Ескертпе
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Жүйеге кіруді немесе каталогтарды өзгертуді байқап көруге болады.
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Каталогтарды өзгертуді байқап көруге болады.
Узнайте, как использовать предварительно обученную модель ONNX в ML.NET для обнаружения объектов в изображениях.
Для обучения модели обнаружения объектов с нуля требуется установка миллионов параметров, большое количество помеченных обучающих данных и огромное количество вычислительных ресурсов (сотни часов GPU). Использование предварительно обученной модели позволяет ярлыку процесса обучения.
В этом руководстве вы узнаете, как:
- Определение проблемы
- Узнайте, что такое ONNX и как он работает с ML.NET
- Общие сведения о модели
- Повторное использование предварительно обученной модели
- Обнаружение объектов с помощью загруженной модели
Предпосылки
- Visual Studio 2022 или более поздней версии.
- Пакет NuGet Microsoft.ML
- Пакет NuGet Microsoft.ML.ImageAnalytics
- Пакет NuGet Microsoft.ML.OnnxTransformer
- Маленькая предварительно обученная модель YOLOv2
- Netron (необязательно)
Обзор примера обнаружения объектов ONNX
В этом примере создается консольное приложение .NET Core, которое обнаруживает объекты на изображении с помощью предварительно обученной модели ONNX глубокого обучения. Код для этого примера можно найти в репозитории dotnet/machinelearning-samples на сайте GitHub.
Что такое обнаружение объектов?
Обнаружение объектов — это проблема компьютерного зрения. Несмотря на тесное отношение к классификации изображений, обнаружение объектов выполняет классификацию изображений на более детальном уровне. Обнаружение объектов определяет и классифицирует сущности на изображениях. Модели обнаружения объектов обычно обучены с помощью глубокого обучения и нейронных сетей. Дополнительные сведения см. в разделе "Глубокое обучение и машинное обучение ".
Используйте обнаружение объектов, если изображения содержат несколько объектов разных типов.

Ниже приведены некоторые варианты использования для обнаружения объектов:
- автомобили с автопилотом
- Робототехника
- Обнаружение лиц
- Безопасность на рабочем месте
- Подсчет объектов
- Распознавание действий
Выбор модели глубокого обучения
Глубокое обучение — это подмножество машинного обучения. Для обучения моделей глубокого обучения требуются большие объемы данных. Шаблоны в данных представлены рядом слоев. Связи в данных кодируются в виде соединений между слоями, содержащими весовые значения. Чем выше вес, тем сильнее отношения. В совокупности этот ряд слоев и соединений называется искусственными нейронными сетями. Чем больше слоев в сети, тем глубже он является, что делает его глубокой нейронной сетью.
Существуют различные типы нейронных сетей, наиболее распространенными являются многослойный перцептрон (MLP), Сверточная Нейронная Сеть (CNN) и Повторяющаяся Нейронная Сеть (RNN). Наиболее основным является MLP, который сопоставляет набор входных данных с набором выходных данных. Эта нейронная сеть хороша, если данные не имеют пространственного или временного компонента. CNN использует сверточных слоев для обработки пространственной информации, содержащейся в данных. Хороший вариант использования для CNN — это обработка изображений для обнаружения присутствия функции в области изображения (например, есть нос в центре изображения?). Наконец, RNN позволяют использовать сохраняемость состояния или памяти в качестве входных данных. RNN используются для анализа временных рядов, где важно последовательное упорядочение и контекст событий.
