Шаблоны разработки для мультитенантных приложений SaaS и поиска искусственного интеллекта Azure
Мультитенантное приложение — это одно и то же приложение, которое предоставляет те же службы и возможности для любого количества клиентов, которые не могут просматривать или предоставлять общий доступ к данным любого другого клиента. В этой статье рассматриваются стратегии изоляции клиентов для мультитенантных приложений, созданных с помощью поиска ИИ Azure.
Основные понятия поиска ИИ Azure
В качестве решения поиска как службы поиск Azure ai позволяет разработчикам добавлять широкие возможности поиска в приложения без управления инфраструктурой или стать экспертом по получению информации. Данные передаются в службу и затем сохраняются в облаке. С помощью простых запросов к API поиска ИИ Azure данные можно изменить и выполнить поиск.
Службы поиска, индексы, поля и документы
Прежде чем обсуждать шаблоны проектирования, важно понять несколько основных понятий.
При использовании службы поиска ИИ Azure одна подписывается на службу поиска. По мере отправки данных в поиск ИИ Azure он хранится в индексе в службе поиска. В одной службе может существовать множество индексов. Чтобы оперировать привычными понятиями баз данных, службу поиска можно сравнить с базой данных, а индексы в службе — с таблицами в базе данных.
Каждый индекс в службе поиска имеет свою собственную схему, которая определяется рядом настраиваемых полей. Данные добавляются в индекс поиска ИИ Azure в виде отдельных документов. Каждый документ необходимо передать в определенный индекс, при этом данный документ должен соответствовать схеме индекса. При поиске данных с помощью поиска ИИ Azure запросы полнотекстового поиска выдаются по конкретному индексу. Чтобы провести аналогию этих понятий с базой данных, поля можно сравнить со столбцами в таблице, а документы — со строками.
Масштабируемость
Любой служба ИИ Azure в ценовой категории "Стандартный" может масштабироваться в двух измерениях: хранилище и доступность.
- секции для увеличения хранилища службы поиска.
- реплики .
Добавление и удаление секций и реплик в любое время позволяет увеличивать емкость службы поиска по мере роста объема данных и трафика, необходимых приложению. Чтобы служба поиска выполняла соглашение об уровне обслуживаниячтения, требуется две реплики. Чтобы служба поиска выполняла соглашение об уровне обслуживаниячтения и записи, требуется три реплики.
Ограничения служб и индексов в службе "Поиск ИИ Azure"
Существует несколько разных ценовых категорий в службе "Поиск ИИ Azure", каждый из уровней имеет разные ограничения и квоты. Некоторые из этих ограничений действуют на уровне службы, некоторые — на уровне индекса, а некоторые — на уровне секции.
S3, высокая плотность
В ценовой категории "Поиск ИИ Azure" S3 есть вариант для режима высокой плотности (HD), разработанный специально для мультитенантных сценариев. Во многих случаях необходимо поддерживать большое количество небольших клиентов в рамках одной службы, чтобы добиться преимущества простоты и экономичности.
Уровень S3 HD позволяет собрать множество небольших индексов под управлением отдельной службы поиска, жертвуя возможностью горизонтального увеличения масштаба индексов посредством секций ради возможности разместить большее число индексов в отдельной службе.
Служба S3 разработана для размещения фиксированного числа индексов (максимум 200) и позволяет масштабировать каждый индекс по горизонтали по мере добавления новых секций в службу. Добавление секций в службы S3 HD увеличивает максимальное количество индексов, которые может разместить служба. Идеальный максимальный размер для отдельного индекса S3HD составляет около 50 –80 ГБ, хотя для каждого индекса, введенного системой, не существует жесткого ограничения размера.
Рекомендации для мультитенантных приложений
Мультитенантные приложения должны эффективно распределять ресурсы между клиентами, сохраняя при этом определенный уровень конфиденциальности между различными клиентами. Существует несколько рекомендаций по проектированию архитектуры подобного приложения.
Изоляция клиентов. Разработчики приложений должны принять соответствующие меры, чтобы клиенты не имели возможности получить неавторизованный или нежелательный доступ к данным других клиентов. Помимо реализации конфиденциальности данных, стратегии изоляции клиентов требуют эффективного управления общими ресурсами и защиты от "шумных соседей".
Стоимость облачных ресурсов. Как и любое другое приложение, программные решения должны обладать конкурентоспособной ценой в составе мультитенантного приложения.
Простота эксплуатации. При разработке мультитенантной архитектуры важно учесть влияние на эксплуатацию и сложность приложения. Служба "Поиск ИИ Azure" имеет соглашение об уровне обслуживания на уровне 99,9 %.
Глобальный объем: мультитенантные приложения часто должны обслуживать клиентов, распределенных по всему миру.
Масштабируемость. Разработчики приложений должны решить, как сохранить относительно низкий уровень сложности приложения и спроектировать приложение, которое можно масштабировать, чтобы обслуживать множество клиентов с учетом их размера данных и рабочей нагрузки.
