Краткое руководство по преобразованию данных с помощью потоков данных для сопоставления
В этом кратком руководстве служба Azure Synapse Analytics будет использоваться для создания конвейера, который преобразует данные из источника Azure Data Lake Storage 2-го поколения (ADLS 2-го поколения) в приемник ADLS 2-го поколения с помощью потока данных для сопоставления. Шаблон конфигурации в этом кратком руководстве можно взять за основу для настройки преобразования данных с помощью потока данных для сопоставления.
При работе с этим кратким руководством вы выполните следующие действия:
- создание конвейера с использованием действия "Поток данных" в Azure Synapse Analytics;
- создание потока данных для сопоставления с четырьмя преобразованиями;
- тестовый запуск конвейера;
- Отслеживание действия "Поток данных"
Предварительные требования
Подписка Azure: Если у вас еще нет подписки Azure, создайте бесплатную учетную запись Azure, прежде чем начинать работу.
Рабочая область Azure Synapse: создайте рабочую область Synapse с помощью портала Azure, следуя инструкциям, приведенным в статье Краткое руководство по созданию рабочей области Synapse.
Учетная запись хранения Azure: для хранения данных источника и приемника используется хранилище ADLS. Если у вас нет учетной записи хранения, создайте ее, следуя действиям в этом разделе.
Файл, который мы будем преобразовывать в этом руководстве, MoviesDB.csv, можно найти здесь. Чтобы извлечь файл из GitHub, скопируйте его содержимое в свой текстовый редактор, чтобы сохранить его на локальном компьютере в виде CSV-файла. Сведения о передаче файла в учетную запись хранения см. в статье об отправке BLOB-объектов с помощью портала Azure. В примерах будет использоваться контейнер под названием Sample-Data.
Переход к Synapse Studio
После создания рабочей области Azure Synapse можно открыть Synapse Studio двумя способами:
- Откройте рабочую область Synapse на портале Azure. Выберите Открыть в Synapse Studio карта Открыть в разделе Начало работы.
- Откройте Azure Synapse Analytics и войдите в рабочую область.
Для целей этого краткого руководства в качестве примера мы используем рабочую область с именем adftest2020. При этом вы автоматически перейдете на домашнюю страницу Synapse Studio.

Создание конвейера с помощью действия "Поток данных"
Конвейер содержит логический поток для выполнения набора действий. В этом разделе будет создан конвейер, содержащий действие Потока данных.
Перейдите на вкладку Integrate (Интеграция). Нажмите значок плюса рядом с заголовком конвейеров и выберите "Конвейер".
На странице параметров Свойства конвейера введите в поле Имя значение TransformMovies.
В разделе Перемещение и преобразование на панели Действия перетащите элемент Поток данных на холст конвейера.
Во всплывающем окне Добавление потока данных выберите Создать новый поток данных ->Поток данных. Когда закончите, нажмите кнопку ОК.

Присвойте потоку данных имя TransformMovies на странице Свойства.
Встраивание логики преобразования в холст потока данных
После создания потока данных он будет автоматически отправлен на холст Потока данных. На этом шаге будет создан поток данных, который извлекает файл MoviesDB.csv из хранилища ADLS и вычисляет среднюю оценку комедий с 1910 по 2000 гг. Затем этот файл будет записан обратно в хранилище ADLS.
Установите ползунок Отладка потока данных над холстом потока данных в состояние "Вкл.". Режим отладки позволяет в интерактивном режиме тестировать логику преобразования в динамическом кластере Spark. Подготовка кластеров Потоков данных занимает 5–7 минут, поэтому пользователям рекомендуем сначала включить отладку, если планируется разработка Потока данных. Дополнительные сведения см. в статье Режим отладки.
На холсте потока данных добавьте источник, щелкнув поле Добавить источник.
Присвойте источнику имя MoviesDB. Нажмите Создать, чтобы создать новый набор данных источника.
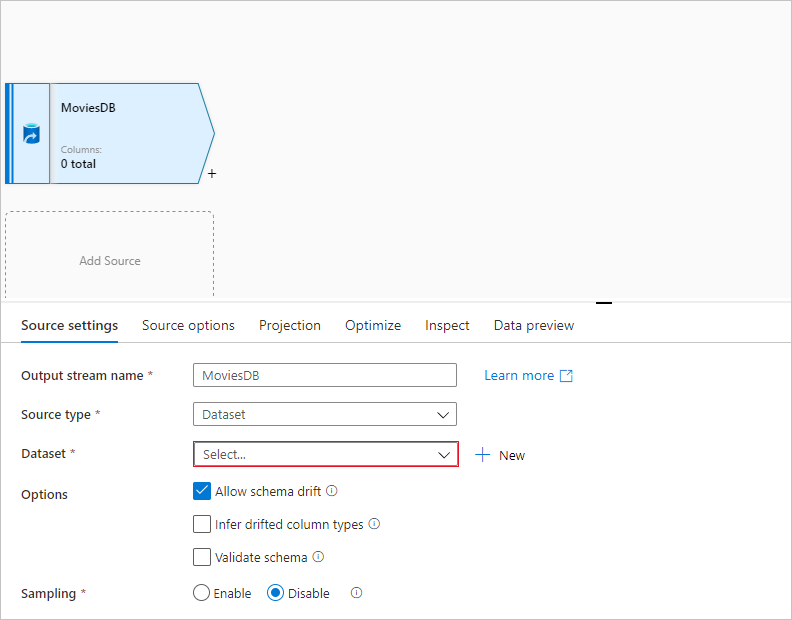
Выберите Azure Data Lake Storage 2-го поколения. Нажмите кнопку "Продолжить".

Выберите DelimitedText. Нажмите кнопку "Продолжить".
Присвойте набору данных имя MoviesDB. В раскрывающемся списке "Связанная служба" выберите Создать.
На экране создания связанной службы присвойте имя связанной службе ADLS 2-го поколения ADLSGen2 и укажите метод проверки подлинности. Затем введите учетные данные подключения. В этом кратком руководстве для подключения к нашей учетной записи хранения используется ключ учетной записи. Можно нажать кнопку Проверить подключение, чтобы проверить правильность ввода учетных данных. После завершения нажмите Создать.

Вернитесь на экран создания набора данных и в поле Путь к файлу укажите расположение файла. В этом кратком руководстве файл MoviesDB.csv находится в контейнере Sample-Data. Так как файл содержит заголовки, установите флажок Первая строка в качестве заголовка. Выберите Из подключения/хранилища, чтобы импортировать схему заголовка непосредственно из файла в хранилище. Когда закончите, нажмите кнопку ОК.

Если кластер отладки запущен, перейдите на вкладку Предварительный просмотр данных преобразования источника и нажмите кнопку Обновить, чтобы получить моментальный снимок данных. Предварительный просмотр данных дает возможность убедиться, что преобразование настроено правильно.

Щелкните значок "плюс" рядом с узлом источника на холсте потока данных, чтобы добавить новое преобразование. Первое добавляемое преобразование — Фильтр.

Назовите преобразование фильтра FilterYears. Щелкните поле "Выражение" рядом с полем Фильтр, чтобы открыть построитель выражений. Здесь нужно указать условие фильтрации.
Построитель выражений потока данных позволяет интерактивно создавать выражения для использования в различных преобразованиях. Выражения могут включать встроенные функции, столбцы из входной схемы и задаваемые пользователем параметры. Дополнительные сведения о построении выражений см. в статье Построитель выражений Потока данных.
В этом кратком руководстве будут отфильтрованы фильмы в жанре комедии, которые вышли в период между 1910 и 2000 годами. В связи с тем, что в настоящее время год является строкой, ее необходимо преобразовать в целое число с помощью функции
toInteger(). Используйте операторы "больше или равно" (>=) и "меньше или равно" (<=) для сравнения значений года с литералами 1910 и 200-. Объедините эти выражения с помощью оператора&&(и). Выражение будет выглядеть следующим образом:toInteger(year) >= 1910 && toInteger(year) <= 2000Чтобы узнать, какие фильмы являются комедиями, можно использовать функцию
rlike(), позволяющую найти слово "комедия" в жанрах столбца. Объедините выражениеrlikeс выражением сравнения года и получите следующее выражение:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')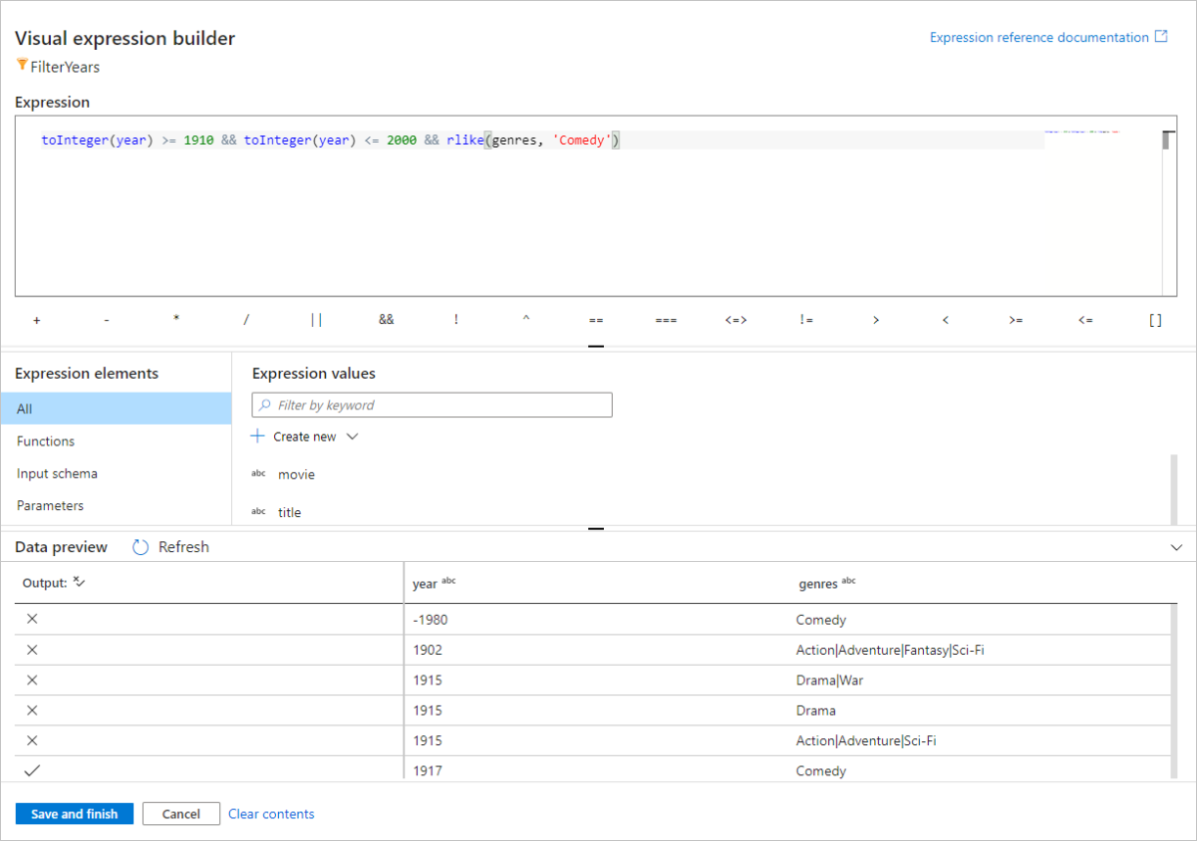
Если кластер отладки активен, можно проверить логику, нажав кнопку Обновить, чтобы увидеть результат выражения в сравнении с используемыми входными данными. Реализовать эту логику с помощью языка выражений потока данных можно разными способами.
После завершения работы с выражением нажмите кнопку Сохранить и завершить.
Загрузите результаты предварительного просмотра данных, чтобы убедиться, что фильтр работает правильно.
Следующее преобразование, которое необходимо добавить, — статистическая обработка в модификаторе схемы.

