Применение связей "многие ко многим" в Power BI Desktop
С помощью связей с кратностью "многие ко многим" в Power BI Desktop можно объединить таблицы, использующие кратность "многие ко многим". Вы можете легко и интуитивно создавать модели данных, содержащие два или более источников данных. Связи с кратностью "многие ко многим" являются частью более крупных составных моделей в Power BI Desktop. Дополнительные сведения о составных моделях см. в разделе "Использование составных моделей в Power BI Desktop"
Какое отношение с кратностью "многие ко многим" решает
Прежде чем отношения с кратностью "многие ко многим" стали доступными, связь между двумя таблицами была определена в Power BI. По крайней мере один из столбцов таблицы, участвующих в связи, должен содержать уникальные значения. Зачастую столбцы не содержат уникальных значений.
Например, две таблицы могут иметь столбец с меткой CountryRegion. Однако значения CountryRegion не были уникальными в любой таблице. Чтобы присоединиться к таким таблицам, необходимо было создать обходное решение. Одним из обходных решений может быть введение дополнительных таблиц с необходимыми уникальными значениями. С помощью связей с кратностью "многие ко многим" можно присоединить такие таблицы напрямую, если вы используете связь с кратностью "многие ко многим".
Использование связей с кратностью "многие ко многим"
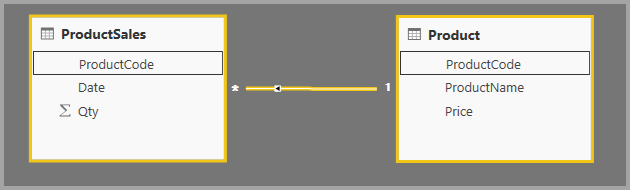
При определении связи между двумя таблицами в Power BI необходимо определить кратность связи. Например, связь между ProductSales и Product —с помощью столбцов ProductSales[ProductCode] и Product[ProductCode]— будет определена как Многие-1. Таким образом мы определяем связь, так как каждый продукт имеет много продаж, а столбец в таблице Product (ProductCode) является уникальным. При определении кратности связи как "многие", "1-многие" или "1-1" Power BI проверяет его, поэтому кратность, которую вы выбираете, соответствует фактическим данным.
Например, взгляните на простую модель на этом изображении:
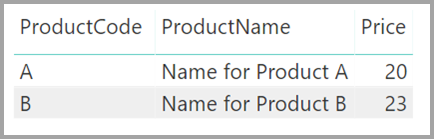
Теперь представьте, что таблица Product отображает только две строки, как показано ниже.
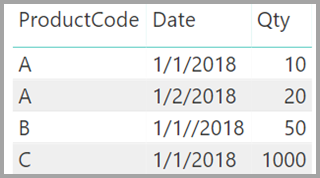
Кроме того, представьте, что в таблице Sales есть всего четыре строки, включая строку для продукта C. Из-за ошибки целостности ссылок строка C продукта не существует в таблице Product .
Имя продукта и цена (из таблицы Product), а также общее количество Qty для каждого продукта (из таблицы ProductSales), будет отображаться, как показано ниже.
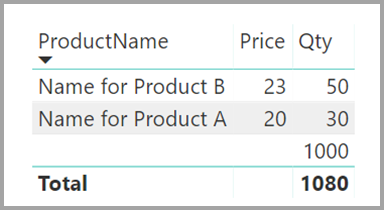
Как видно на предыдущем рисунке, пустая строка ProductName связана с продажами для продукта C. Эта пустая строка учитывает следующие аспекты:
Все строки в таблице ProductSales, для которой в таблице ProductSales нет соответствующей строки. Существует проблема с целостностью ссылок, как мы видим для продукта C в этом примере.
Все строки в таблице ProductSales , для которой столбец внешнего ключа имеет значение NULL.
По этим причинам пустая строка в обоих случаях учитывает продажи, где имя продукта и цена неизвестны.
Иногда таблицы объединяются двумя столбцами, но ни столбец не является уникальным. Например, рассмотрим следующие две таблицы:
В таблице "Продажи" отображаются данные о продажах по состоянию, а каждая строка содержит сумму продаж для типа продажи в этом состоянии. К состояниям относятся ЦС, WA и TX.
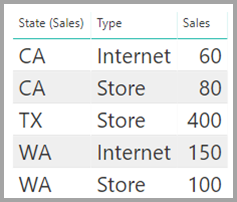
В таблице CityData отображаются данные о городах, включая население и состояние (например, CA, WA и Нью-йорк).
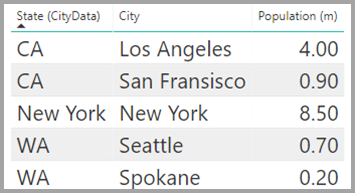
Столбец для состояния теперь находится в обеих таблицах. Разумно сообщить о общих продажах по состоянию и общему населению каждого штата. Однако проблема существует: столбец state не является уникальным в любой таблице.