Поиск ИИ Azure предлагает несколько границ, которые можно использовать для изоляции данных и рабочих нагрузок клиентов.
Моделирование мультитенантности с помощью поиска ИИ Azure
В случае мультитенантного сценария разработчик приложений использует одну или несколько служб поиска и делит их клиентов между службами, индексами или обоими. Поиск ИИ Azure имеет несколько распространенных шаблонов при моделировании мультитенантного сценария:
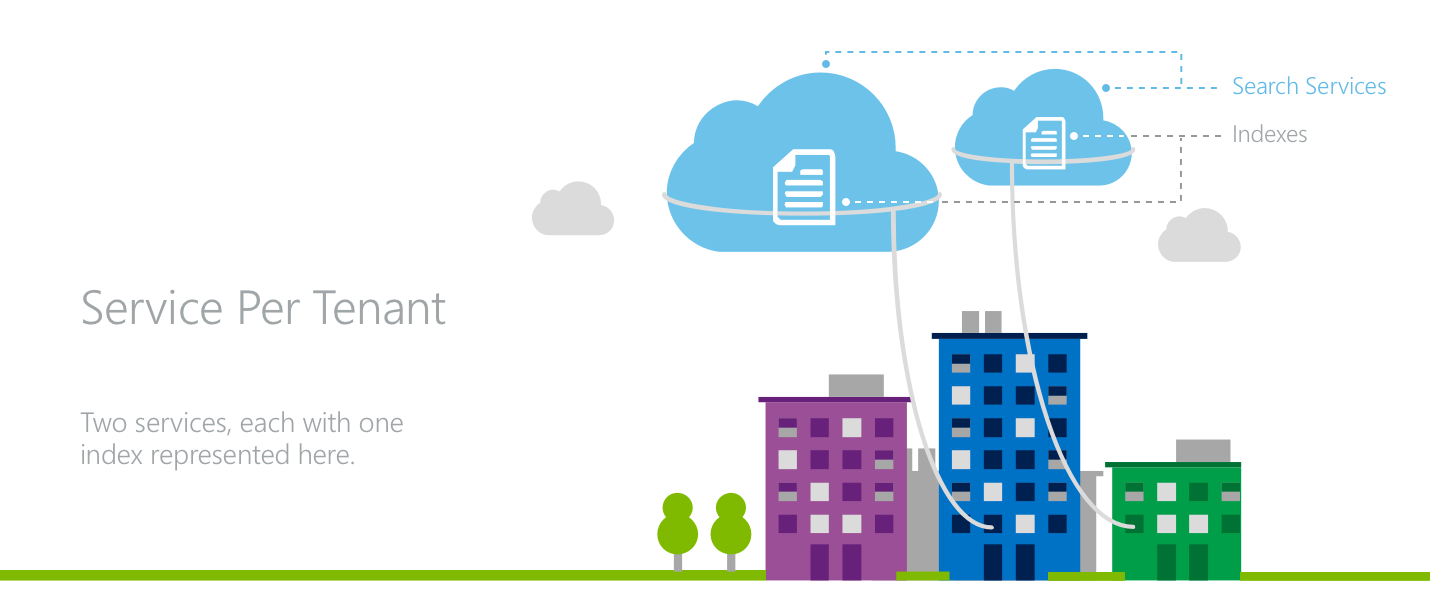
Один индекс на клиента. Каждый клиент имеет собственный индекс в службе поиска, используемой совместно с другими клиентами.
Одна служба для каждого клиента: каждый клиент имеет собственный выделенный служба ИИ Azure, предлагая высокий уровень разделения данных и рабочей нагрузки.
Сочетание обоих вариантов. Более активным клиентам большого размера назначаются выделенные службы, а небольшим клиентам назначаются отдельные индексы в общих службах.
Модель 1. Один индекс на клиента

В модели индекса для каждого клиента несколько клиентов занимают один служба ИИ Azure, где каждый клиент имеет собственный индекс.
Клиенты обеспечивают изоляцию данных, так как все поисковые запросы и операции с документами выдаются на уровне индекса в службе "Поиск ИИ Azure". На уровне приложений необходимо повысить осведомленность о том, чтобы направлять трафик различных клиентов к соответствующим индексам, а также управлять ресурсами на уровне обслуживания для всех клиентов.
Ключевой атрибут модели с индексом на каждого клиента заключается в том, что разработчик приложений может неравномерно распределить емкость службы поиска между подписанными на нее клиентами приложения. Если рабочая нагрузка неравномерно распределена между клиентами, то можно распределить оптимальное сочетание клиентов между индексами службы поиска, чтобы обслуживать ресурсоемкие высокоактивные клиенты, одновременно обслуживая длинную очередь менее активных клиентов. Недостаток модели заключается в том, что она не подходит для ситуаций, в которых все клиенты одновременно являются высокоактивными.
Модель индекса на клиент предоставляет основу для модели переменной стоимости, где весь служба искусственного интеллекта Azure приобретается заранее, а затем заполняется клиентами. Это позволяет выделить неиспользуемую емкость для пробных и бесплатных учетных записей.
Для приложений с глобальным объемом ресурсов модель индекса на клиент может оказаться не самой эффективной. Если клиенты приложения распределены по всему миру, отдельная служба может потребоваться для каждого региона, дублируя затраты на каждую из них.
Поиск ИИ Azure позволяет масштабировать как отдельные индексы, так и общее количество индексов. Если выбрана соответствующая ценовая категория, то во всю службу поиска можно будет добавить секции и реплики, когда какой-либо индекс в службе станет слишком большим с точки зрения потребляемых ресурсов хранения или трафика.
Если общее число индексов для одной службы становится слишком большим, то для обработки новых клиентов следует подготовить еще одну службу. Если индексы должны быть перемещены между службами поиска при добавлении новых служб, данные из индекса должны быть вручную скопированы из одного индекса в другой, так как поиск ИИ Azure не позволяет перемещать индекс.
Модель 2. Одна служба для каждого клиента
В архитектуре со службой на каждого клиента каждый клиент имеет свою собственную службу поиска.
В этой модели приложение обеспечивает максимальный уровень изоляции своих клиентов. Каждая служба имеет выделенное хранилище и пропускную способность для обработки запросов поиска. Каждый клиент имеет отдельное владение ключами API.
Для приложений, где каждый клиент имеет большое место или рабочая нагрузка имеет мало параметров от клиента к клиенту, модель обслуживания на клиент является эффективным выбором, так как ресурсы не используются для различных рабочих нагрузок клиентов.
Данная модель также дает преимущества модели с прогнозируемыми, фиксированными затратами. Нет дополнительных инвестиций в всю службу поиска до тех пор, пока не будет клиент, чтобы заполнить его, однако стоимость на клиента выше, чем модель индекса для каждого клиента.
Модель со службой на каждого клиента — удачный выбор для приложений, развертываемых по всему миру. С географически распределенными клиентами можно легко использовать службу каждого клиента в соответствующем регионе.
При такой схеме трудности масштабирования возникают, когда отдельным клиентам перестает хватать емкости их службы. Поиск по искусственному интеллекту Azure в настоящее время не поддерживает обновление ценовой категории службы поиска, поэтому все данные должны быть скопированы вручную в новую службу.
Модель 3. Гибридная
Еще один шаблон для моделирования мультитенантности подразумевает совмещение модели с индексом на каждый клиента и модели со службой на каждый клиент.
При совмещении двух шаблонов наибольшие клиенты приложения могут занимать выделенные службы, а длинная очередь менее активных клиентов меньшего размера может занимать индексы в общей службе. Эта модель обеспечивает наибольшим клиентам постоянную высокую производительность обслуживания службой, помогая при этом защитить небольшие клиенты от "шумных соседей".
Однако реализация этой стратегии зависит от предвидения в прогнозировании того, какие клиенты будут требовать выделенную службу и индекс в общей службе. Повышается сложность приложения, так как необходимо управлять обеими моделям мультитенантности.
Достижение большей степени детализации
Приведенные выше шаблоны проектирования для моделирования мультитенантных сценариев в службе "Поиск ИИ Azure" предполагают единую область, в которой каждый клиент является целым экземпляром приложения. Однако иногда приложения могут обрабатывать несколько областей меньшего размера.
Если модели для каждого клиента и индекса на клиент недостаточно небольшие области, можно моделировать индекс для достижения еще более детальной степени детализации.
Чтобы один индекс вел себя по-разному для разных конечных точек клиента, можно добавить поле в индекс, которое обозначает определенное значение для каждого возможного клиента. Каждый раз, когда клиент вызывает поиск ИИ Azure для запроса или изменения индекса, код из клиентского приложения задает соответствующее значение для этого поля с помощью возможности фильтрации поиска Azure в момент запроса.
Данный метод может использоваться для реализации отдельных учетных записей пользователей, отдельных уровней разрешений и даже полностью отдельных приложений.
Примечание.
Использование описанного выше подхода для настройки одного индекса, обслуживающего несколько клиентов, влияет на релевантность результатов поиска. Показатели релевантности поиска вычисляются на уровне индекса, а не на уровне клиента, поэтому все данные клиентов включаются в базовую статистику показателей релевантности (например, частота встречаемости термина).
Следующие шаги
Поиск по искусственному интеллекту Azure — это убедительный выбор для многих приложений. При оценке различных шаблонов проектирования для мультитенантных приложений следует учитывать различные ценовые категории и соответствующие ограничения служб, чтобы лучше всего адаптировать поиск ИИ Azure для соответствия рабочих нагрузок и архитектур приложений всех размеров.