Оқиға
Power BI DataViz әлем чемпионаты
Feb 14, 4 PM - Mar 31, 4 PM
Кіруге 4 мүмкіндікпен конференция пакетін ұтып, оны Лас-Вегастағы LIVE Grand Финалына шығаруға болар еді
Қосымша мәліметтерБұл браузерге бұдан былай қолдау көрсетілмейді.
Соңғы мүмкіндіктерді, қауіпсіздік жаңартуларын және техникалық қолдауды пайдалану үшін Microsoft Edge браузеріне жаңартыңыз.
ОБЛАСТЬ ПРИМЕНЕНИЯ: ![]() Служба Power BI Power BI Desktop
Служба Power BI Power BI Desktop ![]()
Визуальный элемент ключевых факторов влияния помогает понять факторы, которые управляют метрикой, интересующей вас. Он анализирует данные, ранжирует факторы, которые имеют значение, и отображает их как ключевые факторы влияния. Например, предположим, вы хотите выяснить, что влияет на оборот сотрудников, который также называется оттоком. Один фактор может быть продолжительностью контракта на работу, а другой фактор может быть временем коммутировать.
Визуальный элемент ключевых факторов влияния является отличным выбором, если вы хотите:
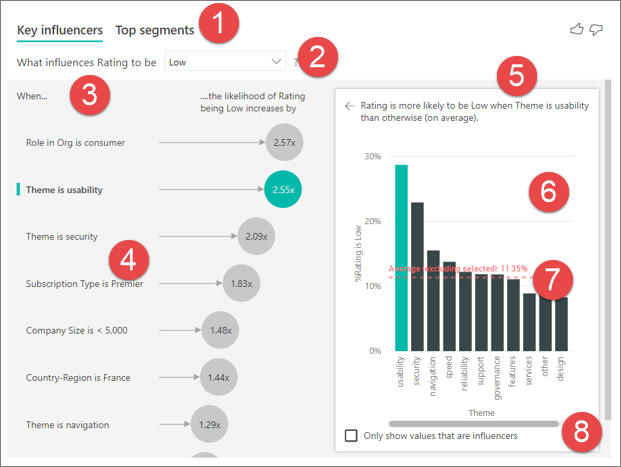
Вкладки: выберите вкладку и переключитесь между представлениями. Ключевые факторы влияния показывают наиболее важных участников выбранного значения метрик. Верхние сегменты отображают верхние сегменты , которые вносят вклад в выбранное значение метрик. Сегмент состоит из сочетания значений. Например, один сегмент может быть потребителями, которые являются долгосрочными клиентами и живут в западном регионе.
Раскрывающийся список: значение метрики, подследуемой. В этом примере просмотрите рейтинг метрик. Выбранное значение — Low.
Перенаправка: это помогает интерпретировать визуальный элемент в левой области.
Левая область: левая панель содержит один визуальный элемент. В этом случае в левой области отображается список ключевых факторов влияния верхнего ключа.
Перебор. Это помогает интерпретировать визуальный элемент в правой области.
Справа: справа панель содержит один визуальный элемент. В этом случае на диаграмме столбцов отображаются все значения темы влияния ключа, выбранной на левой панели. Определенное значение удобства использования на левой панели отображается зеленым цветом. Все остальные значения темы отображаются черным цветом.
Средняя строка: среднее вычисляется для всех возможных значений темы , кроме удобства использования (который является выбранным фактором влияния). Поэтому вычисление применяется ко всем значениям в черном цвете. Он сообщает вам, какой процент других тем имел низкий рейтинг. В этом случае 11,35% имели низкую оценку (показанную пунктирной линией).
Флажок. Отфильтровывает визуальный элемент в правой области, чтобы отобразить только значения, влияющие на это поле. В этом примере визуальный элемент фильтруется для отображения удобства использования, безопасности и навигации.
Ескерім
Набор данных отзывов клиентов основан на [Moro et al., 2014] S. Moro, P. Cortez и P. Rita. "Подход на основе данных для прогнозирования успеха банковского телемаркетинга". Системы поддержки принятия решений, Elsevier, 62:22-31, июнь 2014 года.
В разделе "Создание визуального элемента" на панели "Визуализации" выберите значок "Ключевые факторы влияния".
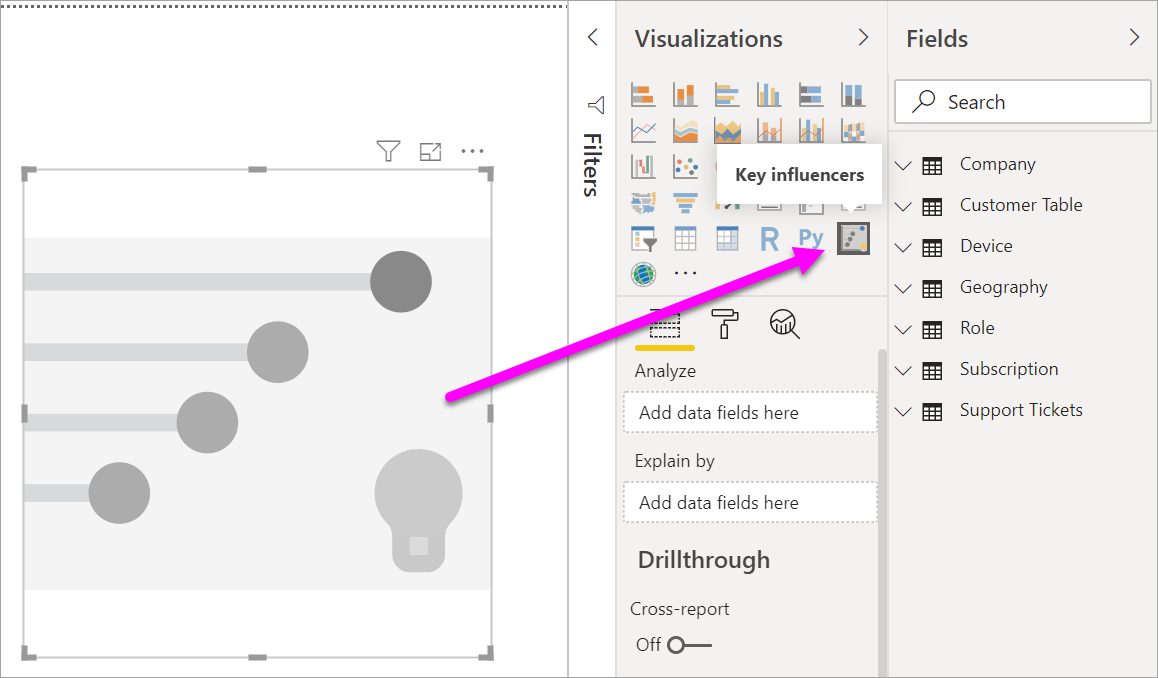
Переместите метрику, которую нужно исследовать в поле "Анализ ". Чтобы узнать, что приводит к низкому рейтингу клиента службы, выберите "Рейтинг таблицы>клиентов".
Перемещение полей, которые вы считаете, может повлиять на рейтинг в поле "Объяснение по ". Можно переместить столько полей, сколько нужно. В этом случае начните с:
Оставьте поле "Развернуть по пустому". Это поле используется только при анализе меры или суммированного поля.
Чтобы сосредоточиться на отрицательных оценках, выберите "Низкий " в раскрывающемся списке "Что влияет на рейтинг".
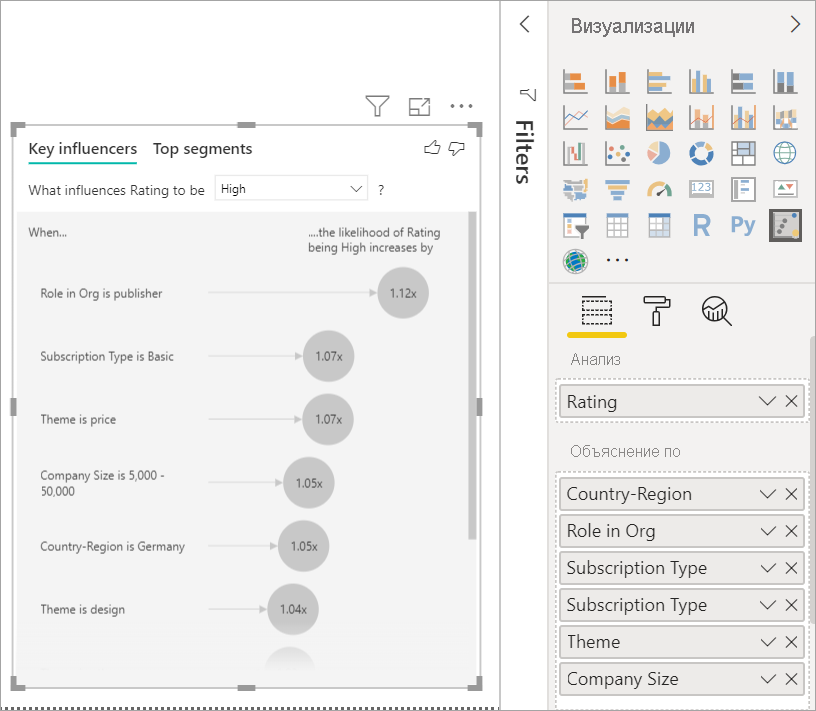
Анализ выполняется на уровне таблицы поля, которое анализируется. В этом случае это метрика рейтинга . Эта метрика определяется на уровне клиента. Каждый клиент дает либо высокую оценку, либо низкую оценку. Все пояснительные факторы должны быть определены на уровне клиента, чтобы визуальный элемент использовал их.
В предыдущем примере все пояснительные факторы имеют связь "один к одному" или "многие ко одному" с метрикой. В этом случае каждому клиенту назначена одна тема их рейтингу. Аналогичным образом клиенты приходят из одной страны или региона, имеют один тип членства и занимают одну роль в своей организации. Пояснительные факторы уже являются атрибутами клиента, и преобразования не требуются. Визуальный элемент может немедленно использовать их.
Далее в руководстве вы узнаете о более сложных примерах, которые имеют связи "один ко многим". В таких случаях столбцы необходимо сначала агрегировать до уровня клиента, прежде чем выполнять анализ.
Меры и агрегаты, используемые в качестве пояснительных факторов, также оцениваются на уровне таблицы метрики анализа . Ниже приведены некоторые примеры.
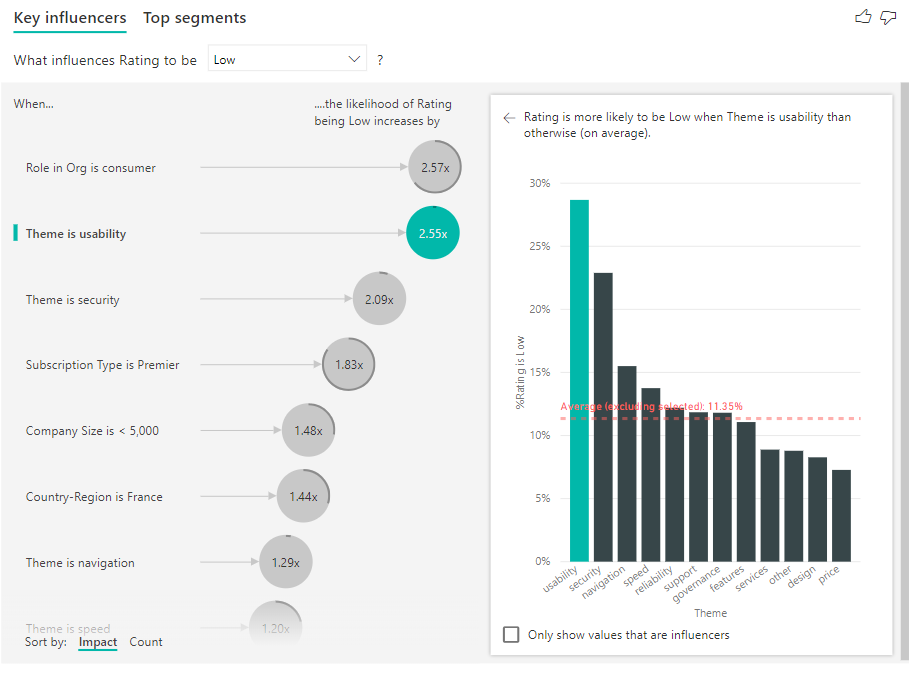
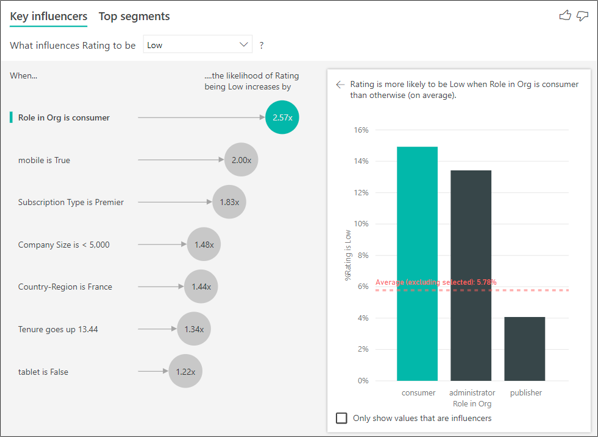
Давайте рассмотрим ключевые факторы влияния для низких рейтингов.
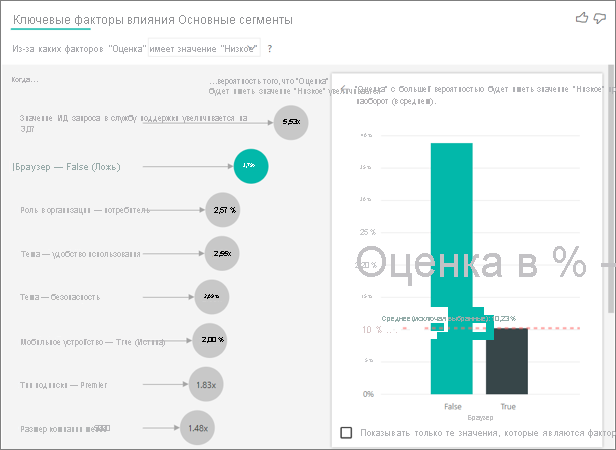
Клиент в этом примере может иметь три роли: потребитель, администратор и издатель. Будучи потребителем является главным фактором, который способствует низкому рейтингу.
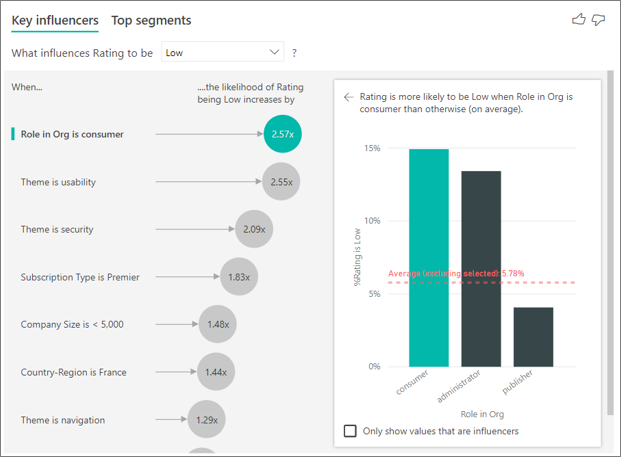
Более точно, ваши потребители 2,57 раза чаще дают вашей службе отрицательный показатель. Диаграмма ключевых факторов влияния выводит список роли в организации — это потребитель в списке слева. Выбрав роль в организации, Power BI отображает дополнительные сведения в правой области. Показано сравнительное влияние каждой роли на вероятность низкой оценки.
Визуальный элемент ключевых факторов влияния сравнивает и ранжирует факторы из множества различных переменных. Второй фактор влияния не имеет ничего общего с ролью в организации. Выберите второй фактор влияния в списке, который является темой, является удобством использования.
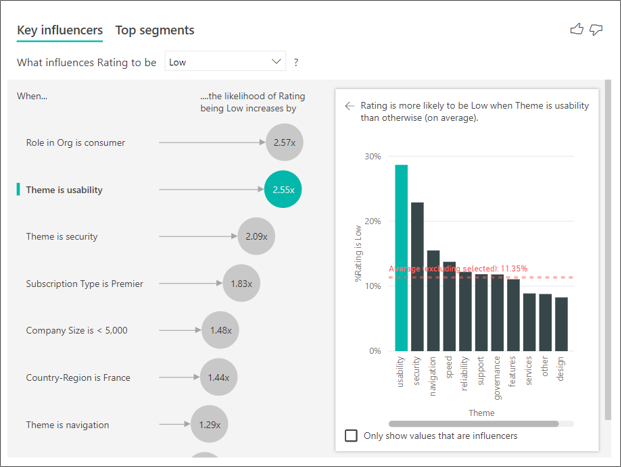
Второй наиболее важный фактор связан с темой обзора клиента. Клиенты, которые прокомментировали удобство использования продукта, были 2,55 раза чаще, чтобы дать низкую оценку по сравнению с клиентами, которые комментировали другие темы, такие как надежность, дизайн или скорость.
Между визуальными элементами среднее значение, отображаемое красной пунктирной линией, изменилось с 5,78% до 11,35%. Среднее значение является динамическим, так как оно основано на среднем всех остальных значений. Для первого влияния средний исключена роль клиента. Для второго влияния он исключил тему удобства использования.