Общие сведения о модели
Обнаружение объектов — это задача обработки изображений. Поэтому большинство моделей глубокого обучения, обученных решить эту проблему, являются CNN. Модель, используемая в этом руководстве, — это модель Tiny YOLOv2, более компактная версия модели YOLOv2, описанная в документе : "YOLO9000: Лучше, быстрее, сильнее" Redmon и Farhadi. Маленький YOLOv2 обучается на наборе данных Pascal VOC и состоит из 15 слоев, которые могут прогнозировать 20 различных классов объектов. Так как Tiny YOLOv2 является сжатой версией исходной модели YOLOv2, компромисс выполняется между скоростью и точностью. Различные слои, составляющие модель, можно визуализировать с помощью таких инструментов, как Netron. Проверка модели приведет к сопоставлению соединений между всеми слоями, составляющими нейронную сеть, где каждый слой будет содержать имя слоя вместе с измерениями соответствующих входных и выходных данных. Структуры данных, используемые для описания входных и выходных данных модели, называются тензорами. Tensors можно рассматривать как контейнеры, которые хранят данные в N-измерениях. В случае Tiny YOLOv2 имя входного слоя — image, и он ожидает тензор размером 3 x 416 x 416. Имя выходного слоя — grid это и создает выходной тензор измерений 125 x 13 x 13.

Модель YOLO принимает изображение 3(RGB) x 416px x 416px. Модель принимает эти входные данные и передает ее через различные слои для создания выходных данных. Выходные данные делят входное изображение на сетку 13 x 13 , с каждой ячейкой в сетке, состоящей из значений 125 .
Что такое модель ONNX?
Open Neural Network Exchange (ONNX) — это формат с открытым исходным кодом для моделей ИИ. ONNX поддерживает взаимодействие между платформами. Это означает, что вы можете обучить модель в одной из многих популярных платформ машинного обучения, таких как PyTorch, преобразовать ее в формат ONNX и использовать модель ONNX в другой платформе, например ML.NET. Дополнительные сведения см. на веб-сайте ONNX.

Предварительно обученная модель Tiny YOLOv2 хранится в формате ONNX, который является сериализованным представлением как слоев, так и изученных шаблонов этих слоев. В ML.NET взаимодействие с ONNX достигается с пакетами NuGet ImageAnalytics и OnnxTransformer. Пакет ImageAnalytics содержит ряд преобразований, которые принимают изображение и кодируют его в числовые значения, которые можно использовать в качестве входных данных в прогноз или конвейер обучения. Пакет OnnxTransformer использует среду выполнения ONNX для загрузки модели ONNX и ее использования для прогнозирования на основе предоставленных входных данных.

Настройка проекта консоли .NET
Теперь, когда у вас есть общее представление о том, что такое ONNX и как работает Tiny YOLOv2, пришло время создать приложение.
Создайте консольное приложение
Создайте консольное приложение C# с именем ObjectDetection. Нажмите кнопку Далее.
Выберите .NET 8 в качестве платформы для использования. Нажмите кнопку Создать.
Установите пакет NuGet Microsoft.ML:
Замечание
В этом примере используется последняя стабильная версия упомянутых пакетов NuGet, если не указано иное.
- В обозревателе решений щелкните проект правой кнопкой мыши и выберите пункт "Управление пакетами NuGet".
- Выберите "nuget.org" в качестве источника пакета, перейдите на вкладку "Обзор", найдите Microsoft.ML.
- Нажмите кнопку Установить.
- Нажмите кнопку "ОК " в диалоговом окне "Предварительные изменения" , а затем нажмите кнопку "Принять" в диалоговом окне принятия лицензий, если вы согласны с условиями лицензии для перечисленных пакетов.
- Повторите эти действия для Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer и Microsoft.ML.OnnxRuntime.
Подготовка данных и предварительно обученной модели
Скачайте ZIP-файл каталога ресурсов проекта и распакуйте его.
Скопируйте каталог
assetsв каталог вашего проекта ObjectDetection. В этом каталоге и его подкаталогах содержатся файлы изображений (за исключением модели Tiny YOLOv2, которую вы скачайте и добавьте на следующем шаге), необходимые для работы с этим руководством.Скачайте модель Tiny YOLOv2 из зоопарка моделей ONNX.
Скопируйте файл
model.onnxв каталог проекта ObjectDetectionassets\Modelи переименуйте его вTinyYolo2_model.onnx. Этот каталог содержит модель, необходимую для этого руководства.В обозревателе решений щелкните правой кнопкой мыши каждый из файлов в каталоге ресурсов и подкаталогах и выберите "Свойства". В разделе "Дополнительно" измените значение Копировать в выходной каталог на Копировать, если новее.
Создание классов и определение путей
Откройте файл Program.cs и добавьте следующие дополнительные using директивы в начало файла:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
Затем определите пути различных ресурсов.
Сначала создайте
GetAbsolutePathметод в нижней части файла Program.cs .string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }Затем под
usingдирективами создайте поля для хранения расположения ресурсов.var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
Добавьте новый каталог в проект для хранения входных данных и классов прогнозирования.
В обозревателе решений щелкните проект правой кнопкой мыши и выберите команду "Добавить>новую папку". Когда новая папка появится в обозревателе решений, назовите ее DataStructures.
Создайте класс входных данных в созданном каталоге DataStructures .
В обозревателе решений щелкните правой кнопкой мыши каталог DataStructures и выберите пункт "Добавить>новый элемент".
В диалоговом окне "Добавление нового элемента" выберите класс и измените поле "Имя " на ImageNetData.cs. Затем нажмите кнопку "Добавить".
Файл ImageNetData.cs откроется в редакторе кода. Добавьте следующую
usingдирективу в начало ImageNetData.cs:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;Удалите существующее определение класса и добавьте следующий код для класса в
ImageNetDataфайл ImageNetData.cs :public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetData— это класс данных входного изображения и имеет следующие String поля:-
ImagePathсодержит путь, в котором хранится изображение. -
Labelсодержит имя файла.
Кроме того,
ImageNetDataсодержит методReadFromFile, который загружает несколько файлов изображений, хранящихся в указанном пути, и возвращает их вimageFolderвиде коллекцииImageNetDataобъектов.-
Создайте класс прогнозирования в каталоге DataStructures .
В обозревателе решений щелкните правой кнопкой мыши каталог DataStructures и выберите пункт "Добавить>новый элемент".
В диалоговом окне "Добавление нового элемента" выберите класс и измените поле "Имя " на ImageNetPrediction.cs. Затем нажмите кнопку "Добавить".
Файл ImageNetPrediction.cs откроется в редакторе кода. Добавьте следующую
usingдирективу в начало ImageNetPrediction.cs:using Microsoft.ML.Data;Удалите существующее определение класса и добавьте следующий код для класса в
ImageNetPredictionфайл ImageNetPrediction.cs :public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPrediction— это класс данных прогнозирования и имеет следующееfloat[]поле:-
PredictedLabelsсодержит измерения, оценку объектности и вероятности класса для каждого ограничивающего прямоугольника, обнаруженного на изображении.
-
Инициализация переменных
Класс MLContext — это отправная точка для всех операций ML.NET, и инициализация mlContext создает новую среду ML.NET, которую можно совместно использовать для объектов рабочего процесса создания модели. Это концептуально похоже на DBContext в Entity Framework.
Инициализируйте переменную mlContext новым экземпляром MLContext, добавив следующую строку под полем outputFolder.
MLContext mlContext = new MLContext();
Создание средства синтаксического анализа для выходных данных модели после процесса
Модель сегментирует изображение в сетку 13 x 13 , где каждая ячейка сетки находится 32px x 32px. Каждая ячейка сетки содержит 5 потенциальных ограничивающих прямоугольников для объектов. Ограничивающий прямоугольник содержит 25 элементов:
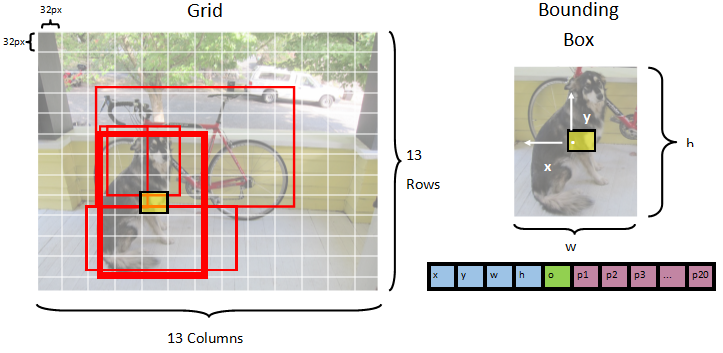
-
xположение x центра ограничивающей рамки относительно ячейки сетки, к которой оно относится. -
yПоложение ограничивающего центра прямоугольника относительно ячейки сетки, с которым она связана. -
wширина ограничивающего прямоугольника. -
hвысота ограничивающего прямоугольника. -
oУровень доверия, что объект существует в ограничивающем прямоугольнике, также известный как оценка объектности. -
p1-p20вероятности классов для каждого из 20 классов, прогнозируемых моделью.
В общей сложности 25 элементов, описывающих каждую из 5 ограничивающих рамок, составляют 125 элементов, содержащихся в каждой ячейке сетки.
Выходные данные, созданные предварительно обученной моделью ONNX, представляют собой массив с плавающей длиной 21125, представляющий элементы тензора с измерениями 125 x 13 x 13. Чтобы преобразовать прогнозы, созданные моделью, в тензор, требуется некоторая работа после обработки. Для этого создайте набор классов для анализа выходных данных.
Добавьте новый каталог в проект, чтобы упорядочить набор классов синтаксического анализа.
- В обозревателе решений щелкните проект правой кнопкой мыши и выберите команду "Добавить>новую папку". Когда новая папка появится в обозревателе решений, назовите ее "YoloParser".
Создавайте ограничительные рамки и размеры
Выходные данные модели включают координаты и размеры ограничивающих рамок объектов на изображении. Создайте базовый класс для измерений.
В обозревателе решений щелкните правой кнопкой мыши каталог YoloParser и выберите "Добавить>новый элемент".
В диалоговом окне "Добавление нового элемента" выберите класс и измените поле "Имя" на DimensionsBase.cs. Затем нажмите кнопку "Добавить".
Файл DimensionsBase.cs откроется в редакторе кода. Удалите все
usingдирективы и существующее определение класса.Добавьте следующий код для
DimensionsBaseкласса в файл DimensionsBase.cs :public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBaseимеет следующиеfloatсвойства:-
Xсодержит положение объекта вдоль оси x. -
Yсодержит положение объекта вдоль оси Y. -
Heightсодержит высоту объекта. -
Widthсодержит ширину объекта.
-
Затем создайте класс для ограничивающих прямоугольников.
В обозревателе решений щелкните правой кнопкой мыши каталог YoloParser и выберите "Добавить>новый элемент".
В диалоговом окне "Добавление нового элемента" выберите класс и измените поле "Имя " на YoloBoundingBox.cs. Затем нажмите кнопку "Добавить".
Файл YoloBoundingBox.cs открывается в редакторе кода. Добавьте следующую
usingдирективу в начало YoloBoundingBox.cs:using System.Drawing;Чуть выше существующего определения класса добавьте новое определение класса
BoundingBoxDimensions, которое наследует от классаDimensionsBase, чтобы содержать размеры соответствующего ограничивающего поля.public class BoundingBoxDimensions : DimensionsBase { }Удалите существующее
YoloBoundingBoxопределение класса и добавьте следующий код дляYoloBoundingBoxкласса в файл YoloBoundingBox.cs :public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBoxимеет следующие свойства:-
Dimensionsсодержит измерения ограничивающего прямоугольника. -
Labelсодержит класс объекта, обнаруженный в ограничивающей рамке. -
Confidenceсодержит достоверность класса. -
Rectсодержит представление размеров ограничивающего прямоугольника. -
BoxColorсодержит цвет, связанный с соответствующим классом, используемым для рисования на изображении.
-
Создание средства синтаксического анализа
Теперь, когда создаются классы для измерений и ограничивающих прямоугольников, пришло время создать средство синтаксического анализа.
В обозревателе решений щелкните правой кнопкой мыши каталог YoloParser и выберите "Добавить>новый элемент".
В диалоговом окне "Добавление нового элемента" выберите класс и измените поле "Имя" на YoloOutputParser.cs. Затем нажмите кнопку "Добавить".
Файл YoloOutputParser.cs откроется в редакторе кода. Добавьте следующие
usingдирективы в начало YoloOutputParser.cs:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;В существующем
YoloOutputParserопределении класса добавьте вложенный класс, содержащий измерения каждой ячейки на изображении. Добавьте следующий код для классаCellDimensions, который наследуется от классаDimensionsBase, в верхней части определения классаYoloOutputParser.class CellDimensions : DimensionsBase { }В определении
YoloOutputParserкласса добавьте следующие константы и поля.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;-
ROW_COUNT— это количество строк в сетке, на которые делится изображение. -
COL_COUNT— это количество столбцов в сетке, на которые делится изображение. -
CHANNEL_COUNT— общее количество значений, содержащихся в одной ячейке сетки. -
BOXES_PER_CELL— это число ограничивающих прямоугольников в ячейке, -
BOX_INFO_FEATURE_COUNT— количество признаков, содержащихся в поле (x,y,height,width,confidence). -
CLASS_COUNT— это количество прогнозов класса, содержащихся в каждом ограничивающем поле. -
CELL_WIDTH— ширина одной ячейки в сетке изображений. -
CELL_HEIGHT— высота одной ячейки в сетке изображений. -
channelStride— начальная позиция текущей ячейки в сетке.
Когда модель делает прогноз, также известный как оценка, он делит
416px x 416pxвходной образ на сетку ячеек размером13 x 13. Каждая ячейка содержится32px x 32px. В каждой ячейке есть 5 ограничивающих рамок, каждая из которых содержит 5 признаков (x, y, ширина, высота, достоверность). Кроме того, каждый ограничивающий прямоугольник содержит вероятность каждого класса, который в данном случае составляет 20. Поэтому каждая ячейка содержит 125 фрагментов информации (5 признаков + 20 вероятностей класса).-
Создайте список привязок ниже channelStride для всех 5 ограничивающих рамок:
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
Привязки — это предопределённые соотношения ширины и высоты ограничивающих прямоугольников. Большинство объектов или классов, обнаруженных моделью, имеют аналогичные коэффициенты. Это ценно, когда дело доходит до создания ограничивающих прямоугольников. Вместо прогнозирования ограничивающих рамок вычисляется смещение от предопределенных размеров, что уменьшает вычислительные затраты, необходимые для прогнозирования ограничивающей рамки. Обычно эти коэффициенты привязки вычисляются на основе используемого набора данных. В этом случае, так как набор данных известен и значения предварительно компилируются, привязки можно жестко закодировать.
Затем определите метки или классы, прогнозируемые моделью. Эта модель прогнозирует 20 классов, что является подмножеством общего числа классов, прогнозируемых исходной моделью YOLOv2.
Добавьте список меток под anchorsним.
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
Существуют цвета, связанные с каждым из классов. Назначьте цвета класса ниже labels:
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
Создание вспомогательных функций
Существует ряд шагов, связанных с этапом после обработки. Чтобы помочь с этим, можно использовать несколько вспомогательных методов.
Вспомогательные методы, используемые синтаксическим анализатором:
-
SigmoidПрименяет сигмоидную функцию, которая выводит число от 0 до 1. -
Softmaxнормализует входной вектор в распределение вероятности. -
GetOffsetсопоставляет элементы в одномерных выходных данных модели с соответствующей позицией в тензоре125 x 13 x 13. -
ExtractBoundingBoxesизвлекает размеры ограничивающей рамки из выходных данных модели с помощью методаGetOffset. -
GetConfidenceизвлекает значение достоверности, указывающее, насколько уверена модель в том, что она обнаружила объект и используетSigmoidфункцию, чтобы превратить ее в процент. -
MapBoundingBoxToCellиспользует размеры ограничивающей рамки и сопоставляет их с соответствующей ячейкой на изображении. -
ExtractClassesизвлекает прогнозы класса для ограничивающего поля из выходных данных модели с помощьюGetOffsetметода и преобразует их в распределение вероятностей с помощьюSoftmaxметода. -
GetTopResultВыбирает класс из списка прогнозируемых классов с наибольшей вероятностью. -
IntersectionOverUnionфильтрует перекрывающиеся ограничивающие прямоугольники с более низкими вероятностями.
Добавьте код для всех вспомогательных методов под списком classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
Когда вы определили все вспомогательные методы, пришло время использовать их для обработки выходных данных модели.
Под методом IntersectionOverUnionParseOutputs создайте метод для обработки выходных данных, созданных моделью.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Создайте список для хранения ограничивающих прямоугольников и определите переменные внутри метода ParseOutputs.
var boxes = new List<YoloBoundingBox>();
Каждое изображение делится на сетку 13 x 13 ячеек. Каждая ячейка содержит пять ограничивающих прямоугольников. Под переменной boxes добавьте код для обработки всех полей в каждой ячейке.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
Внутри самого внутреннего цикла вычислите начальную позицию текущего блока в выходных данных одномерной модели.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Непосредственно под этим ExtractBoundingBoxDimensions используйте метод для получения измерений текущего ограничивающего прямоугольника.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
Затем используйте GetConfidence метод, чтобы получить достоверность для текущего ограничивающего поля.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
После этого используйте MapBoundingBoxToCell метод для сопоставления текущего ограничивающего поля с обрабатываемой текущей ячейкой.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Прежде чем выполнять дополнительную обработку, проверьте, превышает ли значение достоверности указанное пороговое значение. В противном случае обработайте следующую ограничивающую рамку.
if (confidence < threshold)
continue;
В противном случае продолжайте обработку выходных данных. Следующим шагом является получение распределения вероятностей прогнозируемых классов для текущего ограничивающего ExtractClasses поля с помощью метода.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
Затем используйте GetTopResult метод, чтобы получить значение и индекс класса с наибольшей вероятностью для текущего поля и вычислить его оценку.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
topScore Используйте для повторного сохранения только ограничивающих прямоугольник, превышающих указанное пороговое значение.
if (topScore < threshold)
continue;
Наконец, если текущее ограничивающее поле превышает пороговое значение, создайте новый объект BoundingBox и добавьте его в список boxes.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
После обработки всех ячеек в изображении верните список boxes. Добавьте следующую инструкцию возврата под внешним циклом в методе ParseOutputs .
return boxes;
Фильтрация перекрывающихся полей
Теперь, когда все строго уверенные ограничивающие коробки были извлечены из выходных данных модели, для удаления перекрывающихся изображений необходимо выполнить дополнительную фильтрацию. Добавьте метод FilterBoundingBoxes под методом ParseOutputs :
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
В методе FilterBoundingBoxes сначала создайте массив, равный размеру обнаруженных ящиков и пометьте все слоты как активные или готовые к обработке.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
Затем сортируйте список, содержащий ограничивающие поля в порядке убывания, на основе достоверности.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
После этого создайте список для хранения отфильтрованных результатов.
var results = new List<YoloBoundingBox>();
Начните обработку каждого ограничивающего прямоугольника путём итерации по каждому из них.
for (int i = 0; i < boxes.Count; i++)
{
}
В этом цикле проверьте, можно ли обрабатывать текущую ограничивающую рамку.
if (isActiveBoxes[i])
{
}
В этом случае добавьте ограничивающее поле в список результатов. Если результаты превышают указанный предел извлекаемых полей, разорвать цикл. Добавьте следующий код в условие if.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
В противном случае посмотрите на смежные ограничивающие прямоугольники. Добавьте следующий код под флажок ограничения.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Как и в первом прямоугольнике, если соседний прямоугольник активен или готов к обработке, используйте метод IntersectionOverUnion, чтобы проверить, превышают ли первый и второй прямоугольники указанное пороговое значение. Добавьте следующий код в самый внутренний цикл для цикла.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
Вне внутреннего цикла, который проверяет смежные ограничивающие прямоугольники, посмотрите, есть ли какие-либо оставшиеся ограничивающие прямоугольники для обработки. Если нет, вырваться из внешнего цикла для цикла.
if (activeCount <= 0)
break;
Наконец, за пределами начального FilterBoundingBoxes цикла метода возвращаются результаты:
return results;
Отлично! Теперь пришло время использовать этот код вместе с моделью для оценки.
Использование модели для оценки
Как и при последующей обработке, в шагах оценки есть несколько шагов. Чтобы помочь с этим, добавьте класс, содержащий логику оценки в проект.
В обозревателе решений щелкните проект правой кнопкой мыши и выберите пункт "Добавить>новый элемент".
В диалоговом окне "Добавление нового элемента" выберите класс и измените поле "Имя " на OnnxModelScorer.cs. Затем нажмите кнопку "Добавить".
Файл OnnxModelScorer.cs открывается в редакторе кода. Добавьте следующие
usingдирективы в начало OnnxModelScorer.cs:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;В определении
OnnxModelScorerкласса добавьте следующие переменные.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();Непосредственно под этим создайте конструктор для
OnnxModelScorerкласса, который инициализирует ранее определенные переменные.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }После создания конструктора определите несколько структур, которые содержат переменные, связанные с параметрами образа и модели. Создайте структуру, названную
ImageNetSettings, чтобы содержать ожидаемые высоту и ширину в качестве входных данных для модели.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }После этого создайте другую структуру
TinyYoloModelSettings, которая содержит имена входных и выходных слоев модели. Чтобы визуализировать имя входных и выходных слоев модели, можно использовать средство, например Netron.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }Затем создайте первый набор методов, используемых для оценки.
LoadModelСоздайте метод внутри классаOnnxModelScorer.private ITransformer LoadModel(string modelLocation) { }В методе
LoadModelдобавьте следующий код для ведения журнала.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");ML.NET конвейеры должны знать схему данных для работы, когда вызывается метод
Fit. В этом случае будет использоваться процесс, аналогичный обучению. Тем не менее, поскольку фактическое обучение не происходит, это приемлемо для использования пустогоIDataView. Создайте новыйIDataViewдля конвейера из пустого списка.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());Ниже определите конвейер. Конвейер будет состоять из четырех преобразований.
-
LoadImagesзагружает изображение в виде растрового изображения. -
ResizeImagesперемасштабирует изображение до указанного размера (в данном случае416 x 416). -
ExtractPixelsизменяет представление пикселя изображения из растрового изображения на числовый вектор. -
ApplyOnnxModelзагружает модель ONNX и использует ее для оценки предоставленных данных.
Определите конвейер в
LoadModelметоде под переменнойdata.var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));Теперь пришло время создать экземпляр модели для оценки.
FitВызовите метод в конвейере и верните его для дальнейшей обработки.var model = pipeline.Fit(data); return model;-
После загрузки модели ее можно использовать для прогнозирования. Чтобы упростить этот процесс, создайте метод PredictDataUsingModel под методом LoadModel .
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
В ней PredictDataUsingModelдобавьте следующий код для ведения журнала.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
Затем используйте Transform метод для оценки данных.
IDataView scoredData = model.Transform(testData);
Извлеките прогнозируемые вероятности и верните их для дополнительной обработки.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Теперь, когда оба шага настроены, объедините их в один метод. Под методом PredictDataUsingModel добавьте новый метод Score.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
Почти закончили! Теперь пришло время положить все это на использование.
Обнаружение объектов
Теперь, когда все настройки завершены, пришло время обнаружить некоторые объекты.
Оценка и анализ выходных данных модели
Под созданием переменной mlContext добавьте инструкцию try-catch.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
В блоке try начните реализацию логики обнаружения объектов. Сначала загрузите данные в объект IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
Затем создайте экземпляр и используйте его для оценки загруженных OnnxModelScorer данных.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
Теперь пришло время для этапа после обработки. Создайте экземпляр и используйте его для обработки выходных YoloOutputParser данных модели.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
После обработки выходных данных модели пришло время нарисовать ограничивающие прямоугольники на изображениях.
Визуализация прогнозов
После того как модель оценила изображения и выходные данные были обработаны, нужно нарисовать ограничивающие прямоугольники на изображении. Для этого добавьте метод DrawBoundingBox под методом GetAbsolutePath внутри Program.cs.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
Сначала загрузите изображение и получите размеры высоты и ширины в методе DrawBoundingBox .
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
Затем создайте цикл for-each для итерации по каждому из ограничивающих прямоугольников, обнаруженных моделью.
foreach (var box in filteredBoundingBoxes)
{
}
Внутри цикла for-each определите размеры ограничивающей рамки.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Так как размеры ограничивающего прямоугольника соответствуют входным данным 416 x 416 модели, масштабируйте размеры ограничивающего прямоугольника, чтобы соответствовать фактическому размеру изображения.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
Затем определите шаблон для текста, который будет отображаться над каждым ограничивающим полем. Текст будет содержать класс объекта внутри соответствующего ограничивающего поля, а также достоверность.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
Чтобы нарисовать изображение, преобразуйте его в Graphics объект.
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
В блоке using кода настройте параметры объекта графического Graphics элемента.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
Ниже задайте параметры шрифта и цвета для текста и ограничивающего поля.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Создайте и заполните этот прямоугольник над ограничивающим полем, чтобы размещать в нём текст методом FillRectangle. Это поможет контрастить текст и улучшить удобочитаемость.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
Затем нарисуйте текст и ограничивающую рамку на изображении, используя методы DrawString и DrawRectangle.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
Вне цикла for-each добавьте код, чтобы сохранить изображения в outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
Для получения дополнительных отзывов о том, что приложение выполняет прогнозы, как ожидалось во время выполнения, добавьте метод, называемый LogDetectedObjects под DrawBoundingBox методом в файле Program.cs , чтобы вывести обнаруженные объекты в консоль.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Теперь, когда у вас есть вспомогательные методы для создания визуальных отзывов от прогнозов, добавьте цикл для итерации по каждому из оцененных изображений.
for (var i = 0; i < images.Count(); i++)
{
}
Внутри цикла получите имя файла изображения и координаты ограничивающих рамок, связанные с ним.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
Используйте ниже метод DrawBoundingBox для рисования ограничивающих прямоугольников на изображении.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Наконец, используйте LogDetectedObjects метод для вывода прогнозов в консоль.
LogDetectedObjects(imageFileName, detectedObjects);
После блока try-catch добавьте дополнительную логику, чтобы указать на завершение процесса.
Console.WriteLine("========= End of Process..Hit any Key ========");
Вот и все!
Results
После выполнения предыдущих шагов запустите консольное приложение (CTRL+F5). Результаты должны совпадать со следующими выходными данными. Вы можете видеть предупреждения или сообщения о процессе, но эти сообщения были удалены из следующих результатов ради ясности.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
Чтобы просмотреть изображения с ограничивающими полями, перейдите в assets/images/output/ каталог. Ниже приведен пример из одного из обработанных образов.

Поздравляю! Теперь вы успешно создали модель машинного обучения для обнаружения объектов путем повторного использования предварительно обученной ONNX модели в ML.NET.
Исходный код этого руководства можно найти в репозитории dotnet/machinelearning-samples .
Из этого руководства вы узнали, как:
- Определение проблемы
- Узнайте, что такое ONNX и как он работает с ML.NET
- Общие сведения о модели
- Повторное использование предварительно обученной модели
- Обнаружение объектов с помощью загруженной модели
Ознакомьтесь с примерами машинного обучения репозитория GitHub, чтобы изучить развернутый пример обнаружения объектов.
GitHub сайтында бізбен бірлесіп жұмыс істеу
Бұл мазмұнның көзін GitHub сайтында табуға болады. Онда сонымен бірге мәселелер мен өзгертулерді енгізу сұрауларын жасауға және қарап шығуға болады. Қосымша ақпарат алу үшін қатысушы нұсқаулығын қараңыз.