Ескертпе
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Жүйеге кіруді немесе каталогтарды өзгертуді байқап көруге болады.
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Каталогтарды өзгертуді байқап көруге болады.
Применимо к:![]() SQL Server
SQL Server![]() Azure SQL База данных
Azure SQL База данных![]() Azure SQL Управляемый экземпляр
Azure SQL Управляемый экземпляр![]() SQL База данных в Microsoft Fabric
SQL База данных в Microsoft Fabric
В этой статье описывается построение графиков данных с помощью пакета Python pandas'.hist(). База данных SQL Server — это источник, используемый для визуализации интервалов данных гистограммы, имеющих последовательные не перекрывающиеся значения.
Prerequisites
SQL Server Management Studio для восстановления образца базы данных в Управляемый экземпляр SQL Azure.
Azure Data Studio. Сведения об установке см. в разделе Azure Data Studio.
Восстановление образца базы данных DW для получения демонстрационных данных, используемых в этой статье.
Проверка восстановленной базы данных
Чтобы убедиться, что восстановленная база данных существует, выполните запрос к Person.CountryRegion таблице:
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Установка пакетов Python
Скачивание и установка Azure Data Studio.
Установите следующие пакеты Python.
pyodbcpandassqlalchemymatplotlib
Чтобы установить эти пакеты, выполните приведенные ниже действия.
- В записной книжке Azure Data Studio выберите Управление пакетами.
- В области Управление пакетами выберите вкладку Добавить новые.
- Для каждого из следующих пакетов введите имя пакета, нажмите Поиск, а затем — Установить.
Построить гистограмму
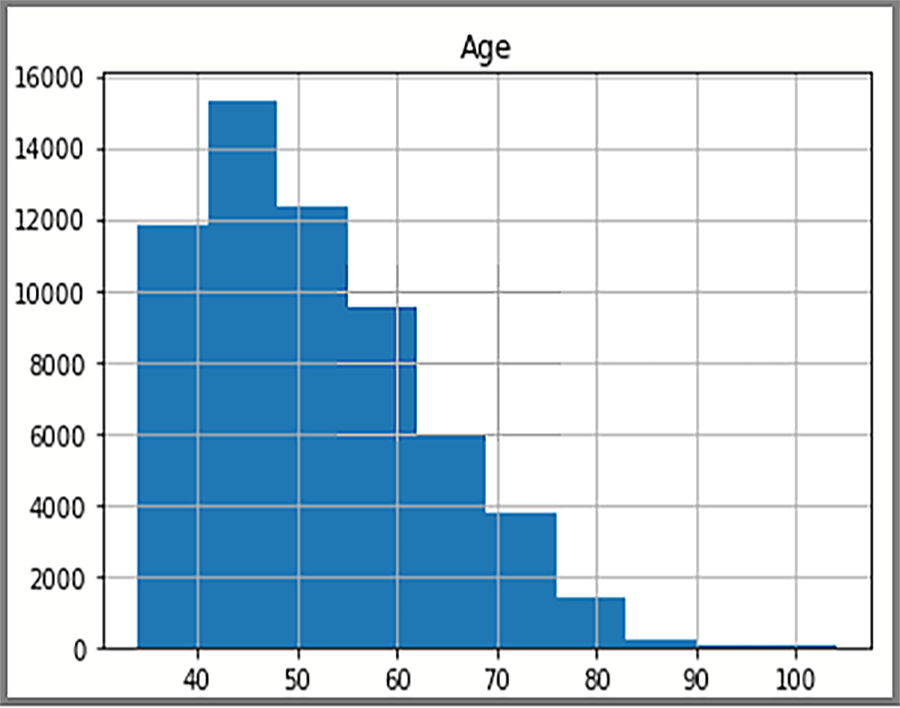
Распределенные данные, отображаемые в гистограмме, основаны на SQL-запросе.AdventureWorksDW2025 Гистограмма визуализирует данные и частоту значений данных.
Измените переменные строки подключения: server, database, usernameи password для подключения к базе данных SQL Server.
Чтобы создать записную книжку:
В Azure Data Studio выберите пункт Файл и Новая записная книжка.
В записной книжке выберите ядро Python3 и нажмите + Код.
Вставьте код в записную книжку. Выберите Запустить все.
import pyodbc import pandas as pd import matplotlib import sqlalchemy from sqlalchemy import create_engine matplotlib.use('TkAgg', force=True) from matplotlib import pyplot as plt # Some other example server values are # server = 'localhost\sqlexpress' # for a named instance # server = 'myserver,port' # to specify an alternate port server = 'servername' database = 'AdventureWorksDW2022' username = 'yourusername' password = 'databasename' url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database) engine = create_engine(url) sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey" df = pd.read_sql(sql, engine) df.hist(bins=50) plt.show()
На экране отображается распределение возрастов клиентов в FactInternetSales таблице.