Хранилище знаний "проекции" в поиске ИИ Azure
Проекции определяют физические таблицы, объекты и файлы в хранилище знаний, принимающем содержимое из конвейера обогащения поиска ИИ Azure. Если вы создаете хранилище знаний, большая часть работы заключается в определении и формировании проекций.
В этой статье приводятся основные понятия проекции и рабочий процесс, чтобы у вас был некоторый фон перед началом написания кода.
Проекции определяются в наборах навыков поиска ИИ Azure, но конечные результаты — это проекции таблиц, объектов и файлов изображений в служба хранилища Azure.
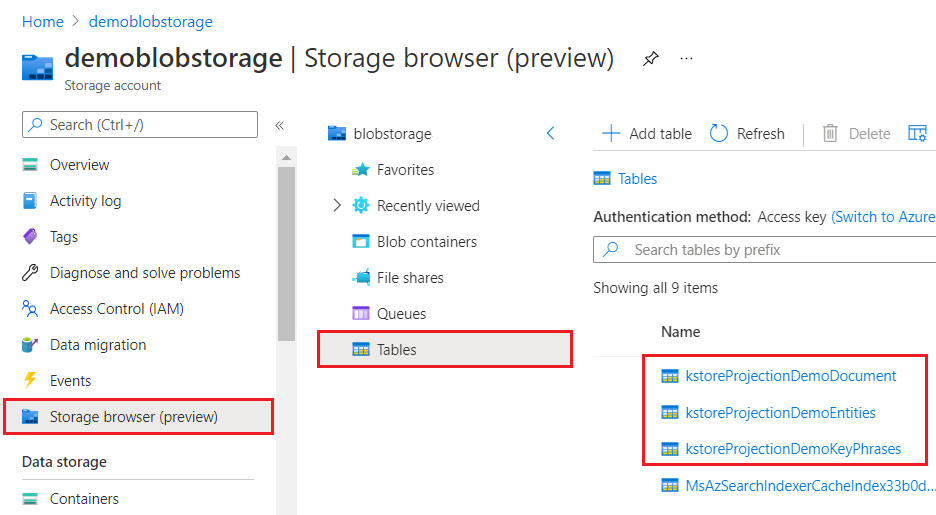
Типы проекций и использования
Хранилище знаний — это логическая конструкция, которая физически выражается как свободная коллекция таблиц, объектов JSON или двоичных файлов изображений в служба хранилища Azure.
| Проекция | Хранилище | Использование |
|---|---|---|
| Таблицы | Хранилище таблиц Azure | Используется для данных, которые лучше всего представлены в виде строк и столбцов, или всякий раз, когда требуется детализированное представление данных (например, в виде кадров данных). Проекции таблиц позволяют определить схемизированную фигуру, используя навык фигуры или использовать встроенное формирование для указания столбцов и строк. Содержимое можно упорядочить в несколько таблиц на основе знакомых принципов нормализации. Таблицы, которые находятся в той же группе, автоматически связаны. |
| Объекты | Хранилище BLOB-объектов Azure | Используется при необходимости полного представления данных и обогащений в одном документе JSON. Как и в случае с проекциями таблиц, только допустимые объекты JSON можно спроецировать в качестве объектов, и формирование может помочь вам в этом. |
| Файлы | Хранилище BLOB-объектов Azure | Используется при сохранении нормализованных двоичных файлов изображений. |
Определение проекции
Проекции задаются в свойстве knowledgeStore набора навыков. Определения проекции используются во время вызова индексатора для создания и загрузки объектов в служба хранилища Azure с обогащенным содержимым. Если вы не знакомы с этими понятиями, начните с обогащения ИИ для введения.
В следующем примере показано размещение проекций в хранилище знаний и базовое построение. Имя, тип и источник контента составляют определение проекции.
"knowledgeStore" : {
"storageConnectionString": "DefaultEndpointsProtocol=https;AccountName=<Acct Name>;AccountKey=<Acct Key>;",
"projections": [
{
"tables": [
{ "tableName": "ks-museums-main", "generatedKeyName": "ID", "source": "/document/tableprojection" },
{ "tableName": "ks-museumEntities", "generatedKeyName": "ID","source": "/document/tableprojection/Entities/*" }
],
"objects": [
{ "storageContainer": "ks-museums", "generatedKeyName": "ID", "source": "/document/objectprojection" }
],
"files": [ ]
}
]
Группы проекций
Проекции — это массив сложных коллекций, что означает, что можно указать несколько наборов каждого типа. Обычно используется только одна группа проекций, но вы можете использовать несколько вариантов, если требования к хранилищу включают поддержку различных средств и сценариев. Например, можно использовать одну группу для разработки и отладки набора навыков, а второй набор собирает выходные данные, используемые для онлайн-приложения, с третьей для рабочих нагрузок обработки и анализа данных.
Один и тот же набор навыков используется для заполнения всех групп в проекциях. В следующем примере показано два.
"knowledgeStore" : {
"storageConnectionString": "DefaultEndpointsProtocol=https;AccountName=<Acct Name>;AccountKey=<Acct Key>;",
"projections": [
{
"tables": [],
"objects": [],
"files": []
},
{
"tables": [],
"objects": [],
"files": []
}
]
}
Группы проекций имеют следующие основные характеристики взаимного исключения и взаимной связи.
| Принцип | Description |
|---|---|
| Взаимное исключение | Каждая группа полностью изолирована от других групп для поддержки различных сценариев формирования данных. Например, при тестировании различных структур и сочетаний таблиц каждый набор будет помещен в другую группу проекций для тестирования AB. Каждая группа получает данные из одного и того же источника (дерева обогащения), но полностью изолирована от сочетания таблиц, объектов и файлов любой из одноранговых групп проекций. |
| Взаимная связь | В группе проекций содержимое в таблицах, объектах и файлах связаны. Хранилище знаний использует созданные ключи в качестве ссылочных точек на общий родительский узел. Например, рассмотрим сценарий, в котором есть документ, содержащий изображения и текст. Вы можете проецировать текст в таблицы и изображения в двоичные файлы, а таблицы и объекты имеют столбец или свойство, содержащее URL-адрес файла. |
Проекция "источник"
Исходный параметр является третьим компонентом определения проекции. Так как проекции хранят данные из конвейера обогащения ИИ, источник проекции всегда является результатом навыка. Таким образом выходные данные могут быть одним полем (например, полем переведенного текста), но часто это ссылка на фигуру данных.
Фигуры данных приходят из набора навыков. Среди всех встроенных навыков, предоставляемых в службе "Поиск ИИ Azure", есть служебная программа, называемая навыком shaper, который используется для создания фигур данных. Вы можете включить навыки фигуры (столько, сколько вам нужно) для поддержки проекций в хранилище знаний.
Фигуры часто используются с проекциями таблиц, где фигура не только указывает, какие строки отправляются в таблицу, но и какие столбцы создаются (вы также можете передать фигуру в проекцию объекта).
Фигуры могут быть сложными, и это не в области, чтобы подробно обсудить их здесь, но следующий пример кратко иллюстрирует базовую фигуру. Выходные данные навыка фигуры указываются в качестве источника проекции таблицы. В самой проекции таблицы будут столбцы для столбцов "метаданные-storage_path", "reviews_text", "reviews_title" и т. д., как указано в фигуре.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "ShaperForTables",
"description": null,
"context": "/document",
"inputs": [
{
"name": "metadata_storage_path",
"source": "/document/metadata_storage_path",
"sourceContext": null,
"inputs": []
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "reviews_username",
"source": "/document/reviews_username"
},
],
"outputs": [
{
"name": "output",
"targetName": "mytableprojection"
}
]
}
Жизненный цикл проекции
У проекций есть жизненный цикл, зависящий от исходных данных в вашем источнике данных. По мере обновления и повторного индексирования данных источника ваши проекции обновляются с учетом результатов обогащения, обеспечивая в конечном итоге согласованность с данными в вашем источнике данных. Однако проекции также хранятся отдельно в службе хранилища Azure. Они не будут удалены при удалении индексатора или самой службы поиска.
Использование в приложениях
После запуска индексатора подключитесь к проекциям и потребляйте данные в других приложениях и рабочих нагрузках.
Используйте портал Azure для проверки создания объектов и содержимого в служба хранилища Azure.
Используйте Power BI для изучения данных. Это средство лучше всего работает, если данные содержатся в хранилище таблиц Azure. В Power BI можно управлять данными в новых таблицах, которые проще запрашивать и анализировать.
Используйте обогащенные данные в контейнере БОЛЬШИХ двоичных объектов в конвейере обработки и анализа данных. Например, данные из больших двоичных объектов можно загрузить в кадр данных Pandas.
Наконец, если необходимо экспортировать данные из хранилища знаний, в фабрике данных Azure имеются соединители для экспорта данных и их размещения в базе данных по вашему выбору.
Контрольный список для начала работы
Помните, что проекции являются эксклюзивными для хранилищ знаний и не используются для структуры индекса поиска.
В служба хранилища Azure получите строка подключения из ключей доступа и убедитесь, что учетная запись StorageV2 (версия общего назначения версии 2).
В служба хранилища Azure ознакомьтесь с существующим содержимым в контейнерах и таблицах, чтобы выбрать имена неконфликации для проекций. Хранилище знаний — это свободная коллекция таблиц и контейнеров. Рассмотрите возможность принятия соглашения об именовании для отслеживания связанных объектов.
В службе поиска ИИ Azure включите кэширование обогащения (предварительная версия) в индексаторе, а затем запустите индексатор для выполнения набора навыков и заполнения кэша. Это функция предварительной версии, поэтому обязательно используйте REST API предварительной версии (API-version=2020-06-30-preview или более поздней версии) в запросе индексатора. После заполнения кэша можно изменить определения проекции в хранилище знаний бесплатно (если сами навыки не изменяются).
В коде все проекции определяются исключительно в наборе навыков. Нет свойств индексатора (например, сопоставления полей или сопоставления выходных полей), которые применяются к проекциям. В определении набора навыков вы будете сосредоточиться на двух областях: свойств knowledgeStore и массиве навыков.
В разделе knowledgeStore укажите таблицу, объект, проекции файлов в
projectionsразделе. Тип объекта, имя объекта и количество (на число определенных проекций) определяются в этом разделе.Из массива навыков определите, какие выходные данные навыков должны ссылаться в
sourceкаждой проекции. Все проекции имеют источник. Источник может быть выходным результатом вышестоящего навыка, но часто является результатом навыка фигуры. Состав проекции определяется с помощью фигур.
Если вы добавляете проекции в существующий набор навыков, обновите набор навыков и запустите индексатор.
Проверьте результаты служба хранилища Azure. При последующих запусках избегайте конфликтов именования, удаляя объекты в служба хранилища Azure или изменяя имена проектов в наборе навыков.
Если вы используете проекции таблиц, ознакомьтесь с моделью данных службы таблиц и целевыми показателями масштабируемости и производительности для хранилища таблиц, чтобы убедиться, что требования к данным находятся в пределах задокументированных ограничений хранилища таблиц.
Следующие шаги
Просмотрите синтаксис и примеры для каждого типа проекции.
Кері байланыс
Жақында қолжетімді болады: 2024 жыл бойы біз GitHub Issues жүйесін мазмұнға арналған кері байланыс механизмі ретінде біртіндеп қолданыстан шығарамыз және оны жаңа кері байланыс жүйесімен ауыстырамыз. Қосымша ақпаратты мұнда қараңыз: https://aka.ms/ContentUserFeedback.
Жіберу және пікірді көру