Ескерім
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Жүйеге кіруді немесе каталогтарды өзгертуді байқап көруге болады.
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Каталогтарды өзгертуді байқап көруге болады.
В этом руководстве представлен полный пример рабочего процесса Synapse Обработка и анализ данных в Microsoft Fabric. Он использует R для анализа и визуализации цен авокадо в США для создания модели машинного обучения, которая прогнозирует будущие цены авокадо.
В этом руководстве рассматриваются следующие действия.
- Загрузка библиотек по умолчанию
- Загрузка данных
- Настройка данных
- Добавление новых пакетов в сеанс
- Анализ и визуализация данных
- Обучение модели

Необходимые компоненты
Получение подписки Microsoft Fabric. Или зарегистрируйте бесплатную пробную версию Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой нижней части домашней страницы, чтобы перейти на Fabric.
Откройте или создайте записную книжку. Узнайте, как использовать записные книжки Microsoft Fabric.
Задайте для параметра языка значение SparkR (R), чтобы изменить основной язык.
Подключите записную книжку к lakehouse. В левой части нажмите кнопку "Добавить ", чтобы добавить существующее озеро или создать озеро.
Загрузка библиотек
Используйте библиотеки из среды выполнения R по умолчанию:
library(tidyverse)
library(lubridate)
library(hms)
Загрузка данных
Чтение цен на авокадо из . CSV-файл, скачанный из Интернета:
df <- read.csv('https://synapseaisolutionsa.blob.core.windows.net/public/AvocadoPrice/avocado.csv', header = TRUE)
head(df,5)
обработка данных
Сначала присвойте столбцам более понятные имена.
# To use lowercase
names(df) <- tolower(names(df))
# To use snake case
avocado <- df %>%
rename("av_index" = "x",
"average_price" = "averageprice",
"total_volume" = "total.volume",
"total_bags" = "total.bags",
"amount_from_small_bags" = "small.bags",
"amount_from_large_bags" = "large.bags",
"amount_from_xlarge_bags" = "xlarge.bags")
# Rename codes
avocado2 <- avocado %>%
rename("PLU4046" = "x4046",
"PLU4225" = "x4225",
"PLU4770" = "x4770")
head(avocado2,5)
Измените типы данных, удалите нежелательные столбцы и добавьте общее потребление:
# Convert data
avocado2$year = as.factor(avocado2$year)
avocado2$date = as.Date(avocado2$date)
avocado2$month = factor(months(avocado2$date), levels = month.name)
avocado2$average_price =as.numeric(avocado2$average_price)
avocado2$PLU4046 = as.double(avocado2$PLU4046)
avocado2$PLU4225 = as.double(avocado2$PLU4225)
avocado2$PLU4770 = as.double(avocado2$PLU4770)
avocado2$amount_from_small_bags = as.numeric(avocado2$amount_from_small_bags)
avocado2$amount_from_large_bags = as.numeric(avocado2$amount_from_large_bags)
avocado2$amount_from_xlarge_bags = as.numeric(avocado2$amount_from_xlarge_bags)
# Remove unwanted columns
avocado2 <- avocado2 %>%
select(-av_index,-total_volume, -total_bags)
# Calculate total consumption
avocado2 <- avocado2 %>%
mutate(total_consumption = PLU4046 + PLU4225 + PLU4770 + amount_from_small_bags + amount_from_large_bags + amount_from_xlarge_bags)
Установка новых пакетов
Используйте встроенную установку пакета для добавления новых пакетов в сеанс:
install.packages(c("repr","gridExtra","fpp2"))
Загрузите необходимые библиотеки.
library(tidyverse)
library(knitr)
library(repr)
library(gridExtra)
library(data.table)
Анализ и визуализация данных
Сравнение обычных (неорганических) цен на авокадо по регионам:
options(repr.plot.width = 10, repr.plot.height =10)
# filter(mydata, gear %in% c(4,5))
avocado2 %>%
filter(region %in% c("PhoenixTucson","Houston","WestTexNewMexico","DallasFtWorth","LosAngeles","Denver","Roanoke","Seattle","Spokane","NewYork")) %>%
filter(type == "conventional") %>%
select(date, region, average_price) %>%
ggplot(aes(x = reorder(region, -average_price, na.rm = T), y = average_price)) +
geom_jitter(aes(colour = region, alpha = 0.5)) +
geom_violin(outlier.shape = NA, alpha = 0.5, size = 1) +
geom_hline(yintercept = 1.5, linetype = 2) +
geom_hline(yintercept = 1, linetype = 2) +
annotate("rect", xmin = "LosAngeles", xmax = "PhoenixTucson", ymin = -Inf, ymax = Inf, alpha = 0.2) +
geom_text(x = "WestTexNewMexico", y = 2.5, label = "My top 5 cities!", hjust = 0.5) +
stat_summary(fun = "mean") +
labs(x = "US city",
y = "Avocado prices",
title = "Figure 1. Violin plot of nonorganic avocado prices",
subtitle = "Visual aids: \n(1) Black dots are average prices of individual avocados by city \n between January 2015 and March 2018. \n(2) The plot is ordered descendingly.\n(3) The body of the violin becomes fatter when data points increase.") +
theme_classic() +
theme(legend.position = "none",
axis.text.x = element_text(angle = 25, vjust = 0.65),
plot.title = element_text(face = "bold", size = 15)) +
scale_y_continuous(lim = c(0, 3), breaks = seq(0, 3, 0.5))
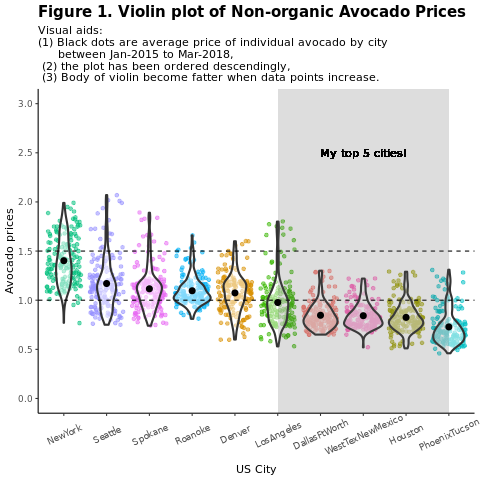
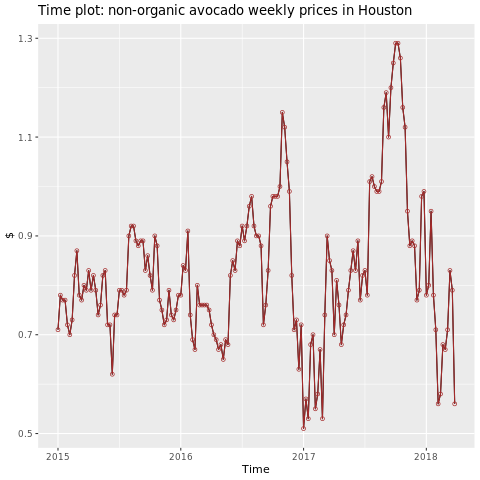
Сосредоточьтесь на хьюстонском регионе.
library(fpp2)
conv_houston <- avocado2 %>%
filter(region == "Houston",
type == "conventional") %>%
group_by(date) %>%
summarise(average_price = mean(average_price))
# Set up ts
conv_houston_ts <- ts(conv_houston$average_price,
start = c(2015, 1),
frequency = 52)
# Plot
autoplot(conv_houston_ts) +
labs(title = "Time plot: nonorganic avocado weekly prices in Houston",
y = "$") +
geom_point(colour = "brown", shape = 21) +
geom_path(colour = "brown")
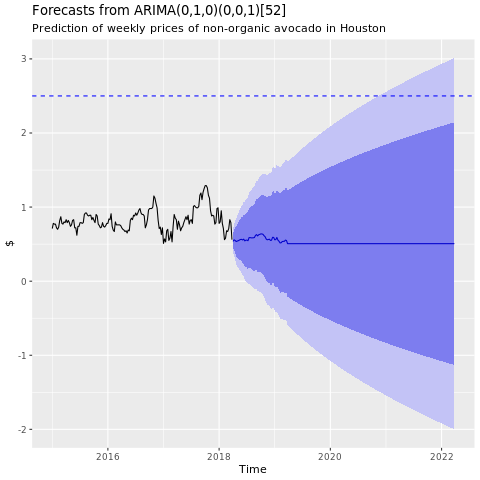
Обучение модели машинного обучения
Создайте модель прогнозирования цен для района Хьюстона на основе авторегресивного интегрированного скользящего среднего (ARIMA):
conv_houston_ts_arima <- auto.arima(conv_houston_ts,
d = 1,
approximation = F,
stepwise = F,
trace = T)
checkresiduals(conv_houston_ts_arima)
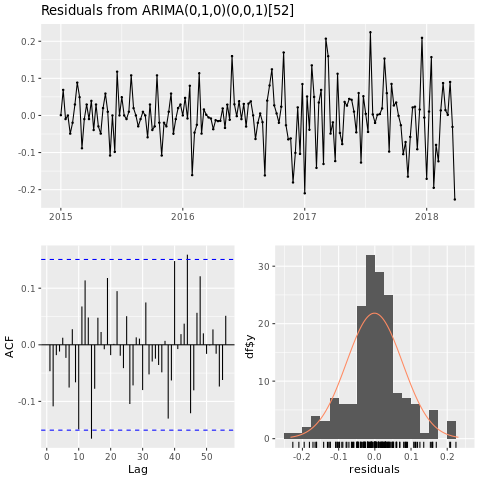
Отображение графа прогнозов из модели ARIMA Хьюстона:
conv_houston_ts_arima_fc <- forecast(conv_houston_ts_arima, h = 208)
autoplot(conv_houston_ts_arima_fc) + labs(subtitle = "Prediction of weekly prices of nonorganic avocados in Houston",
y = "$") +
geom_hline(yintercept = 2.5, linetype = 2, colour = "blue")