Общие сведения о развертывании приложений в Кластерах больших данных SQL Server
Область применения: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Внимание
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Развертывание приложения позволяет развертывать приложения в Кластерах больших данных SQL Server, предоставляя интерфейсы для создания и выполнения приложений, а также управления ими. Приложения, развертываемые в кластере больших данных, могут использовать его вычислительные возможности и обращаться к размещенным в нем данным. Это повышает масштабируемость и производительность приложений, а также позволяет управлять ими в месте размещения данных. Поддерживаемые среды выполнения приложений в Кластерах больших данных SQL Server: R, Python, dtexec и MLeap.
В следующих разделах описываются архитектура и функциональные возможности развертывания приложения.
Архитектура развертывания приложения
Развертывание приложения состоит из контроллера и обработчиков среды выполнения приложений. При создании приложения предоставляется файл спецификации (spec.yaml). Этот файл spec.yaml содержит все сведения, которые нужны контроллеру для успешного развертывания приложения. Ниже приведен пример содержимого файла spec.yaml.
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
Контроллер проверяет элемент runtime в файле spec.yaml и вызывает соответствующий обработчик среды выполнения. Обработчик среды выполнения создает приложение. Во-первых, создается объект ReplicaSet Kubernetes, содержащий один или несколько объектов pod, каждый из которых содержит развертываемое приложение. Количество объектов pod определяется параметром replicas, указанным в файле spec.yaml для приложения. Каждый объект pod может иметь один или несколько пулов. Количество пулов определяется параметром poolsize, указанным в файле spec.yaml.
Эти параметры определяют, какой объем запросов может обрабатываться в развертывании параллельно. Максимальное количество запросов в определенный момент времени равно значению replicas, умноженному на poolsize. Если имеется 5 реплик с двумя пулами в каждой, параллельно могут обрабатываться 10 запросов. Графическое представление параметров replicas и poolsize см. на рисунке ниже.
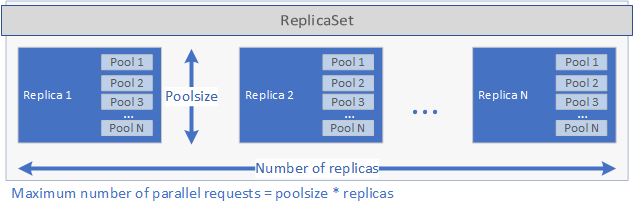
После создания объекта ReplicaSet и запуска пулов создается задание cron, если в файле spec.yaml был задан параметр schedule. Наконец, создается служба Kubernetes, которую можно использовать для управления приложением и его запуска (см. ниже).
При выполнении приложения служба Kubernetes передает запросы в реплику и возвращает результаты.
Рекомендации по безопасности для развертываний приложений в OpenShift
SQL Server 2019 с накопительным пакетом обновления 5 (CU5) обеспечивает для кластеров больших данных поддержку развертывания на базе Red Hat OpenShift и обновленную модель безопасности, за счет чего привилегированные контейнеры больше не требуются. Для всех новых развертываний, использующих SQL Server 2019 с накопительным пакетом обновления 5 (CU5), контейнеры не только являются непривилегированными, но и по умолчанию работают от имени непривилегированного пользователя.
На момент выпуска CU5 установка приложений, развертываемых с помощью интерфейсов развертывания приложений, по-прежнему производилась от имени привилегированного пользователя. Это обусловлено тем, что в ходе установки необходимо также установить дополнительные пакеты, используемые приложением. Другой пользовательский код, развертываемый в составе приложения, выполняется от имени пользователя с низким уровнем привилегий.
Кроме того, имеется дополнительная возможность CAP_AUDIT_WRITE, которая необходима для планирования работы приложений SQL Server Integration Services (SSIS) с помощью заданий cron. Если в YAML-файле спецификации приложения указано расписание, то приложение будет запускаться с помощью задания cron, для чего необходима эта дополнительная возможность. Помимо этого, приложение также можно активировать по запросу с помощью команды azdata app run через вызов веб-службы, для которого возможность CAP_AUDIT_WRITE не требуется. Обратите внимание, что возможность CAP_AUDIT_WRITE больше не требуется для cronjob, начиная с выпуска SQL Server 2019 с накопительным пакетом обновления 8 (CU8).
Примечание.
Настраиваемое ограничение контекста безопасности (SCC) из статьи по развертыванию в OpenShift не включает эту возможность, так как она не требуется для развертывания кластера больших данных по умолчанию. Чтобы включить эту возможность, сначала измените пользовательский YAML-файл SCC и включите в него CAP_AUDIT_WRITE.
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
Развертывание приложения в кластере больших данных
Развертывание приложения имеет два основных интерфейса:
- Интерфейс командной строки Azure Data CLI (
azdata) - расширение для Visual Studio Code и Azure Data Studio.
Приложение может также выполняться с помощью веб-службы RESTful. Дополнительные сведения см. в статье Использование приложения, развернутого в Кластерах больших данных SQL Server, с помощью веб-службы RESTful.
Сценарии развертывания приложения
Развертывание приложения предоставляет интерфейсы для создания, контроля и запуска приложений в кластере больших данных SQL Server.
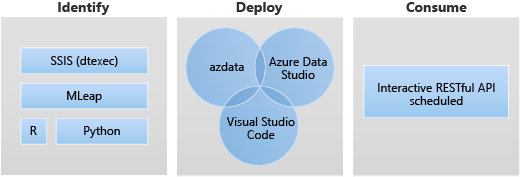
Целевые сценарии развертывания приложения:
- Развертывание веб-служб Python или R в кластере больших данных для различных вариантов использования, таких как вывод машинного обучения, обслуживание API и т. д.
- Создание конечной точки вывода машинного обучения с использованием подсистемы MLeap.
- Планирование работы и запуск пакетов из файлов DTSX с помощью служебной программы dtexec для целей преобразования и перемещения данных.
Использование среды выполнения Python для развертывания приложения
Развертывание приложения позволяет применять среду выполнения приложений Python в кластере больших данных для различных вариантов использования, таких как вывод машинного обучения, обслуживание API и многие другие.
При развертывании приложения в среде выполнения Python используется Python 3.8 в кластерах больших данных SQL Server с накопительным пакетом обновления 10 (CU10) или более поздней версии.
В файле spec.yaml указываются сведения, необходимые контроллеру для развертывания приложения. Ниже перечислены поля, которые можно указать.
name: имя приложения.version: версия приложения, напримерv1.runtime: среда выполнения развертывания приложения. Ее необходимо указать какPython.src: путь к приложению Python.entry point: функция точки входа в скрипте src, выполняемом для этого приложения Python.
Помимо значений выше, необходимо указать входные и выходные данные приложения Python. Будет создан файл spec.yaml следующего вида:
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
Вы можете создать базовую структуру папок и файлов, необходимую для развертывания приложения Python, запускаемого в Кластерах больших данных:
azdata app init --template python --name hello-py --version v1
Дальнейшие действия см. в статье Развертывание приложения в Кластерах больших данных SQL Server.
Ограничения среды выполнения Python для развертывания приложения
Среда выполнения Python для развертывания приложений не поддерживает сценарий планирования. После развертывания приложения Python и его запуска в кластере больших данных конечная точка RESTful настраивается для ожидания входящих запросов.
Использование среды выполнения R для развертывания приложения
Развертывание приложения позволяет применять среду выполнения Python в кластере больших данных для различных вариантов использования приложения R, таких как вывод машинного обучения, обслуживание API и многие другие.
При развертывании приложения в среде выполнения R используется Microsoft R Open (MRO) версии 3.5.2 в кластерах больших данных SQL Server с накопительным пакетом обновления 10 (CU10) или более поздней версии.
Использование
В файле spec.yaml указываются сведения, необходимые контроллеру для развертывания приложения. Ниже перечислены поля, которые можно указать.
name: имя приложения.version: версия приложения, напримерv1.runtime: среда выполнения развертывания приложения. Ее необходимо указать какR.src: путь к приложению R.entry point: точка входа для выполнения этого приложения R.
Помимо значений выше, необходимо указать входные и выходные данные приложения R. Будет создан файл spec.yaml следующего вида:
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
Вы можете создать базовую структуру папок и файлов, необходимую для развертывания нового приложения R, с помощью следующей команды:
azdata app init --template r --name hello-r --version v1
Дальнейшие действия см. в статье Развертывание приложения в Кластерах больших данных SQL Server.
Ограничения среды выполнения R
Эти ограничения соответствуют сети приложений Microsoft R, которая была прекращена 1 июля 2023 года. Дополнительные сведения и обходные пути см. в статье о выходе из сети приложений Microsoft R.
Использование среды выполнения dtexec для развертывания приложения
При развертывании приложения используется служебная программа dtexec из SSIS для Linux (mssql-server-is), интегрированная в среду выполнения кластера больших данных. Служебная программа dtexe используется при развертывании приложения для загрузки пакетов из файлов DTSX. Она поддерживает запуск пакетов SSIS по расписанию в стиле cron или по требованию через запросы веб-службы.
Эта функция использует /opt/ssis/bin/dtexec /FILE из службы интеграции SQL Server 2019 в Linux. Она поддерживает формат DTSX для службы интеграции SQL Server 2019 в Linux (mssql-server-is 15.0.2). См. дополнительные сведения о служебной программе dtexec.
В файле spec.yaml указываются сведения, необходимые контроллеру для развертывания приложения. Ниже перечислены поля, которые можно указать.
name: имя (name) приложения.version: версия приложения, напримерv1.runtime: среда выполнения развертывания приложения. Для запуска служебной программы dtexec необходимо указать ее какSSIS.entrypoint: точка входа. Обычно это DTSX-файл.options: дополнительные параметры для/opt/ssis/bin/dtexec /FILE. Например, для соединения с базой данных с помощью строки подключения используется следующий шаблон:/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=xx\""Сведения о синтаксисе см. в описании служебной программы dtexec.
schedule: указание частоты выполнения задания. Например, если с помощью выражения cron указать значение "*/1 * * * *", то задание будет выполняться раз в минуту.
Вы можете создать базовую структуру папок и файлов, необходимую для развертывания нового приложения SSIS, с помощью следующей команды:
azdata app init --name hello-is –version v1 --template ssis
Будет создан файл spec.yaml следующего вида:
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
В примере также создается образец пакета hello.dtsx.
Все файлы приложения находятся в том же каталоге, что и файл spec.yaml. Файл spec.yaml должен находиться на корневом уровне папки с исходным кодом приложения, включающей файл DTSX.
Дальнейшие действия см. в статье Развертывание приложения в Кластерах больших данных SQL Server.
Ограничения среды выполнения служебной программы dtexec
Все ограничения и известные проблемы, связанные со службами SQL Server Integration Services (SSIS) в Linux, применимы к Кластерам больших данных SQL Server. Дополнительные сведения см. в статье Ограничения и известные проблемы для служб SSIS в Linux.
Использование среды выполнения MLeap для развертывания приложений
Среда выполнения MLeap для развертывания приложений поддерживает MLeap Serving v0.13.0.
В файле spec.yaml указываются сведения, необходимые контроллеру для развертывания приложения. Ниже перечислены поля, которые можно указать.
name: имя приложения.version: версия приложения, напримерv1.runtime: среда выполнения развертывания приложения. Ее необходимо указать какMleap.
Помимо значений выше, необходимо указать bundleFileName для вашего приложения MLeap. Будет создан файл spec.yaml следующего вида:
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
Вы можете создать базовую структуру папок и файлов, необходимую для развертывания нового приложения MLeap, с помощью следующей команды:
azdata app init --template mleap --name hello-mleap --version v1
Дальнейшие действия см. в статье Развертывание приложения в Кластерах больших данных SQL Server.
Ограничения среды выполнения MLeap
Ограничения соответствуют концепции проекта MLeap с открытым кодом от Сombust на сайте GitHub.
Следующие шаги
Дополнительные сведения о создании и выполнении приложений в Кластерах больших данных SQL Server см. в следующих статьях:
- Развертывание приложений с помощью azdata
- Использования расширения для развертывания приложения
- Использование приложений в Кластерах больших данных
Дополнительные сведения о Кластеры больших данных SQL Server см. в следующем обзоре: