Руководство. Оптимизация индексирования с помощью API push-уведомлений
Служба "Поиск ИИ Azure" поддерживает два основных подхода к импорту данных в индекс поиска: отправка данных в индекс программным способом или извлечение данных путем указания индексатора поиска ИИ Azure в поддерживаемом источнике данных.
В этом руководстве объясняется, как эффективно индексировать данные с помощью модели принудительной отправки путем пакетного запроса и использования экспоненциальной стратегии повторных попыток. Вы можете скачать и запустить пример приложения. В этой статье описываются ключевые аспекты приложения и факторы, которые следует учитывать при индексировании данных.
В этом руководстве используется C# и библиотека Azure.Search.Documents из пакета SDK Azure для .NET для выполнения следующих задач:
- Создание индекса
- Попробуйте разные размеры пакетов, чтобы выбрать наиболее эффективный вариант.
- Реализуйте асинхронное индексирование пакетов.
- Используйте несколько потоков для увеличения скорости индексирования.
- Реализуйте стратегию повторов с экспоненциальной задержкой для повторных попыток при неудачной обработке документов:
Необходимые компоненты
Для выполнения инструкций из этого руководства потребуются перечисленные ниже службы и инструменты.
Подписка Azure. Если ее нет, можно создать бесплатную учетную запись.
Visual Studio (любой выпуск). Пример кода и инструкции были протестированы с помощью бесплатного выпуска Community Edition.
Загрузка файлов
Исходный код для этого руководства находится в папке optimize-data-indexing/v11 в репозитории GitHub azure-samples/azure-search-dotnet-scale GitHub.
Основные рекомендации
Ниже перечислены факторы, влияющие на скорость индексирования. Дополнительные сведения см. в разделе "Индексирование больших наборов данных".
- Уровень служб и количество секций или реплик: добавление секций или обновление уровня увеличивает скорость индексирования.
- Сложность схемы индекса: добавление полей и свойств полей снижает скорость индексирования. Меньшие индексы быстрее индексируются.
- Размер пакета: оптимальный размер пакета зависит от схемы индекса и набора данных.
- Количество потоков или рабочих ролей: один поток не использует полные преимущества скорости индексирования.
- Стратегия повторных попыток: экспоненциальная стратегия повторных попыток является оптимальной практикой для оптимального индексирования.
- Скорость передачи данных в сети: скорость передачи данных может быть ограничивающим фактором. Чтобы увеличить скорость передачи данных, индексируйте данные из среды Azure.
Шаг 1. Создание служба искусственного интеллекта Azure
Для работы с этим руководством вам потребуется служба ИИ Azure, который можно создать в портал Azure или найти существующую службу в текущей подписке. Мы рекомендуем использовать тот же уровень, который планируется применять в рабочей среде, чтобы точнее оценить скорость индексирования и оптимизировать ее.
Получение ключа администратора и URL-адреса для поиска искусственного интеллекта Azure
В этом руководстве используется проверка подлинности на основе ключей. Скопируйте ключ API администратора для вставки в файл appsettings.json .
Войдите на портал Azure. Получите URL-адрес конечной точки на странице обзора службы поиска. Пример конечной точки может выглядеть так:
https://mydemo.search.windows.net.В разделе Параметры>Ключи получите ключ администратора, чтобы обрести полные права на службу. Существуют два взаимозаменяемых ключа администратора, предназначенных для обеспечения непрерывности бизнес-процессов на случай, если вам потребуется сменить один из них. Вы можете использовать первичный или вторичный ключ для выполнения запросов на добавление, изменение и удаление объектов.
Шаг 2. Настройка среды
Запустите Visual Studio и откройте файл OptimizeDataIndexing.sln.
В Обозреватель решений откройте appsettings.json для предоставления сведений о подключении службы.
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
Шаг 3. Изучение кода
Когда вы завершите обновление файла appsettings.json, пример программы в файле OptimizeDataIndexing.sln будет готов к компиляции и запуску.
Этот код является производным от раздела C# краткого руководства. Полнотекстовый поиск с помощью пакетов SDK Azure. В нем вы найдете более подробные сведения об основах работы с пакетом SDK для .NET.
Это простое консольное приложение для C#/.NET выполняет следующие задачи:
- Создает новый индекс на основе структуры данных класса C#
Hotel(который также ссылается наAddressкласс) - выполняет тесты с разными размерами пакетов, чтобы выбрать наиболее эффективный вариант;
- Индексирует данные асинхронно
- использует несколько потоков для увеличения скорости индексирования;
- применяет стратегию повторов с экспоненциальной задержкой, чтобы обрабатывать неудачные попытки.
Перед выполнением этой программы тщательно изучите ее код и определения индекса, созданные для этого примера. Соответствующий код находится в нескольких файлах:
- Hotel.cs и Address.cs содержат схему, определяющую индекс.
- DataGenerator.cs содержит простой класс, который облегчает создание данных об отелях в больших объемах;
- ExponentialBackoff.cs содержит код для оптимизации процесса индексирования, как описано в этой статье
- Program.cs содержит функции, которые создают и удаляют индекс поиска Azure AI, индексирует пакеты данных и проверяет различные размеры пакетов.
Создание индекса
В этом примере программы для .NET используется пакет SDK Azure для .NET для определения и создания индекса поиска ИИ Azure. Он использует преимущества FieldBuilder класса для создания структуры индекса из класса модели данных C#.
Модель данных определяется классом Hotel , который также содержит ссылки на Address класс. FieldBuilder углубляется в структуру определений нескольких классов, создавая на их основе сложную структуру данных для индекса. Теги метаданных применяются для определения атрибутов каждого поля, например сведений о поддержке поиска или сортировки.
Следующие фрагменты кода из файла Hotel.cs демонстрируют, как можно определить одно поле и ссылку на другой класс модели данных.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
В файле Program.cs для индекса определяется имя и коллекция полей, созданных методом FieldBuilder.Build(typeof(Hotel)), а затем этот индекс создается, как показано ниже:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Сформировать данные
В файле DataGenerator.cs реализован простой класс для создания тестовых данных. Единственным назначением этого класса является быстрое создание большого количества документов с уникальным идентификатором для последующего индексирования.
Чтобы получить список из 100 000 отелей с уникальными идентификаторами, выполните следующие строки кода:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Этот пример поддерживает два размера гостиниц для тестирования: small (маленькие) и large (большие).
Схема индекса влияет на скорость индексирования. По этой причине рекомендуется преобразовать этот класс для создания данных, которые лучше всего соответствуют предполагаемой схеме индекса после выполнения этого руководства.
Шаг 4. Тестирование размеров пакетов
Служба "Поиск ИИ Azure" поддерживает следующие API для загрузки одного или нескольких документов в индекс:
Индексирование документов в пакетах значительно повышает производительность индексирования. Эти пакеты могут составлять до 1000 документов или около 16 МБ на пакет.
Определение оптимального размера пакета для данных является ключевой задачей при оптимизации скорости индексирования. Существует два основных фактора, которые влияют на оптимальный размер пакета:
- схема индекса;
- размер данных.
Поскольку оптимальный размер пакета зависит от индекса и данных, лучше всего всегда проверять пакеты разных размеров, чтобы найти самый быстрый вариант индексирования для конкретного сценария.
В следующем примере функции показан простой подход к выполнению тестирования с пакетами разных размеров.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Обычно не все документы имеют одинаковый размер, как в нашем примере, поэтому нам нужно оценивать размер данных, отправляемых в службу поиска. Это можно сделать с помощью следующей функции, которая сначала преобразует объект в json, а затем определяет его размер в байтах. Этот метод позволяет определить наиболее эффективные размеры пакетов с точки зрения скорости индексирования (МБ/с).
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
Для функции требуется SearchClient плюс количество попыток, которые вы хотите протестировать для каждого размера пакета. Так как для каждого пакета может быть вариативность, попробуйте каждый пакет три раза по умолчанию сделать результаты более статистически значимыми.
await TestBatchSizesAsync(searchClient, numTries: 3);
При запуске функции вы увидите выходные данные в консоли, как показано в следующем примере:
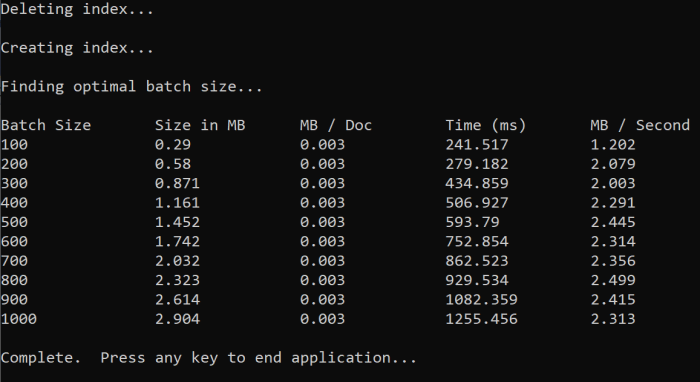
Найдите наиболее эффективный размер пакета и примените его на следующем шаге руководства. Вы можете увидеть плато в МБ/с в разных размерах пакета.
Шаг 5. Индексирование данных
Теперь, когда вы определили размер пакета, который вы планируете использовать, следующий шаг — начать индексировать данные. Для эффективного индексирования в этом примере применяется следующее:
- использует несколько потоков и рабочих ролей
- реализует экспоненциальную стратегию повторных попыток
Раскомментируйте строки 41–49, а затем повторно запустите программу. В этом запуске образец создает и отправляет пакеты документов до 100 000, если код выполняется без изменения параметров.
Использование нескольких потоков и рабочих ролей
Чтобы воспользоваться всеми преимуществами скорости индексирования поиска ИИ Azure, используйте несколько потоков для одновременной отправки запросов на индексирование пакетной службы.
Некоторые из ключевых соображений, упомянутых ранее, могут повлиять на оптимальное количество потоков. Вы можете изменить этот пример так, чтобы проверить работу с разным количеством потоков и выбрать оптимальный вариант для вашего сценария. Но обычно любое количество параллельных потоков позволяет добиться значительного повышения эффективности.
По мере увеличения запросов, поступающих в службу поиска, могут возникнуть коды состояния HTTP, указывающие, что запрос не полностью выполнен. При индексировании часто используются следующие два кода состояния HTTP:
- Служба 503 недоступна. Эта ошибка означает, что система находится под тяжелой нагрузкой, и ваш запрос не может обрабатываться в настоящее время.
- 207 Multi-Status: эта ошибка означает, что некоторые документы успешно выполнены, но по крайней мере один произошел сбой.
Реализация стратегии повторов с экспоненциальной задержкой
В случае сбоя следует повторить выполнение запроса, используя стратегию повторов с экспоненциальной задержкой.
Пакет SDK для .NET поиска Azure автоматически повторяет 503 и другие неудачные запросы, но следует реализовать собственную логику для повторных попыток 207. Средства с открытым исходным кодом, такие как Polly , могут быть полезны в стратегии повторных попыток.
В нашем примере есть собственная реализация стратегии повторов с экспоненциальной задержкой. Сначала мы определим некоторые переменные, включая maxRetryAttempts инициал delay для неудачного запроса:
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Результаты операции индексирования хранятся в переменной IndexDocumentResult result. Эта переменная важна, так как она позволяет проверить, завершилось ли сбой документов в пакете, как показано в следующем примере. Если произошел частичный сбой, создается новый пакет на основе идентификатора неудачных документов.
Следует также перехватывать исключения RequestFailedException, так как они указывают на полностью неудачное выполнение запроса и необходимость выполнить запрос повторно.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Отсюда оставьте экспоненциальный код обратной передачи в функцию, чтобы ее можно было легко вызвать.
Кроме того, создается еще одна функция для управления активными потоками. Для простоты мы не приводим здесь эту функцию, но вы можете найти ее в файле ExponentialBackoff.cs. Эту функцию можно вызвать с помощью следующей команды, где hotels — это данные для передачи, 1000 означает размер пакета, а 8 — количество параллельных потоков:
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
При запуске функции вы увидите выходные данные:

Если обработка пакета документов завершается ошибкой, выводится соответствующее сообщение с информацией о сбое и о применении повторной попытки:
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Когда функция завершит выполнение, вы можете убедиться, что все документы успешно добавлены в индекс.
Шаг 6. Изучение индекса
Вы можете изучить заполненный индекс поиска после выполнения программы программным способом или с помощью обозревателя поиска на портале.
Программный способ
Есть два основных метода проверки количества документов в индексе: API Count Documents и API Get Index Statistics. Оба пути требуют времени для обработки, поэтому не следует беспокоиться, если количество возвращенных документов изначально ниже, чем ожидалось.
Подсчет документов
Операция Count Documents возвращает количество документов в индексе поиска.
long indexDocCount = await searchClient.GetDocumentCountAsync();
Получение статистики индексов
Операция Get Index Statistics возвращает количество документов в текущем индексе, а также сведения об использовании хранилища. Статистика индексов занимает больше времени, чем количество документов для обновления.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Портал Azure
В портал Azure в области навигации слева и найдите индекс оптимизации индексирования в списке индексов.

Размер документа и количества документов основан на API получения статистики индекса и может занять несколько минут.
Сброс и повторный запуск
На ранних экспериментальных этапах разработки наиболее практический подход к итерации проектирования заключается в удалении объектов из службы "Поиск ИИ Azure" и их перестроении. Имена ресурсов являются уникальными. Удаление объекта позволяет воссоздать его с использованием того же имени.
Пример кода для этого руководства проверяет имеющиеся индексы и удаляет их, чтобы вы могли повторно выполнить этот код.
Также для удаления индексов можно использовать портал.
Очистка ресурсов
Если вы работаете в своей подписке, после завершения проекта целесообразно удалить созданные ресурсы, которые вам больше не потребуются. Ресурсы, которые продолжат работать, могут быть платными. Вы можете удалить ресурсы по отдельности либо удалить всю группу ресурсов.
Просматривать ресурсы и управлять ими можно на портале с помощью ссылок Все ресурсы или Группы ресурсов на панели навигации слева.
Следующий шаг
Дополнительные сведения об индексировании больших объемов данных см. в следующем руководстве.