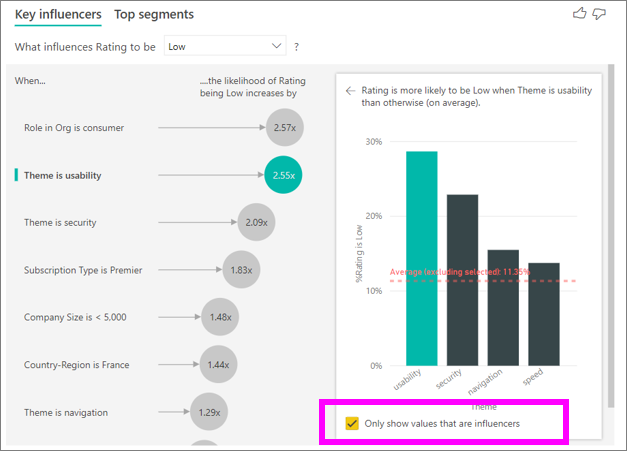
Установите флажок "Только показывать значения" для фильтрации только влиятельных значений. В этом случае это роли, которые управляют низкой оценкой. Двенадцать тем сокращаются до четырех, которые Power BI определяет как темы, которые управляют низкими рейтингами.
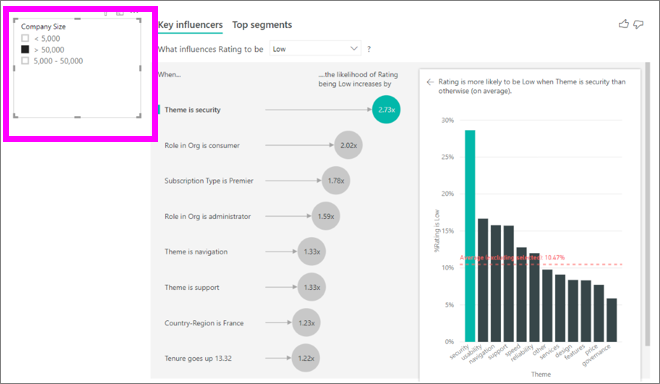
Каждый раз, когда вы выбираете срез, фильтр или другой визуальный элемент на холсте, визуальный элемент, влияющий на ключевые факторы, повторно запускает анализ новой части данных. Например, можно переместить размер компании в отчет и использовать его в качестве среза. Используйте его, чтобы узнать, отличаются ли ключевые факторы влияния для ваших корпоративных клиентов от общего населения. Корпоративный размер компании превышает 50 000 сотрудников.
Выберите >50 000, чтобы повторно запустить анализ, и вы увидите, что факторы влияния изменились. Для крупных корпоративных клиентов главный фактор влияния для низких рейтингов имеет тему, связанную с безопасностью. Вам может потребоваться изучить дополнительные сведения о наличии конкретных функций безопасности, о которых ваши крупные клиенты не удовлетворены.
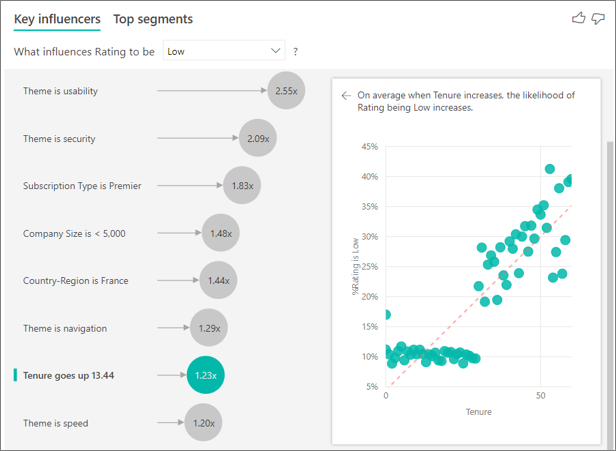
До сих пор вы узнали, как использовать визуальный элемент для изучения того, как различные категориальные поля влияют на низкие рейтинги. Кроме того, можно иметь непрерывные факторы, такие как возраст, высота и цена в поле "Объяснить по полю ". Давайте рассмотрим, что происходит при перемещении срока действия из таблицы клиента в "Объяснение". Срок пребывания в должности показывает, сколько времени клиент использует службу.
По мере увеличения срока пребывания вероятность получения более низкой оценки также увеличивается. Эта тенденция предполагает, что долгосрочные клиенты, скорее всего, дают негативную оценку. Это понимание интересно, и то, что вы можете продолжить позже.
Визуализация показывает, что каждый раз, когда срок пребывания в должности растет на 13,44 месяца, в среднем вероятность низкого рейтинга увеличивается на 1,23 раза. В этом случае 13,44 месяца изображают стандартное отклонение должности. Таким образом, понимание, которое вы получаете, смотрит на то, как увеличение срока пребывания на уровне стандартного уровня, которое является стандартным отклонением срока пребывания, влияет на вероятность получения низкой оценки.
Точечная диаграмма на правой панели отображает средний процент низких оценок для каждого значения пребывания. Он выделяет склон с линией тренда.
В некоторых случаях вы можете обнаружить, что ваши непрерывные факторы были автоматически преобразованы в категориальные. Если связь между переменными не является линейной, мы не можем описать связь как простое увеличение или уменьшение (например, в предыдущем примере).
Мы запускаем тесты корреляции, чтобы определить, как линейный фактор влияния сравнивается с целевым объектом. Если целевой объект является непрерывным, мы запускаем корреляцию Пирсона и если целевой объект категориальный, мы запускаем тесты корреляции Point Biserial. Если мы обнаруживаем, что связь не является достаточно линейной, мы проводим защищенное бинирование и создадим не более пяти ячеек. Чтобы выяснить, какие ячейки лучше всего подходят, мы используем защищенный метод binning. Защищенный метод binning рассматривает связь между пояснительным фактором и объектом анализа целевого объекта.
Вы можете использовать меры и агрегаты в качестве пояснительных факторов в анализе. Например, какой эффект влияет на количество запросов в службу поддержки клиентов на оценку, которую вы получаете. Или, что влияет на среднюю продолжительность открытого билета на оценку, которую вы получаете.
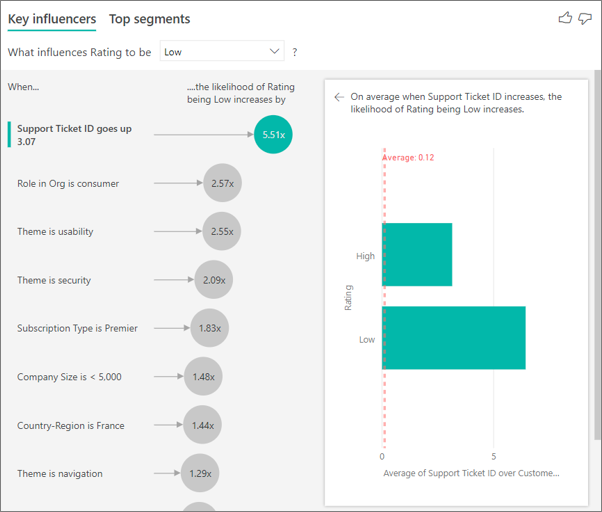
В этом случае вы хотите узнать, влияет ли количество запросов в службу поддержки, которое клиент влияет на оценку, которую они дают. Теперь вы введете идентификатор запроса в службу поддержки из таблицы запросов в службу поддержки. Так как у клиента может быть несколько запросов в службу поддержки, вы объединяете идентификатор на уровень клиента. Агрегирование важно, так как анализ выполняется на уровне клиента, поэтому все драйверы должны быть определены на этом уровне детализации.
Рассмотрим количество идентификаторов. Каждая строка клиента имеет количество запросов в службу поддержки, связанных с ним. В этом случае, по мере увеличения количества запросов в службу поддержки вероятность того, что рейтинг будет низким, растет 4,08 раза. Снимок экрана: среднее количество запросов в службу поддержки по разным значениям оценки , оцененным на уровне клиента.
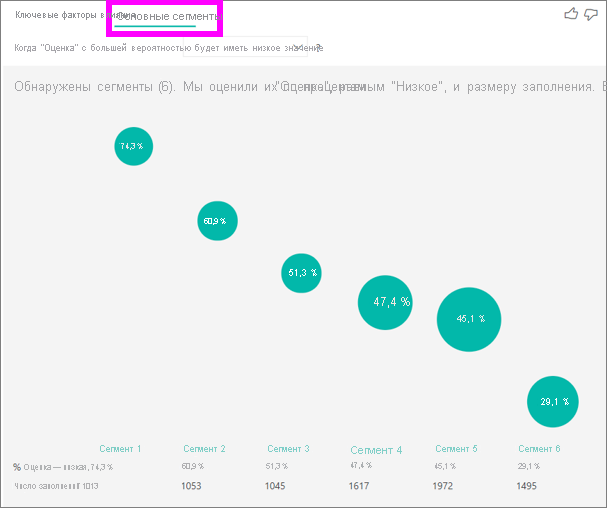
Вы можете использовать вкладку "Ключевые факторы влияния" для оценки каждого фактора по отдельности. Вы также можете использовать вкладку "Верхние сегменты" , чтобы узнать, как сочетание факторов влияет на метрику, которую вы анализируете.
Первые сегменты изначально отображают обзор всех обнаруженных сегментов Power BI. В следующем примере показано, что найдены шесть сегментов. Процент низких рейтингов в сегменте определяет рейтинг. Сегмент 1, например, имеет 74,3% оценок клиентов, которые являются низкими. Чем выше пузырь, тем выше доля низких рейтингов. Размер пузырька представляет количество клиентов в сегменте.
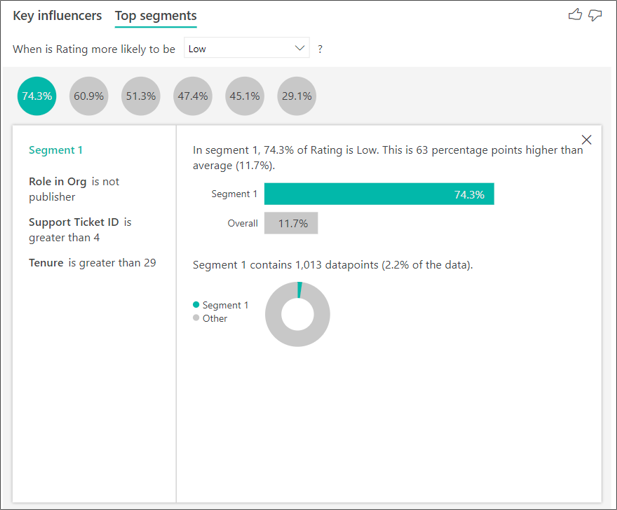
При выборе пузырька отображаются сведения об этом сегменте. Если выбрать сегмент 1, например, вы обнаружите, что он представляет установленных клиентов. Они были клиентами более 29 месяцев и имеют более четырех запросов в службу поддержки. Наконец, они не издатели, поэтому они либо потребители, либо администраторы.
В этой группе 74,3% клиентов дали низкий рейтинг. Средний клиент дал низкий рейтинг 11,7% времени, поэтому этот сегмент имеет большую долю низких рейтингов. Это 63 процентных пункта выше. Сегмент 1 также содержит около 2,2% данных, поэтому он представляет адресную часть населения.
Иногда влияние может иметь значительный эффект, но представлять мало данных. Например, тема является удобством использования третий самый большой фактор влияния для низких рейтингов. Однако, возможно, было только горстка клиентов, которые жаловались на удобство использования. Счетчики помогут вам определить приоритеты, на какие факторы влияния вы хотите сосредоточиться.
Вы можете включить счетчики с помощью карточки анализа области форматирования.

После включения счетчиков вы увидите кольцо вокруг пузыря каждого влияния, представляющего приблизительный процент данных, содержащихся в нем. Чем больше пузырьков круги, тем больше данных он содержит. Мы видим, что тема является удобством использования, содержит небольшую долю данных.
Вы также можете использовать сортировку, переключив в левом нижнем углу визуального элемента, чтобы отсортировать пузырьки по счетчику, а не влиять. Тип подписки — Premier — это главный фактор влияния, основанный на подсчете.
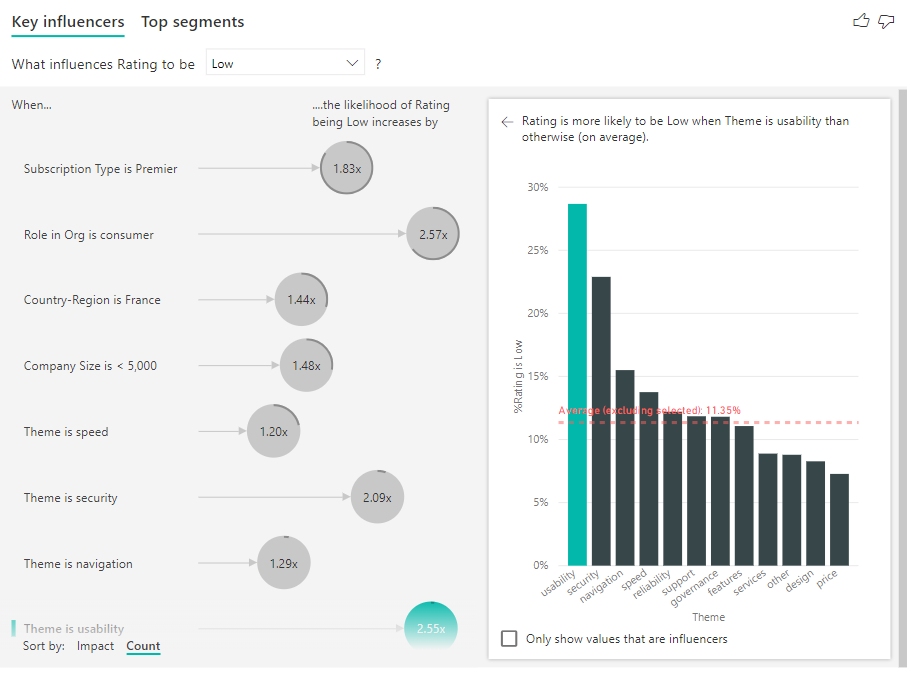
Наличие полного кольца вокруг круга означает, что влияние содержит 100% данных. Тип счетчика можно изменить относительно максимального влияния с помощью раскрывающегося списка "Число " в карточке анализа области форматирования. Теперь влияние с наибольшим объемом данных представлено полным кольцом, и все остальные счетчики относительно него.
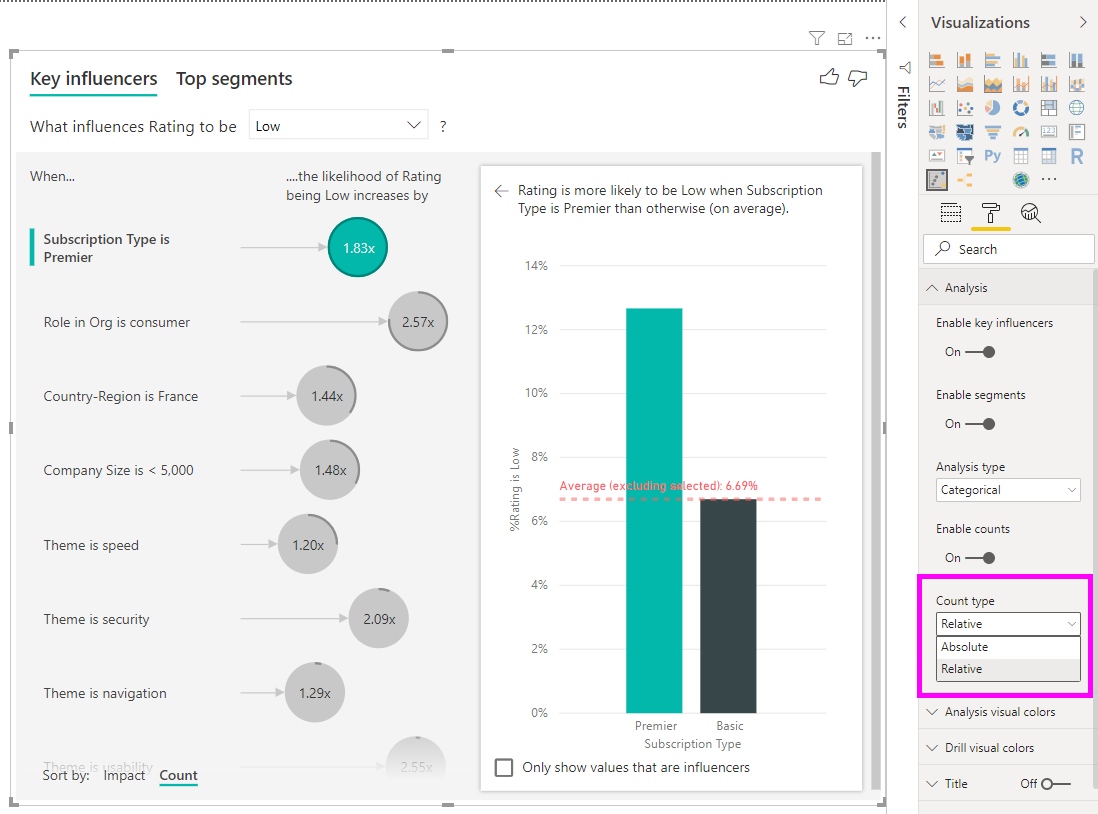
При перемещении неумммаризованного числового поля в поле "Анализ " вы можете выбрать способ обработки этого сценария. Вы можете изменить поведение визуального элемента, перейдя в область форматирования и переключившись между типом категориального анализа и типом непрерывного анализа.
Тип категориального анализа описан ранее в этой статье. Например, если вы посмотрите на оценки опроса в диапазоне от 1 до 10, вы можете спросить"Что влияет на оценки опросов, чтобы быть 1?"
Тип непрерывного анализа изменяет вопрос на непрерывный. Используя предыдущий пример, наш новый вопрос : "Что влияет на оценки опросов для увеличения/уменьшения?"
Это различие полезно при наличии большого количества уникальных значений в поле, которое вы анализируете. В следующем примере мы рассмотрим цены на жилье. Это не понятно, чтобы спросить "Что влияет на цену дома 156 214?", так как это конкретно, и мы, скорее всего, не должны иметь достаточно данных для вывода шаблона.
Вместо этого мы можем попросить: "Что влияет на цену на жилье для увеличения", что позволяет нам рассматривать цены на жилье как диапазон, а не отдельные значения.
Ескерім
В примерах этого раздела используются данные о ценах на жилье общего домена. Вы можете скачать пример набора данных, если вы хотите продолжить.
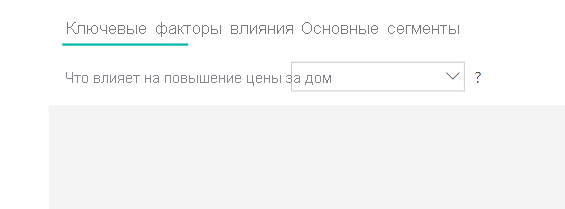
В этом сценарии мы рассмотрим "Что влияет на цену на дом для увеличения". Ряд пояснительных факторов может повлиять на цену дома, как Год построен (год был построен дом), КухняQual (качество кухни), и YearRemodAdd (год был перестроен дом).
В приведенном ниже примере мы рассмотрим наш лучший фактор влияния, который является качество кухни отлично. Результаты похожи на те, которые мы видели, когда мы анализирули категориальные метрики с несколькими важными различиями:
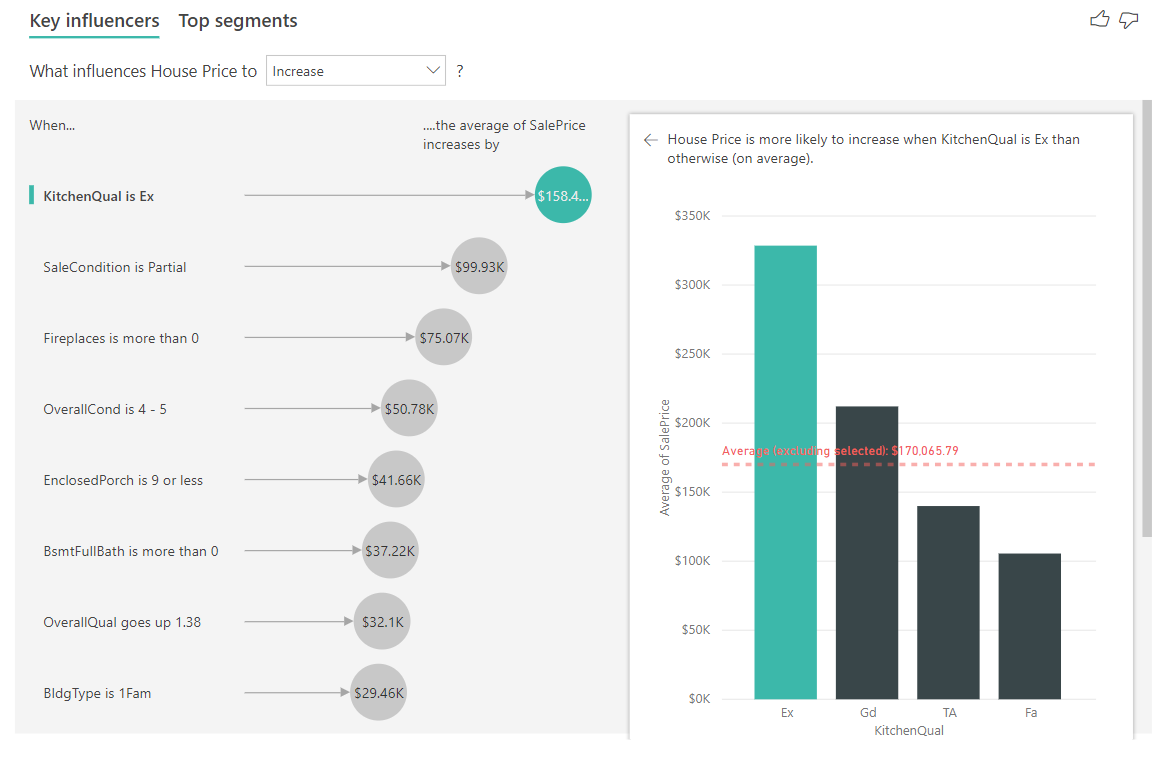
В приведенном ниже примере мы рассмотрим влияние непрерывного фактора (год дом был перемоделирован) на цену на жилье. Различия по сравнению с тем, как анализировать непрерывные факторы влияния для категориальных метрик, как показано ниже.
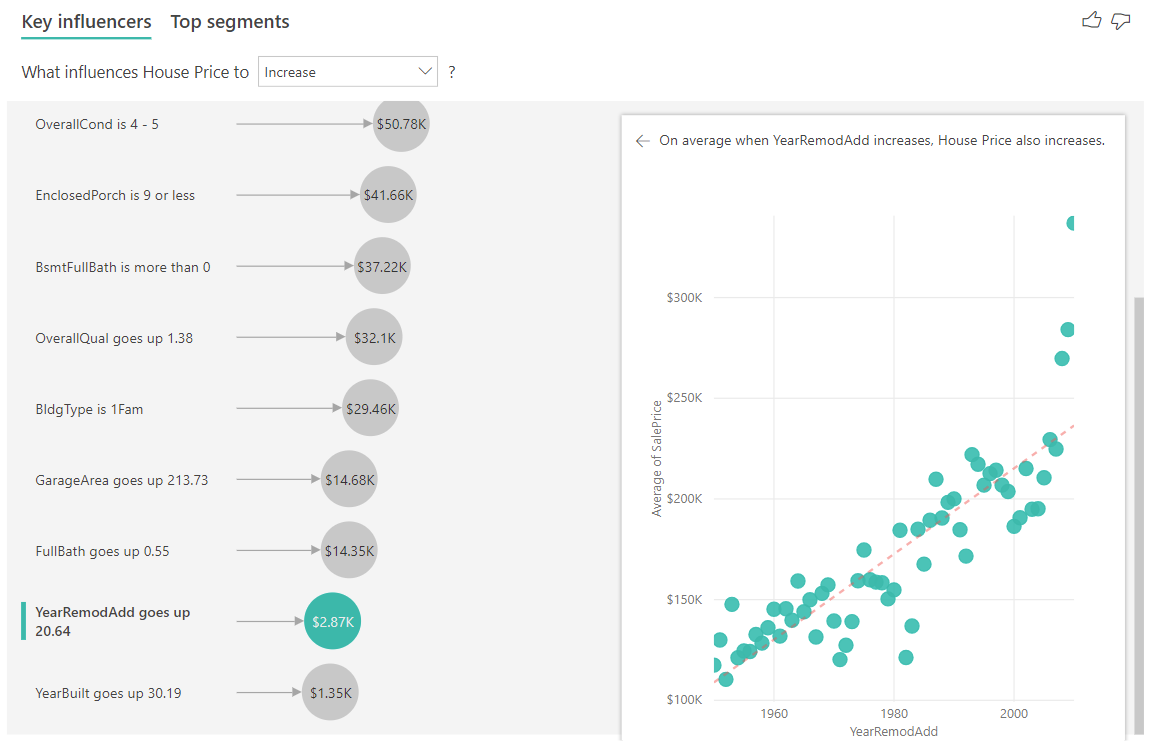
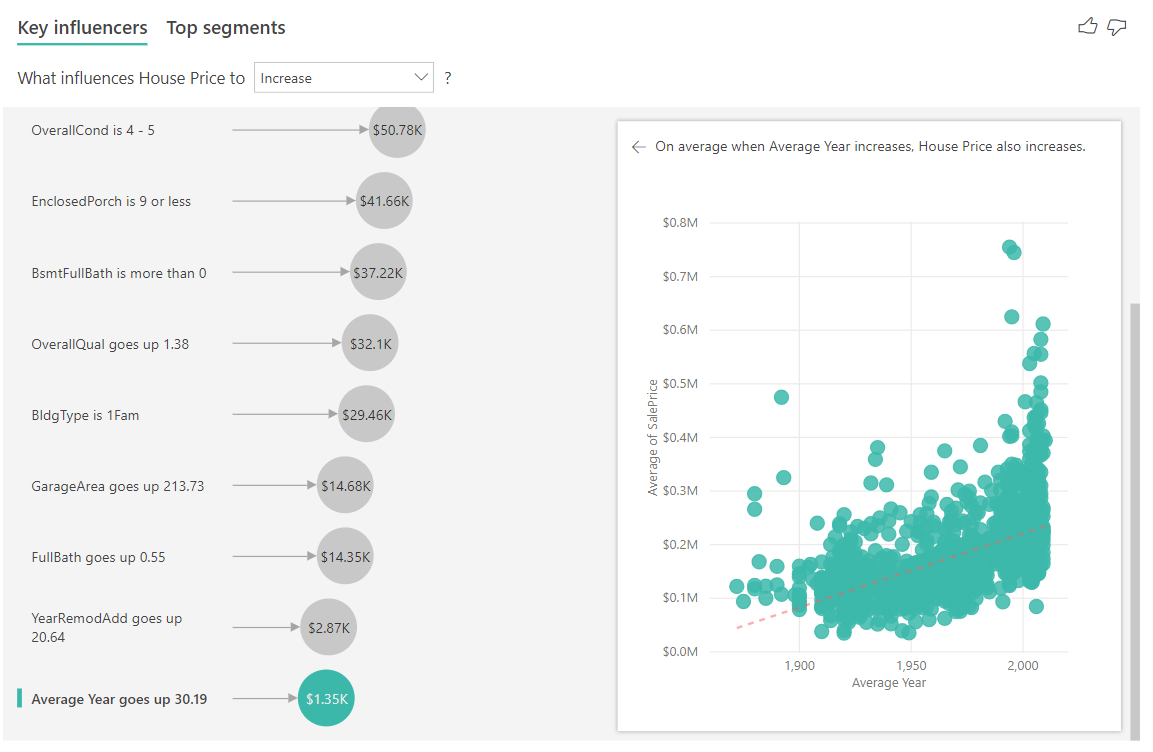
Наконец, в случае мер, мы смотрим на средний год дом был построен. Анализ выглядит следующим образом:
Основные сегменты для числовых целевых объектов показывают группы, где цены на жилье в среднем выше, чем в общем наборе данных. Например, ниже мы видим, что сегмент 1 состоит из домов, где ГаражКары (количество автомобилей, которые гараж может поместиться) больше 2, и Крыша с хипом. Дома с этими характеристиками имеют среднюю цену

Для измерения или сводного столбца анализ по умолчанию используется тип непрерывного анализа, описанный ранее в этой статье. Это значение нельзя изменить. Самое большое различие между анализом столбца или суммированного столбца и неуправляемым числовым столбцом является уровень, на котором выполняется анализ.
Для неуправляемых столбцов анализ всегда выполняется на уровне таблицы. В примере цены на жилье мы проанализировали метрику цен на дом, чтобы увидеть, что влияет на цену на жилье для увеличения/уменьшения. Анализ автоматически выполняется на уровне таблицы. Наша таблица имеет уникальный идентификатор для каждого дома, поэтому анализ выполняется на уровне дома.
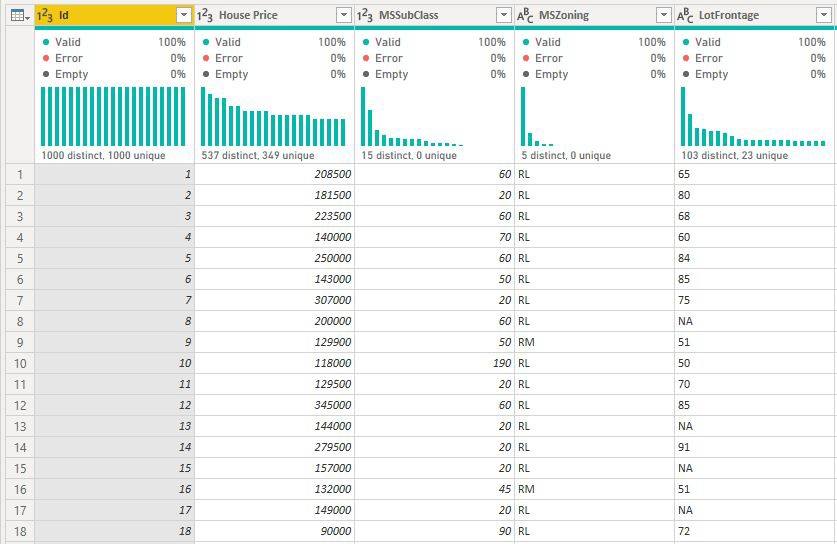
Для мер и суммированных столбцов мы не сразу знаем, на каком уровне их анализировать. Если цена на жилье была суммирована как средняя, нам потребуется рассмотреть уровень, который мы хотели бы, чтобы эта средняя цена на жилье вычислялась. Это средняя цена на жилье на уровне района? Или, возможно, региональный уровень?
Меры и суммированные столбцы автоматически анализируются на уровне поля "Объяснение" по используемым полям . Представьте, что мы хотим изучить три поля в объяснении: Качество кухни, тип здания и кондиционер. Средняя цена дома будет вычисляться для каждого уникального сочетания этих трех полей. Часто полезно переключиться на представление таблицы, чтобы посмотреть, как выглядят данные.
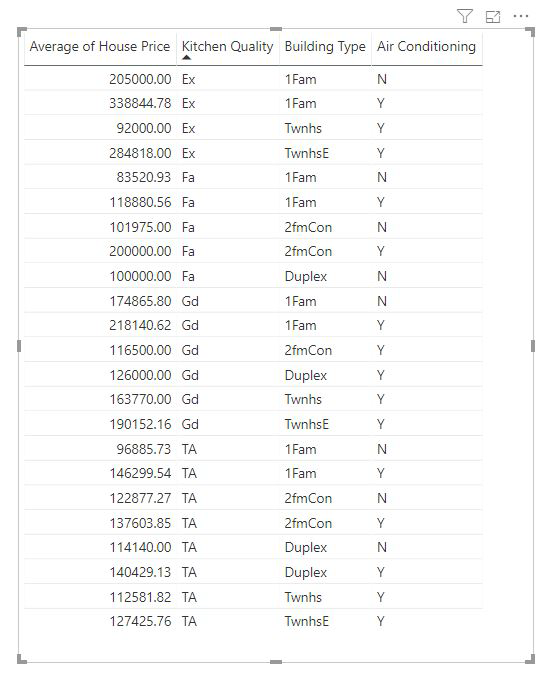
Этот анализ очень обобщен и поэтому может оказаться сложной для модели регрессии найти любые шаблоны в данных, на которых он может учиться. Мы должны выполнить анализ на более подробном уровне, чтобы получить лучшие результаты. Если бы мы хотели проанализировать цену на жилье на уровне дома, нам потребуется явно добавить поле идентификатора в анализ. Тем не менее, мы не хотим, чтобы идентификатор дома считался влиятельным. Это не полезно, чтобы узнать, что по мере увеличения идентификатора дома, цена дома увеличивается. Здесь хорошо подходит параметр "Развернуть по полю". Чтобы добавить поля, которые необходимо использовать для настройки уровня анализа, можно использовать для добавления полей без поиска новых факторов влияния.
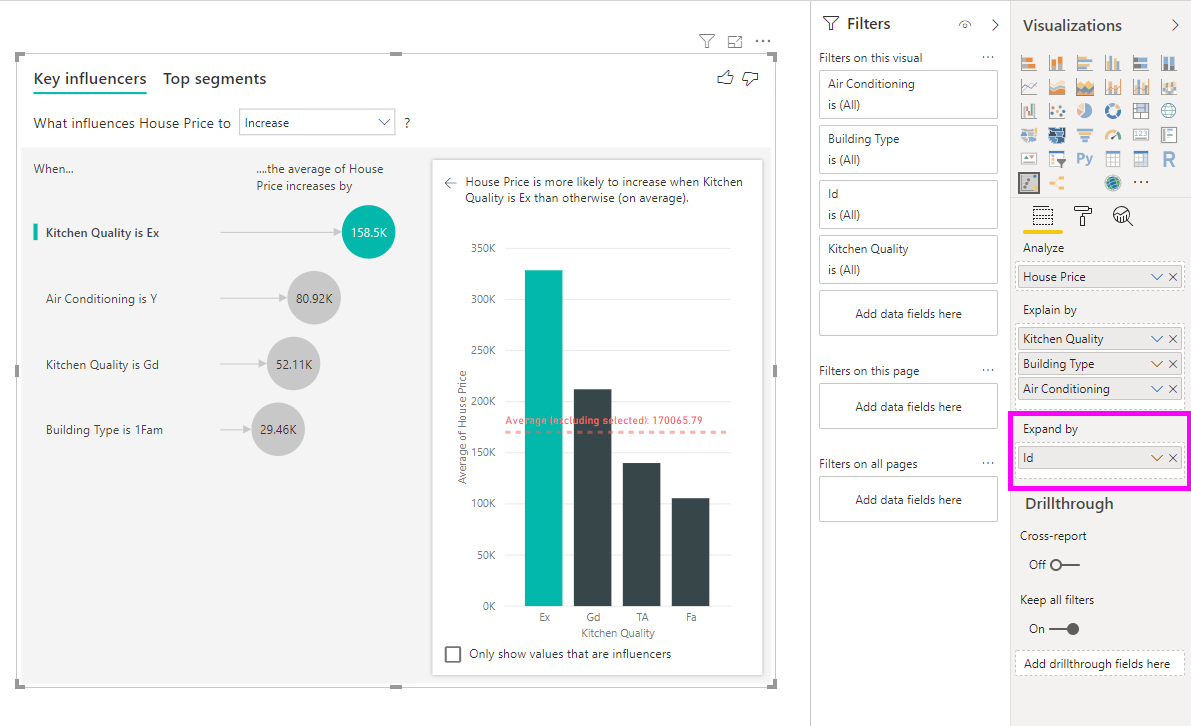
Ознакомьтесь с тем, как выглядит визуализация после добавления идентификатора к развертыванию. Определив уровень, на котором вы хотите оценить меру, интерпретация факторов влияния точно аналогична неумеченным числовым столбцам.
Сведения о том, как Power BI использует ML.NET за кулисами, чтобы понять данные и аналитические сведения о поверхности естественным образом, см. в статье Power BI идентифицирует ключевые факторы влияния с помощью ML.NET.
Каковы ограничения для визуального элемента?
Визуальный элемент ключевых факторов влияния имеет некоторые ограничения:
Я вижу ошибку, что не найдены факторы влияния или сегменты. Почему так?
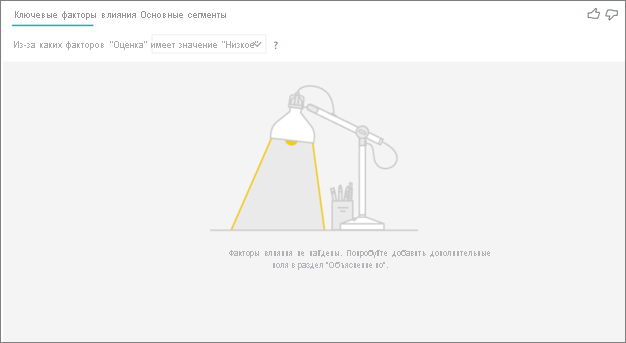
Эта ошибка возникает при добавлении полей в "Объяснение" , но не найдены факторы влияния.
Я вижу ошибку, в которую я анализирую метрику, не хватает данных для выполнения анализа. Почему так?

Визуализация работает путем просмотра шаблонов в данных для одной группы по сравнению с другими группами. Например, он ищет клиентов, которые дали низкие рейтинги по сравнению с клиентами, которые дали высокие рейтинги. Если данные в модели имеют только несколько наблюдений, шаблоны трудно найти. Если визуализация не имеет достаточно данных для поиска значимых факторов влияния, это означает, что для выполнения анализа требуется больше данных.
Рекомендуется иметь по крайней мере 100 наблюдений для выбранного состояния. В этом случае государство — это клиенты, которые вырвали. Кроме того, вам потребуется не менее 10 наблюдений за состояниями, которые вы используете для сравнения. В этом случае состояние сравнения — это клиенты, которые не выполняют операции.
Если вы анализируете числовое поле, может потребоваться перейти от категориального анализа к непрерывному анализу в области форматирования под карточкой анализа.
Я вижу ошибку, что при необобновленном анализе анализ всегда выполняется на уровне строк родительской таблицы. Изменение этого уровня с помощью полей "Развернуть по" не допускается. Почему так?
При анализе числового или категориального столбца анализ всегда выполняется на уровне таблицы. Например, если вы анализируете цены на жилье, а таблица содержит столбец идентификаторов, анализ автоматически выполняется на уровне идентификатора дома.
При анализе меры или сводного столбца необходимо явно указать, на каком уровне необходимо выполнить анализ. Вы можете использовать expand, чтобы изменить уровень анализа для мер и суммированных столбцов, не добавляя новые факторы влияния. Если цена на жилье была определена как мера, можно добавить столбец идентификатора дома, чтобы расширить , чтобы изменить уровень анализа.
Я вижу ошибку, что поле в "Объяснить" не связано с таблицей, содержащей метрики, которую я анализирую. Почему так?
Анализ выполняется на уровне таблицы поля, которое анализируется. Например, если вы анализируете отзывы клиентов о вашей службе, возможно, у вас может быть таблица, которая указывает, дал ли клиент высокий рейтинг или низкий рейтинг. В этом случае анализ выполняется на уровне таблицы клиента.
Если у вас есть связанная таблица, определенная на более детальном уровне, чем таблица, содержащая метрику, вы увидите эту ошибку. Приведем пример:
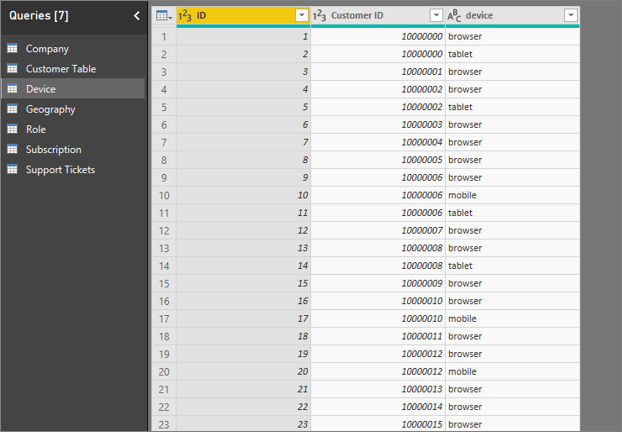
Если вы пытаетесь использовать столбец устройства в качестве объяснительного фактора, вы увидите следующую ошибку:

Эта ошибка возникает, так как устройство не определено на уровне клиента. Один клиент может использовать службу на нескольких устройствах. Для поиска шаблонов визуализации устройство должно быть атрибутом клиента. Существует несколько решений, которые зависят от вашего понимания бизнеса:
В этом примере данные были сводные для создания новых столбцов для браузера, мобильных устройств и планшетов (убедитесь, что вы удаляете и повторно создаете связи в представлении моделирования после сводки данных). Теперь эти конкретные устройства можно использовать в "Объяснении". Все устройства оказываются влиятельными, и браузер имеет наибольшее влияние на оценку клиентов.
Точнее, клиенты, которые не используют браузер для использования службы, 3,79 раза чаще дают низкую оценку, чем клиенты, которые делают. Вниз в списке для мобильных устройств обратное значение имеет значение true. Клиенты, использующие мобильное приложение, скорее всего, дают низкую оценку, чем клиенты, которые этого не делают.
Я вижу предупреждение о том, что меры не были включены в мой анализ. Почему так?
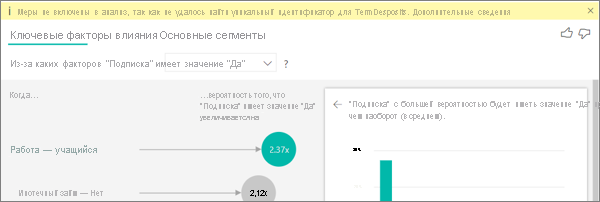
Анализ выполняется на уровне таблицы поля, которое анализируется. При анализе оттока клиентов может появиться таблица, которая сообщает о том, был ли клиент сворачен или нет. В этом случае анализ выполняется на уровне таблицы клиента.
Меры и агрегаты по умолчанию анализируются на уровне таблицы. Если бы была мера для средних ежемесячных расходов, она будет проанализирована на уровне таблицы клиента.
Если в таблице клиента нет уникального идентификатора, вы не можете оценить меру, и она игнорируется анализом. Чтобы избежать этой ситуации, убедитесь, что таблица с метрикой имеет уникальный идентификатор. В этом случае это таблица клиента, а уникальный идентификатор — идентификатор клиента. Кроме того, можно легко добавить столбец индекса с помощью Power Query.
Я вижу предупреждение о том, что метрика, которую я анализирую, имеет более 10 уникальных значений, и что эта сумма может повлиять на качество анализа. Почему так?
Визуализация ИИ может анализировать категориальные поля и числовые поля. Для категориальных полей может быть значение "Чурн" — "Да" или "Нет", а "Удовлетворенность клиентов" — "Высокий", "Средний" или "Низкий". Увеличение числа категорий для анализа означает, что на каждую категорию меньше наблюдений. Эта ситуация затрудняет поиск шаблонов в данных визуализации.
При анализе числовых полей у вас есть выбор между обработкой числовых полей, таких как текст, в этом случае выполняется тот же анализ, что и для категориальных данных (категориальный анализ). Если у вас много различных значений, рекомендуется переключить анализ на непрерывный анализ , так как это означает, что мы можем выводить шаблоны, когда числа увеличиваются или уменьшаются, а не рассматривать их как отдельные значения. Вы можете переключаться с категориального анализа на непрерывный анализ в области форматирования на карточке анализа.
Чтобы найти более сильные факторы влияния, рекомендуется группировать аналогичные значения в одну единицу. Например, если у вас есть метрика по цене, скорее всего, вы получите лучшие результаты путем группировки аналогичных цен на категории "Высокий", "Средний" и "Низкий" и "Низкий" с использованием отдельных ценовых точек.
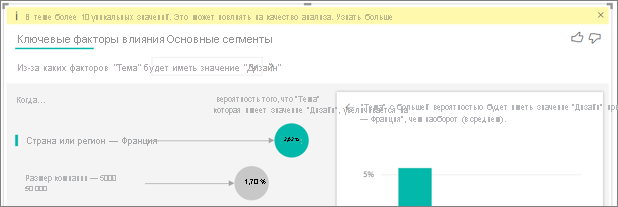
Есть факторы в моих данных, которые выглядят так, как они должны быть ключевыми факторами влияния, но они не являются. Как это может произойти?
В следующем примере клиенты, являющиеся потребителями, управляют низкими рейтингами, с 14,93% рейтингов, которые являются низкими. Роль администратора также имеет высокую долю низких рейтингов, на 13,42%, но это не считается влиянием.
Причина этого определения заключается в том, что визуализация также учитывает количество точек данных при обнаружении факторов влияния. В следующем примере более 29 000 потребителей и 10 раз меньше администраторов, около 2900. Только 390 из них дали низкий рейтинг. Визуальный элемент не имеет достаточно данных, чтобы определить, найден ли он шаблон с оценками администратора или если это просто шанс найти.
Каковы ограничения точек данных для ключевых факторов влияния? Мы запускаем анализ на выборке из 10 000 точек данных. Пузыри на одной стороне показывают все найденные факторы влияния. Диаграммы столбцов и точечная диаграмма на другой стороне соблюдают стратегии выборки для этих основных визуальных элементов.
Как вычислить ключевые факторы влияния для категориального анализа?
Визуализация искусственного интеллекта использует ML.NET для выполнения логистической регрессии для вычисления ключевых факторов влияния. Логистическая регрессия — это статистическая модель, которая сравнивает разные группы друг с другом.
Если вы хотите увидеть, что приводит к низкому рейтингу, логистическая регрессия смотрит на то, как клиенты, которые дали низкий показатель отличаются от клиентов, которые дали высокий показатель. Если у вас несколько категорий, таких как высокие, нейтральные и низкие оценки, вы посмотрите, как клиенты, которые дали низкий рейтинг, отличаются от клиентов, которые не дали низкий рейтинг. В этом случае, как клиенты, которые дали низкую оценку, отличаются от клиентов, которые дали высокий рейтинг или нейтральный рейтинг?
Логистическая регрессия ищет шаблоны в данных и ищет, как клиенты, которые дали низкий рейтинг, могут отличаться от клиентов, которые дали высокий рейтинг. Например, это может найти, что клиенты с большим количеством запросов в службу поддержки дают более высокий процент низких рейтингов, чем клиенты с несколькими или без запросов в службу поддержки.
Логистическая регрессия также учитывает количество точек данных. Например, если клиенты, которые играют роль администратора, дают пропорционально более отрицательные оценки, но есть только несколько администраторов, этот фактор не считается влиятельным. Это определение сделано, так как для вывода шаблона недостаточно точек данных. Статистический тест, известный как тест Вальда, используется для определения того, считается ли фактор фактором влияния. Визуальный элемент использует p-значение 0,05 для определения порогового значения.
Как вычислить ключевые факторы влияния для числового анализа?
Визуализация искусственного интеллекта использует ML.NET для выполнения линейной регрессии для вычисления ключевых факторов влияния. Линейная регрессия — это статистическая модель, которая смотрит на то, как результат поля, которое вы анализируете изменения на основе объяснительных факторов.
Например, если мы анализируем цены на жилье, линейная регрессия смотрит на эффект, который имеет отличную кухню hAs на цену дома. Дома с отличной кухней обычно имеют более низкие или более высокие цены на жилье по сравнению с домами без отличной кухни?
Линейная регрессия также учитывает количество точек данных. Например, если дома с теннисными кортами имеют более высокие цены, но у нас есть несколько домов с теннисным кортом, этот фактор не считается влиятельным. Это определение сделано, так как для вывода шаблона недостаточно точек данных. Статистический тест, известный как тест Вальда, используется для определения того, считается ли фактор фактором влияния. Визуальный элемент использует p-значение 0,05 для определения порогового значения.
Как вычислить сегменты?
За кулисами визуализация ИИ использует ML.NET для запуска дерева принятия решений для поиска интересных подгрупп. Цель дерева принятия решений заключается в том, чтобы в конечном итоге получить подгруппу точек данных, которые относительно высоки в интересующей вас метрике. Это могут быть клиенты с низким рейтингом или домами с высокими ценами.
Дерево принятия решений принимает каждый объясняющий фактор и пытается поставить причину, какой фактор дает ему лучший раскол. Например, если вы фильтруете данные для включения только крупных корпоративных клиентов, это отделяет клиентов, которые дали высокий рейтинг и низкий рейтинг? Или, возможно, лучше отфильтровать данные, чтобы включить только клиентов, которые прокомментировали безопасность?
После разделения дерева принятия решений она принимает подгруппу данных и определяет следующий лучший разбиение для этих данных. В этом случае подгруппа — это клиенты, которые комментировали безопасность. После каждого разделения дерево принятия решений также считает, достаточно ли у этой группы точек данных, чтобы быть достаточно репрезентативным, чтобы определить шаблон. Если нет, то это аномалия в данных, а не реальный сегмент. Еще один статистический тест применяется для проверки статистической важности условия разделения с p-значением 0,05.
После завершения работы дерева принятия решений все разбиения, такие как комментарии по безопасности и крупные предприятия, и создает фильтры Power BI. Это сочетание фильтров упаковается в виде сегмента в визуальном элементе.
Почему некоторые факторы становятся влиятельными или перестают быть влиятельными, так как я перемещаю больше полей в объяснение по полю ?
Визуализация оценивает все пояснительные факторы вместе. Фактор может быть влиянием сам по себе, но при рассмотрении с другими факторами он может не быть. Предположим, вы хотите проанализировать, что приводит к высокой цене дома, с спальнями и размером дома в качестве объяснительных факторов:
Для предоставления общего доступа к отчету коллеге Power BI необходимо иметь отдельные лицензии Power BI Pro или сохранить отчет в емкости Premium. См . отчеты о совместном доступе.
Оқиға
Power BI DataViz әлем чемпионаты
Feb 14, 4 PM - Mar 31, 4 PM
Кіруге 4 мүмкіндікпен конференция пакетін ұтып, оны Лас-Вегастағы LIVE Grand Финалына шығаруға болар еді
Қосымша мәліметтерОқыту
Оқыту бағдарламасы
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization
Сертификаттау
Демонстрация методов и рекомендаций, которые соответствуют бизнес-и техническим требованиям для моделирования, визуализации и анализа данных с помощью Microsoft Power BI.
Құжаттама
Дерево декомпозиции - Power BI
Руководство. Создание визуализации дерева декомпозиции в Power BI
Создание умных сводок по повествованию - Power BI
Создайте интеллектуальные визуализации повествования в Power BI, чтобы предоставить краткий текст визуальных элементов и отчетов.
Руководство по обнаружению аномалий - Power BI
Узнайте, как использовать обнаружение аномалий Power BI Desktop для добавления аномалий, форматирования аномалий и просмотра и настройки объяснений.