Ескерім
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Жүйеге кіруді немесе каталогтарды өзгертуді байқап көруге болады.
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Каталогтарды өзгертуді байқап көруге болады.
Качество данных — это измерение целостности данных в организации и оценивается с помощью оценок качества данных. Оценки, созданные на основе оценки данных по правилам, определенным в Единый каталог Microsoft Purview.
Правила качества данных — это важные рекомендации, устанавливаемые организациями для обеспечения точности, согласованности и полноты данных. Эти правила помогают поддерживать целостность и надежность данных.
Ниже приведены некоторые ключевые аспекты правил качества данных.
Точность . Данные должны точно представлять реальные сущности. Контекст имеет значение! Например, если вы храните адреса клиентов, убедитесь, что они соответствуют фактическим расположениям.
Полнота . Цель этого правила — определить пустые, пустые или отсутствующие данные. Это правило проверяет наличие всех значений (хотя и не обязательно правильных).
Соответствие . Это правило гарантирует, что данные соответствуют стандартам форматирования данных, таким как представление дат, адресов и допустимых значений.
Согласованность . Это правило проверяет, соответствуют ли различные значения одной записи заданному правилу и нет ли противоречий. Согласованность данных обеспечивает равномерное представление одной и той же информации в разных записях. Например, если у вас есть каталог продуктов, согласованные названия и описания продуктов имеют решающее значение.
Своевременность . Это правило направлено на то, чтобы обеспечить доступ к данным в течение как можно более короткого времени. Это гарантирует актуальность данных.
Уникальность . Это правило проверяет, не дублируются ли значения, например, если на клиента должна быть только одна запись, то для одного клиента не существует нескольких записей. Каждый клиент, продукт или транзакция должен иметь уникальный идентификатор.
Жизненный цикл качества данных
Создание правил качества данных — это шестой шаг в жизненном цикле качества данных. Предыдущие шаги:
- Назначьте пользователям разрешения на управление качеством данных в Единый каталог для использования всех функций качества данных.
- Зарегистрируйте и проверьте источник данных в Схема данных Microsoft Purview.
- Добавление ресурса данных в продукт данных
- Настройте подключение к источнику данных, чтобы подготовить источник к оценке качества данных.
- Настройте и запустите профилирование данных для ресурса в источнике данных.
Необходимые роли
- Для создания правил качества данных и управления ими пользователи должны быть в роли администратора качества данных.
- Чтобы просмотреть существующие правила качества, пользователи должны быть в роли читателя качества данных.
Просмотр существующих правил качества данных
В Единый каталог Microsoft Purview выберите меню Управление работоспособностью и подменю Качество данных.
В подменю качества данных выберите домен управления.
Выберите продукт данных.
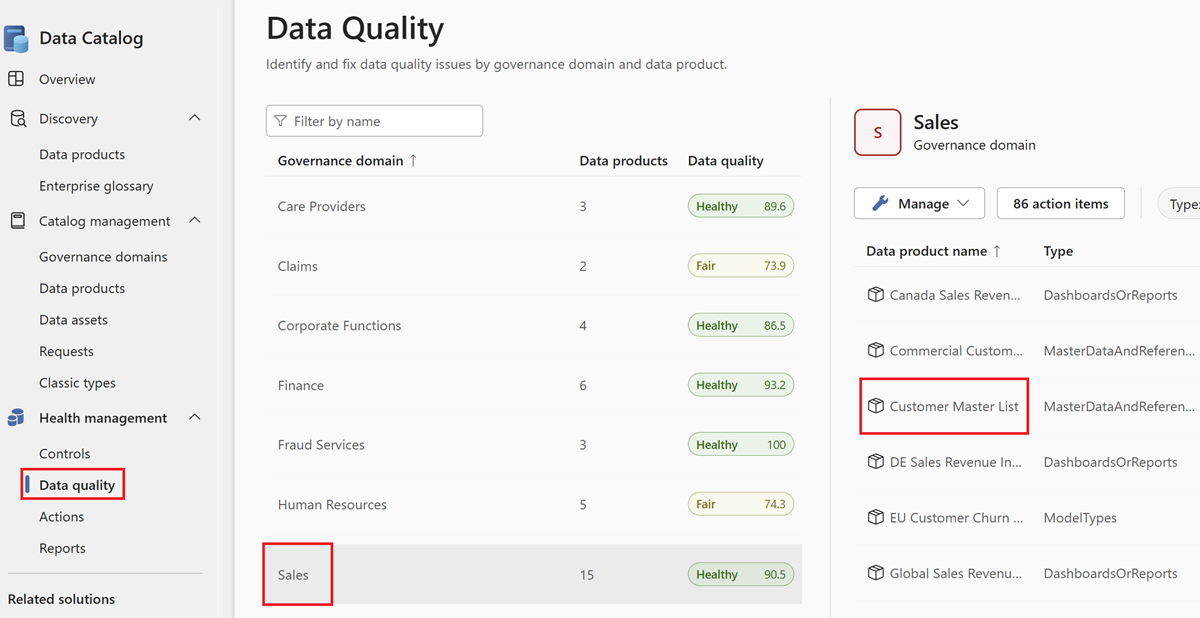
Выберите ресурс данных из списка ресурсов выбранного продукта данных.
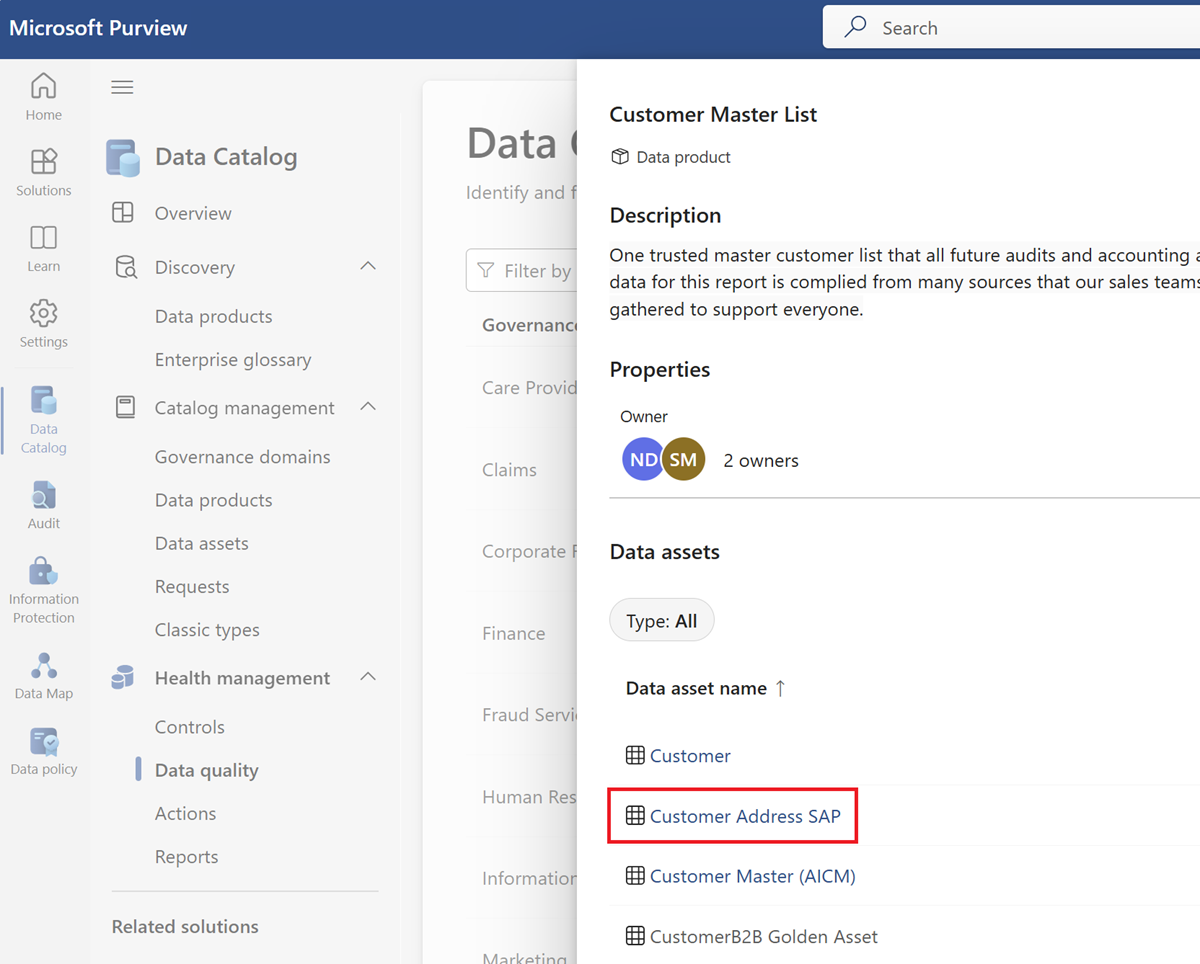
Перейдите на вкладку меню Правила , чтобы просмотреть существующие правила, применяемые к ресурсу.
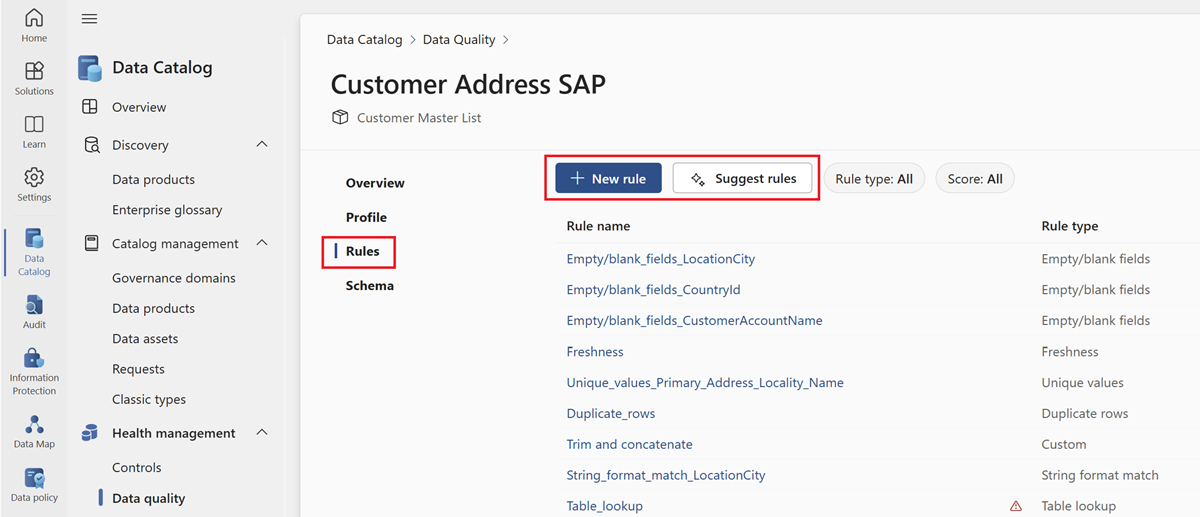
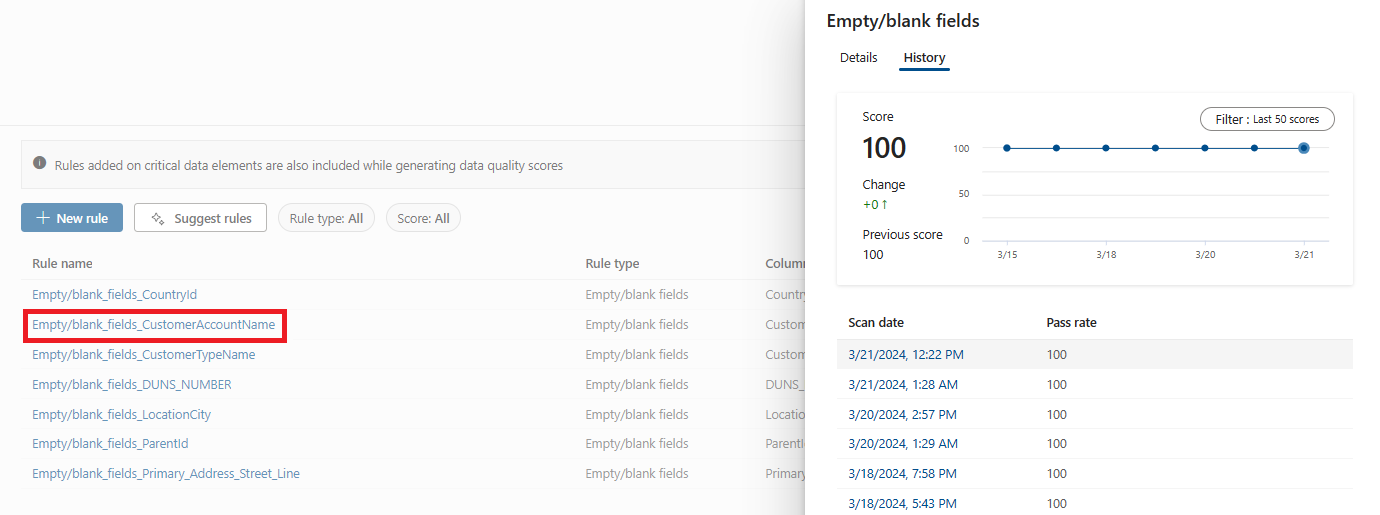
Выберите правило, чтобы просмотреть журнал производительности примененного правила к выбранному ресурсу данных.




Доступные правила качества данных
Качество данных Microsoft Purview позволяет настроить приведенные ниже правила, это готовые правила, которые предлагают способ измерения качества данных с низким уровнем кода и без кода.
| Правило | Определение |
|---|---|
| Компонент ранжирования по актуальности | Подтверждает актуальность всех значений. |
| Уникальные значения | Подтверждает, что значения в столбце уникальны. |
| Соответствие строкового формата | Подтверждает, что значения в столбце соответствуют определенному формату или другим критериям. |
| Соответствие типов данных | Подтверждает, что значения в столбце соответствуют требованиям к типу данных. |
| Повторяющиеся строки | Проверяет наличие повторяющихся строк с одинаковыми значениями в двух или более столбцах. |
| Пустые и пустые поля | Поиск пустых и пустых полей в столбце, где должны быть значения. |
| Подстановка таблицы | Подтверждает, что значение в одной таблице можно найти в определенном столбце другой таблицы. |
| Custom | Создайте пользовательское правило с помощью построителя визуальных выражений. |
Компонент ранжирования по актуальности
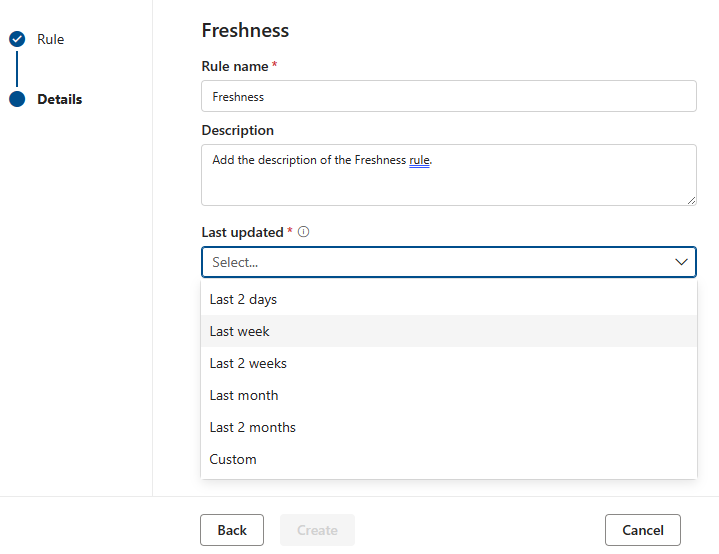
Цель правила актуальности — определить, был ли ресурс обновлен в течение ожидаемого времени. В настоящее время Microsoft Purview поддерживает проверку актуальности путем просмотра дат последнего изменения.
Примечание.
Оценка для правила актуальности — 100 (прошло) или 0 (сбой). Правило свежести не поддерживается для Snowflake, Azure Databricks UC, Google BigQuery, Synapes и Azure SQL.
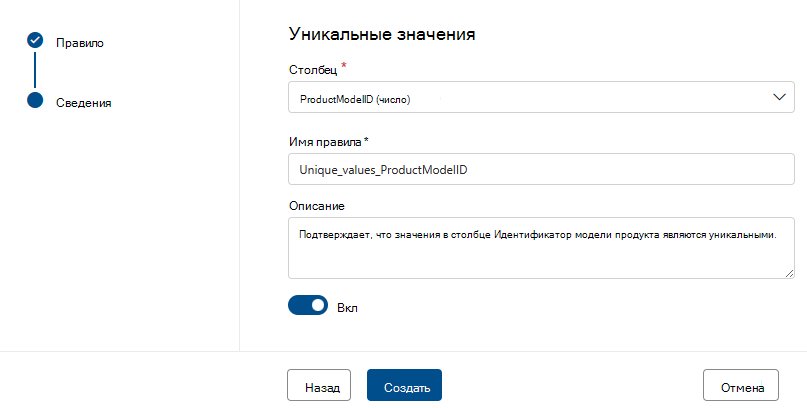
Уникальные значения
В правиле Уникальные значения указано, что все значения в указанном столбце должны быть уникальными. Все уникальные значения pass и значения, которые не обрабатываются как сбои. Если правило пустых и пустых полей не определено в столбце, значения NULL и пустые будут игнорироваться для целей этого правила.
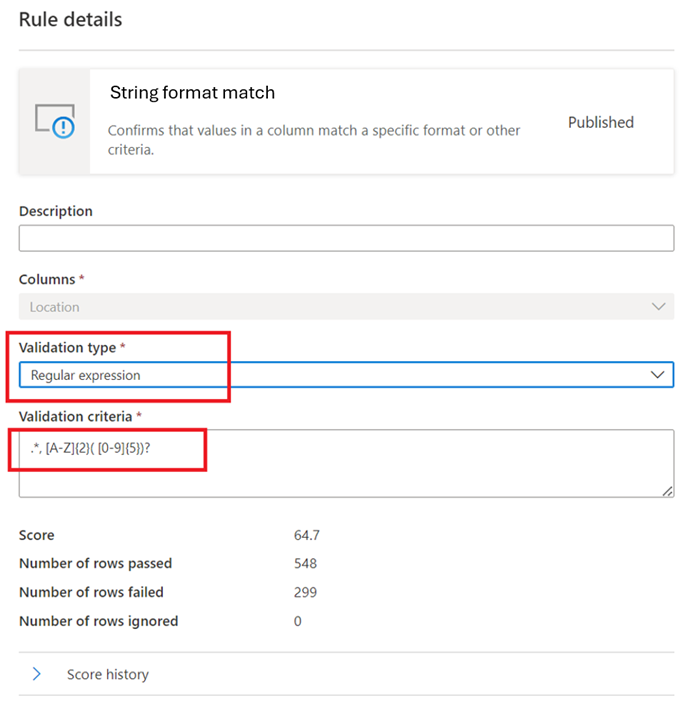
Соответствие строкового формата
Правило форматирования соответствия проверяет, являются ли все значения в столбце допустимыми. Если правило пустых и пустых полей не определено в столбце, значения NULL и пустые будут игнорироваться для целей этого правила.
Это правило может проверить каждое значение в столбце с помощью трех разных подходов:
Перечисление — список значений, разделенный запятыми. Если вычисляемое значение не может быть сопоставлено с одним из перечисленных значений, проверка завершается ошибкой. Запятые и обратные косые черты можно экранировать с помощью обратной косой черты:
\. Таким образомa \, b, c, содержит два значения: первое — ,a , bа второе —c.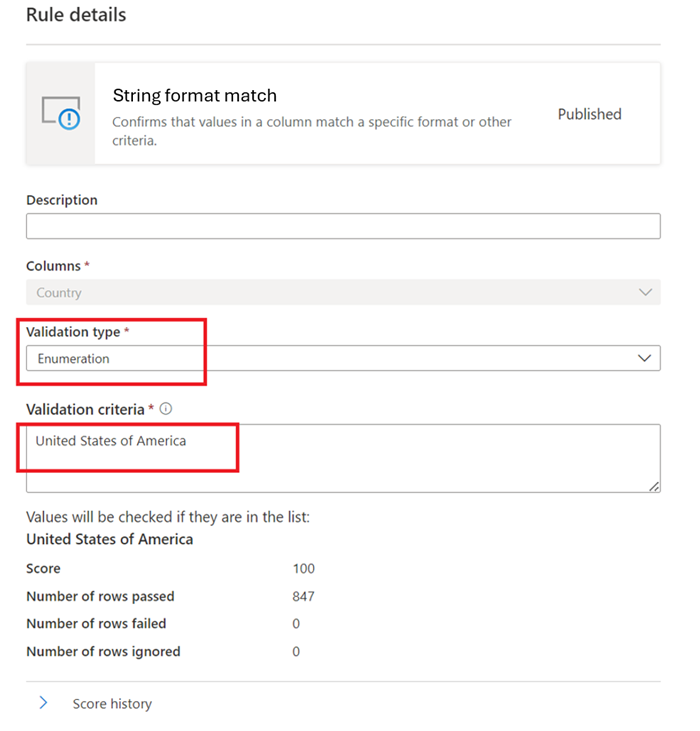
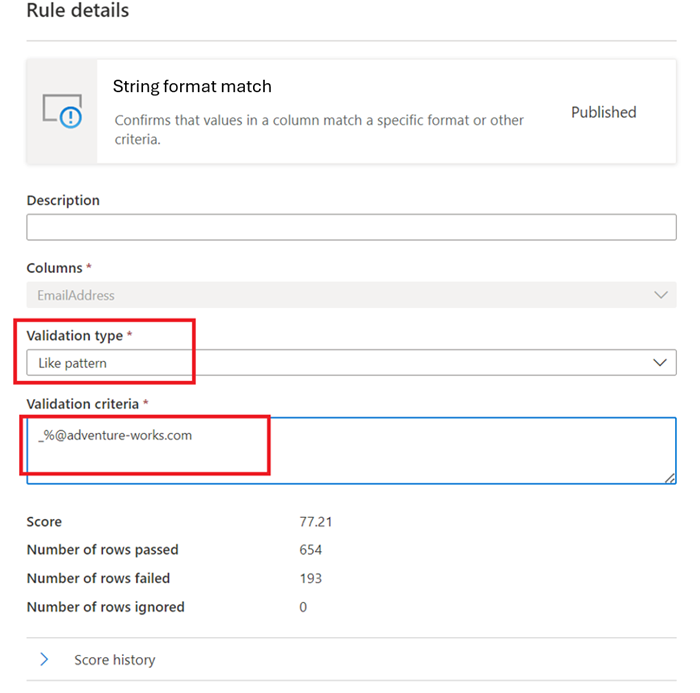
Шаблон "Нравится" -
like(<string> : string, <pattern match> : string) => boolean
Шаблон — это строка, которая сопоставляется буквально. Исключениями являются следующие специальные символы: _ соответствует любому одному символу во входных данных (аналогично . вposixрегулярных выражениях) % соответствует нулю или нескольким символам во входных данных (аналогично .* вposixрегулярных выражениях). Escape-символ — "". Если escape-символ предшествует специальному символу или другому escape-символу, следующий символ сопоставляется буквально. Невозможно экранировать любой другой символ.like('icecream', 'ice%') -> true
Регулярное выражение —
regexMatch(<string> : string, <regex to match> : string) => boolean
Проверяет, соответствует ли строка заданному шаблону регулярных выражений. Используйте<regex>(обратная кавычка) для сопоставления строки без экранирования.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
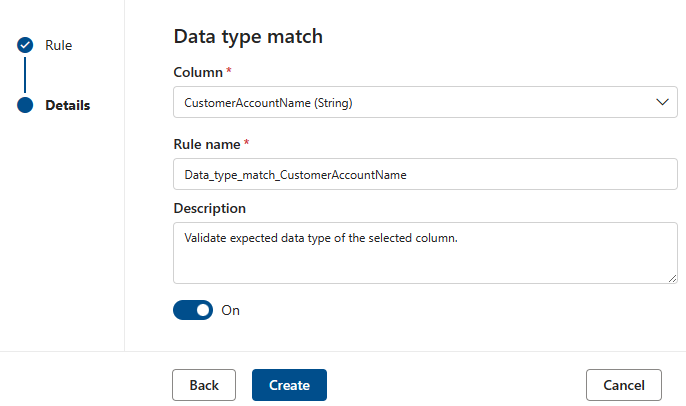
Соответствие типов данных
Правило сопоставления типов данных указывает тип данных, который должен содержать связанный столбец. Так как обработчик правил должен работать во множестве различных источников данных, он не может использовать собственные типы, такие как BIGINT или VARCHAR. Вместо этого он имеет собственную систему типов, в которую он преобразует собственные типы. Это правило сообщает механизму проверки качества, в какой из его встроенных типов должен быть преобразован собственный тип. Система типов данных берется из системы типов Поток данных Azure, используемой в Фабрика данных Azure.
Во время проверки качества все собственные типы будут проверяться с типом соответствия типа данных, и если невозможно преобразовать собственный тип в тип соответствия типа данных, эта строка будет рассматриваться как ошибка.
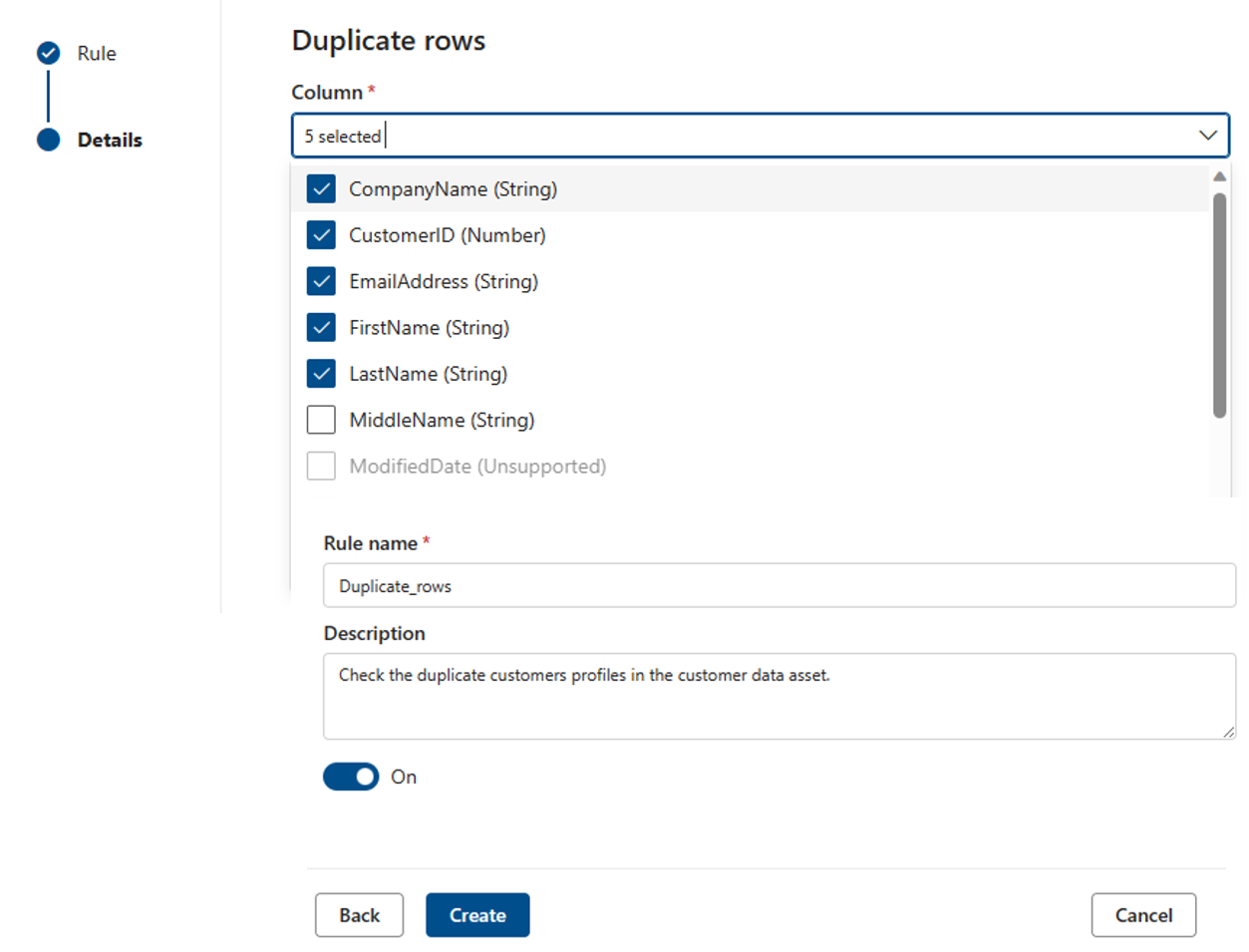
Повторяющиеся строки
Правило повторяющихся строк проверяет, является ли сочетание значений в столбце уникальным для каждой строки таблицы.
В приведенном ниже примере ожидается, что объединение _CompanyName, CustomerID, EmailAddress, FirstName и LastName создаст уникальное значение для всех строк в таблице.
Каждый ресурс может иметь ноль или один экземпляр этого правила.
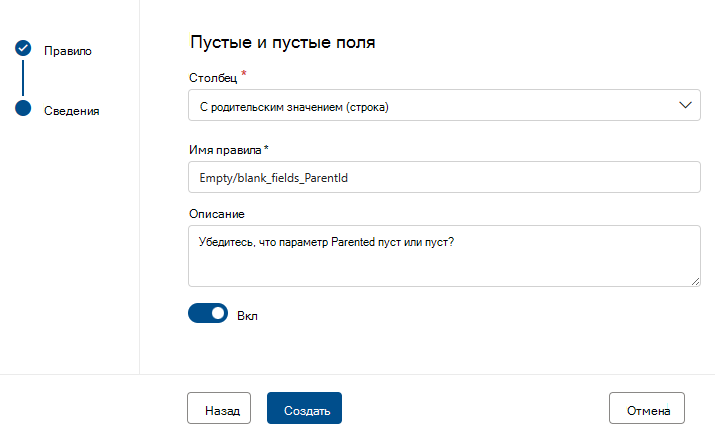
Пустые и пустые поля
Правило пустых и пустых полей утверждает, что указанные столбцы не должны содержать значения NULL, а в конкретном случае строк — пустые или пробелы. Во время проверки качества любое значение в этом столбце, не равное NULL, будет рассматриваться как правильное. Это правило будет влиять на другие правила, такие как уникальные значения или правила сопоставления форматов . Если это правило не определено для столбца, эти правила при выполнении в этом столбце будут автоматически игнорировать любые значения NULL. Если это правило определено для столбца, эти правила будут проверять значения NULL/пустые в этом столбце и рассматривать их для оценки.
Подстановка таблицы
Правило подстановки в таблице проверяет каждое значение в столбце, в который определено правило, и сравнивает его со ссылочной таблицей. Например, первичная таблица содержит столбец с именем "расположение", который содержит города, штаты и почтовые индексы в формате "city, state zip". Существует справочная таблица, называемая citystate, которая содержит все юридические сочетания городов, штатов и почтовых индексов, поддерживаемые в США. Цель состоит в том, чтобы сравнить все расположения в текущем столбце с этим списком ссылок, чтобы убедиться, что используются только юридические сочетания.
Для этого сначала введите имя citystatezip в диалоговом окне поиска ресурсов. Затем мы выбираем нужный ресурс, а затем столбец, с которым нужно сравнить.
Примечание.
Эталонная таблица или ресурс данных должны принадлежать к одному и тому же домену управления. Сравнение ресурса данных в разных доменах управления не допускается.
Пользовательские правила
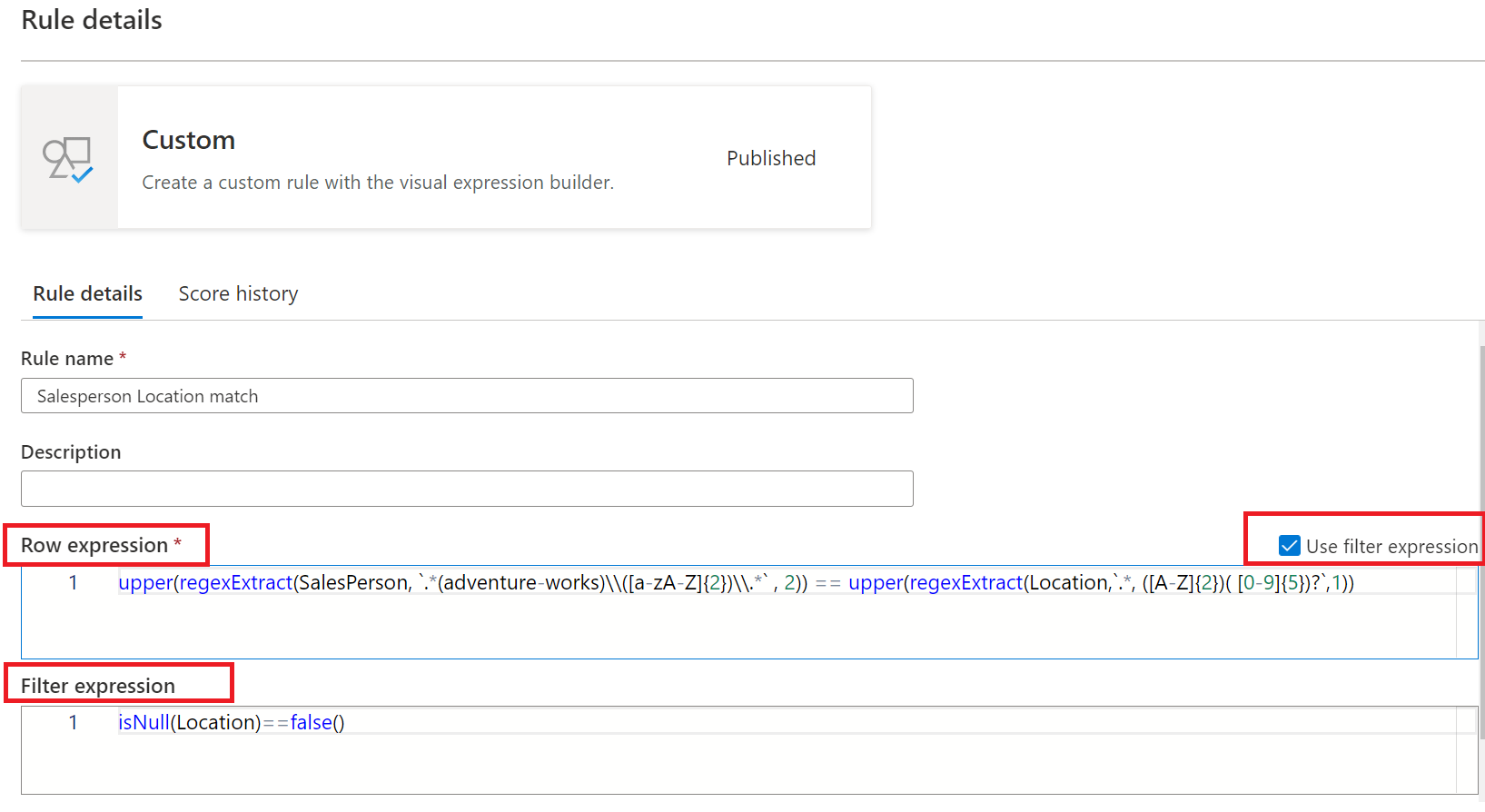
Настраиваемое правило позволяет указывать правила, которые пытаются проверить строки на основе одного или нескольких значений в этой строке. Пользовательское правило состоит из двух частей:
- Первая часть — это необязательное выражение фильтра, которое активируется путем выбора проверка поля "Использовать выражение фильтра". Это выражение возвращает логическое значение. Выражение фильтра будет применено к строке, и если оно возвращает значение true, то эта строка будет считаться для правила. Если выражение фильтра возвращает значение false для этой строки, это означает, что строка будет игнорироваться для целей этого правила. По умолчанию выражение фильтра передает все строки. Поэтому, если выражение фильтра не указано и оно не требуется, будут рассматриваться все строки.
- Вторая часть — это выражение строки. Это логическое выражение применяется к каждой строке, которая утверждается выражением фильтра. Если это выражение возвращает значение true, то строка проходит, если значение false, то оно помечается как сбой.
Примеры пользовательских правил
| Сценарий | Выражение строки |
|---|---|
| Проверьте, соответствует ли state_id Калифорнии, а aba_Routing_Number соответствует определенному шаблону регулярных выражений, а дата рождения попадает в определенный диапазон | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Проверьте, равен ли Идентификатор поставщика 124 | {VendorID}=='124' |
| Проверьте, равен ли fare_amount или больше 100 | {fare_amount} >= "100" |
| Проверьте, больше ли fare_amount 100, а tolls_amount не равно 100 | {fare_amount} >= "100" || {tolls_amount} != "400" |
| Проверьте , меньше ли 5 | Rating < 5 |
| Проверьте, равно ли число цифр в году 4 | length(toString(year)) == 4 |
| Сравнение двух столбцов bbToLoanRatio и bankBalance с проверка, если их значения равны | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| Проверьте, больше ли обрезанного и сцепленного количества символов в firstName, LastName, LoanID, uuid больше 20 | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| Проверьте, соответствует ли aba_Routing_Number определенному шаблону регулярных выражений, а начальная дата транзакции больше 2022-11-12, а disallow-Listed — false, а среднее значение bankBalance больше 50 000, а state_id равно "Massachuse", "Tennessee", "North Dakota" или "Albama" | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| Проверьте, соответствует ли aba_Routing_Number определенному шаблону регулярных выражений, а dateOfBirth находится в период с 1968-12-13 по 2020-12-13 | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Проверьте, равно ли количество уникальных значений в aba_Routing_Number 1 000 000, а число уникальных значений в EMAIL_ADDR равно 1 000 000 | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
Выражение фильтра и выражение строки определяются с помощью языка выражений Фабрика данных Azure, представленного здесь с языком, определенным здесь. Обратите внимание, однако, что доступны не все функции, определенные для универсального языка выражений ADF. Полный список доступных функций содержится в списке Функции, доступном в диалоговом окне выражения. Следующие функции, определенные здесь , не поддерживаются: isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, кэшированный поиск и функции Window.
Примечание.
<regex> (backquote) можно использовать в регулярных выражениях, включенных в настраиваемые правила, для сопоставления строки без экранирования специальных символов. Язык регулярных выражений основан на Java и работает так, как показано здесь.
На этой странице указаны символы, которые необходимо экранировать.
Автоматически созданные правила с помощью ИИ
Автоматизированное создание правил с помощью ИИ для измерения качества данных включает использование методов искусственного интеллекта (ИИ) для автоматического создания правил для оценки и улучшения качества данных. Автоматически созданные правила зависят от содержимого. Большинство общих правил будут создаваться автоматически, чтобы пользователям не нужно было прикладывать столько усилий для создания пользовательских правил.
Чтобы просмотреть и применить автоматически созданные правила, выполните следующие действия:
- Выберите Предложить правила на странице правил.
- Просмотрите список предлагаемых правил.

- Выберите правила из списка предлагаемых правил для применения к ресурсу данных.

Дальнейшие действия
- Настройте и запустите проверку качества данных в продукте данных, чтобы оценить качество всех поддерживаемых ресурсов в продукте данных.
- Просмотрите результаты сканирования , чтобы оценить текущее качество данных продукта данных.