Руководство по отношениям "один к одному"
Эта статья предназначена для моделирователя данных, работающего с Power BI Desktop. Он предоставляет рекомендации по работе с отношениями модели "один к одному". Связь "один к одному" можно создать, если обе таблицы содержат столбец общих и уникальных значений.
Примечание.
Общие сведения о связях модели не рассматриваются в этой статье. Если вы не знакомы с связями, их свойствами или настройкой, рекомендуем сначала прочитать связи модели в статье Power BI Desktop .
Важно также понимать схему звездочки. Дополнительные сведения см. в статье "Общие сведения о схеме звезды" и важности для Power BI.
Существует два сценария, которые связаны с отношениями "один к одному":
Вырожденные измерения: вы можете наследить вырожденное измерение из таблицы типа фактов.
Диапазоны данных строк между таблицами: одна бизнес-сущность или тема загружается в виде двух (или более) таблиц моделей, возможно, так как их данные источникируются из разных хранилищ данных. Этот сценарий можно использовать для таблиц типов измерений. Например, основные сведения о продукте хранятся в операционной системе продаж, а дополнительные сведения о продукте хранятся в другом источнике.
Тем не менее, это необычно, что вы бы связывать две таблицы типа фактов с отношением "один к одному". Это связано с тем, что обе таблицы типа фактов должны иметь одинаковую размерность и степень детализации. Кроме того, для каждой таблицы типа фактов потребуются уникальные столбцы, позволяющие создать связь модели.
Вырожденные аналитики
Если столбцы из таблицы типа фактов используются для фильтрации или группировки, их можно сделать доступными в отдельной таблице. Таким образом, вы отделяете столбцы, используемые для фильтрации или группировки, от этих столбцов, используемых для суммирования строк фактов. Это разделение может:
- Сокращение места в хранилище
- Упрощение вычислений модели
- Повышение производительности запросов
- Предоставление более интуитивно понятной области полей авторам отчетов
Рассмотрим исходную таблицу продаж, в которой хранятся сведения о заказе на продажу в двух столбцах.
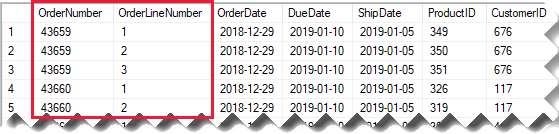
Столбец OrderNumber хранит номер заказа, а столбец OrderLineNumber хранит последовательность строк в заказе.
На следующей схеме модели обратите внимание, что столбцы номера заказа и номера строки заказа не были загружены в таблицу Sales . Вместо этого их значения использовались для создания суррогатного ключевого столбца с именем SalesOrderLineID. (Значение ключа вычисляется путем умножения номера заказа на 1000, а затем добавления номера строки заказа.)
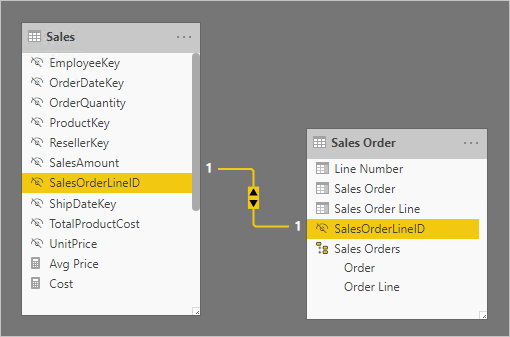
Таблица заказов на продажу предоставляет широкий интерфейс для авторов отчетов с тремя столбцами: Заказ на продажу, Строку заказа продаж и номер строки. Она также включает иерархию. Эти ресурсы таблиц поддерживают проекты отчетов, которые должны фильтровать, группировать по или детализации по заказам и строкам заказов.
Так как таблица заказа на продажу является производным от данных о продажах, в каждой таблице должно быть ровно одинаковое количество строк. Кроме того, следует сопоставить значения между каждым столбцом SalesOrderLineID .
Диапазоны данных строк между таблицами
Рассмотрим пример с двумя таблицами, связанными с измерением одного к одному: Product и Product Category. Каждая таблица представляет импортированные данные и содержит столбец SKU (единица хранения запасов), содержащий уникальные значения.
Ниже приведена частичная схема модели двух таблиц.
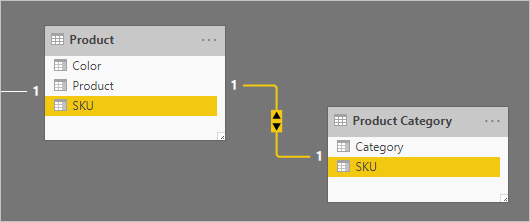
Первая таблица называется Product и содержит три столбца: Color, Product и SKU. Вторая таблица называется "Категория продукта", и она содержит два столбца: Категория и номер SKU. Связь "один к одному" связана с двумя столбцами SKU . Фильтры связей в обоих направлениях, которые всегда являются вариантом для связей "один к одному".
Чтобы узнать, как работает распространение фильтра связей, схема модели была изменена, чтобы отобразить строки таблицы. Все примеры в этой статье основаны на этих данных.
Примечание.
Невозможно отобразить строки таблицы на схеме модели Power BI Desktop. Это сделано в этой статье для поддержки обсуждения с четкими примерами.
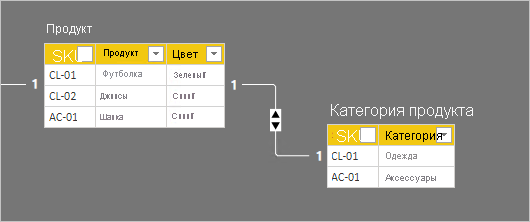
Сведения о строке для двух таблиц описаны в следующем маркированном списке:
- Таблица Product содержит три строки:
- SKU CL-01, футболка продукта , цвет зеленый
- SKU CL-02, Product Jeans, Color Blue
- SKU AC-01, Product Hat, Color Blue
- В таблице "Категория продукта" есть две строки:
- SKU CL-01, категория одежды
- SKU AC-01, аксессуары категории
Обратите внимание, что таблица "Категория продукта" не содержит строку для номера SKU продукта CL-02. Далее в этой статье мы обсудим последствия этой недостающей строки.
В области "Поля" авторы отчетов будут находить поля, связанные с продуктом, в двух таблицах: "Продукт" и "Категория продукта".
Давайте посмотрим, что происходит, когда поля из обеих таблиц добавляются в визуальный элемент таблицы. В этом примере столбец SKU создается из таблицы Product .
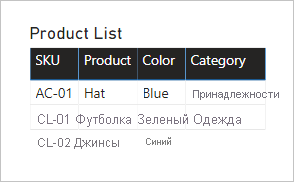
Обратите внимание, что значение категории для номера SKU продукта CL-02 — BLANK. Это связано с отсутствием строки в таблице "Категория продукта" для этого продукта.
Рекомендации
По возможности рекомендуется избегать создания связей модели "один к одному", когда данные строк охватывают таблицы моделей. Это связано с тем, что эта конструкция может:
- Участие в загромождировании области полей , перечисление больше таблиц, чем необходимо
- Усложняйте поиск связанных полей авторами отчетов, так как они распределяются по нескольким таблицам.
- Ограничение возможности создания иерархий, так как их уровни должны основываться на столбцах из той же таблицы.
- Создает непредвиденные результаты, если между таблицами не существует полного совпадения строк
Конкретные рекомендации различаются в зависимости от того, является ли связь "один к одному" внутри исходной группы или между исходными группами. Дополнительные сведения об оценке связей см. в разделе "Отношения модели" в Power BI Desktop (оценка отношений).
Связь внутри исходной группы "один к одному"
Если между таблицами существует связь одно к одному внутри исходной группы , рекомендуется объединить данные в одну таблицу моделей. Это делается путем объединения запросов Power Query.
Ниже приведена методология консолидации и моделирования данных, связанных с одним к одному:
Запросы слияния. При объединении двух запросов учитывайте полноту данных в каждом запросе. Если один запрос содержит полный набор строк (например, главный список), объедините другой запрос с ним. Настройте преобразование слияния, чтобы использовать левое внешнее соединение, которое является типом соединения по умолчанию. Этот тип соединения гарантирует, что все строки первого запроса будут храниться и дополнять их любыми соответствующими строками второго запроса. Разверните все необходимые столбцы второго запроса в первый запрос.
Отключить загрузку запроса: не забудьте отключить загрузку второго запроса. Таким образом, он не загрузит результат в виде таблицы моделей. Эта конфигурация уменьшает размер хранилища модели данных и помогает отключить область полей .
В нашем примере авторы отчетов теперь находят одну таблицу с именем Product в области "Поля ". Он содержит все поля, связанные с продуктом.
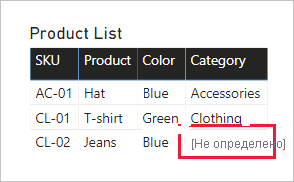
Замените отсутствующие значения: если второй запрос имеет несовпаденные строки, NULLs будут отображаться в столбцах, представленных из него. При необходимости рекомендуется заменить NULL значением маркера. Замена отсутствующих значений особенно важна, когда авторы отчетов фильтруют или группируют значения столбцов, так как BLANKs могут отображаться в визуальных элементах отчета.
В приведенном ниже визуальном элементе таблицы обратите внимание, что категория для номера SKU продукта CL-02 теперь считывает [Undefined]. В запросе категории NULL были заменены этим текстовым значением маркера.
Создание иерархий: если связи существуют между столбцами консолидированной таблицы, рассмотрите возможность создания иерархий. Таким образом авторы отчетов быстро определяют возможности для визуального бурения отчетов.
В нашем примере авторы отчетов теперь могут использовать иерархию с двумя уровнями: категория и продукт.
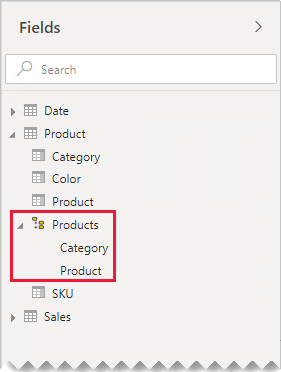
Если вы хотите, как отдельные таблицы помогают упорядочивать поля, мы по-прежнему рекомендуем объединить их в одну таблицу. Вы по-прежнему можете упорядочивать поля, но с помощью отображаемых папок .
В нашем примере авторы отчетов могут найти поле "Категория" в папке "Маркетинг".
Если вы по-прежнему решите определить связи одно к одному внутри исходной группы в модели, если это возможно, убедитесь, что в связанных таблицах имеются соответствующие строки. Как связь одно к одному внутри исходной группы оценивается как обычная связь, проблемы целостности данных могут возникнуть в визуальных элементах отчета как BLANK. (Пример группировки BLANK можно увидеть в первом визуальном элементе таблицы, представленном в этой статье.)
Перекрестная связь между исходной группой "один к одному"
Если между таблицами существует связь группы "один к одному" между таблицами, нет альтернативной модели, если вы не будете предварительно консолидировать данные в источниках данных. Power BI оценивает связь модели "один к одному" как ограниченную связь. Поэтому необходимо убедиться, что в связанных таблицах имеются соответствующие строки, так как несовпаденные строки будут исключены из результатов запроса.
Давайте посмотрим, что происходит, когда поля из обеих таблиц добавляются в визуальный элемент таблицы, а между таблицами существует ограниченная связь.
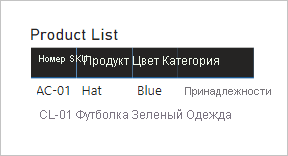
В таблице отображаются только две строки. Номер SKU продукта CL-02 отсутствует, так как в таблице "Категория продукта" отсутствует соответствующая строка.
Связанный контент
Дополнительные сведения, связанные с этой статьей, проверка следующие ресурсы:
Кері байланыс
Жақында қолжетімді болады: 2024 жыл бойы біз GitHub Issues жүйесін мазмұнға арналған кері байланыс механизмі ретінде біртіндеп қолданыстан шығарамыз және оны жаңа кері байланыс жүйесімен ауыстырамыз. Қосымша ақпаратты мұнда қараңыз: https://aka.ms/ContentUserFeedback.
Жіберу және пікірді көру