Использование OPENROWSET с бессерверным пулом SQL в Azure Synapse Analytics
Функция OPENROWSET(BULK...) позволяет получить доступ к файлам в службе хранилища Azure. Функция OPENROWSET считывает содержимое удаленного источника данных (например, файла) и возвращает содержимое в виде набора строк. В ресурсе бессерверного пула SQL доступ к поставщику больших наборов строк OPENROWSET осуществляется путем вызова функции OPENROWSET и указанием параметра BULK.
Из предложения FROM запроса можно ссылаться на функцию OPENROWSET, как если бы это было имя таблицы OPENROWSET. Функция также поддерживает массовые операции с помощью встроенного поставщика BULK, позволяющего считывать данные из файла и возвращать их в виде набора строк.
Примечание.
Функция OPENROWSET не поддерживается в выделенном пуле SQL.
Источник данных
Функция OPENROWSET в Synapse SQL считывает содержимое файлов из источника данных. Источник данных — это учетная запись хранения Azure, которую можно явно указать в функции OPENROWSET или динамически выводить из URL-адреса файлов, которые вы намерены считать.
Функция OPENROWSET может содержать необязательный параметр DATA_SOURCE для указания источника данных с нужными файлами.
OPENROWSETбезDATA_SOURCEпозволяет считать содержимого файлов напрямую по URL-адресу, указанному в параметреBULK:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Это быстрый и простой способ считать содержимое файлов без предварительной настройки. Этот параметр позволяет использовать базовый параметр проверки подлинности для доступа к хранилищу (сквозное руководство Microsoft Entra для входа Microsoft Entra и маркер SAS для входа SQL).
OPENROWSETсDATA_SOURCEможно использовать для доступа к файлам в указанной учетной записи хранения:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Этот параметр позволяет настроить расположение учетной записи хранения в источнике данных и указать метод проверки подлинности, который должен использоваться для доступа к хранилищу.
Важно!
OPENROWSETбезDATA_SOURCEобеспечивает быстрый и простой способ доступа к файлам хранилища, но поддерживает мало возможностей для проверки подлинности. Например, субъекты Microsoft Entra могут получать доступ к файлам только с помощью удостоверения Microsoft Entra или общедоступных файлов. Если вам нужны более мощные возможности для проверки подлинности, используйте параметрDATA_SOURCEи определите учетные данные, которые нужно использовать для доступа к хранилищу.
Безопасность
Пользователь базы данных должен иметь разрешение ADMINISTER BULK OPERATIONS, чтобы использовать функцию OPENROWSET.
Администратор хранилища также должен предоставить пользователю доступ к файлам, предоставив действительный маркер SAS или предоставив субъекту Microsoft Entra доступ к файлам хранилища. Узнайте больше об управлении доступом к хранилищу в этой статье.
OPENROWSET использует следующие правила, чтобы выбрать способ проверки подлинности в хранилище:
- В
OPENROWSETбезDATA_SOURCEмеханизм проверки подлинности зависит от типа вызывающего объекта.- Любой пользователь может использовать
OPENROWSETбезDATA_SOURCE, чтобы считывать общедоступные файлы в службе хранилища Azure. - Имена входа Microsoft Entra могут получить доступ к защищенным файлам с помощью собственного удостоверения Microsoft Entra, если хранилище Azure позволяет пользователю Microsoft Entra получить доступ к базовым файлам (например, если вызывающий объект имеет
Storage Readerразрешение на хранилище Azure). - Для имен входа SQL также можно использовать
OPENROWSETбезDATA_SOURCEдля доступа к общедоступным файлам, защищенным с помощью маркера SAS файлам и управляемым удостоверениям рабочей области Synapse. Чтобы разрешить доступ к файлам хранилища, необходимо создать учетные данные уровня сервера.
- Любой пользователь может использовать
- В
OPENROWSETсDATA_SOURCEмеханизм проверки подлинности определяется в учетных данных уровня базы данных, которые назначены указанному источнику данных. Этот параметр позволяет получить доступ к общедоступному хранилищу или получить доступ к хранилищу с помощью маркера SAS, управляемого удостоверения рабочей области или удостоверения вызывающего объекта Microsoft Entra (если вызывающий объект является субъектом Microsoft Entra). ЕслиDATA_SOURCEссылается на хранилище Azure, которое не является общедоступным, придется создать учетные данные уровня базы данных и указать их вDATA SOURCE, чтобы разрешить доступ к файлам хранилища.
Вызывающий объект должен иметь разрешение REFERENCES для этих учетных данных, чтобы использовать их для проверки подлинности в хранилище.
Синтаксис
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Аргументы
У вас есть три варианта входных файлов, содержащих целевые данные для запроса. Допустимые значения:
"CSV" — включает любой текстовый файл с разделителями (разделители строк и столбцов). В качестве разделителя полей можно использовать любой символ, например TSV: FIELDTERMINATOR = знак табуляции.
"PARQUET" — двоичный файл в формате Parquet.
'DELTA' - набор файлов Parquet, организованных в формате Delta Lake (предварительная версия)
Значения с пустыми пробелами недопустимы, например CSV не является допустимым значением.
unstructured_data_path
Аргумент unstructured_data_path, который определяет путь к данным, может содержать абсолютный или относительный путь:
- Абсолютный путь в формате
\<prefix>://\<storage_account_path>/\<storage_path>позволяет пользователю напрямую читать файлы. - Относительный путь в формате
<storage_path>, который нужно использовать с параметромDATA_SOURCE, описывает шаблон имени файла в расположении <путь_к_учетной_записи_хранения>, которое определено вEXTERNAL DATA SOURCE.
Ниже приведены соответствующие <пути к учетной записи хранения>, которые будут связаны с конкретным внешним источником данных.
| Внешний источник данных | Префикс | Путь к учетной записи хранения |
|---|---|---|
| Хранилище BLOB-объектов Azure | http(s) | <учетная_запись_хранения>.blob.core.windows.net/path/file |
| Хранилище BLOB-объектов Azure | wasb(s) | <контейнер>@<учетная_запись_хранения>.blob.core.windows.net/path/file |
| Azure Data Lake Store 1-го поколения | http(s) | <учетная_запись_хранения>.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store 2-го поколения | http(s) | <учетная_запись_хранения>.dfs.core.windows.net /path/file |
| Azure Data Lake Store 2-го поколения | abfs(s) | <файловая_система>@<учетная_запись_хранения>.dfs.core.windows.net/path/file |
'<путь_к_хранилищу>'
Позволяет задать путь в хранилище, указывающий на папку или файл, который нужно считать. Если путь указывает на контейнер или папку, все файлы будут считываться только из этого контейнера или папки. Файлы во вложенных папках не включаются.
Для выбора нескольких файлов или папок можно использовать подстановочные знаки. Допускается использование нескольких подстановочных знаков, если они размещены не подряд.
Ниже приведен пример для считывания всех файлов .csv, в начале имени которых указано population, из всех папок, в начале имени которых указано /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Если указать, что unstructured_data_path является папкой, тогда запрос бессерверного пула SQL будет извлекать файлы из этой папки.
Вы можете настроить бессерверный пул SQL, так чтобы он перемещался по папкам, указав /* в конце пути, как показано в примере: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Примечание.
В отличие от Hadoop и PolyBase бессерверный пул SQL не возвращает вложенные папки, если в конце пути не указано /**. Как и Hadoop и PolyBase, он не возвращает файлы, имя которых начинается с подчеркивания (_) или точки (.).
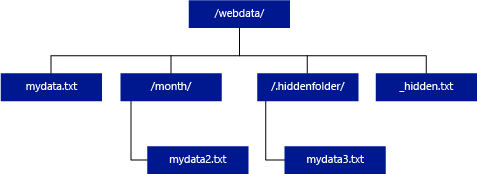
Если в приведенном ниже примере unstructured_data_path = https://mystorageaccount.dfs.core.windows.net/webdata/, после обращения в бессерверный пул SQL будут возвращены строки из mydata.txt. Файлы mydata2.txt и mydata3.txt не возвращаются, так как они находятся во вложенной папке.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
Предложение WITH позволяет указать столбцы, которые нужно считать из файлов.
Для чтения всех столбцов в файлах данных CSV укажите имена столбцов и их типы данных. Если нужно считать подмножество столбцов, используйте порядковые номера, чтобы выбрать столбцы из исходных файлов данных по порядковому номеру. Столбцы будут привязаны к порядковым обозначениям. Если использовать значение HEADER_ROW = TRUE, привязка к столбцу будет выполнена по его имени, а не по порядковому номеру.
Совет
Вы также можете опустить предложение WITH для CSV-файлов. Типы данных будут автоматически выводиться из содержимого файла. Аргумент HEADER_ROW можно использовать для указания существования строки заголовка. Тогда имена столбцов регистра будут считываться из этой строки заголовка. Узнайте больше об автоматическом обнаружении схемы.
Для файлов Parquet или Delta Lake укажите имена столбцов, которые соответствуют именам столбцов в исходных файлах данных. Столбцы будут связаны по имени и чувствительны к регистру. Если предложение WITH не указано, возвращаются все столбцы из файлов Parquet.
Важно!
Имена столбцов в файлах Parquet и Delta Lake чувствительны к регистру. Если вы укажете имя столбца с регистром, отличным от регистра имени столбца в файлах, для данного столбца будут возвращены значения
NULL.
column_name (имя_столбца) = имя выходного столбца. Если значение указано, это имя переопределяет имя столбца в исходном файле и имя столбца, указанное в пути JSON (если применимо). Если аргумент json_path не указан, он будет автоматически добавлен как $.column_name. Проверьте поведение аргумента json_path.
column_type (тип_столбца) = тип данных в выходном столбце. Выполняется неявное преобразование типов данных.
column_ordinal (порядковый_номер_столбца) = порядковый номер столбца в исходных файлах. Этот аргумент не учитывается для файлов Parquet, так как привязка выполняется по имени. В следующем примере из CSV-файла будет возвращен только второй столбец:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = выражение пути JSON к столбцу или вложенному свойству. Режим пути по умолчанию является нестрогим.
Примечание.
В строгом режиме выполнение запроса завершится сбоем, если указанный путь не существует. В нестрогом режиме запрос будет выполнен, и выражение пути JSON получит значение NULL.
<параметры_массовых_операций>
FIELDTERMINATOR ='признак_конца_поля'
Указывает признак конца поля, который нужно использовать. Признак конца поля по умолчанию — запятая (",").
ROWTERMINATOR ='признак_конца_строки'`
Указывает признак конца строки, который нужно использовать. Если признак конца строки не указан, будет использоваться один из признаков конца строки по умолчанию. По умолчанию для версии PARSER_VERSION = "1.0" используются признаки \r\n, \n и \r. По умолчанию для версии PARSER_VERSION = "2.0" используются признаки \r\n и \n.
Примечание.
Если при использовании PARSER_VERSION='1.0' в качестве признака конца строки задан знак \n (перевод строки), к нему автоматически добавляется префикс \r (возврат каретки), в результате чего формируется признак конца строки \r\n.
ESCAPE_CHAR = 'char'
Задает символ в файле, используемый для экранирования собственно этого символа и всех значений разделителей в файле. Если за escape-символом следует значение, отличное от него самого или какого-либо из значений разделителей, при считывании этого значения escape-символ пропускается.
Параметр ESCAPECHAR будет применяться независимо от того, включен ли параметр FIELDQUOTE. Он не будет использоваться для экранирования символа кавычек. Символ кавычек нужно экранировать другим символом кавычек. Такой символ может использоваться в значении столбца только в том случае, если значение инкапсулировано с помощью символов кавычек.
FIRSTROW = 'first_row' (первая_строка)
Указывает номер первой строки для загрузки. Значение по умолчанию — 1. Оно указывает на первую строку в используемом файле данных. Номера строк определяются с помощью подсчета признаков конца строки. Значения аргумента FIRSTROW начинаются с 1.
FIELDQUOTE = "field_quote"
Определяет символ, который будет использоваться в качестве символа кавычки в CSV-файле. Если значение не указано, будут использоваться текущий символ кавычек (").
DATA_COMPRESSION = "метод_cжатия_данных"
Позволяет указать метод сжатия. Поддерживается только в PARSER_VERSION = "1.0". Поддерживается следующий метод сжатия:
- GZIP
PARSER_VERSION = "версия_средства_синтаксического_анализа"
Позволяет указать версию средства синтаксического анализа, которая используется при чтении файлов. В настоящее время поддерживаются версии 1.0 и 2.0 средства синтаксического анализа для CSV-файлов.
- PARSER_VERSION = "1.0"
- PARSER_VERSION = "2.0"
Средство синтаксического анализа для CSV-файлов версии 1.0 обладает широким набором функций и используется по умолчанию, а версия 2.0 оптимизирована для производительности и поддерживает не все параметры и кодировки.
Особенности средства синтаксического анализа CSV версии 1.0:
- Следующие параметры не поддерживаются: HEADER_ROW.
- По умолчанию используются признаки \r\n, \n и \r.
- Если в качестве признака конца строки задан знак \n (перевод строки), к нему автоматически добавляется префикс \r (возврат каретки), в результате чего формируется признак конца строки \r\n.
Особенности средства синтаксического анализа для CSV-файлов версии 2.0:
- Поддерживаются не все типы данных.
- Максимальная длина символьного столбца — 8000.
- Размер строки не может превышать 8 МБ.
- Следующие параметры не поддерживаются: DATA_COMPRESSION.
- Пустая строка в кавычках ("") интерпретируется как пустая строка.
- Параметр SET DATEFORMAT не учитывается.
- Поддерживаемый формат для типа данных DATE: ГГГГ-ММ-ДД
- Поддерживаемый формат для типа данных TIME: HH:MM:SS[.fractional seconds]
- Поддерживаемый формат для типа данных DATETIME2: ГГГГ-ММ-ДД HH:MM:SS[.дробные секунды]
- По умолчанию используются признаки \r\n и \n.
HEADER_ROW = { TRUE | FALSE }
Указывает, содержит ли CSV-файл строку заголовка. По умолчанию FALSE. поддерживается в PARSER_VERSION='2.0'. Если установлено значение TRUE, имена столбцов будут считываться из первой строки в соответствии с аргументом FIRSTROW. Если значение равно TRUE и схема указана с помощью предложения WITH, привязка имен столбцов будет выполняться по именам столбцов, а не по их порядковым номерам.
DATAFILETYPE = { 'char' | 'widechar' }
Указывает на кодировку: char используется для файлов UTF8, а widechar — для файлов UTF16.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Указывает кодовую страницу данных в файле данных. Значение по умолчанию — 65001 (кодировка UTF-8). Дополнительные сведения об этом параметре доступны здесь.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Этот параметр позволяет отключить проверку изменения файлов во время выполнения запроса и считать файлы, которые обновляются во время выполнения запроса. Такая возможность полезна, если нужно считать файлы только для добавления, добавленные во время выполнения запроса. В добавляемых файлах существующее содержимое не обновляется, только добавляются новые строки. Таким образом, вероятность неверного результата сводится к минимуму по сравнению с обновляемыми файлами. Этот параметр позволяет считывать часто добавляемые файлы без обработки ошибок. Дополнительные сведения см. в разделе Запросы к добавляемым CSV-файлам.
Параметры отклонения
Примечание.
Функция отклоненных строк доступна в виде общедоступной предварительной версии. Обратите внимание, что она работает с текстовыми файлами с разделителями и параметром средства анализа PARSER_VERSION со значением версии 1.0.
Вы можете указать параметры отклонения, определяющие, как служба будет обрабатывать грязные записи, полученные из внешнего источника данных. Запись считается "грязной", если фактические типы данных не соответствует определениям столбцов во внешней таблице.
Если вы не укажете или не измените значения отклонения, служба будет использовать значения по умолчанию. Служба будет применять параметры отклонения, чтобы определить количество строк, которые могут быть отклонены, прежде чем произойдет сбой самого запроса. Запрос будет возвращать (частичные) результаты, пока не будет превышено пороговое значение отклонения. Затем он выдаст соответствующее сообщение об ошибке.
MAXERRORS = значение_отклонения
Указывает количество строк, которые могут быть отклонены, прежде чем произойдет сбой запроса. Это должно быть целое число от 0 до 2 147 483 647.
ERRORFILE_DATA_SOURCE = источник_данных
Указывает источник данных, в котором должны записываться отклоненные строки и соответствующий файл ошибок.
ERRORFILE_LOCATION = расположение_каталога
Указывает каталог в источнике_данных, или ERROR_FILE_DATASOURCE, куда должны записываться отклоненные строки и соответствующий файл ошибок. Если расположение по указанному пути не существует, служба создаст его от вашего имени. Дочерний каталог создается с именем "отклоненные". Символ "" гарантирует, что каталог экранируется для другой обработки данных, если не указано явно в параметре расположения. В этом каталоге создается папка, имя которой соответствует времени отправки загруженных данных. Оно имеет следующий формат: "ГодМесяцДень-ЧасМинутаСекунда-ИдентификаторИнструкции" (например, 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Вы можете использовать идентификатор инструкции, чтобы сопоставить папку с запросом, в результате которого она была создана. В этой папке записываются два файла: error.json и файл данных.
Файл error.json содержит массив JSON с обнаруженными ошибками, связанными с отклоненными строками. Каждый элемент, представляющий ошибку, имеет следующие атрибуты:
| Атрибут | Description |
|---|---|
| Ошибка | Причина, по которой строка отклонена. |
| Row | Порядковый номер отклоненной строки в файле. |
| Column | Порядковый номер отклоненного столбца. |
| Значение | Значение отклоненного столбца. Если длина значения превышает 100 символов, будут показаны только первые 100. |
| Файл | Путь к файлу, которому принадлежит строка. |
Быстрый синтаксический анализ текста с разделителями
Можно использовать две версии средства синтаксического анализа текста с разделителями. Средство синтаксического анализа CSV-файла версии 1.0 является стандартным и изначально имеет больше возможностей, а средство синтаксического анализа версии 2.0 создано для повышения производительности. Улучшение производительности в средстве синтаксического анализа версии 2.0 создается за счет расширенных техник синтаксического анализа и многопоточности. С увеличением размера файла также будет увеличиваться разница в скорости.
Автоматическое обнаружение схем
Файлы CSV и Parquet можно запрашивать, не зная и не указывая схему, опустив предложение WITH. Имена столбцов и типы данных будут выводиться из файлов.
Файлы Parquet содержат метаданные столбцов, которые считываются. Сопоставления типов можно найти в разделе Сопоставление типов для Parquet. Проверьте считывание файлов Parquet без указания схем для выборки.
Имена столбцов для CSV-файлов можно считывать из строки заголовка. Можно указать, существует ли строка заголовка, с помощью аргумента HEADER_ROW. Если HEADER_ROW = FALSE, будут использоваться универсальные имена столбцов: C1, C2, ... Cn where n — число столбцов в файле. Типы данных будут выводиться из первых 100 строк данных. Проверьте считывание CSV-файлов без указания схемы для примеров.
Имейте в виду, что при одновременном чтении количества файлов схема будет выводиться из первой файловой службы из хранилища. Это может означать, что некоторые из ожидаемых столбцов опущены, все потому, что файл, используемый службой для определения схемы, не содержал этих столбцов. В этом случае используйте предложение OPENROWSET WITH.
Важно!
В некоторых случаях из-за недостатка информации не удается вычислить подходящий тип данных, поэтому вместо него используется больший тип данных. Это приводит к снижению производительности, что важно для столбцов со знаками, которые будут выводиться как varchar(8000). Чтобы обеспечить оптимальную производительность, проверьте выводимые типы данных и используйте соответствующие типы данных.
Сопоставление типов для Parquet
Файлы Parquet и Delta Lake содержат описания типов для каждого столбца. В приведенной ниже таблице показано, как типы Parquet сопоставляются с собственными типами SQL.
| Тип Parquet | Логический тип Parquet (заметка) | Тип данных SQL |
|---|---|---|
| BOOLEAN | bit | |
| BINARY / BYTE_ARRAY | varbinary | |
| DOUBLE | с плавающей запятой | |
| FLOAT | real | |
| INT32 | INT | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binary | |
| BINARY | UTF8 | varchar *(параметры сортировки UTF8) |
| BINARY | STRING | varchar *(параметры сортировки UTF8) |
| BINARY | ENUM | varchar *(параметры сортировки UTF8) |
| FIXED_LEN_BYTE_ARRAY | UUID | uniqueidentifier |
| BINARY | DECIMAL | десятичное |
| BINARY | JSON | varchar(8000) *(параметры сортировки UTF8) |
| BINARY | BSON | Не поддерживается |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | десятичное |
| BYTE_ARRAY | INTERVAL | Не поддерживается |
| INT32 | INT(8, true) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, true) | INT |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | INT |
| INT32 | INT(32, false) | bigint |
| INT32 | DATE | Дата |
| INT32 | DECIMAL | десятичное |
| INT32 | TIME (MILLIS) | Время |
| INT64 | INT(64, true) | bigint |
| INT64 | INT(64, false) | decimal(20,0) |
| INT64 | DECIMAL | десятичное |
| INT64 | TIME (MICROS) | Время |
| INT64 | TIME (NANOS) | Не поддерживается |
| INT64 | TIMESTAMP (нормализовано в формат UTC) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (не нормализовано в формат UTC) (MILLIS / MICROS) | bigint — убедитесь, что значение bigint явно отрегулировано с помощью смещения часового пояса, прежде чем преобразовать его в значение даты и времени (datetime). |
| INT64 | TIMESTAMP (NANOS) | Не поддерживается |
| Сложный тип | LIST | varchar(8000), сериализованный в JSON |
| Сложный тип | MAP | varchar(8000), сериализованный в JSON |
Примеры
Считывание CSV-файлов без указания схемы
В следующем примере считывается CSV-файл, содержащий строку заголовка, без указания имен столбцов и типов данных:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
В следующем примере считывается CSV-файл, который не содержит строку заголовка, без указания имен столбцов и типов данных:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Считывание файлов Parquet без указания схемы
В следующем примере возвращаются все столбцы первой строки из набора данных переписи в формате Parquet без указания имен столбцов и типов данных.
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Чтение файлов Delta Lake без указания схемы
В приведенном ниже примере возвращаются все столбцы первой строки из набора данных переписи в формате Delta Lake без указания имен столбцов и типов данных:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Считывание конкретных столбцов из CSV-файла
В следующем примере из файлов population*.csv возвращаются только два столбца с порядковыми номерами 1 и 4. В файлах нет строки заголовка, поэтому чтение начинается с первой строки.
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Считывание конкретных столбцов из файла Parquet
В следующем примере возвращаются только два столбца первой строки из набора данных переписи в формате Parquet:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Определение столбцов с помощью путей JSON
В следующем примере показано, как можно использовать выражения пути JSON в предложении WITH и в чем заключается различие между строгими и нестрогими режимами пути:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Определение нескольких фалов или папок в пути массового выполнения
В следующем примере показано, как использовать пути к нескольким файлам или папкам в параметре групповой обработки:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Следующие шаги
Дополнительные образцы см. в кратком руководстве по хранилищу данных запросов, чтобы узнать, как использовать OPENROWSET для чтения CSV, PARQUET, DELTA LAKE, а также форматов файлов JSON. Ознакомьтесь с рекомендациями, чтобы иметь возможность достичь оптимальной производительности. Вы также узнаете, как сохранить результаты запроса в службе хранилища Azure с помощью CETAS.