Руководство. Прием данных в пул данных SQL Server с заданиями Spark
Область применения: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Внимание
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
В этом руководстве показано, как использовать задания Spark для загрузки данных в пул данных Кластеры больших данных SQL Server 2019.
В этом руководстве описано следующее:
- Создание внешней таблицы в пуле данных.
- Создание задания Spark для загрузки данных из HDFS.
- Запрос результатов во внешней таблице.
Совет
При необходимости вы можете скачать и выполнить скрипт, содержащий команды из этого руководства. См. инструкции в разделе Примеры пулов данных на сайте GitHub.
Необходимые компоненты
- Средства работы с большими данными
- kubectl
- Azure Data Studio
- Расширение SQL Server 2019
- Загрузка примера данных в кластер больших данных
Создание внешней таблицы в пуле данных
Выполните следующие действия, чтобы создать внешнюю таблицу с именем web_clickstreams_spark_results в пуле данных. В дальнейшем эта таблица может использоваться для приема данных в кластер больших данных.
В Azure Data Studio установите подключение к главному экземпляру SQL Server в кластере больших данных. Дополнительные сведения см. в разделе Подключение к главному экземпляру SQL Server.
Дважды щелкните подключение в окне Серверы, чтобы открыть панель мониторинга сервера для главного экземпляра SQL Server. Выберите Создать запрос.
Создайте разрешения для соединителя MSSQL-Spark.
USE Sales CREATE LOGIN sample_user WITH PASSWORD ='password123!#' CREATE USER sample_user FROM LOGIN sample_user -- To create external tables in data pools GRANT ALTER ANY EXTERNAL DATA SOURCE TO sample_user; -- To create external tables GRANT CREATE TABLE TO sample_user; GRANT ALTER ANY SCHEMA TO sample_user; -- To view database state for Sales GRANT VIEW DATABASE STATE ON DATABASE::Sales TO sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user ALTER ROLE [db_datawriter] ADD MEMBER sample_userСоздайте внешний источник данных для пула данных, если это не было сделано ранее.
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlDataPool') CREATE EXTERNAL DATA SOURCE SqlDataPool WITH (LOCATION = 'sqldatapool://controller-svc/default');Создайте внешнюю таблицу с именем web_clickstreams_spark_results в пуле данных.
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_tables WHERE name = 'web_clickstreams_spark_results') CREATE EXTERNAL TABLE [web_clickstreams_spark_results] ("wcs_click_date_sk" BIGINT , "wcs_click_time_sk" BIGINT , "wcs_sales_sk" BIGINT , "wcs_item_sk" BIGINT , "wcs_web_page_sk" BIGINT , "wcs_user_sk" BIGINT) WITH ( DATA_SOURCE = SqlDataPool, DISTRIBUTION = ROUND_ROBIN );Создайте имя входа для пулов данных и предоставьте пользователю разрешения.
EXECUTE( ' Use Sales; CREATE LOGIN sample_user WITH PASSWORD = ''password123!#'' ;') AT DATA_SOURCE SqlDataPool; EXECUTE('Use Sales; CREATE USER sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user; ALTER ROLE [db_datawriter] ADD MEMBER sample_user;') AT DATA_SOURCE SqlDataPool;
Создание внешней таблицы пула данных является блокирующей операцией. Управление возвращается лишь после создания указанной таблицы на всех узлах пула данных серверной части. Если во время операции создания произойдет ошибка, сообщение о ней возвращается вызывающей стороне.
Запуск задания потоковой передачи Spark
Следующим шагом является создание задания потоковой передачи Spark, которое загружает сведения о посещениях из пула носителей (HDFS) во внешнюю таблицу, созданную в пуле данных. Эти данные были добавлены в /clickstream_data в разделе Загрузка примера данных в кластер больших данных.
В Azure Data Studio установите подключение к главному экземпляру в кластере больших данных. Дополнительные сведения см. в разделе Подключение к кластеру больших данных.
Создайте новую записную книжку и выберите Spark | Scala в качестве ядра.
Запуск задания приема Spark
- Настройка параметров соединителя Spark-SQL
Примечание.
Если кластер больших данных развертывается с интеграцией с Active Directory, замените значение hostname ниже, чтобы оно включало полное доменное имя, добавленное к имени службы. Например, hostname=master-p-svc.<domainName>.
import org.apache.spark.sql.types._ import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} // Change per your installation val user= "username" val password= "****" val database = "MyTestDatabase" val sourceDir = "/clickstream_data" val datapool_table = "web_clickstreams_spark_results" val datasource_name = "SqlDataPool" val schema = StructType(Seq( StructField("wcs_click_date_sk",LongType,true), StructField("wcs_click_time_sk",LongType,true), StructField("wcs_sales_sk",LongType,true), StructField("wcs_item_sk",LongType,true), StructField("wcs_web_page_sk",LongType,true), StructField("wcs_user_sk",LongType,true) )) val hostname = "master-p-svc" val port = 1433 val url = s"jdbc:sqlserver://${hostname}:${port};database=${database};user=${user};password=${password};"- Определение и запуск задания Spark
- Каждое задание состоит из двух частей: readStream и writeStream. Ниже мы создадим кадр данных, используя определенную выше схему, а затем запишем его во внешнюю таблицу в пуле данных.
import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} val df = spark.readStream.format("csv").schema(schema).option("header", true).load(sourceDir) val query = df.writeStream.outputMode("append").foreachBatch{ (batchDF: DataFrame, batchId: Long) => batchDF.write .format("com.microsoft.sqlserver.jdbc.spark") .mode("append") .option("url", url) .option("dbtable", datapool_table) .option("user", user) .option("password", password) .option("dataPoolDataSource",datasource_name).save() }.start() query.awaitTermination(40000) query.stop()
Запрос данных
Следующие шаги показывают, что задание потоковой передачи Spark загрузило данные из HDFS в пул данных.
