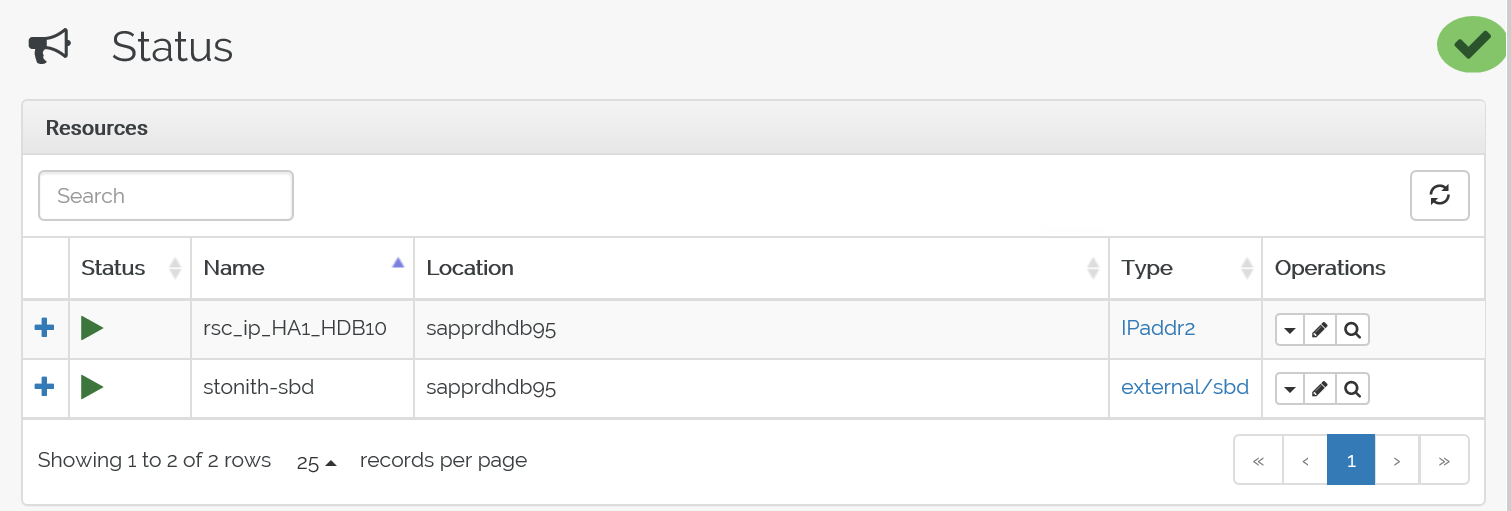
crm_monдля проверки ресурсов.В результатах показаны два ресурса.

Состояние можно также проверить по адресу https://<IP-адрес узла>:7630/cib/live/state.

Протестируйте процесс отработки отказа.
Чтобы протестировать процесс отработки отказа, используйте следующую команду для завершения работы службы pacemaker на узле node1.
Service pacemaker stopВ результате отработки отказа ресурсы перейдут на узел node2.
Остановите службу pacemaker на узле node2. После этого произойдет отработка отказа ресурсов на узел node1.
Состояние до отработки отказа выглядит следующим образом:

Состояние после отработки отказа выглядит следующим образом:

Устранение неполадок
В этом разделе описываются сценарии сбоев, которые могут возникнуть во время установки.
Сценарий 1. Узел кластера не в сети
Если какой-либо из узлов отображается в диспетчере кластеров как находящийся не в сети, можно попробовать включить его с помощью приведенных ниже действий.
Используйте следующую команду, чтобы запустить службу iSCSI.
service iscsid startИспользуйте следующую команду, чтобы войти на этот узел iSCSI.
iscsiadm -m node -lОжидаемый результат выглядит примерно так:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
Сценарий 2. В YaST2 не отображается графическое представление
В этой статье для настройки высокодоступного кластера используется графический экран YaST2. Если YaST2 при открытии не отображает графический экран и возвращает ошибку Qt, выполните следующие действия, чтобы установить необходимые пакеты. Если он открывается с графическим окном, эти шаги можно пропустить.
Так выглядит пример ошибки Qt:

Так выглядит ожидаемый вывод:
Необходимо войти в систему как пользователь root и настроить SMT для скачивания и установки пакетов.
Перейдите в раздел YaST>Software>Software Management>Dependencies (YaST > Программы > Управление программами > Зависимости), а затем нажмите Install recommended packages (Установить рекомендуемые пакеты).
Примечание
Для получения доступа к графическому представлению YaST2 выполните указанные выше действия на обоих узлах.
На следующем снимке экрана показано окно, которое должно появиться.

В разделе Dependencies (Зависимости) выберите Install Recommended Packages (Установить рекомендуемые пакеты).

Проверьте изменения и щелкните ОК.

Установка пакета продолжится.

Выберите Далее.
Когда появится экран Installation Successfully Finished (Установка успешно завершена), нажмите кнопку Finish (Готово).

Используйте следующие команды для установки пакетов libqt4 и libyui-qt.
zypper -n install libqt4
zypper -n install libyui-qt

Теперь YaST2 может открыть графическое представление.

Сценарий 3. В YaST2 не отображается пункт для высокого уровня доступности
Для отображения пункта high-availability (высокий уровень доступности) в YaST2 Control Center необходимо установить дополнительные пакеты.
Перейдите в раздел Yast2>Software>Software Management (YaST > Программы > Управление программами). Затем выберите пункт Software>Online Update (Программы > Обновление онлайн).
Выберите шаблоны для следующих элементов. Затем нажмите Accept (Принять).
- Базовый сервер SAP HANA.
- Компилятор и средства C/C++.
- Высокий уровень доступности
- Базовый сервер приложений SAP.

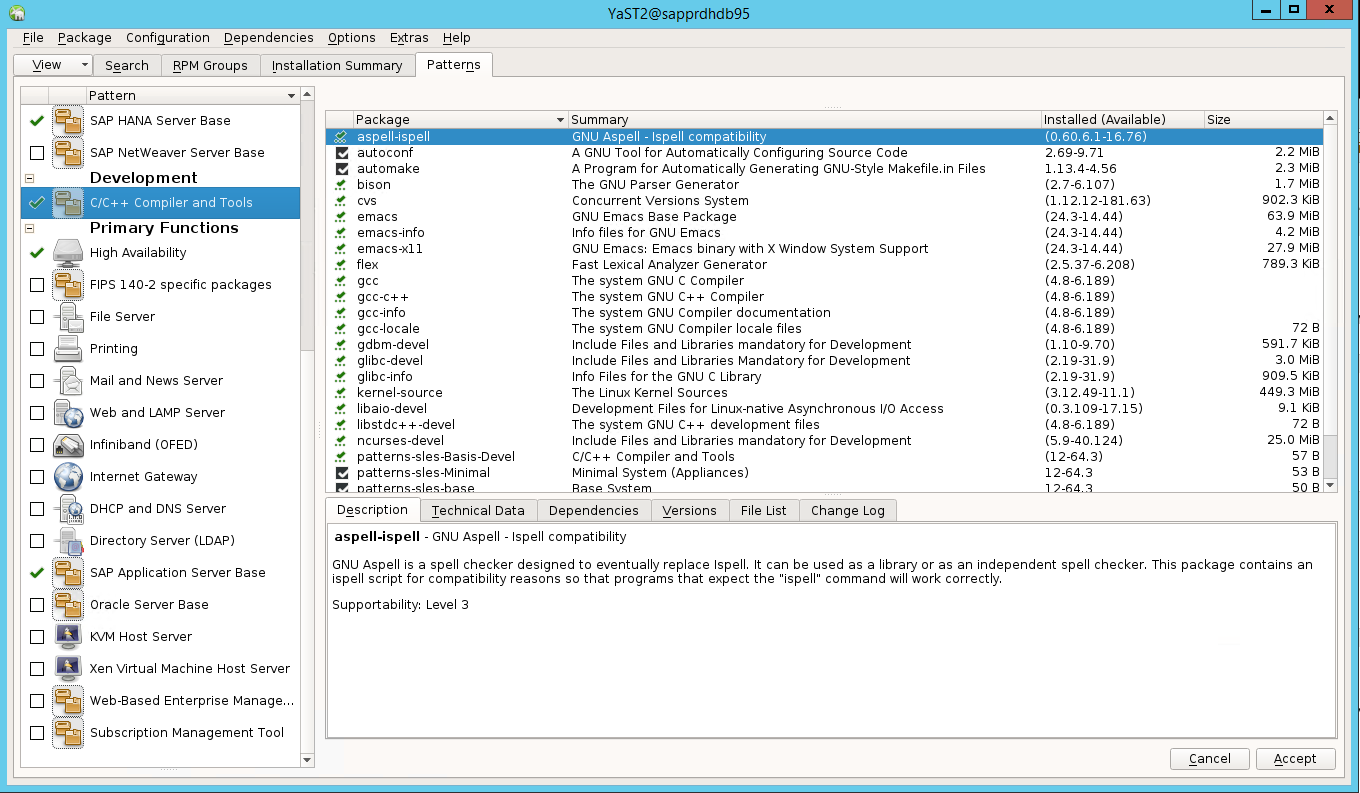
В списке пакетов, которые были изменены для разрешения зависимостей, нажмите Continue (Продолжить).

На странице состояния Performing Installation (Выполняется установка) нажмите кнопку Next (Далее).

После завершения установки появится отчет об установке. Нажмите кнопку Готово.

Сценарий 4. Установка HANA завершается ошибкой сборок gcc
Если установка HANA завершается сбоем, может появиться следующая ошибка.

Чтобы устранить эту проблему, установите библиотеки libgcc_sl и libstdc++6, как показано на следующем снимке экрана.

Сценарий 5. Сбой службы Pacemaker
Если не удается запустить службу pacemaker, отображаются следующие сведения.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
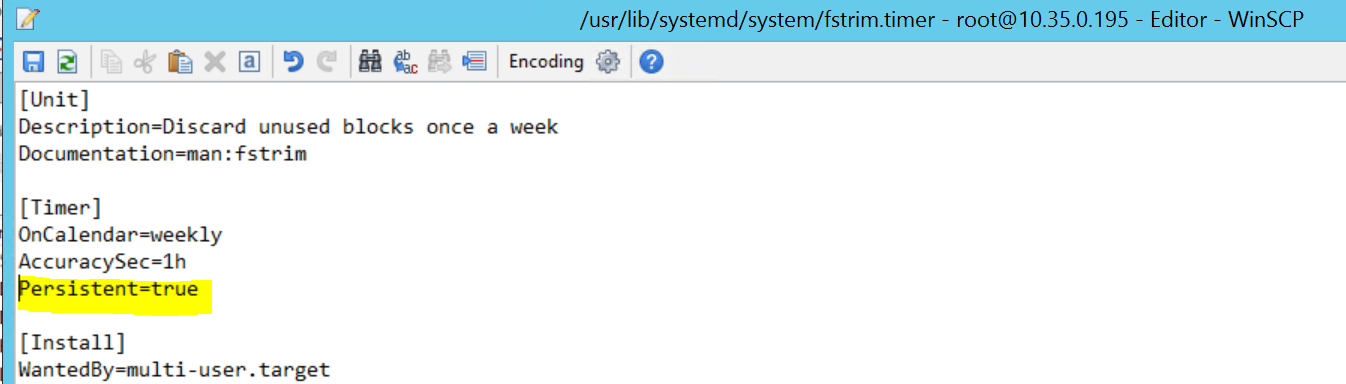
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
Чтобы устранить проблему, удалите следующую строку в файле /usr/lib/systemd/system/fstrim.timer:
Persistent=true
Сценарий 6. Узел node2 не может присоединиться к кластеру
Следующая ошибка возникает, если есть проблемы с присоединением узла node2 к существующему кластеру с помощью команды ha-cluster-join.
ERROR: Can’t retrieve SSH keys from <Primary Node>

Чтобы устранить эту проблему, выполните следующие действия.
Выполните следующие команды на обоих узлах.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

Убедитесь, что узел node2 добавлен в кластер.

Дальнейшие действия
Дополнительные сведения об установке SUSE HA можно найти в следующих статьях:
- Сценарий оптимизации производительности системной репликации SAP HANA (веб-сайт SUSE)
- Ограничение и устройства ограничения (веб-сайт SUSE)
- Подготовка к использованию кластера Pacemaker для SAP HANA — Часть 1. Основные сведения (блог SAP)
- Подготовка к использованию кластера Pacemaker для SAP HANA — Часть 2. Сбой обоих узлов (блог SAP)
- Резервное копирование и восстановление ОС