Рекомендации по проектированию и разработке сложных потоков данных
Если поток данных, который вы разрабатываете, становится больше и сложнее, ниже приведены некоторые действия, которые можно сделать, чтобы улучшить исходный дизайн.
Разбить его на несколько потоков данных
Не выполняйте все в одном потоке данных. Не только один сложный поток данных делает процесс преобразования данных более длинным, он также затрудняет понимание и повторное использование потока данных. Разбиение потока данных в несколько потоков данных можно сделать, разделив таблицы в разных потоках данных или даже одну таблицу в несколько потоков данных. Вы можете использовать концепцию вычисляемой таблицы или связанной таблицы для сборки части преобразования в одном потоке данных и повторно использовать ее в других потоках данных.
Разделение потоков данных преобразования данных из промежуточных и извлечения потоков данных
Наличие некоторых потоков данных только для извлечения данных (то есть промежуточного потока данных) и других только для преобразования данных полезно не только для создания многослойной архитектуры, но и для снижения сложности потоков данных. Некоторые шаги просто извлекают данные из источника данных, например получение данных, навигации и изменения типов данных. Разделив промежуточные потоки данных и потоки данных преобразования, вы упрощаете разработку потоков данных.
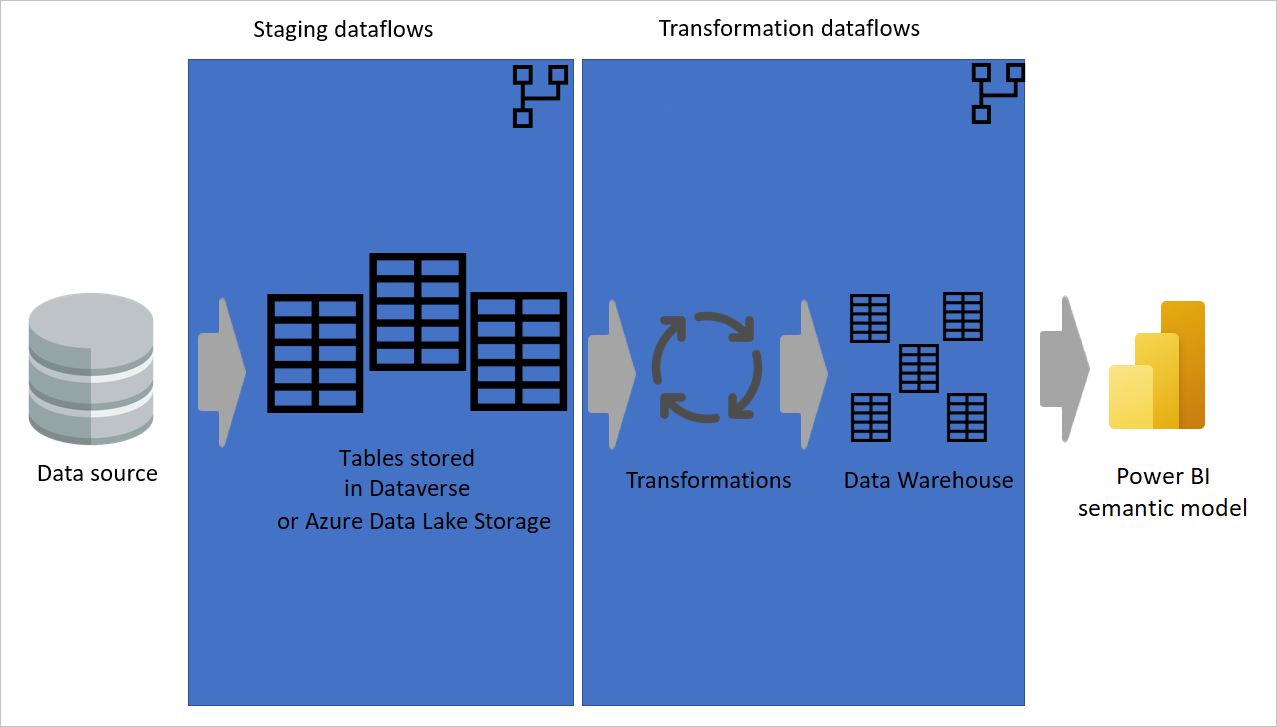
Изображение, показывающее извлечение данных из источника данных в промежуточные потоки данных, где таблицы хранятся в Dataverse или в хранилище Azure Data Lake. Затем данные перемещаются в потоки данных преобразования, в которых данные преобразуются и преобразуются в структуру хранилища данных. Затем данные перемещаются в семантику модели.
Использование пользовательских функций
Пользовательские функции полезны в сценариях, когда необходимо выполнить определенное количество шагов для ряда запросов из разных источников. Пользовательские функции можно разрабатывать с помощью графического интерфейса в Редактор Power Query или с помощью скрипта M. Функции можно повторно использовать в потоке данных в столько таблиц, сколько необходимо.
Наличие пользовательской функции помогает иметь только одну версию исходного кода, поэтому вам не нужно дублировать код. В результате поддержание логики преобразования Power Query и всего потока данных гораздо проще. Дополнительные сведения см. в следующей записи блога: Пользовательские функции, которые были просты в Power BI Desktop.
Примечание.
Иногда может появиться уведомление о необходимости обновления потока данных с помощью пользовательской функции. Это сообщение можно игнорировать и повторно открыть редактор потока данных. Это обычно решает вашу проблему, если функция не ссылается на запрос с поддержкой загрузки.
Размещение запросов в папки
Использование папок для запросов помогает группировать связанные запросы вместе. При разработке потока данных проводите немного больше времени, чтобы упорядочить запросы в папках, которые имеет смысл. Благодаря этому подходу запросы можно легко найти в будущем и поддерживать код гораздо проще.
Использование вычисляемых таблиц
Вычислимые таблицы не только делают поток данных более понятным, они также обеспечивают более высокую производительность. При использовании вычисляемой таблицы другие таблицы, на которые она ссылается, получают данные из таблицы " уже обработанной и сохраненной". Преобразование гораздо проще и быстрее.
Преимущества расширенного вычислительного модуля
Для потоков данных, разработанных на портале администрирования Power BI, убедитесь, что вы используете расширенный вычислительный модуль, выполняя соединения и преобразования фильтров, сначала в вычисляемой таблице, прежде чем выполнять другие типы преобразований.
Разорвать множество шагов на несколько запросов
Трудно отслеживать большое количество шагов в одной таблице. Вместо этого следует разбить большое количество шагов на несколько таблиц. Вы можете включить загрузку для других запросов и отключить их, если они промежуточные запросы, и загрузить только окончательную таблицу через поток данных. При наличии нескольких запросов с меньшими шагами в каждом из них проще использовать схему зависимостей и отслеживать каждый запрос для дальнейшего изучения, а не копаться в сотни шагов в одном запросе.
Добавление свойств для запросов и шагов
Документация — это ключ к простому обслуживанию кода. В Power Query можно добавить свойства в таблицы, а также выполнить действия. Добавляемый текст в свойствах отображается в виде подсказки при наведении указателя мыши на этот запрос или шаг. Эта документация помогает поддерживать модель в будущем. С помощью взгляда на таблицу или шаг вы можете понять, что происходит там, а не переосмыслить и вспомнить, что вы сделали на этом шаге.
Убедитесь, что емкость находится в одном регионе
Потоки данных в настоящее время не поддерживают несколько стран или регионов. Емкость Premium должна находиться в том же регионе, что и клиент Power BI.
Разделение локальных источников из облачных источников
Рекомендуется создать отдельный поток данных для каждого типа источника, например локальный, облачный, SQL Server, Spark и Dynamics 365. Разделение потоков данных по типу источника упрощает быстрое устранение неполадок и позволяет избежать внутренних ограничений при обновлении потоков данных.
Разделение потоков данных на основе запланированного обновления, необходимого для таблиц
Если у вас есть таблица транзакций продаж, которая обновляется в исходной системе каждый час, и у вас есть таблица сопоставления продуктов, которая обновляется каждую неделю, разбийте эти две таблицы на два потока данных с различными расписаниями обновления данных.
Избегайте планирования обновления связанных таблиц в той же рабочей области
Если вы регулярно блокируете потоки данных, содержащие связанные таблицы, это может быть вызвано соответствующим зависимым потоком данных в той же рабочей области, которая заблокирована во время обновления потока данных. Такая блокировка обеспечивает точность транзакций и гарантирует успешное обновление обоих потоков данных, но может блокировать редактирование.
Если вы настроили отдельное расписание для связанного потока данных, потоки данных можно обновить без необходимости и заблокировать редактирование потока данных. Существует две рекомендации, чтобы избежать этой проблемы:
- Не устанавливайте расписание обновления для связанного потока данных в той же рабочей области, что и исходный поток данных.
- Если вы хотите настроить расписание обновления отдельно и избежать поведения блокировки, переместите поток данных в отдельную рабочую область.
Кері байланыс
Жақында қолжетімді болады: 2024 жыл бойы біз GitHub Issues жүйесін мазмұнға арналған кері байланыс механизмі ретінде біртіндеп қолданыстан шығарамыз және оны жаңа кері байланыс жүйесімен ауыстырамыз. Қосымша ақпаратты мұнда қараңыз: https://aka.ms/ContentUserFeedback.
Жіберу және пікірді көру