Назовите агрегатное преобразование AggregateComedyRatings. На вкладке Группировать по выберите год из раскрывающегося списка, чтобы сгруппировать агрегаты по году выхода фильма.

Перейдите на вкладку Статистическая обработка. В левом текстовом поле присвойте столбцу имя AverageComedyRating. Щелкните правой кнопкой мыши поле выражения, чтобы ввести выражение агрегирования с помощью построителя выражений.

Чтобы получить среднее значение столбца Оценка, используйте агрегатную функцию
avg(). Так как оценка является строковым значением, аavg()принимает числовые входные данные, необходимо преобразовать значение в число с помощью функцииtoInteger(). Это выражение выглядит следующим образом:avg(toInteger(Rating))После завершения нажмите Сохранить и завершить.

Перейдите на вкладку Предварительный просмотр данных, чтобы просмотреть выходные данные преобразования. Обратите внимание, что здесь есть только два столбца: year и AverageComedyRating.

Затем необходимо добавить преобразование Приемник в разделе Назначение.
Назовите приемник Sink. Нажмите Создать, чтобы создать набор данных приемника.
Выберите Azure Data Lake Storage 2-го поколения. Нажмите кнопку "Продолжить".
Выберите DelimitedText. Нажмите кнопку "Продолжить".
Назовите приемный набор данных MoviesSink. В качестве связанной службы выберите связанную службу ADLS 2-го поколения, созданную на шаге 7. Укажите выходную папку для записи данных. В этом кратком руководстве мы записываем данные в папку Output в контейнере Sample-Data. Папка не обязательно должна существовать заранее и может быть создана динамически. Задайте для параметра Использовать первую строку в качестве заголовка значение "истина" и выберите значение Нет для параметра Импорт схемы. Когда закончите, нажмите кнопку ОК.

Теперь создание потока данных завершено. Все готово для его запуска в конвейере.
Запуск и отслеживание Потока данных
Перед публикацией можно выполнить отладку конвейера. На этом шаге будет активирован запуск отладки конвейера Потока данных. При предварительном просмотре данных они не записываются, а в режиме отладки данные записываются в место назначения приемника.
Перейдите на холст конвейера. Нажмите кнопку Отладка, чтобы запустить отладку.

При отладке конвейера для действий потока данных используется активный кластер отладки, но инициализация по-прежнему займет не менее минуты. Ход выполнения можно отслеживать на вкладке Выходные данные. После успешного выполнения щелкните значок с очками, чтобы открыть область мониторинга.

В области мониторинга можно увидеть количество строк и время, затраченное на каждый шаг преобразования.

Щелкните преобразование, чтобы получить подробные сведения о столбцах и секционировании данных.

Если действия в этом кратком руководстве выполнены правильно, в папку приемника должны быть записаны 83 строки и 2 столбца. Данные можно проверить в хранилище BLOB-объектов.
Дальнейшие действия
Ознакомьтесь со следующими статьями, чтобы узнать о поддержке Azure Synapse Analytics: