Ескертпе
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Жүйеге кіруді немесе каталогтарды өзгертуді байқап көруге болады.
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Каталогтарды өзгертуді байқап көруге болады.
Подсказка
Это фрагмент из электронной книги «Архитектура облачных нативных приложений .NET для Azure», доступен на .NET Docs или как бесплатный загружаемый PDF-файл, который можно прочитать в автономном режиме.

Как мы видели в этой книге, облачный подход изменяет способ разработки, развертывания и управления приложениями. Он также изменяет способ управления и хранения данных.
Рис. 5-1 контрастирует с различиями.
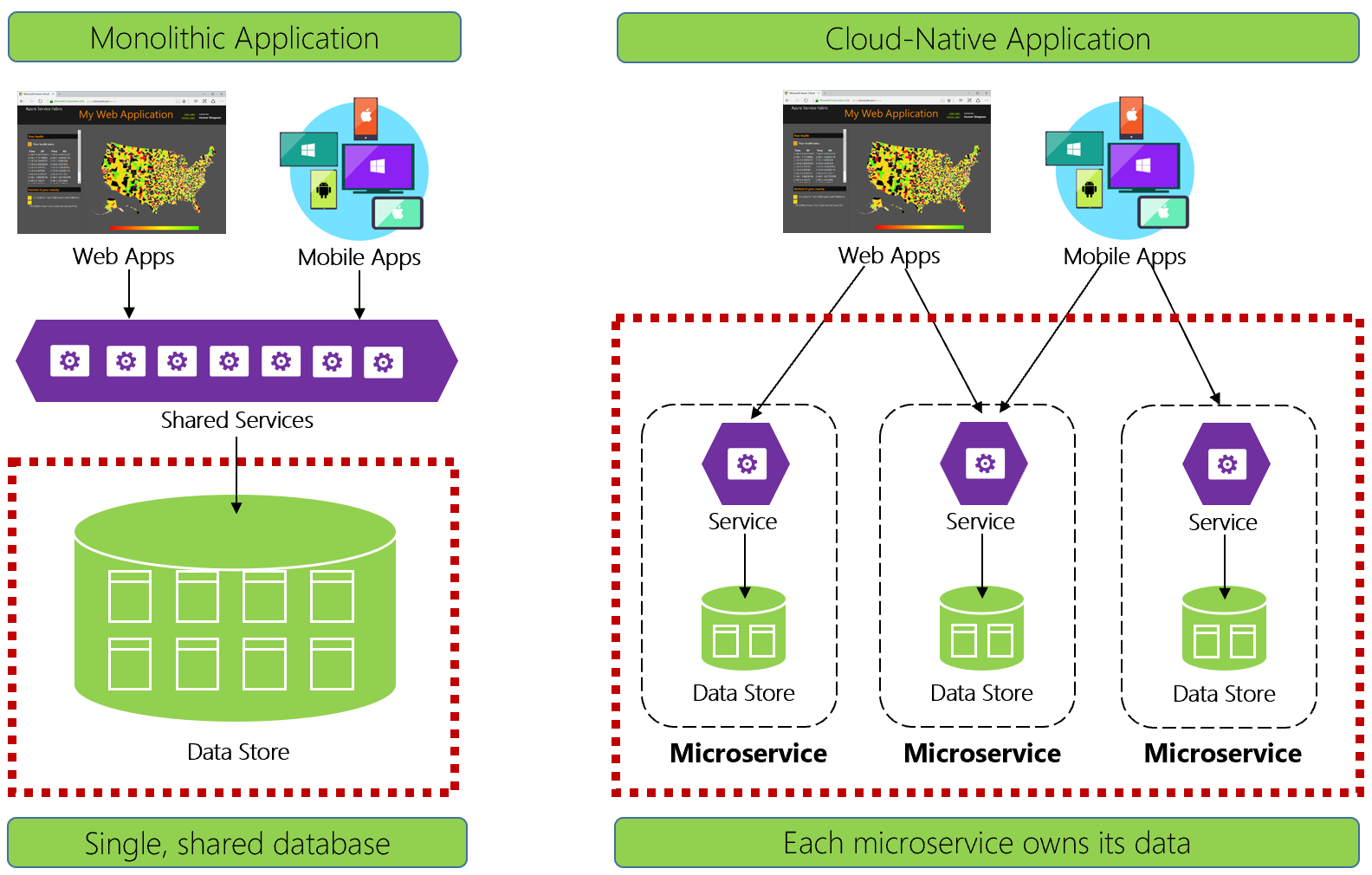
Рис. 5-1. Управление данными в облачных приложениях
Опытные разработчики легко распознают архитектуру на левой части рисунка 5-1. В этом монолитном приложении компоненты бизнес-службы объединяются на уровне общих служб и совместно используют данные из одной реляционной базы данных.
Во многих отношениях одна база данных обеспечивает простое управление данными. Запрос данных в нескольких таблицах прост. Изменения обновляются все вместе или полностью откатываются. Транзакции ACID гарантируют надежную и немедленную согласованность.
Проектируя в облачном окружении, мы используем иной подход. На правой части рисунка 5-1 обратите внимание на то, как бизнес-функции разделяются на небольшие независимые микрослужбы. Каждая микрослужба инкапсулирует определенную бизнес-возможность и собственные данные. Монолитная база данных разлагается в распределенную модель данных с множеством небольших баз данных, каждая из которых соответствует микрослужбе. Когда дым очищается, мы возникаем с конструкцией, которая предоставляет базу данных для каждой микрослужбы.
Отдельная база данных для каждой микрослужбы, почему?
Эта база данных на микрослужбу обеспечивает множество преимуществ, особенно для систем, которые должны быстро развиваться и поддерживать массовый масштаб. С этой моделью...
- Данные домена заключены внутри службы
- Схема данных может развиваться без непосредственного влияния на другие службы
- Каждое хранилище данных может независимо масштабироваться
- Сбой хранилища данных в одной службе не будет напрямую влиять на другие службы.
Разделение данных также позволяет каждой микрослужбе реализовать тип хранилища данных, оптимизированный для рабочей нагрузки, потребностей хранилища и шаблонов чтения и записи. Варианты включают реляционные, документные, ключ-значение и даже графовые хранилища данных.
Рис. 5-2 представляет принцип полиглотной устойчивости в облачно-ориентированной системе.
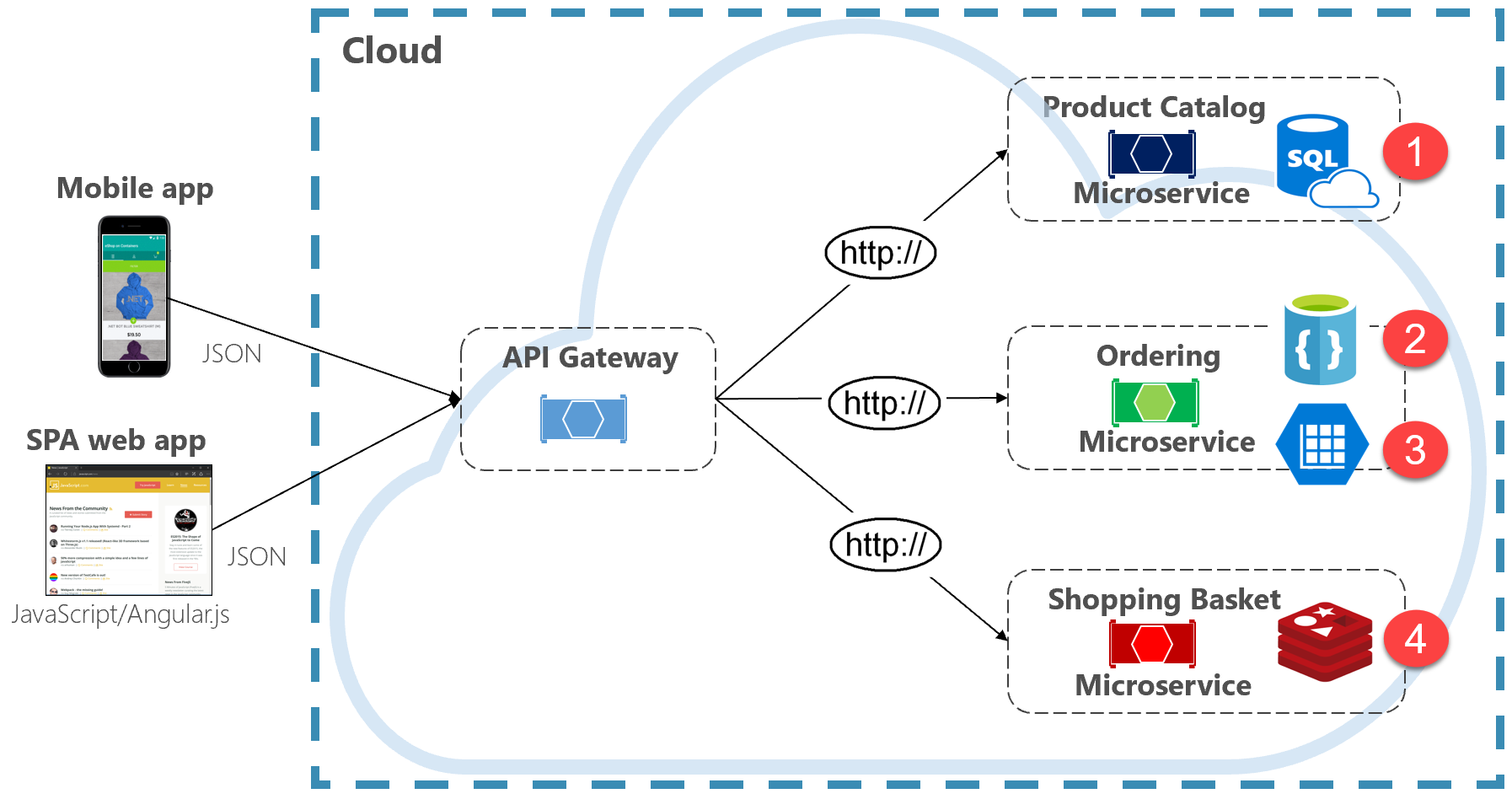
Рис. 5-2. Сохраняемость данных Polyglot
Обратите внимание на предыдущий рисунок, как каждая микрослужба поддерживает другой тип хранилища данных.
- Микрослужба каталога продуктов использует реляционную базу данных для размещения богатой реляционной структуры ее базовых данных.
- Микрослужба корзины покупок использует распределенный кэш, который поддерживает его простое хранилище данных с ключом и значением.
- Микрослужба заказа использует базу данных документов NoSql для операций записи вместе с хранилищем ключей и значений с высоким уровнем денормализации ключей и значений для размещения больших объемов операций чтения.
Хотя реляционные базы данных остаются актуальными для микрослужб с сложными данными, базы данных NoSQL приобрели значительную популярность. Они обеспечивают масштабные возможности и высокую доступность. Их без схемы характер позволяет разработчикам отойти от архитектуры типизированных классов данных и ORM, которые делают изменение дорогостоящим и трудоемким. Далее в этой главе мы рассмотрим базы данных NoSQL.
Хотя инкапсулирование данных в отдельные микрослужбы может повысить гибкость, производительность и масштабируемость, она также представляет множество проблем. В следующем разделе мы обсудим эти проблемы вместе с шаблонами и методиками, которые помогут преодолеть их.
Запросы между службами
Хотя микрослужбы независимы и сосредоточены на конкретных функциональных возможностях, таких как инвентаризация, доставка или заказ, они часто требуют интеграции с другими микрослужбами. Часто интеграция включает одну микрослужбу, запрашивающую другую для данных. На рисунке 5-3 показан сценарий.
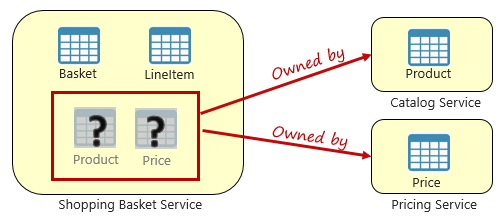
Рис. 5-3. Выполнение запросов между микросервисами
На предыдущем рисунке мы видим микрослужбу корзины покупок, которая добавляет элемент в корзину покупок пользователя. Хотя хранилище данных для этой микрослужбы содержит данные корзины и позиции, оно не содержит данные о продуктах или ценах. Вместо этого эти элементы данных принадлежат каталогу и микрослужбам цен. Этот аспект представляет проблему. Как микрослужба корзины покупок может добавить продукт в корзину покупок пользователя, если у него нет данных о продукте или ценах в базе данных?
Один из вариантов, рассмотренных в главе 4, — прямой HTTP-вызов из корзины покупок в каталог и микрослужбы ценообразования. Однако в главе 4 мы сказали, что синхронные HTTP-вызовы объединяют микрослужбы , уменьшая их автономию и уменьшая их архитектурные преимущества.
Мы также можем реализовать шаблон запрос-ответ с отдельными входящими и исходящими очередями для каждой службы. Тем не менее, этот шаблон является сложным и требует внутренней логики для сопоставления сообщений запроса и ответа. Хотя он отделяет вызовы внутренней микрослужбы, служба вызовов должна по-прежнему синхронно ждать завершения вызова. Перегрузка сети, временные сбоя или перегруженная микрослужба, что может привести к длительным и даже неудачным операциям.
Вместо этого широко принятый шаблон удаления зависимостей между службами — это шаблон материализованного представления, показанный на рис. 5-4.
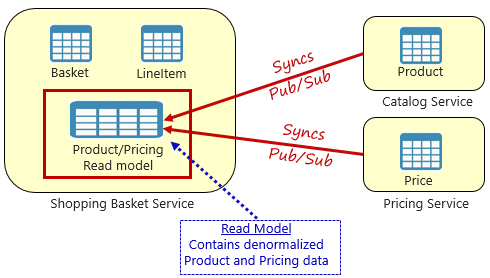
Рис. 5-4. Шаблон материализованного представления
С помощью этого шаблона вы размещаете локальную таблицу данных (называемую моделью чтения) в службе корзины покупок. Эта таблица содержит денормализованную копию данных, необходимых для продукта и микрослужб ценообразования. Копирование данных непосредственно в микрослужбу корзины покупок устраняет необходимость дорогостоящих вызовов между службами. При использовании локальной службы данных вы улучшаете время отклика и надежность службы. Кроме того, наличие собственной копии данных делает службу корзин покупок более устойчивой. Если служба каталога должна стать недоступной, она не будет напрямую влиять на службу корзины покупок. Корзина покупок может продолжать работать с данными из собственного магазина.
Недостаток этого подхода заключается в том, что теперь в системе есть дубли. Однако стратегическое дублирование данных в облачных системах является общепринятой практикой и не считается плохим шаблоном или неприемлемой практикой. Имейте в виду, что одна и только одна служба может принадлежать набору данных и иметь в нем полномочия. При обновлении системы записей необходимо синхронизировать модели чтения. Синхронизация обычно реализуется с помощью асинхронного обмена сообщениями с шаблоном публикации и подписки, как показано на рис. 5.4.
Распределенные транзакции
Хотя выполнение запросов к данным в микрослужбах сложно, реализация транзакции между несколькими микрослужбами еще более сложна. Сложность поддержания согласованности данных в независимых источниках данных в разных микрослужбах не должна быть недооценена. Отсутствие распределенных транзакций в облачных приложениях означает, что необходимо программно управлять распределенными транзакциями. Вы переходите от мира немедленной согласованности к миру конечной согласованности.
На рисунке 5-5 показана проблема.
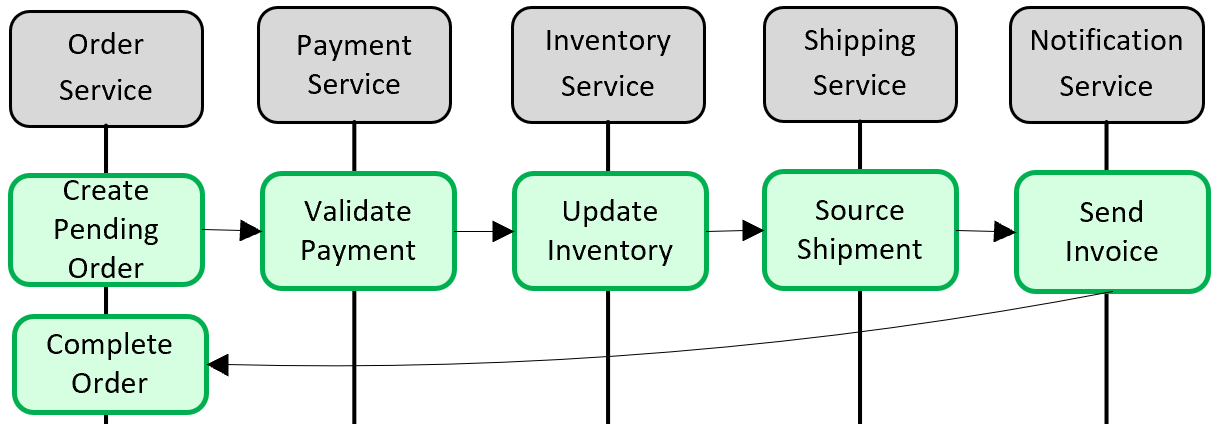
Рис. 5-5. Реализация транзакции между микрослужбами
На предыдущем рисунке пять независимых микрослужб участвуют в распределенной транзакции, которая создает заказ. Каждая микрослужба поддерживает собственное хранилище данных и реализует локальную транзакцию для своего хранилища. Чтобы создать заказ, локальная транзакция для каждой отдельной микрослужбы должна завершиться успешно, или все должны прервать и откатить операцию. Хотя встроенная поддержка транзакций доступна внутри каждой микрослужбы, нет поддержки распределенной транзакции, которая будет охватывать все пять служб для обеспечения согласованности данных.
Вместо этого необходимо программно создать эту распределенную транзакцию.
Популярным шаблоном добавления распределенной поддержки транзакций является шаблон Saga. Он реализуется путем группировки локальных транзакций программным путем и последовательного вызова каждого из них. Если произошел сбой локальных транзакций, сага прерывает операцию и вызывает набор компенсирующих транзакций. Компенсирующие транзакции отменяют изменения, внесенные предыдущими локальными транзакциями, и восстанавливают согласованность данных. На рисунке 5-6 показана неудачная транзакция в паттерне Saga.
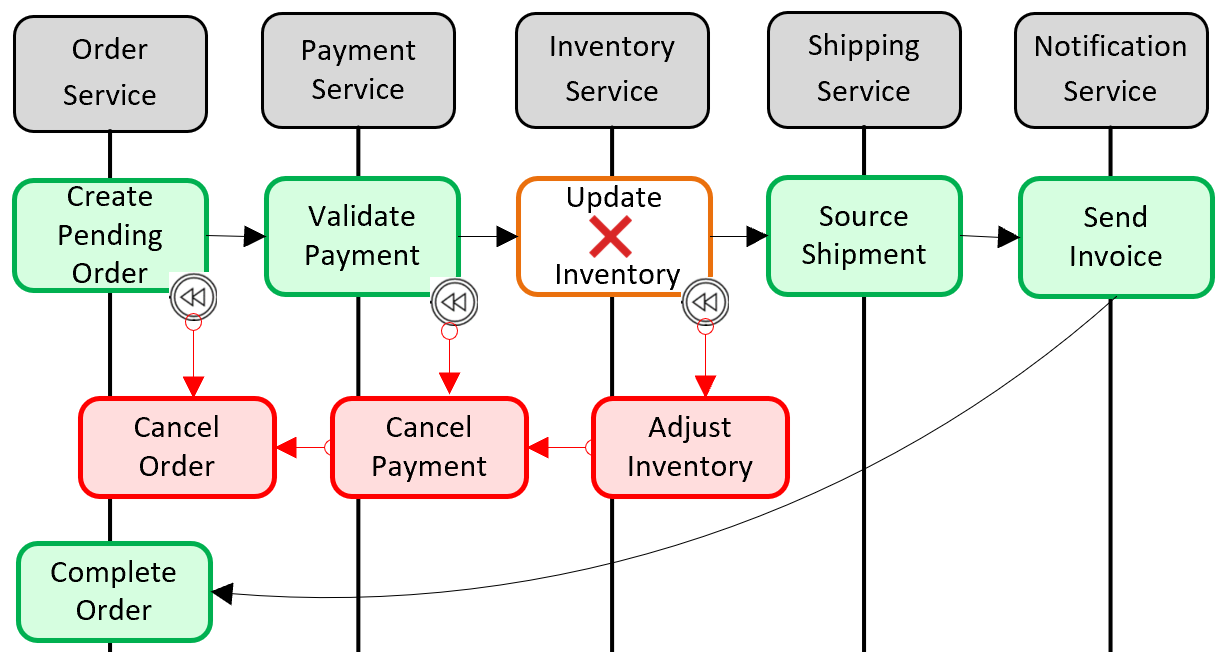
Рис. 5-6. Откат транзакции
На предыдущем рисунке операция Обновление запасов завершилась сбоем в микрослужбе управления запасами. Сага вызывает набор компенсирующих транзакций (отмечено красным цветом) для коррекции счетчиков инвентаризации, отмены платежа и заказа, а также приведения данных каждой микрослужбы в согласованное состояние.
Шаблоны SAGA обычно хореографируются как последовательность связанных событий или оркестрируются в виде набора связанных команд. В главе 4 мы обсудили шаблон агрегатора услуг, который будет основой оркестированной реализации саги. Мы также обсудили события вместе со служебной шиной Azure и разделами сетки событий Azure , которые будут основой для реализации хореографической сага.
Большие объемные данные
Крупные облачные приложения часто поддерживают требования к данным большого объема. В этих сценариях традиционные методы хранения данных могут привести к узким местам. Для сложных систем, развертывающихся в большом масштабе, функции разделения команд и ответственности запросов (CQRS) и событий могут повысить производительность приложений.
CQRS
CQRS — это архитектурный шаблон, который может повысить производительность, масштабируемость и безопасность. Шаблон отделяет операции, которые считывают данные от тех операций, которые записывают данные.
В обычных сценариях для операций чтения и записи используются одинаковые модели сущностей и объект репозитория данных.
Однако сценарий больших объемов данных может воспользоваться отдельными моделями и таблицами данных для операций чтения и записи. Чтобы повысить производительность, операция чтения может запрашивать высоко денормализованное представление данных, чтобы избежать дорогостоящих повторяющихся соединений таблиц и блокировок таблиц. Операция записи, известная как команда, обновляет данные в полностью нормализованном представлении, которое гарантирует согласованность. Затем необходимо реализовать механизм для синхронизации обоих представлений. Как правило, при изменении таблицы записи она публикует событие , которое реплицирует изменение в таблицу чтения.
На рисунке 5-7 показана реализация шаблона CQRS.
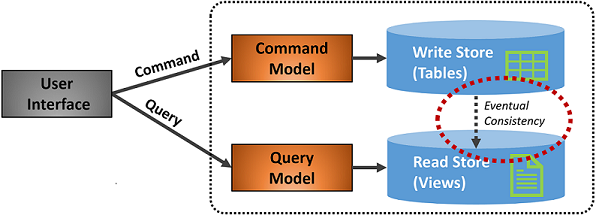
Рис. 5-7. Реализация CQRS
На предыдущем рисунке реализованы отдельные модели команд и запросов. Каждая операция записи данных сохраняется в хранилище записи, а затем распространяется в хранилище чтения. Обратите особое внимание на то, как процесс распространения данных работает с принципом конечной согласованности. Модель чтения в конечном итоге синхронизируется с моделью записи, но в процессе может возникнуть некоторая задержка. Мы обсудим конечную согласованность в следующем разделе.
Это разделение позволяет масштабировать операции чтения и записи независимо друг от друга. Операции чтения используют схему, оптимизированную для запросов, а записи используют схему, оптимизированную для обновлений. Чтение запросов идет против денормализованных данных, а сложная бизнес-логика может применяться к модели записи. Кроме того, вы можете установить более строгие меры безопасности для операций записи, чем для операций, которые позволяют чтение.
Реализация CQRS может повысить производительность приложений для облачных служб. Однако это приводит к более сложному дизайну. Примените этот принцип тщательно и стратегически к этим разделам облачного приложения, которые будут использовать его. Дополнительные сведения о CQRS см. в книге Майкрософт по микрослужбам .NET: архитектура для контейнерных приложений .NET.
Источник событий
Другой подход к оптимизации сценариев данных с большим объемом включает источник событий.
Система обычно сохраняет текущее состояние сущности данных. Если пользователь изменяет номер телефона, например, запись клиента обновляется новым номером. Мы всегда знаем текущее состояние сущности данных, но каждое обновление перезаписывает предыдущее состояние.
В большинстве случаев эта модель работает нормально. Однако в системах с большим объемом затраты от блокировки транзакций и частых операций обновления могут повлиять на производительность базы данных, скорость реагирования и ограничение масштабируемости.
Событийное моделирование предлагает иной подход к захвату данных. Каждая операция, которая влияет на данные, сохраняется в хранилище событий. Вместо обновления состояния записи данных мы добавим каждое изменение к последовательному списку прошлых событий, аналогично реестру бухгалтера. Хранилище событий становится системой записи для данных. Он используется для распространения различных материализованных представлений в ограниченном контексте микрослужбы. На рисунке 5.8 показан шаблон.
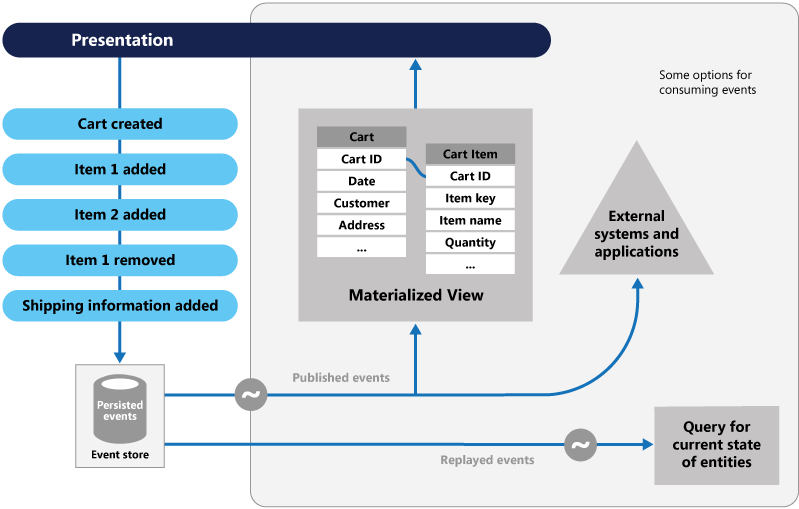
Рис. 5-8. Источник событий
На предыдущем рисунке обратите внимание, что каждая запись (синяя) для корзины покупок пользователя добавляется в базовое хранилище событий. В прилегающем материализованном представлении система показывает текущее состояние путем воспроизведения всех событий, связанных с каждой корзиной покупок. Это представление или модель чтения затем возвращается в пользовательский интерфейс. События также можно интегрировать с внешними системами и приложениями или запрашивать для определения текущего состояния сущности. С помощью этого подхода вы сохраняете историю. Вы знаете не только текущее состояние сущности, но и то, как вы достигли этого состояния.
С точки зрения механики, использование event sourcing упрощает модель записи. Нет обновлений или удалений. Добавление каждой записи данных в качестве неизменяемого события сводит к минимуму конкуренцию, блокировки и конфликты параллелизма, связанные с реляционными базами данных. Создание моделей чтения с помощью шаблона материализованного представления позволяет отделить представление от модели записи и выбрать лучшее хранилище данных для оптимизации потребностей пользовательского интерфейса приложения.
Для этого паттерна рассмотрим хранилище данных, которое напрямую поддерживает использование событий как источника. Azure Cosmos DB, MongoDB, Cassandra, CouchDB и RavenDB являются хорошими кандидатами.
Как и во всех шаблонах и технологиях, реализуйте стратегически и при необходимости. Хотя событийное моделирование может обеспечить повышенную производительность и масштабируемость, это происходит за счет сложности и потребности в изучении.
GitHub сайтында бізбен бірлесіп жұмыс істеу
Бұл мазмұнның көзін GitHub сайтында табуға болады. Онда сонымен бірге мәселелер мен өзгертулерді енгізу сұрауларын жасауға және қарап шығуға болады. Қосымша ақпарат алу үшін қатысушы нұсқаулығын қараңыз.