Предыдущее решение
До выпуска Power BI Desktop за июль 2018 г. невозможно создать прямую связь между этими таблицами. Обычное решение заключается в том, чтобы:
Создайте третью таблицу, содержащую только уникальные идентификаторы состояния. Таблица может быть любой или любой из следующих:
- Вычисляемая таблица (определяемая с помощью выражений анализа данных [DAX]).
- Таблица на основе запроса, который определен в Редакторе Power Query; он может отображать уникальные идентификаторы, извлеченные из одной из таблиц.
- Объединенный полный набор.
Затем соотносите две исходные таблицы с этой новой таблицей с помощью общих связей "Многие-1 ".
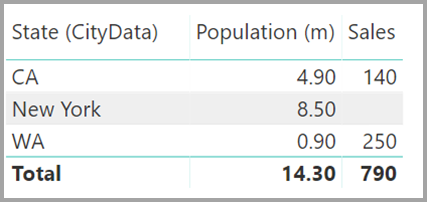
Вы можете оставить таблицу обходного решения видимой. Или вы можете скрыть таблицу обходного решения, поэтому она не отображается в списке полей . Если вы скрываете таблицу, отношения "Многие-1 " обычно задаются для фильтрации в обоих направлениях, и можно использовать поле "Состояние" из любой таблицы. Последняя перекрестная фильтрация будет распространяться на другую таблицу. Этот подход показан на следующем рисунке:
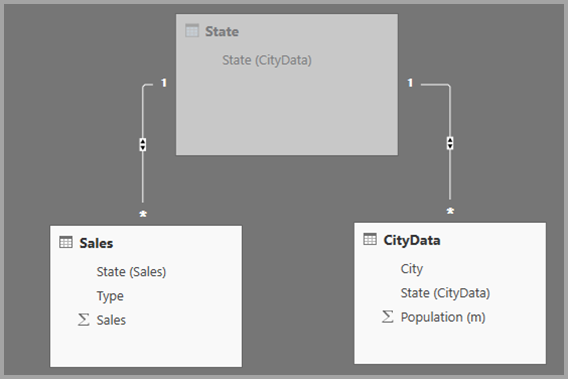
Визуальный элемент, отображающий состояние (из таблицы CityData), а также общее население и общее количество продаж, будет отображаться следующим образом:
Примечание.
Так как состояние из таблицы CityData используется в этом обходном пути, отображаются только состояния в этой таблице, поэтому TX исключается. Кроме того, в отличие от связей "Многие-1 ", в то время как общая строка включает все продажи (включая TX), сведения не содержат пустой строки, охватывающие такие несовпадения строк. Аналогичным образом, пустая строка не будет охватывать продажи , для которых имеется значение NULL для состояния.
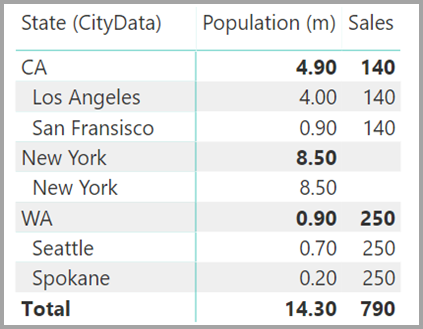
Предположим, вы также добавляете город в этот визуальный элемент. Хотя население каждого города известно, продажи, отображаемые для города, просто повторяет продажи для соответствующего штата. Этот сценарий обычно возникает, когда группирование столбцов не связано с какой-то статистической мерой, как показано ниже.
Предположим, что вы определяете новую таблицу Sales как сочетание всех государств здесь, и мы делаем ее видимой в списке полей . Тот же визуальный элемент будет отображать состояние (в новой таблице), общее население и общее количество продаж:
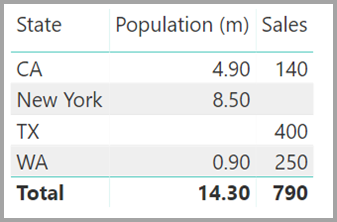
Как видно, TX с данными о продажах, но неизвестными данными о популяции ( и Нью-йорке) с известными данными о населении, но не будут включены данные о продажах. Это решение не является оптимальным, и у него есть много проблем. Для связей с кратностью "многие ко многим" возникают возникающие проблемы, как описано в следующем разделе.
Дополнительные сведения о реализации этого обходного решения см . в руководстве по связям "многие ко многим".
Используйте связь с кратностью "многие ко многим" вместо обходного решения
Вы можете напрямую связать таблицы, такие как описанные ранее, не прибегая к аналогичным обходным решениям. Теперь можно задать кратность отношений ко многим. Этот параметр указывает, что ни одна таблица не содержит уникальных значений. Для таких связей можно по-прежнему контролировать, какие таблицы фильтруют другую таблицу. Кроме того, можно применить двунаправленную фильтрацию, где каждая таблица фильтрует другую.
В Power BI Desktop кратность по умолчанию по умолчанию используется для многих, если она определяет, что ни одна таблица не содержит уникальные значения для столбцов связи. В таких случаях предупреждение подтверждает, что вы хотите установить связь, и что изменение не является нежелательным эффектом проблемы с данными.
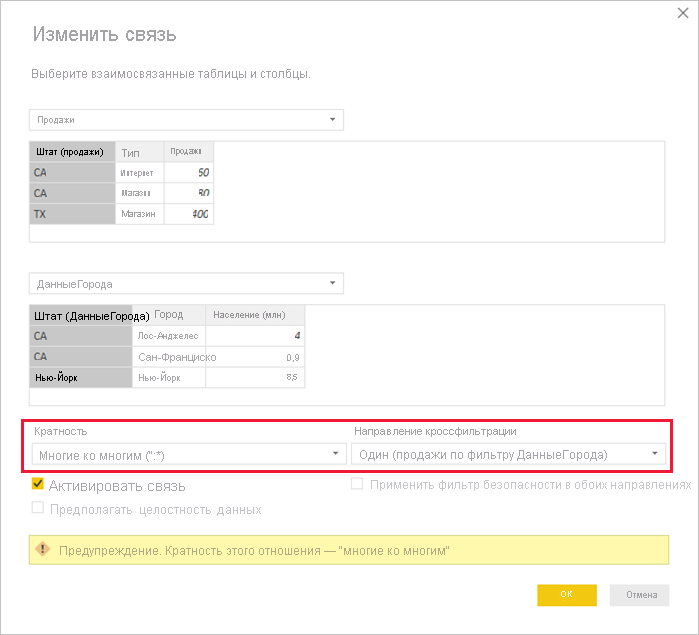
Например, при создании связи непосредственно между CityData и Sales ( где фильтры должны передаваться из CityData в Sales— Power BI Desktop отображает диалоговое окно "Изменить связь ":
В результате представления связей будет отображаться прямая связь "многие ко многим" между двумя таблицами. Внешний вид таблиц в списке полей и их последующее поведение при создании визуальных элементов аналогично применению обходного решения. В обходном пути дополнительная таблица, отображающая отдельные данные состояния, не отображается. Как описано ранее, будет отображаться визуальный элемент, в котором отображаются данные о состоянии, популяции и продажах :
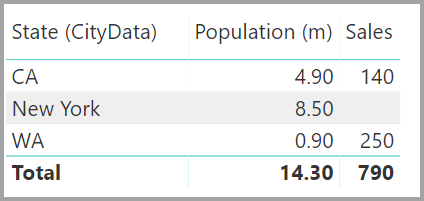
Основные различия между связями с кратностью "многие ко многим" и более типичными отношениями "Многие-1 " являются следующими:
Отображаемые значения не включают пустую строку, которая учитывает несовпадение строк в другой таблице. Кроме того, значения не учитывают строки, в которых столбец, используемый в связи в другой таблице, имеет значение NULL.
Вы не можете использовать функцию
RELATED(), так как может быть связана несколько строк.ALL()Использование функции в таблице не удаляет фильтры, применяемые к другим связанным таблицам с помощью связи "многие ко многим". В предыдущем примере мера, определяемая здесь, не удаляет фильтры для столбцов в связанной таблице CityData:![Снимок экрана: пример скрипта. Пример: Sales total = Calculate(Sum('Sales'[Sales]), All('Sales')).](media/desktop-many-to-many-relationships/many-to-many-relationships_13.png)
Визуальный элемент с общими данными состояния, продаж и продаж приведет к следующему рисунку:
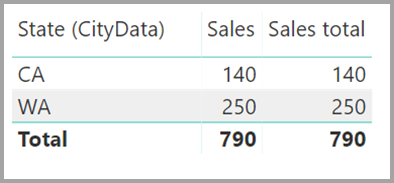
Учитывая предыдущие различия, убедитесь, что используемые вычисления ALL(<Table>), такие как % общего объема, возвращают предполагаемые результаты.
Рекомендации и ограничения
Существует несколько ограничений для этого выпуска связей с кратностью "многие ко многим" и составными моделями.
Следующие источники Live Connect (многомерные) нельзя использовать с составными моделями:
- SAP HANA
- Хранилище SAP для бизнеса
- SQL Server Analysis Services
- Семантические модели Power BI
- Azure Analysis Services
При подключении к этим многомерным источникам с помощью DirectQuery невозможно подключиться к другому источнику DirectQuery или объединить его с импортированными данными.
Существующие ограничения использования DirectQuery по-прежнему применяются при использовании связей с кратностью "многие ко многим". Теперь для каждой таблицы существует множество ограничений в зависимости от режима хранения таблицы. Например, вычисляемый столбец импортированной таблицы может ссылаться на другие таблицы, но вычисляемый столбец в таблице DirectQuery по-прежнему может ссылаться только на столбцы в той же таблице. Другие ограничения применяются ко всей модели, если какие-либо таблицы в модели являются DirectQuery. Например, функции QuickInsights и Q&A недоступны в модели, если в ней есть режим хранения DirectQuery.
Связанный контент
Дополнительные сведения о составных моделях и DirectQuery см. в следующих статьях: