Руководство. Создание определения задания Apache Spark в Synapse Studio
В этом учебнике показано, как использовать Synapse Studio для создания определений заданий Apache Spark и их отправки в бессерверный пул Apache Spark.
В рамках этого руководства рассматриваются следующие задачи:
- Создание определения задания Apache Spark для PySpark (Python)
- Создание определения задания Apache Spark для Spark (Scala)
- Создание определения задания Apache Spark для .NET Spark (C# или F#)
- Создание определения задания путем импорта JSON-файла
- Экспорт файла определения задания Apache Spark в локальную среду
- Отправка определения задания Apache Spark в виде пакетного задания
- Добавление определения задания Apache Spark в конвейер
Необходимые компоненты
Прежде чем приступить к изучению этого руководства, убедитесь, что выполнены следующие требования.
- Рабочая область Azure Synapse Analytics. См. руководство по созданию рабочей области Azure Synapse Analytics.
- Бессерверный пул Apache Spark.
- Учетная запись хранения ADLS 2-го поколения. Вам потребуется роль Участник для данных BLOB-объектов хранилища для файловой системы ADLS 2-го поколения, с которой вы хотите работать. Если у вас нет этой роли, добавьте разрешение вручную.
- Если вы не хотите использовать хранилище рабочей области по умолчанию, свяжите необходимую учетную запись хранения ADLS 2-го поколения с Synapse Studio.
Создание определения задания Apache Spark для PySpark (Python)
В этом разделе рассказывается о том, как создать определение задания Apache Spark для PySpark (Python).
Откройте Synapse Studio.
Вы можете перейти на страницу примеров файлов для создания определений заданий Apache Spark и скачать примеры файлов для python.zip, а затем распаковать сжатый пакет и извлечь файлы wordcount.py и shakespeare.txt.

Последовательно выберитеДанные ->Связанные ->Azure Data Lake Storage 2-го поколения и отправьте файлы wordcount.py и shakespeare.txt в файловую систему ADLS 2-го поколения.

Выберите центр Разработка, щелкните значок "+" и выберите пункт Spark job definition (Определение задания Spark), чтобы создать определение задания Spark.

В главном окне определения задания Apache Spark из раскрывающегося списка языков выберите PySpark (Python).

Введите сведения об определении задания Apache Spark.
Свойство Description Имя определения задания Введите имя определения задания Apache Spark. Это имя можно изменить в любое время до публикации.
Пример:job definition sampleОсновной файл определения Основной файл, используемый для задания. Выберите PY-файл в хранилище. Для отправки файла в учетную запись хранения можно выбрать Отправить файл.
Пример:abfss://…/path/to/wordcount.pyАргументы командной строки Дополнительные аргументы для задания.
Образец:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Примечание. Два аргумента для определения примера задания разделены пробелом.Файлы ссылок Дополнительные файлы, используемые для ссылки в основном файле определения. Для отправки файла в учетную запись хранения можно выбрать Отправить файл. Пул Spark Задание будет отправлено в выбранный пул Apache Spark. Версия Spark Версия Apache Spark, которая используется в пуле Apache Spark. Исполнители Количество исполнителей, которые будут предоставлены для задания в определенном пуле Apache Spark. Размер исполнителя Количество ядер и памяти, которые будут использоваться для исполнителей, предоставленных для задания в определенном пуле Apache Spark. Размер драйвера Количество ядер и объем памяти, которые будут использоваться для драйвера, предоставленного для задания в указанном пуле Apache Spark. Конфигурация Apache Spark Настройте конфигурации, добавив следующие свойства. Если вы не добавите свойство, Azure Synapse будет использовать значение по умолчанию, если применимо. 
Выберите Опубликовать, чтобы сохранить определение задания Apache Spark.

Создание определения задания Apache Spark для Apache Spark (Scala)
В этом разделе рассказывается о том, как создать определение задания Apache Spark для Apache Spark (Scala).
Откройте Azure Synapse Studio.
Вы можете перейти на страницу примеров файлов для создания определений заданий Apache Spark и скачать примеры файлов для scala.zip, а затем распаковать сжатый пакет и извлечь файлы wordcount.jar и shakespeare.txt.