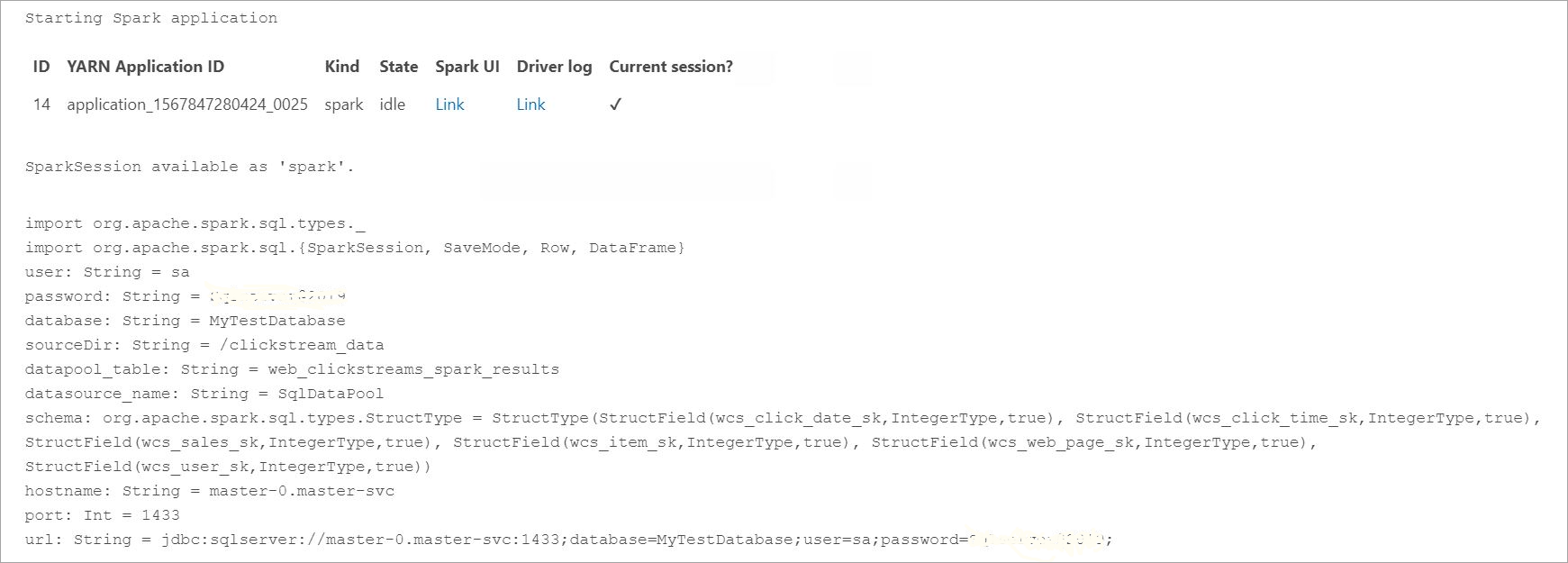
Перед запросом полученных данных просмотрите состояние выполнения Spark, включая идентификатор приложения Yarn, пользовательский интерфейс Spark и журналы драйверов. Эти сведения будут отображаться в записной книжке при первом запуске приложения Spark.
Вернитесь в окно запроса главного экземпляра SQL Server, которое было открыто в начале работы с этим руководством.
Выполните приведенный ниже запрос, чтобы изучить принятые данные.
USE Sales GO SELECT count(*) FROM [web_clickstreams_spark_results]; SELECT TOP 10 * FROM [web_clickstreams_spark_results];Данные также можно запрашивать в Spark. Например, приведенный ниже код выводит число записей в таблице.
def df_read(dbtable: String, url: String, dataPoolDataSource: String=""): DataFrame = { spark.read .format("com.microsoft.sqlserver.jdbc.spark") .option("url", url) .option("dbtable", dbtable) .option("user", user) .option("password", password) .option("dataPoolDataSource", dataPoolDataSource) .load() } val new_df = df_read(datapool_table, url, dataPoolDataSource=datasource_name) println("Number of rows is " + new_df.count)
Очистка
Выполните следующую команду, чтобы удалить объекты базы данных, созданные в рамках этого руководства.
DROP EXTERNAL TABLE [dbo].[web_clickstreams_spark_results];
Следующие шаги
См. сведения о запуске примера записной книжки в Azure Data Studio:
Кері байланыс
Жақында қолжетімді болады: 2024 жыл бойы біз GitHub Issues жүйесін мазмұнға арналған кері байланыс механизмі ретінде біртіндеп қолданыстан шығарамыз және оны жаңа кері байланыс жүйесімен ауыстырамыз. Қосымша ақпаратты мұнда қараңыз: https://aka.ms/ContentUserFeedback.
Жіберу және пікірді көру