Последовательно выберитеДанные ->Связанные ->Azure Data Lake Storage 2-го поколения и отправьте файлы wordcount.jar и shakespeare.txt в файловую систему ADLS 2-го поколения.

Выберите центр Разработка, щелкните значок "+" и выберите пункт Spark job definition (Определение задания Spark), чтобы создать определение задания Spark. (Пример изображения аналогичен примеру для шага 4 Создание определения задания Apache Spark для PySpark (Python).)
В главном окне определения задания Apache Spark из раскрывающегося списка языков выберите Spark (Scala).

Введите сведения об определении задания Apache Spark. Пример сведений можно скопировать.
Свойство Description Имя определения задания Введите имя определения задания Apache Spark. Это имя можно изменить в любое время до публикации.
Пример:scalaОсновной файл определения Основной файл, используемый для задания. Выберите JAR-файл в хранилище. Для отправки файла в учетную запись хранения можно выбрать Отправить файл.
Пример:abfss://…/path/to/wordcount.jarИмя главного класса Полный идентификатор или основной класс, который находится в основном файле определения.
Пример:WordCountАргументы командной строки Дополнительные аргументы для задания.
Образец:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Примечание. Два аргумента для определения примера задания разделены пробелом.Файлы ссылок Дополнительные файлы, используемые для ссылки в основном файле определения. Для отправки файла в учетную запись хранения можно выбрать Отправить файл. Пул Spark Задание будет отправлено в выбранный пул Apache Spark. Версия Spark Версия Apache Spark, которая используется в пуле Apache Spark. Исполнители Количество исполнителей, которые будут предоставлены для задания в определенном пуле Apache Spark. Размер исполнителя Количество ядер и памяти, которые будут использоваться для исполнителей, предоставленных для задания в определенном пуле Apache Spark. Размер драйвера Количество ядер и объем памяти, которые будут использоваться для драйвера, предоставленного для задания в указанном пуле Apache Spark. Конфигурация Apache Spark Настройте конфигурации, добавив следующие свойства. Если вы не добавите свойство, Azure Synapse будет использовать значение по умолчанию, если применимо. 
Выберите Опубликовать, чтобы сохранить определение задания Apache Spark.

Создание определения задания Apache Spark для .NET Spark (C# или F#)
В этом разделе рассказывается о том, как создать определение задания Apache Spark для .NET Spark (C# или F#).
Откройте Azure Synapse Studio.
Вы можете перейти на страницу примеров файлов для создания определений заданий Apache Spark и скачать примеры файлов для dotnet.zip, а затем распаковать сжатый пакет и извлечь файлы wordcount.zip и shakespeare.txt.

Последовательно выберитеДанные ->Связанные ->Azure Data Lake Storage 2-го поколения и отправьте файлы wordcount.zip и shakespeare.txt в файловую систему ADLS 2-го поколения.

Выберите центр Разработка, щелкните значок "+" и выберите пункт Spark job definition (Определение задания Spark), чтобы создать определение задания Spark. (Пример изображения аналогичен примеру для шага 4 Создание определения задания Apache Spark для PySpark (Python).)
В главном окне определения задания Apache Spark из раскрывающегося списка языков выберите .NET Spark (C#/F#).

Введите сведения об определении задания Apache Spark. Пример сведений можно скопировать.
Свойство Description Имя определения задания Введите имя определения задания Apache Spark. Это имя можно изменить в любое время до публикации.
Пример:dotnetОсновной файл определения Основной файл, используемый для задания. Выберите из хранилища ZIP-файл, содержащий приложение .NET для Apache Spark (то есть основной исполняемый файл, библиотеки DLL с пользовательскими функциями и другие необходимые файлы). Для отправки файла в учетную запись хранения можно выбрать Отправить файл.
Пример:abfss://…/path/to/wordcount.zipОсновной исполняемый файл Основной исполняемый файл — это основной ZIP-файл определения.
Пример:WordCountАргументы командной строки Дополнительные аргументы для задания.
Образец:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Примечание. Два аргумента для определения примера задания разделены пробелом.Файлы ссылок Дополнительные файлы, необходимые рабочим узлам для запуска приложения .NET для Apache Spark, не включенные в основной ZIP-файл определения (то есть зависимые JAR-файлы, дополнительные библиотеки DLL с пользовательскими функциями и другие файлы конфигурации). Для отправки файла в учетную запись хранения можно выбрать Отправить файл. Пул Spark Задание будет отправлено в выбранный пул Apache Spark. Версия Spark Версия Apache Spark, которая используется в пуле Apache Spark. Исполнители Количество исполнителей, которые будут предоставлены для задания в определенном пуле Apache Spark. Размер исполнителя Количество ядер и памяти, которые будут использоваться для исполнителей, предоставленных для задания в определенном пуле Apache Spark. Размер драйвера Количество ядер и объем памяти, которые будут использоваться для драйвера, предоставленного для задания в указанном пуле Apache Spark. Конфигурация Apache Spark Настройте конфигурации, добавив следующие свойства. Если вы не добавите свойство, Azure Synapse будет использовать значение по умолчанию, если применимо. 
Выберите Опубликовать, чтобы сохранить определение задания Apache Spark.

Примечание.
Если в конфигурации Apache Spark определение задания Apache Spark не выполняет никаких специальных действий, то при выполнении задания будет использоваться конфигурация по умолчанию.
Создание определения задания Apache Spark путем импорта JSON-файла
Вы можете импортировать существующий локальный файл JSON в рабочую область Azure Synapse с помощью меню Действия (...) в обозревателе определений заданий Apache Spark, чтобы создать новое определение задания Apache Spark.

Определение задания Spark полностью совместимо с API Livy. Вы можете добавить параметры для других свойств Livy (документация по Livy, раздел о REST API (apache.org)) в локальный JSON-файл. Можно также указать параметры, связанные с конфигурацией Spark, в соответствующем свойстве, как показано ниже. Затем можно импортировать JSON-файл обратно, чтобы создать новое определение для пакетного задания Apache Spark. Пример JSON для импорта определения Spark:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
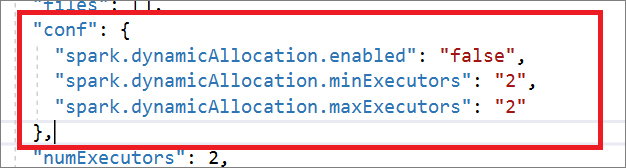
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
Экспорт существующего файла определения задания Apache Spark
Можно экспортировать существующие файлы определений заданий Apache Spark в локальную среду с помощью меню Действия (...) в проводнике. При необходимости вы можете обновить такой JSON-файл, добавив в него свойства Livy, и импортировать его обратно для создания нового определения задания.


Отправка определения задания Apache Spark в виде пакетного задания
Созданное определение задания Apache Spark можно отправить в пул Apache Spark. Убедитесь, что у вас есть роль Участник для данных BLOB-объектов хранилища для файловой системы ADLS 2-го поколения, с которой вы хотите работать. Если у вас нет этой роли, добавьте разрешение вручную.
Сценарий 1. Отправка определения задания Apache Spark
Откройте окно определения задания Apache Spark, выбрав его.

Нажмите кнопку Отправить, чтобы отправить проект в выбранный пул Apache Spark. Вы можете щелкнуть вкладку Spark monitoring URL (URL-адрес мониторинга Spark), чтобы просмотреть LogQuery приложения Apache Spark.


Сценарий 2. Просмотр выполнения задания Apache Spark
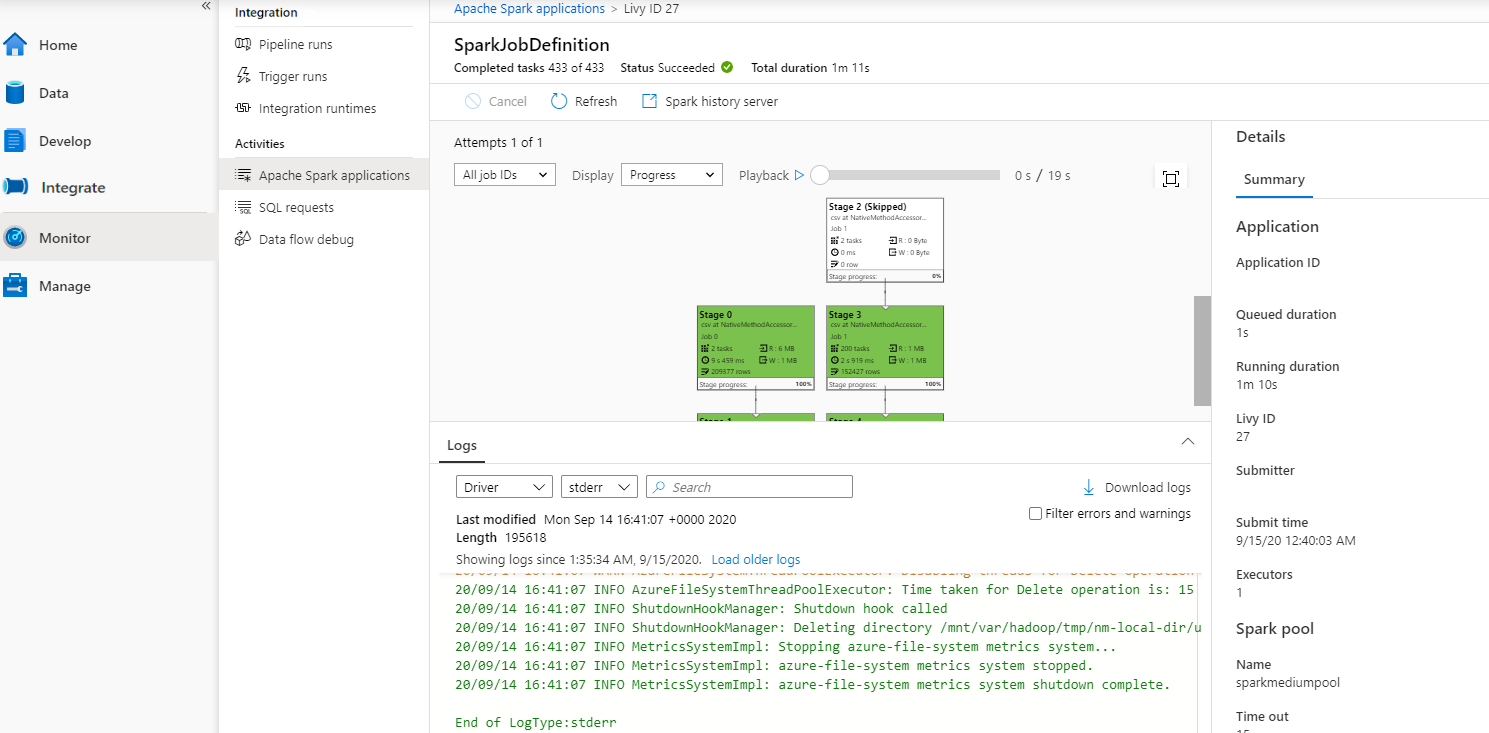
Щелкните Монитор и выберите параметр Apache Spark applications (Приложения Apache Spark). В списке будет отправленное приложение Apache Spark.

Затем выберите приложение Apache Spark, которое отображается в окне задания SparkJobDefinition. В этом окне можно просмотреть ход выполнения задания.
Сценарий 3. Проверка выходного файла
Последовательно выберите Данные ->Связанные ->Azure Data Lake Storage 2-го поколения (hozhaobdbj), откройте созданную ранее папку результатов, в которой можно просмотреть, созданы ли выходные данные.

Добавление определения задания Apache Spark в конвейер
В этом сценарии определение задания Apache Spark добавляется в конвейер.
Откройте имеющееся определение задания Apache Spark.
Щелкните значок в правом верхнем углу определения задания Apache Spark, выберите Existing Pipeline (Имеющийся конвейер) или New pipeline (Новый конвейер). Дополнительные сведения см. на странице Pipeline (Конвейер).


Следующие шаги
Далее вы можете использовать Azure Synapse Studio для создания наборов данных Power BI и управления такими данными. Дополнительные сведения см. в статье Краткое руководство. Связывание рабочей области Power BI с рабочей областью Synapse.